 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Data-Driven Deep Learning Based Hybrid Beamforming for Aerial Massive MIMO-OFDM Systems with Implicit CSI
Jan 18, 2022
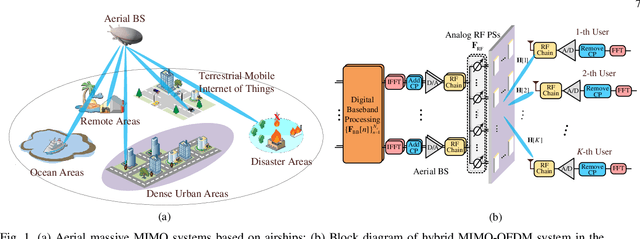
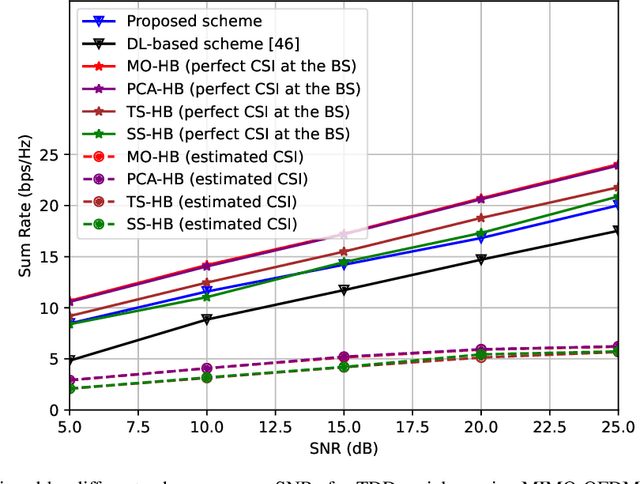
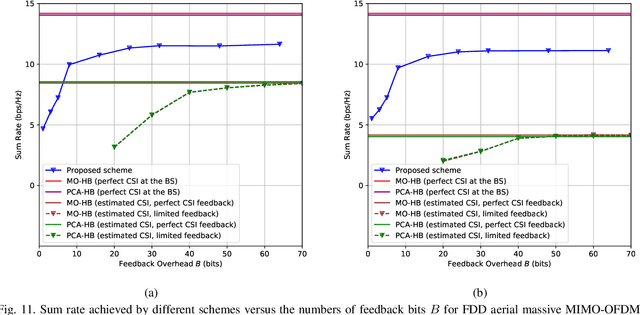
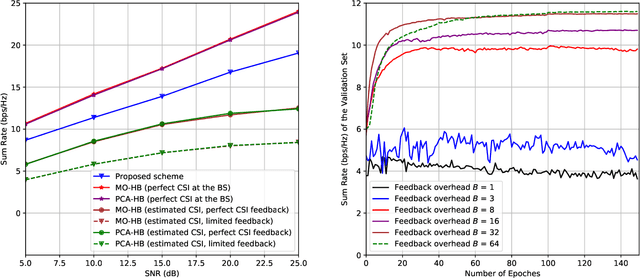
In an aerial hybrid massive multiple-input multiple-output (MIMO) and orthogonal frequency division multiplexing (OFDM) system, how to design a spectral-efficient broadband multi-user hybrid beamforming with a limited pilot and feedback overhead is challenging. To this end, by modeling the key transmission modules as an end-to-end (E2E) neural network, this paper proposes a data-driven deep learning (DL)-based unified hybrid beamforming framework for both the time division duplex (TDD) and frequency division duplex (FDD) systems with implicit channel state information (CSI). For TDD systems, the proposed DL-based approach jointly models the uplink pilot combining and downlink hybrid beamforming modules as an E2E neural network. While for FDD systems, we jointly model the downlink pilot transmission, uplink CSI feedback, and downlink hybrid beamforming modules as an E2E neural network. Different from conventional approaches separately processing different modules, the proposed solution simultaneously optimizes all modules with the sum rate as the optimization object. Therefore, by perceiving the inherent property of air-to-ground massive MIMO-OFDM channel samples, the DL-based E2E neural network can establish the mapping function from the channel to the beamformer, so that the explicit channel reconstruction can be avoided with reduced pilot and feedback overhead. Besides, practical low-resolution phase shifters (PSs) introduce the quantization constraint, leading to the intractable gradient backpropagation when training the neural network. To mitigate the performance loss caused by the phase quantization error, we adopt the transfer learning strategy to further fine-tune the E2E neural network based on a pre-trained network that assumes the ideal infinite-resolution PSs. Numerical results show that our DL-based schemes have considerable advantages over state-of-the-art schemes.
