 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Prevalence Estimation with Multicalibrated LLMs
Apr 23, 2026Estimating the prevalence of a category in a population using imperfect measurement devices (diagnostic tests, classifiers, or large language models) is fundamental to science, public health, and online trust and safety. Standard approaches correct for known device error rates but assume these rates remain stable across populations. We show this assumption fails under covariate shift and that multicalibration, which enforces calibration conditional on the input features rather than just on average, is sufficient for unbiased prevalence estimation under such shift. Standard calibration and quantification methods fail to provide this guarantee. Our work connects recent theoretical work on fairness to a longstanding measurement problem spanning nearly all academic disciplines. A simulation confirms that standard methods exhibit bias growing with shift magnitude, while a multicalibrated estimator maintains near-zero bias. While we focus the discussion mostly on LLMs, our theoretical results apply to any classification model. Two empirical applications -- estimating employment prevalence across U.S. states using the American Community Survey, and classifying political texts across four countries using an LLM -- demonstrate that multicalibration substantially reduces bias in practice, while highlighting that calibration data should cover the key feature dimensions along which target populations may differ.
On the Convergence of Multicalibration Gradient Boosting
Feb 06, 2026Multicalibration gradient boosting has recently emerged as a scalable method that empirically produces approximately multicalibrated predictors and has been deployed at web scale. Despite this empirical success, its convergence properties are not well understood. In this paper, we bridge the gap by providing convergence guarantees for multicalibration gradient boosting in regression with squared-error loss. We show that the magnitude of successive prediction updates decays at $O(1/\sqrt{T})$, which implies the same convergence rate bound for the multicalibration error over rounds. Under additional smoothness assumptions on the weak learners, this rate improves to linear convergence. We further analyze adaptive variants, showing local quadratic convergence of the training loss, and we study rescaling schemes that preserve convergence. Experiments on real-world datasets support our theory and clarify the regimes in which the method achieves fast convergence and strong multicalibration.
What is the Alignment Objective of GRPO?
Feb 25, 2025In this note, we examine the aggregation of preferences achieved by the Group Policy Optimisation (GRPO) algorithm, a reinforcement learning method used to train advanced artificial intelligence models such as DeepSeek-R1-Zero and DeepSeekMath. The GRPO algorithm trains a policy using a reward preference model, which is computed by sampling a set of outputs for a given context, observing the corresponding rewards, and applying shift-and-scale normalisation to these reward values. Additionally, it incorporates a penalty function to discourage deviations from a reference policy. We present a framework that enables us to characterise the stationary policies of the GRPO algorithm. This analysis reveals that the aggregation of preferences differs fundamentally from standard logarithmic pooling, which is implemented by other approaches such as RLHF. The precise form of preference aggregation arises from the way the reward preference model is defined and from the penalty function, which we show to essentially correspond to the reverse Kullback-Leibler (KL) divergence between the aggregation policy and the reference policy. Interestingly, we demonstrate that for groups of size two, the reward preference model corresponds to pairwise comparison preferences, similar to those in other alignment methods based on pairwise comparison feedback. We provide explicit characterisations of the aggregate preference for binary questions, for groups of size two, and in the limit of large group size. This provides insights into the dependence of the aggregate preference on parameters such as the regularisation constant and the confidence margin of question answers. Finally, we discuss the aggregation of preferences obtained by modifying the GRPO algorithm to use direct KL divergence as the penalty or to use rewards without scale normalisation.
Rotting Infinitely Many-armed Bandits beyond the Worst-case Rotting: An Adaptive Approach
Apr 22, 2024In this study, we consider the infinitely many armed bandit problems in rotting environments, where the mean reward of an arm may decrease with each pull, while otherwise, it remains unchanged. We explore two scenarios capturing problem-dependent characteristics regarding the decay of rewards: one in which the cumulative amount of rotting is bounded by $V_T$, referred to as the slow-rotting scenario, and the other in which the number of rotting instances is bounded by $S_T$, referred to as the abrupt-rotting scenario. To address the challenge posed by rotting rewards, we introduce an algorithm that utilizes UCB with an adaptive sliding window, designed to manage the bias and variance trade-off arising due to rotting rewards. Our proposed algorithm achieves tight regret bounds for both slow and abrupt rotting scenarios. Lastly, we demonstrate the performance of our algorithms using synthetic datasets.
