 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reinforcement Learning with Competitive Ensembles of Information-Constrained Primitives
Jun 25, 2019
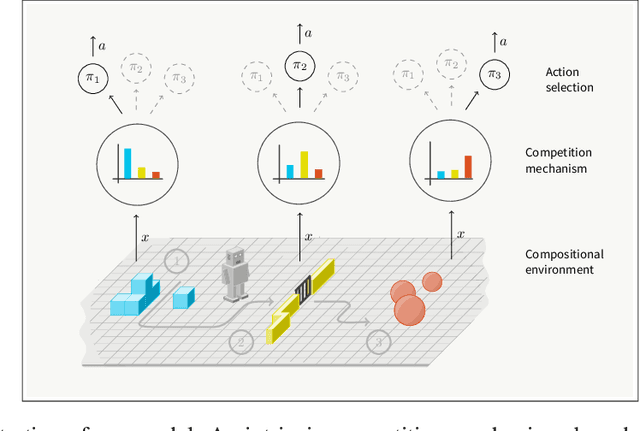

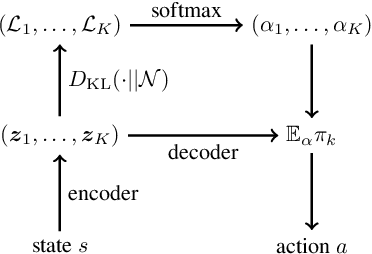
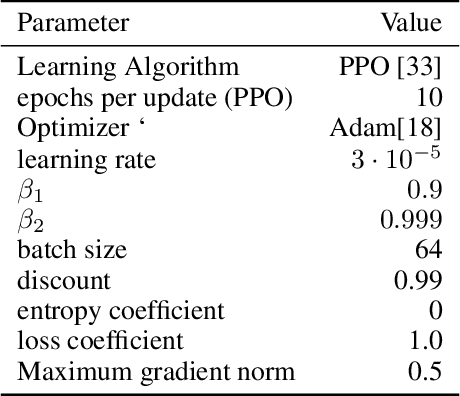
Reinforcement learning agents that operate in diverse and complex environments can benefit from the structured decomposition of their behavior. Often, this is addressed in the context of hierarchical reinforcement learning, where the aim is to decompose a policy into lower-level primitives or options, and a higher-level meta-policy that triggers the appropriate behaviors for a given situation. However, the meta-policy must still produce appropriate decisions in all states. In this work, we propose a policy design that decomposes into primitives, similarly to hierarchical reinforcement learning, but without a high-level meta-policy. Instead, each primitive can decide for themselves whether they wish to act in the current state. We use an information-theoretic mechanism for enabling this decentralized decision: each primitive chooses how much information it needs about the current state to make a decision and the primitive that requests the most information about the current state acts in the world. The primitives are regularized to use as little information as possible, which leads to natural competition and specialization. We experimentally demonstrate that this policy architecture improves over both flat and hierarchical policies in terms of generalization.
Utilizing geospatial data for assessing energy security: Mapping small solar home systems using unmanned aerial vehicles and deep learning
Jan 14, 2022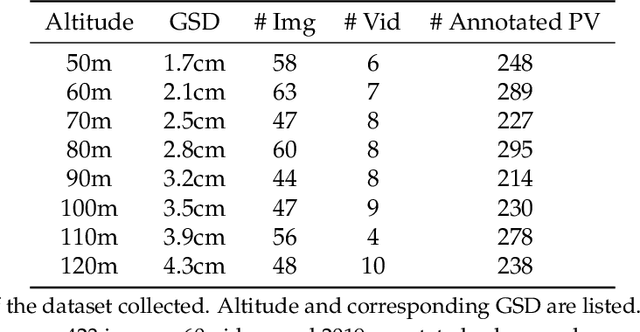

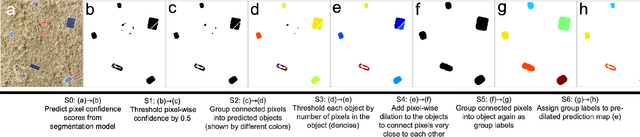
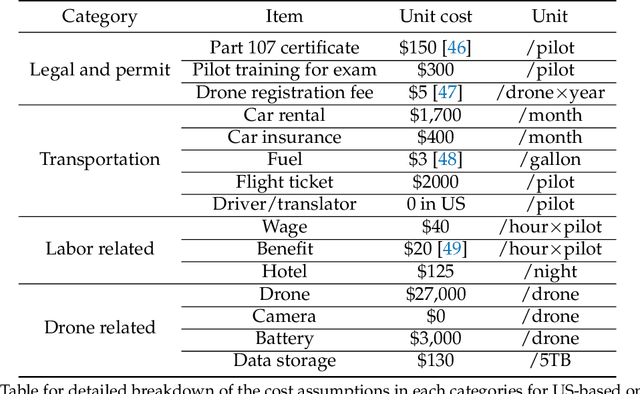
Solar home systems (SHS), a cost-effective solution for rural communities far from the grid in developing countries, are small solar panels and associated equipment that provides power to a single household. A crucial resource for targeting further investment of public and private resources, as well as tracking the progress of universal electrification goals, is shared access to high-quality data on individual SHS installations including information such as location and power capacity. Though recent studies utilizing satellite imagery and machine learning to detect solar panels have emerged, they struggle to accurately locate many SHS due to limited image resolution (some small solar panels only occupy several pixels in satellite imagery). In this work, we explore the viability and cost-performance tradeoff of using automatic SHS detection on unmanned aerial vehicle (UAV) imagery as an alternative to satellite imagery. More