Adaptive Optimization with Examplewise Gradients
Nov 30, 2021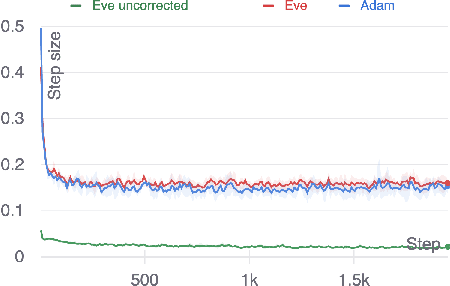

We propose a new, more general approach to the design of stochastic gradient-based optimization methods for machine learning. In this new framework, optimizers assume access to a batch of gradient estimates per iteration, rather than a single estimate. This better reflects the information that is actually available in typical machine learning setups. To demonstrate the usefulness of this generalized approach, we develop Eve, an adaptation of the Adam optimizer which uses examplewise gradients to obtain more accurate second-moment estimates. We provide preliminary experiments, without hyperparameter tuning, which show that the new optimizer slightly outperforms Adam on a small scale benchmark and performs the same or worse on larger scale benchmarks. Further work is needed to refine the algorithm and tune hyperparameters.
Nondestructive Testing of Composite Fibre Materials with Hyperspectral Imaging : Evaluative Studies in the EU H2020 FibreEUse Project
Nov 04, 2021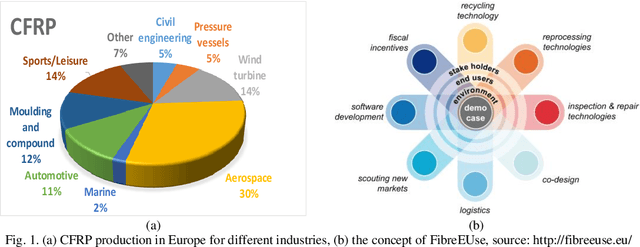
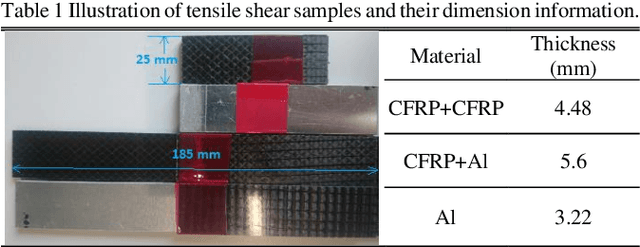
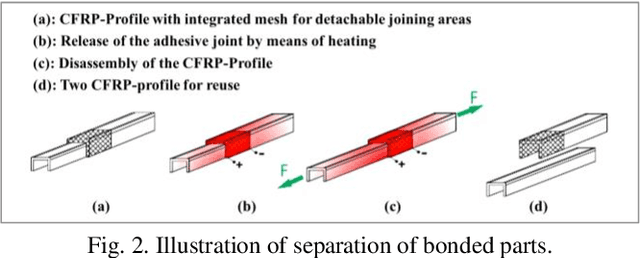

Through capturing spectral data from a wide frequency range along with the spatial information, hyperspectral imaging (HSI) can detect minor differences in terms of temperature, moisture and chemical composition. Therefore, HSI has been successfully applied in various applications, including remote sensing for security and defense, precision agriculture for vegetation and crop monitoring, food/drink, and pharmaceuticals quality control. However, for condition monitoring and damage detection in carbon fibre reinforced polymer (CFRP), the use of HSI is a relatively untouched area, as existing non-destructive testing (NDT) techniques focus mainly on delivering information about physical integrity of structures but not on material composition. To this end, HSI can provide a unique way to tackle this challenge. In this paper, with the use of a near-infrared HSI camera, applications of HSI for the non-destructive inspection of CFRP products are introduced, taking the EU H2020 FibreEUse project as the background. Technical challenges and solutions on three case studies are presented in detail, including adhesive residues detection, surface damage detection and Cobot based automated inspection. Experimental results have fully demonstrated the great potential of HSI and related vision techniques for NDT of CFRP, especially the potential to satisfy the industrial manufacturing environment.