On the convergence of loss and uncertainty-based active learning algorithms
Dec 21, 2023We study convergence rates of loss and uncertainty-based active learning algorithms under various assumptions. First, we provide a set of conditions under which a convergence rate guarantee holds, and use this for linear classifiers and linearly separable datasets to show convergence rate guarantees for loss-based sampling and different loss functions. Second, we provide a framework that allows us to derive convergence rate bounds for loss-based sampling by deploying known convergence rate bounds for stochastic gradient descent algorithms. Third, and last, we propose an active learning algorithm that combines sampling of points and stochastic Polyak's step size. We show a condition on the sampling that ensures a convergence rate guarantee for this algorithm for smooth convex loss functions. Our numerical results demonstrate efficiency of our proposed algorithm.
Rotting infinitely many-armed bandits
Jan 31, 2022
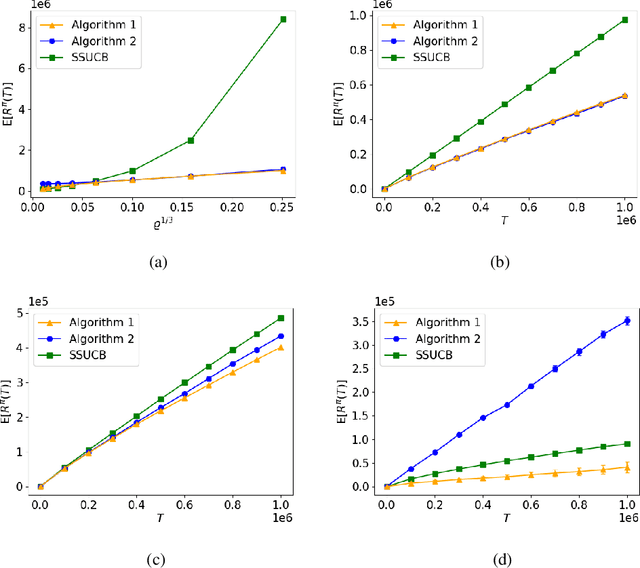
We consider the infinitely many-armed bandit problem with rotting rewards, where the mean reward of an arm decreases at each pull of the arm according to an arbitrary trend with maximum rotting rate $\varrho=o(1)$. We show that this learning problem has an $\Omega(\max\{\varrho^{1/3}T,\sqrt{T}\})$ worst-case regret lower bound where $T$ is the horizon time. We show that a matching upper bound $\tilde{O}(\max\{\varrho^{1/3}T,\sqrt{T}\})$, up to a poly-logarithmic factor, can be achieved by an algorithm that uses a UCB index for each arm and a threshold value to decide whether to continue pulling an arm or remove the arm from further consideration, when the algorithm knows the value of the maximum rotting rate $\varrho$. We also show that an $\tilde{O}(\max\{\varrho^{1/3}T,T^{3/4}\})$ regret upper bound can be achieved by an algorithm that does not know the value of $\varrho$, by using an adaptive UCB index along with an adaptive threshold value.