specifically, we explore three questions: (i) what is the detection performance of SHS using drone imagery; (ii) how expensive is the drone data collection, compared to satellite imagery; and (iii) how well does drone-based SHS detection perform in real-world scenarios. We collect and publicly-release a dataset of high-resolution drone imagery encompassing SHS imaged under real-world conditions and use this dataset and a dataset from Rwanda to evaluate the capabilities of deep learning models to recognize SHS, including those that are too small to be reliably recognized in satellite imagery. The results suggest that UAV imagery may be a viable alternative to identify very small SHS from perspectives of both detection accuracy and financial costs of data collection. UAV-based data collection may be a practical option for supporting electricity access planning strategies for achieving sustainable development goals and for monitoring the progress towards those goals.
Kernelized information bottleneck leads to biologically plausible 3-factor Hebbian learning in deep networks
Jun 12, 2020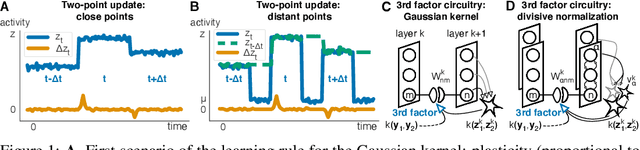
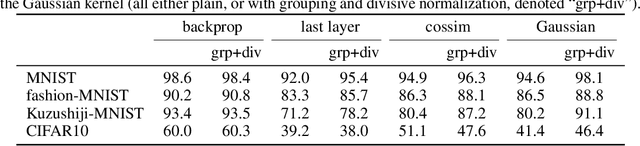
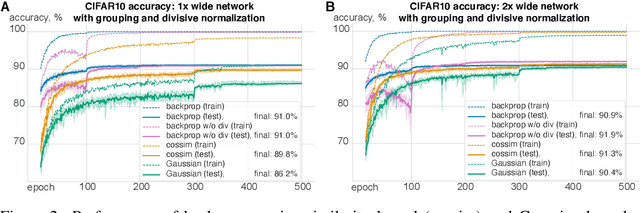

The state-of-the art machine learning approach to training deep neural networks, backpropagation, is implausible for real neural networks: neurons need to know their outgoing weights; training alternates between a forward pass (computation) and a backward pass (learning); and the algorithm needs a large amount of labeled data. Biologically plausible approximations to backpropagation, such as feedback alignment, solve the weight transport problem, but not the other two. Thus, fully biologically plausible learning rules have so far remained elusive. Here we present a family of learning rules that does not suffer from any of these problems. It is motivated by the information bottleneck principle (extended with kernel methods), in which networks learn to squeeze as much information as possible out of the input without sacrificing prediction of the output. The resulting rules have a 3-factor Hebbian structure: they require pre- and post-synaptic firing rates and a global error signal - the third factor - that can be supplied by a neuromodulator. Moreover, they do not require precise labels; instead, they rely on the similarity between the desired outputs. They thus solve all three implausibility issues of backpropagation. Moreover, to obtain good performance on hard problems and retain biologically plausible learning rules, our rules need divisive normalization - a known feature of biological networks. Finally, simulations show that our rule performs nearly as well as backpropagation on image classification tasks.