Label Relation Graphs Enhanced Hierarchical Residual Network for Hierarchical Multi-Granularity Classification
Jan 11, 2022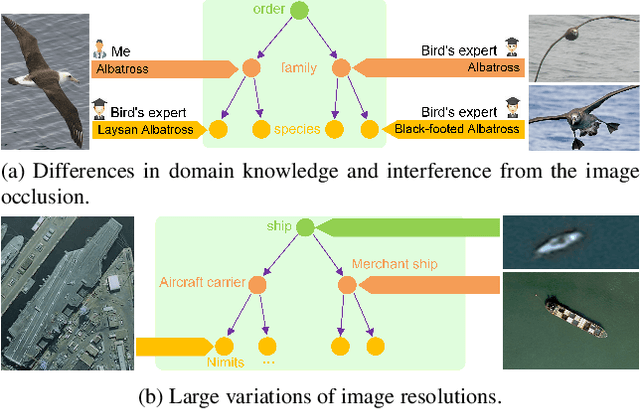

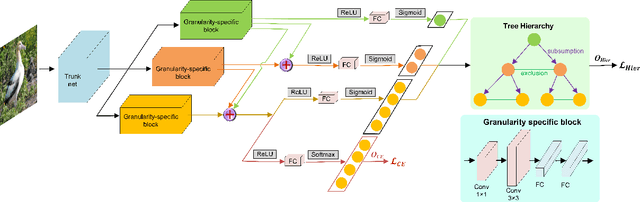
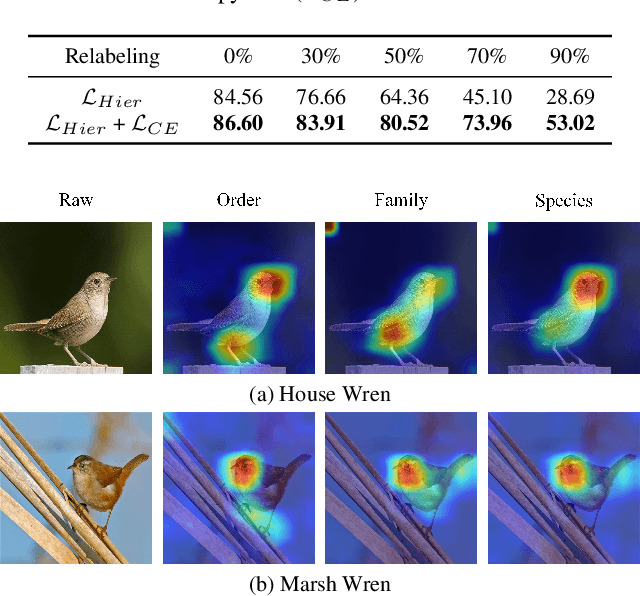
Hierarchical multi-granularity classification (HMC) assigns hierarchical multi-granularity labels to each object and focuses on encoding the label hierarchy, e.g., ["Albatross", "Laysan Albatross"] from coarse-to-fine levels. However, the definition of what is fine-grained is subjective, and the image quality may affect the identification. Thus, samples could be observed at any level of the hierarchy, e.g., ["Albatross"] or ["Albatross", "Laysan Albatross"], and examples discerned at coarse categories are often neglected in the conventional setting of HMC. In this paper, we study the HMC problem in which objects are labeled at any level of the hierarchy. The essential designs of the proposed method are derived from two motivations: (1) learning with objects labeled at various levels should transfer hierarchical knowledge between levels; (2) lower-level classes should inherit attributes related to upper-level superclasses. The proposed combinatorial loss maximizes the marginal probability of the observed ground truth label by aggregating information from related labels defined in the tree hierarchy. If the observed label is at the leaf level, the combinatorial loss further imposes the multi-class cross-entropy loss to increase the weight of fine-grained classification loss. Considering the hierarchical feature interaction, we propose a hierarchical residual network (HRN), in which granularity-specific features from parent levels acting as residual connections are added to features of children levels. Experiments on three commonly used datasets demonstrate the effectiveness of our approach compared to the state-of-the-art HMC approaches and fine-grained visual classification (FGVC) methods exploiting the label hierarchy.