Scheduling Servers with Stochastic Bilinear Rewards
Dec 13, 2021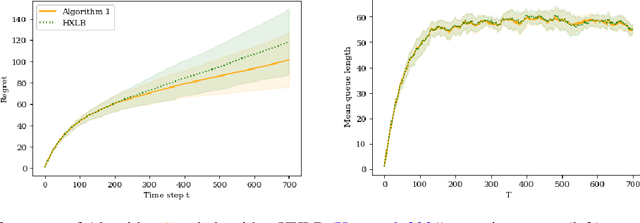
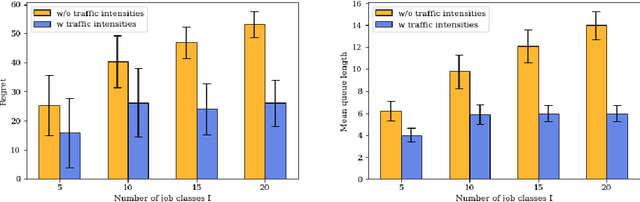
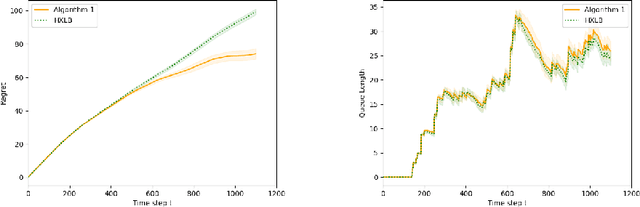
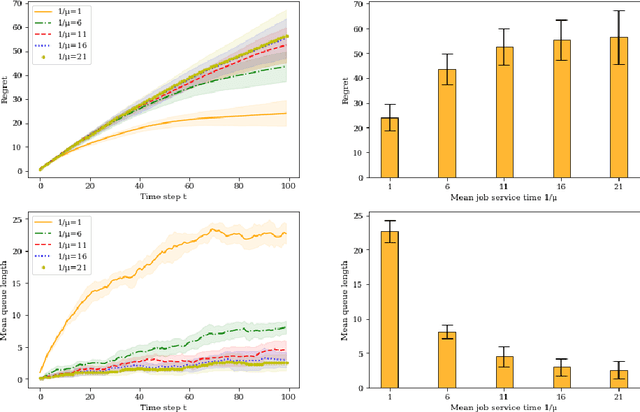
In this paper we study a multi-class, multi-server queueing system with stochastic rewards of job-server assignments following a bilinear model in feature vectors representing jobs and servers. Our goal is regret minimization against an oracle policy that has a complete information about system parameters. We propose a scheduling algorithm that uses a linear bandit algorithm along with dynamic allocation of jobs to servers. For the baseline setting, in which mean job service times are identical for all jobs, we show that our algorithm has a sub-linear regret, as well as a sub-linear bound on the mean queue length, in the horizon time. We further show that similar bounds hold under more general assumptions, allowing for non-identical mean job service times for different job classes and a time-varying set of server classes. We also show that better regret and mean queue length bounds can be guaranteed by an algorithm having access to traffic intensities of job classes. We present results of numerical experiments demonstrating how regret and mean queue length of our algorithms depend on various system parameters and compare their performance against a previously proposed algorithm using synthetic randomly generated data and a real-world cluster computing data trace.
Pure Exploration and Regret Minimization in Matching Bandits
Jul 31, 2021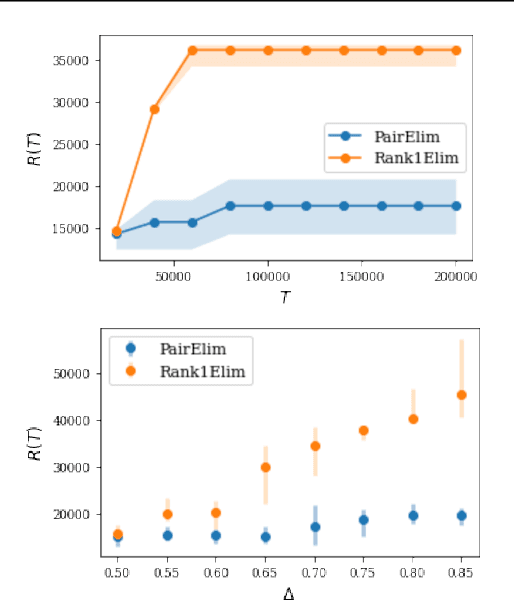
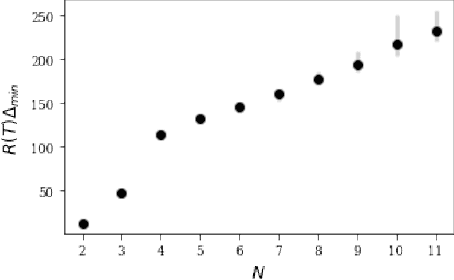
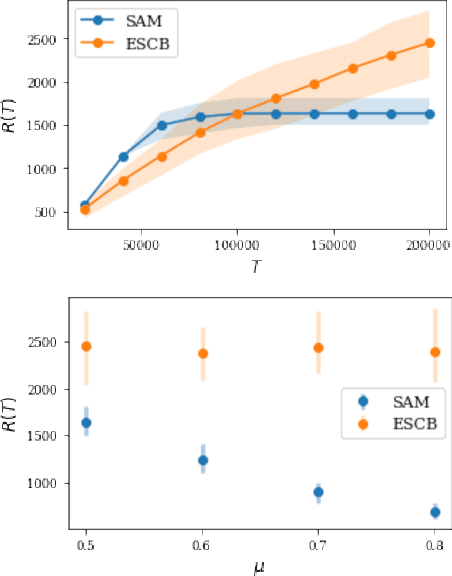
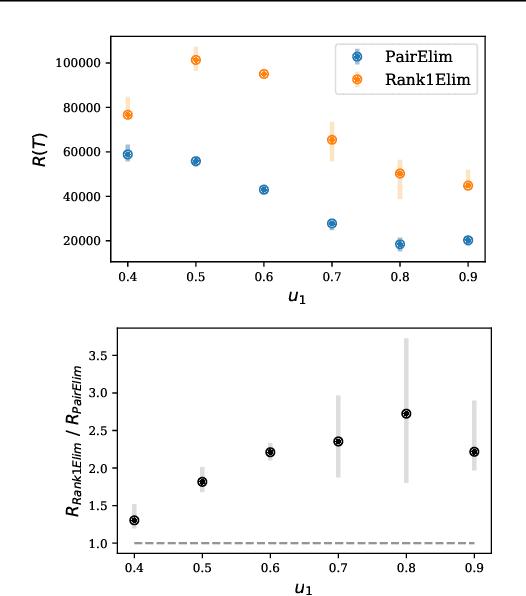