On robust risk-based active-learning algorithms for enhanced decision support
Jan 07, 2022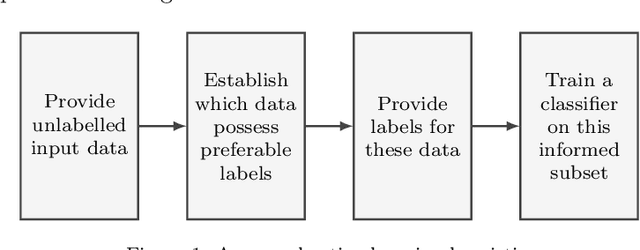
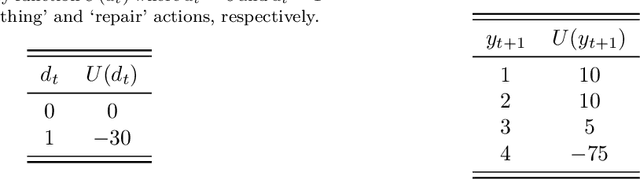
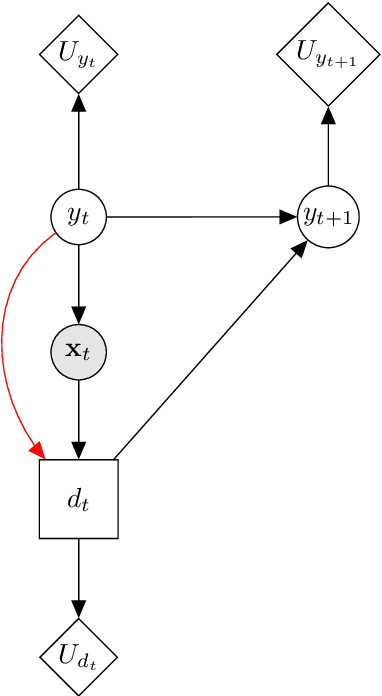
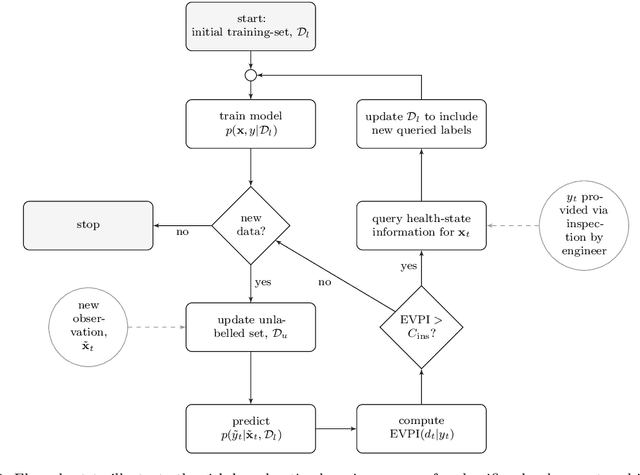
Classification models are a fundamental component of physical-asset management technologies such as structural health monitoring (SHM) systems and digital twins. Previous work introduced \textit{risk-based active learning}, an online approach for the development of statistical classifiers that takes into account the decision-support context in which they are applied. Decision-making is considered by preferentially querying data labels according to \textit{expected value of perfect information} (EVPI). Although several benefits are gained by adopting a risk-based active learning approach, including improved decision-making performance, the algorithms suffer from issues relating to sampling bias as a result of the guided querying process. This sampling bias ultimately manifests as a decline in decision-making performance during the later stages of active learning, which in turn corresponds to lost resource/utility. The current paper proposes two novel approaches to counteract the effects of sampling bias: \textit{semi-supervised learning}, and \textit{discriminative classification models}. These approaches are first visualised using a synthetic dataset, then subsequently applied to an experimental case study, specifically, the Z24 Bridge dataset. The semi-supervised learning approach is shown to have variable performance; with robustness to sampling bias dependent on the suitability of the generative distributions selected for the model with respect to each dataset. In contrast, the discriminative classifiers are shown to have excellent robustness to the effects of sampling bias. Moreover, it was found that the number of inspections made during a monitoring campaign, and therefore resource expenditure, could be reduced with the careful selection of the statistical classifiers used within a decision-supporting monitoring system.