SIDE: Center-based Stereo 3D Detector with Structure-aware Instance Depth Estimation
Aug 24, 2021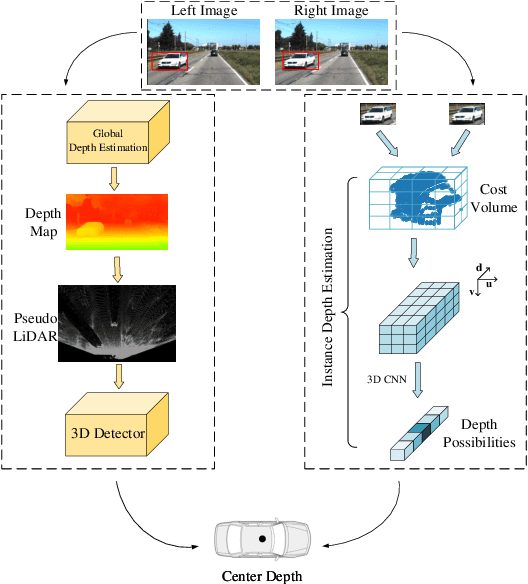
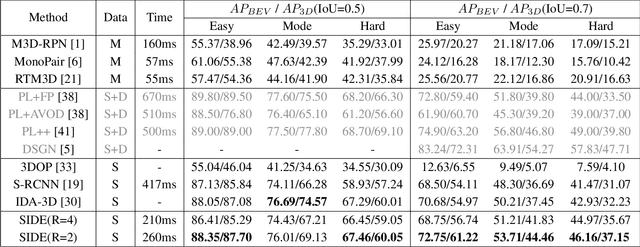
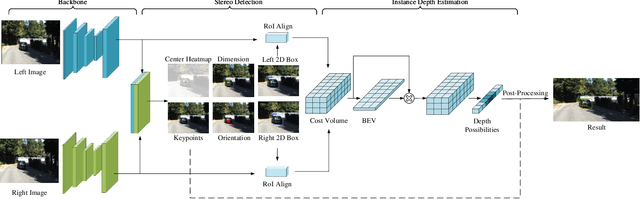
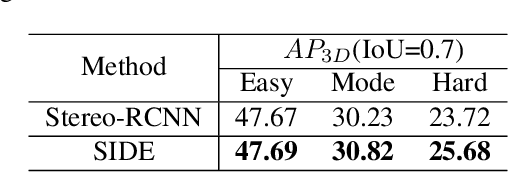
3D detection plays an indispensable role in environment perception. Due to the high cost of commonly used LiDAR sensor, stereo vision based 3D detection, as an economical yet effective setting, attracts more attention recently. For these approaches based on 2D images, accurate depth information is the key to achieve 3D detection, and most existing methods resort to a preliminary stage for depth estimation. They mainly focus on the global depth and neglect the property of depth information in this specific task, namely, sparsity and locality, where exactly accurate depth is only needed for these 3D bounding boxes. Motivated by this finding, we propose a stereo-image based anchor-free 3D detection method, called structure-aware stereo 3D detector (termed as SIDE), where we explore the instance-level depth information via constructing the cost volume from RoIs of each object. Due to the information sparsity of local cost volume, we further introduce match reweighting and structure-aware attention, to make the depth information more concentrated. Experiments conducted on the KITTI dataset show that our method achieves the state-of-the-art performance compared to existing methods without depth map supervision.