Finding an optimal matching in a weighted graph is a standard combinatorial problem. We consider its semi-bandit version where either a pair or a full matching is sampled sequentially. We prove that it is possible to leverage a rank-1 assumption on the adjacency matrix to reduce the sample complexity and the regret of off-the-shelf algorithms up to reaching a linear dependency in the number of vertices (up to poly log terms).
Learning to Schedule
May 28, 2021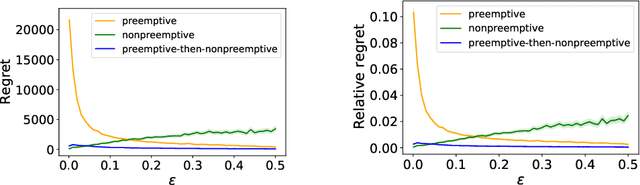
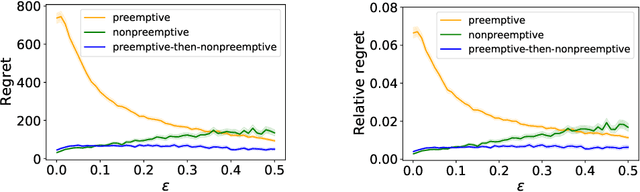
This paper proposes a learning and scheduling algorithm to minimize the expected cumulative holding cost incurred by jobs, where statistical parameters defining their individual holding costs are unknown a priori. In each time slot, the server can process a job while receiving the realized random holding costs of the jobs remaining in the system. Our algorithm is a learning-based variant of the $c\mu$ rule for scheduling: it starts with a preemption period of fixed length which serves as a learning phase, and after accumulating enough data about individual jobs, it switches to nonpreemptive scheduling mode. The algorithm is designed to handle instances with large or small gaps in jobs' parameters and achieves near-optimal performance guarantees. The performance of our algorithm is captured by its regret, where the benchmark is the minimum possible cost attained when the statistical parameters of jobs are fully known. We prove upper bounds on the regret of our algorithm, and we derive a regret lower bound that is almost matching the proposed upper bounds. Our numerical results demonstrate the effectiveness of our algorithm and show that our theoretical regret analysis is nearly tight.