Exploiting Persona Information for Diverse Generation of Conversational Responses
May 29, 2019
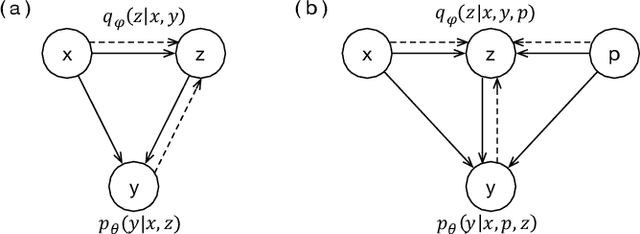
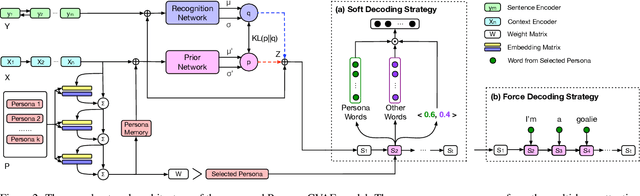
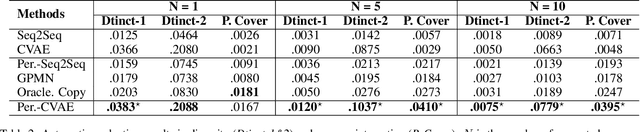
In human conversations, due to their personalities in mind, people can easily carry out and maintain the conversations. Giving conversational context with persona information to a chatbot, how to exploit the information to generate diverse and sustainable conversations is still a non-trivial task. Previous work on persona-based conversational models successfully make use of predefined persona information and have shown great promise in delivering more realistic responses. And they all learn with the assumption that given a source input, there is only one target response. However, in human conversations, there are massive appropriate responses to a given input message. In this paper, we propose a memory-augmented architecture to exploit persona information from context and incorporate a conditional variational autoencoder model together to generate diverse and sustainable conversations. We evaluate the proposed model on a benchmark persona-chat dataset. Both automatic and human evaluations show that our model can deliver more diverse and more engaging persona-based responses than baseline approaches.
Joint Learning of Visual-Audio Saliency Prediction and Sound Source Localization on Multi-face Videos
Nov 05, 2021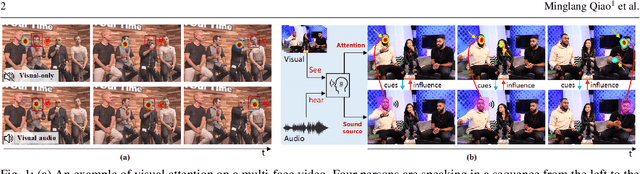
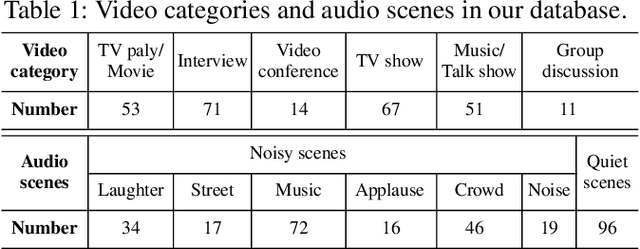

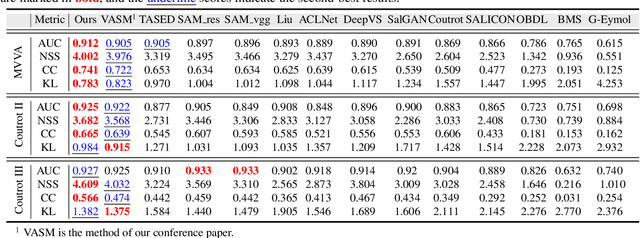
Visual and audio events simultaneously occur and both attract attention. However, most existing saliency prediction works ignore the influence of audio and only consider vision modality. In this paper, we propose a multitask learning method for visual-audio saliency prediction and sound source localization on multi-face video by leveraging visual, audio and face information. Specifically, we first introduce a large-scale database of multi-face video in visual-audio condition (MVVA), containing eye-tracking data and sound source annotations. Using this database, we find that sound influences human attention, and conversly attention offers a cue to determine sound source on multi-face video. Guided by these findings, a visual-audio multi-task network (VAM-Net) is introduced to predict saliency and locate sound source. VAM-Net consists of three branches corresponding to visual, audio and face modalities. Visual branch has a two-stream architecture to capture spatial and temporal information. Face and audio branches encode audio signals and faces, respectively. Finally, a spatio-temporal multi-modal graph (STMG) is constructed to model the interaction among multiple faces. With joint optimization of these branches, the intrinsic correlation of the tasks of saliency prediction and sound source localization is utilized and their performance is boosted by each other. Experiments show that the proposed method outperforms 12 state-of-the-art saliency prediction methods, and achieves competitive results in sound source localization.