MFNet: Multi-class Few-shot Segmentation Network with Pixel-wise Metric Learning
Oct 30, 2021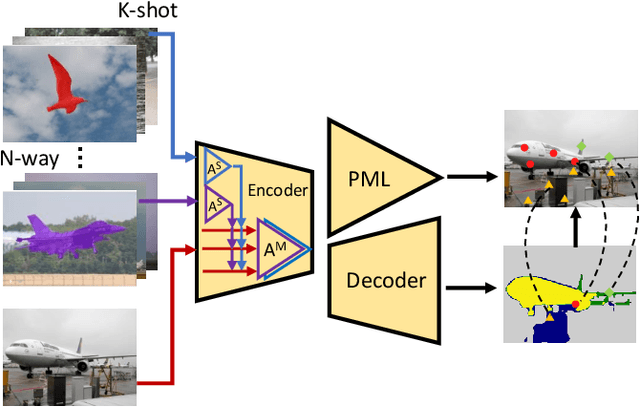
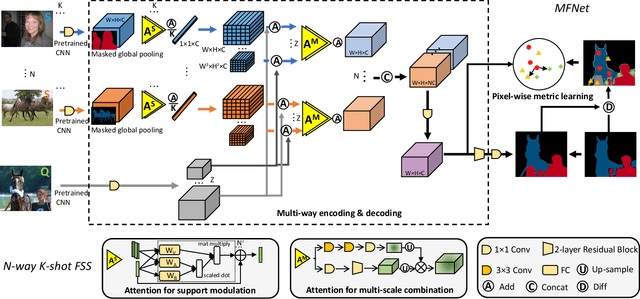
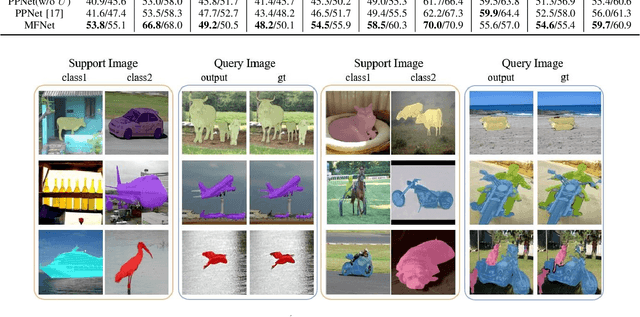
In visual recognition tasks, few-shot learning requires the ability to learn object categories with few support examples. Its recent resurgence in light of the deep learning development is mainly in image classification. This work focuses on few-shot semantic segmentation, which is still a largely unexplored field. A few recent advances are often restricted to single-class few-shot segmentation. In this paper, we first present a novel multi-way encoding and decoding architecture which effectively fuses multi-scale query information and multi-class support information into one query-support embedding; multi-class segmentation is directly decoded upon this embedding. In order for better feature fusion, a multi-level attention mechanism is proposed within the architecture, which includes the attention for support feature modulation and attention for multi-scale combination. Last, to enhance the embedding space learning, an additional pixel-wise metric learning module is devised with triplet loss formulated on the pixel-level embedding of the input image. Extensive experiments on standard benchmarks PASCAL-5^i and COCO-20^i show clear benefits of our method over the state of the art in few-shot segmentation.