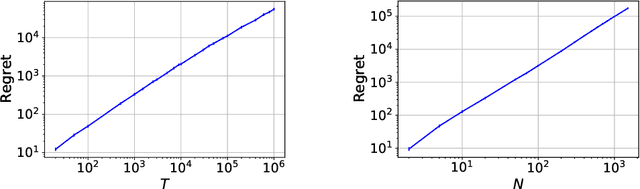
Test Score Algorithms for Budgeted Stochastic Utility Maximization
Dec 30, 2020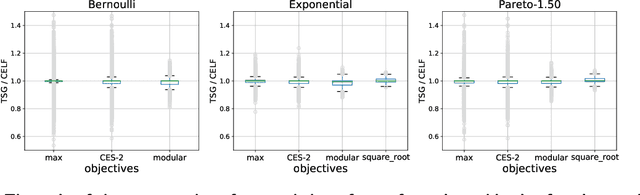
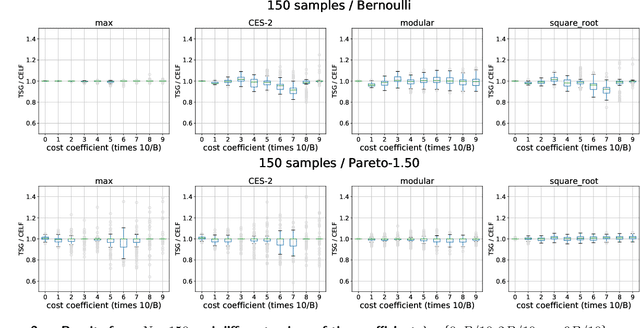
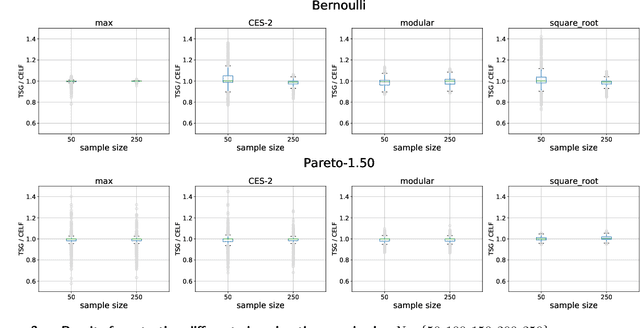
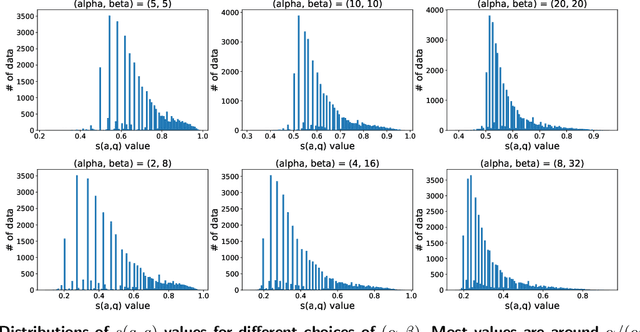
Motivated by recent developments in designing algorithms based on individual item scores for solving utility maximization problems, we study the framework of using test scores, defined as a statistic of observed individual item performance data, for solving the budgeted stochastic utility maximization problem. We extend an existing scoring mechanism, namely the replication test scores, to incorporate heterogeneous item costs as well as item values. We show that a natural greedy algorithm that selects items solely based on their replication test scores outputs solutions within a constant factor of the optimum for a broad class of utility functions. Our algorithms and approximation guarantees assume that test scores are noisy estimates of certain expected values with respect to marginal distributions of individual item values, thus making our algorithms practical and extending previous work that assumes noiseless estimates. Moreover, we show how our algorithm can be adapted to the setting where items arrive in a streaming fashion while maintaining the same approximation guarantee. We present numerical results, using synthetic data and data sets from the Academia.StackExchange Q&A forum, which show that our test score algorithm can achieve competitiveness, and in some cases better performance than a benchmark algorithm that requires access to a value oracle to evaluate function values.