Determination of building flood risk maps from LiDAR mobile mapping data
Jan 14, 2022
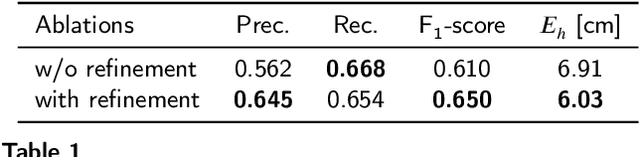
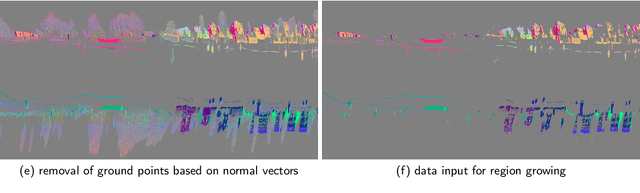
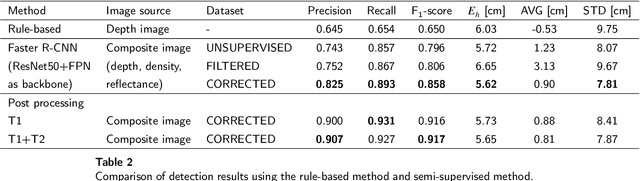
With increasing urbanization, flooding is a major challenge for many cities today. Based on forecast precipitation, topography, and pipe networks, flood simulations can provide early warnings for areas and buildings at risk of flooding. Basement windows, doors, and underground garage entrances are common places where floodwater can flow into a building. Some buildings have been prepared or designed considering the threat of flooding, but others have not. Therefore, knowing the heights of these facade openings helps to identify places that are more susceptible to water ingress. However, such data is not yet readily available in most cities. Traditional surveying of the desired targets may be used, but this is a very time-consuming and laborious process. This research presents a new process for the extraction of windows and doors from LiDAR mobile mapping data. Deep learning object detection models are trained to identify these objects. Usually, this requires to provide large amounts of manual annotations. In this paper, we mitigate this problem by leveraging a rule-based method. In a first step, the rule-based method is used to generate pseudo-labels. A semi-supervised learning strategy is then applied with three different levels of supervision. The results show that using only automatically generated pseudo-labels, the learning-based model outperforms the rule-based approach by 14.6% in terms of F1-score. After five hours of human supervision, it is possible to improve the model by another 6.2%. By comparing the detected facade openings' heights with the predicted water levels from a flood simulation model, a map can be produced which assigns per-building flood risk levels. This information can be combined with flood forecasting to provide a more targeted disaster prevention guide for the city's infrastructure and residential buildings.
Learning Target-aware Representation for Visual Tracking via Informative Interactions
Jan 07, 2022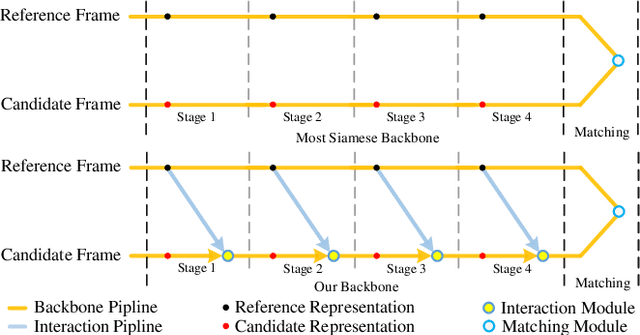
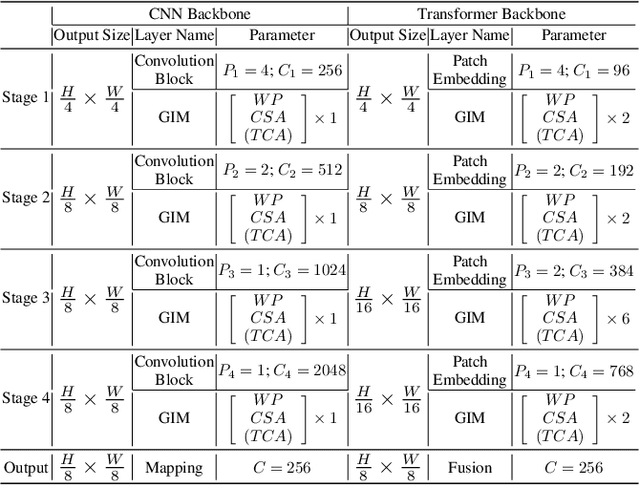
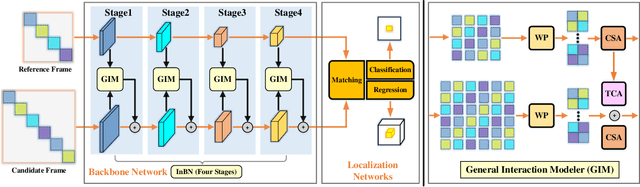
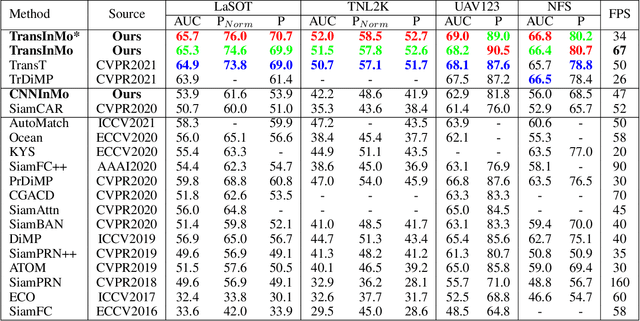