A Review on Graph Neural Network Methods in Financial Applications
Nov 27, 2021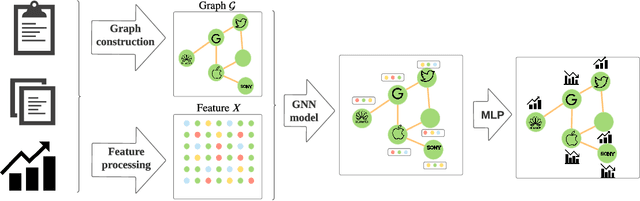

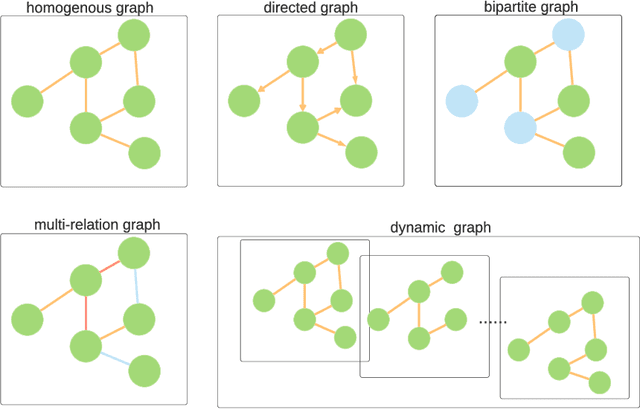
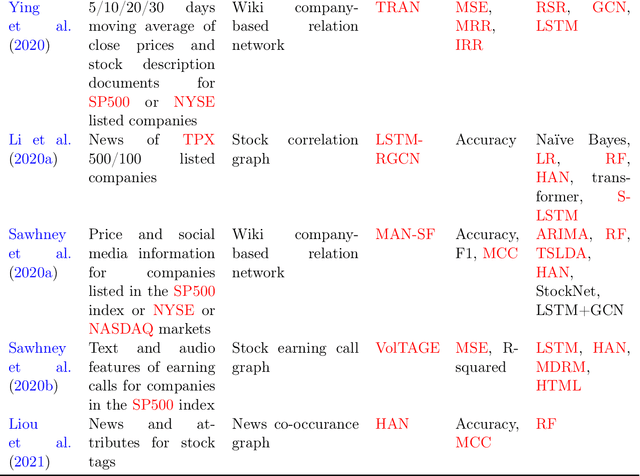
Keeping the individual features and the complicated relations, graph data are widely utilized and investigated. Being able to capture the structural information by updating and aggregating nodes' representations, graph neural network (GNN) models are gaining popularity. In the financial context, the graph is constructed based on real-world data, which leads to complex graph structure and thus requires sophisticated methodology. In this work, we provide a comprehensive review of GNN models in recent financial context. We first categorize the commonly-used financial graphs and summarize the feature processing step for each node. Then we summarize the GNN methodology for each graph type, application in each area, and propose some potential research areas.
Recommender systems based on graph embedding techniques: A comprehensive review
Sep 20, 2021
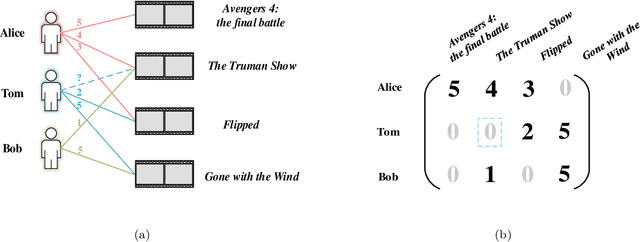

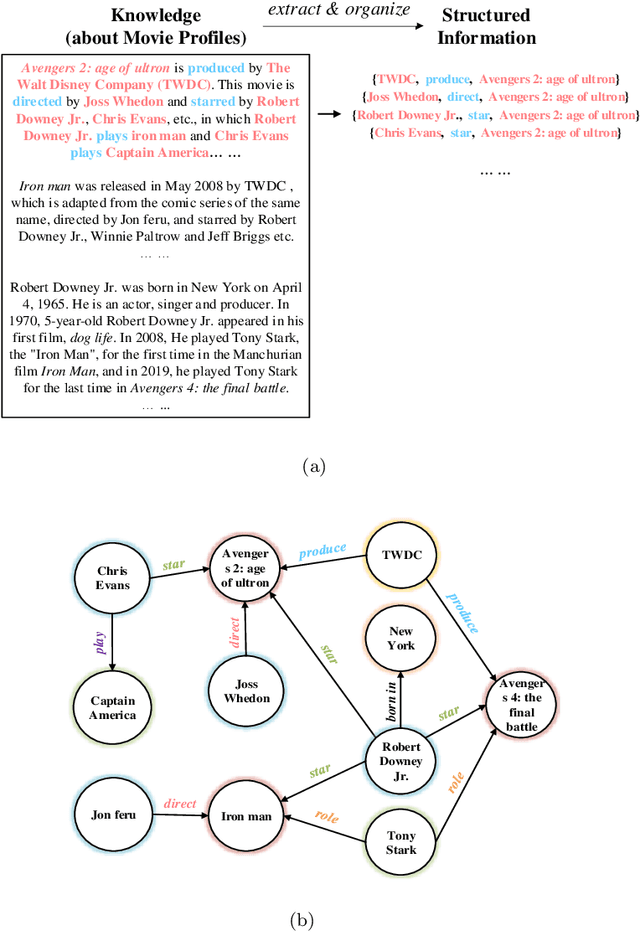
Recommender systems, a pivotal tool to alleviate the information overload problem, aim to predict user's preferred items from millions of candidates by analyzing observed user-item relations. As for tackling the sparsity and cold start problems encountered by recommender systems, uncovering hidden (indirect) user-item relations by employing side information and knowledge to enrich observed information for the recommendation has been