We introduce a novel backbone architecture to improve target-perception ability of feature representation for tracking. Specifically, having observed that de facto frameworks perform feature matching simply using the outputs from backbone for target localization, there is no direct feedback from the matching module to the backbone network, especially the shallow layers. More concretely, only the matching module can directly access the target information (in the reference frame), while the representation learning of candidate frame is blind to the reference target. As a consequence, the accumulation effect of target-irrelevant interference in the shallow stages may degrade the feature quality of deeper layers. In this paper, we approach the problem from a different angle by conducting multiple branch-wise interactions inside the Siamese-like backbone networks (InBN). At the core of InBN is a general interaction modeler (GIM) that injects the prior knowledge of reference image to different stages of the backbone network, leading to better target-perception and robust distractor-resistance of candidate feature representation with negligible computation cost. The proposed GIM module and InBN mechanism are general and applicable to different backbone types including CNN and Transformer for improvements, as evidenced by our extensive experiments on multiple benchmarks. In particular, the CNN version (based on SiamCAR) improves the baseline with 3.2/6.9 absolute gains of SUC on LaSOT/TNL2K, respectively. The Transformer version obtains SUC scores of 65.7/52.0 on LaSOT/TNL2K, which are on par with recent state of the arts. Code and models will be released.
M-FasterSeg: An Efficient Semantic Segmentation Network Based on Neural Architecture Search
Dec 30, 2021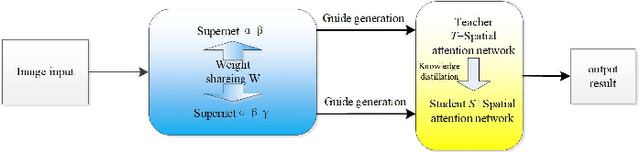
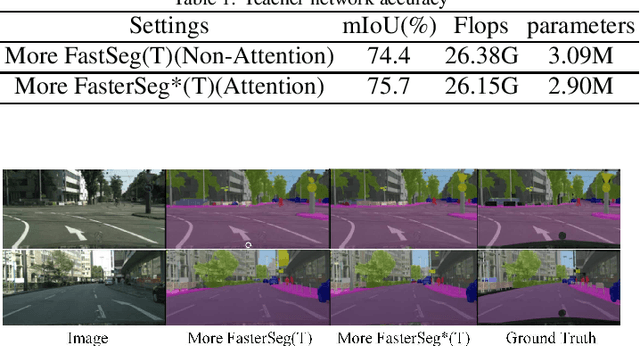
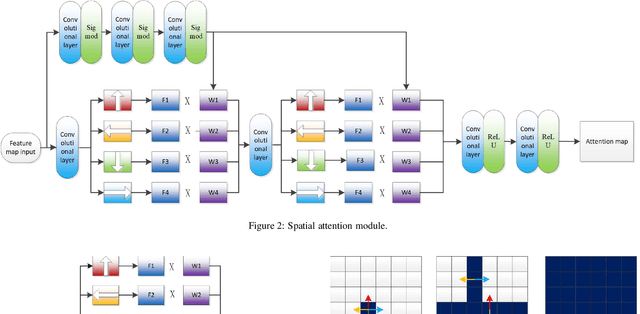
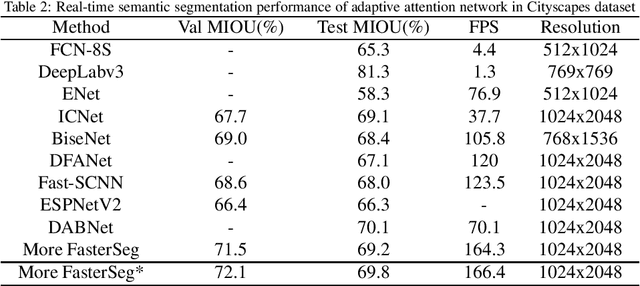
Image semantic segmentation technology is one of the key technologies for intelligent systems to understand natural scenes. As one of the important research directions in the field of visual intelligence, this technology has broad application scenarios in the fields of mobile robots, drones, smart driving, and smart security. However, in the actual application of mobile robots, problems such as inaccurate segmentation semantic label prediction and loss of edge information of segmented objects and background may occur. This paper proposes an improved structure of a semantic segmentation network based on a deep learning network that combines self-attention neural network and neural network architecture search methods. First, a neural network search method NAS (Neural Architecture Search) is used to find a semantic segmentation network with multiple resolution branches. In the search process, combine the self-attention network structure module to adjust the searched neural network structure, and then combine the semantic segmentation network searched by different branches to form a fast semantic segmentation network structure, and input the picture into the network structure to get the final forecast result. The experimental results on the Cityscapes dataset show that the accuracy of the algorithm is 69.8%, and the segmentation speed is 48/s. It achieves a good balance between real-time and accuracy, can optimize edge segmentation, and has a better performance in complex scenes. Good robustness is suitable for practical application.
Enhancing Multi-Scale Implicit Learning in Image Super-Resolution with Integrated Positional Encoding
Dec 10, 2021
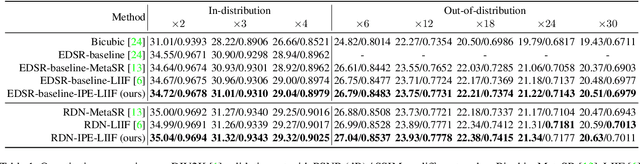
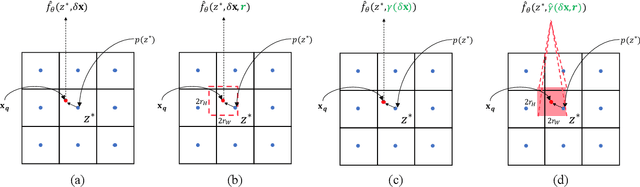
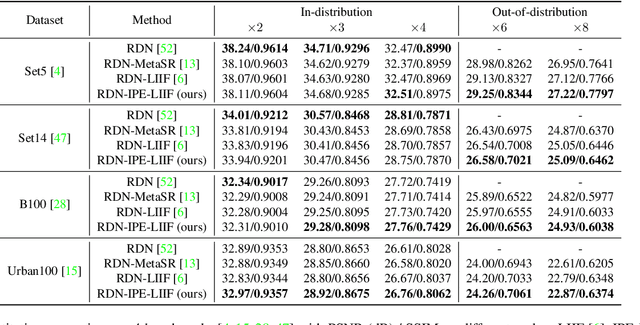
Is the center position fully capable of representing a pixel? There is nothing wrong to represent pixels with their centers in a discrete image representation, but it makes more sense to consider each pixel as the aggregation of signals from a local area in an image super-resolution (SR) context. Despite the great capability of coordinate-based implicit representation in the field of arbitrary-scale image SR, this area's nature of pixels is not fully considered. To this end, we propose integrated positional encoding (IPE), extending traditional positional encoding by aggregating frequency information over the pixel area. We apply IPE to the state-of-the-art arbitrary-scale image super-resolution method: local implicit image function (LIIF), presenting IPE-LIIF. We show the effectiveness of IPE-LIIF by quantitative and qualitative evaluations, and further demonstrate the generalization ability of IPE to larger image scales and multiple implicit-based methods. Code will be released.