proven promising recently; and its performance is largely determined by the scalability of recommendation models in the face of the high complexity and large scale of side information and knowledge. Making great strides towards efficiently utilizing complex and large-scale data, research into graph embedding techniques is a major topic. Equipping recommender systems with graph embedding techniques contributes to outperforming the conventional recommendation implementing directly based on graph topology analysis and has been widely studied these years. This article systematically retrospects graph embedding-based recommendation from embedding techniques for bipartite graphs, general graphs, and knowledge graphs, and proposes a general design pipeline of that. In addition, comparing several representative graph embedding-based recommendation models with the most common-used conventional recommendation models, on simulations, manifests that the conventional models overall outperform the graph embedding-based ones in predicting implicit user-item interactions, revealing the relative weakness of graph embedding-based recommendation in these tasks. To foster future research, this article proposes constructive suggestions on making a trade-off between graph embedding-based recommendation and the conventional recommendation in different tasks as well as some open questions.
A model of semantic completion in generative episodic memory
Nov 26, 2021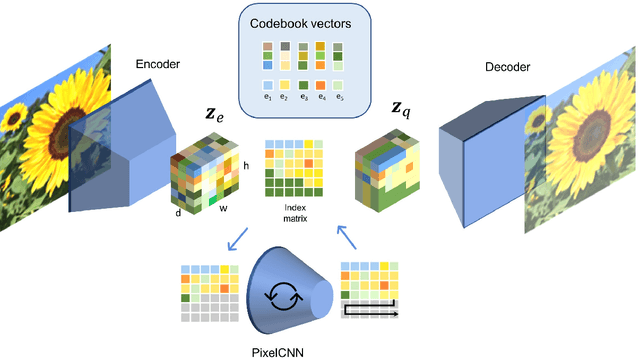
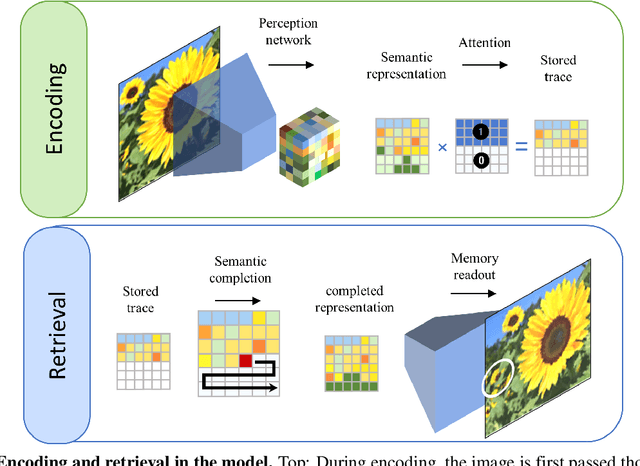
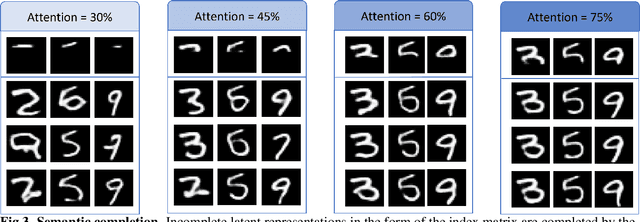
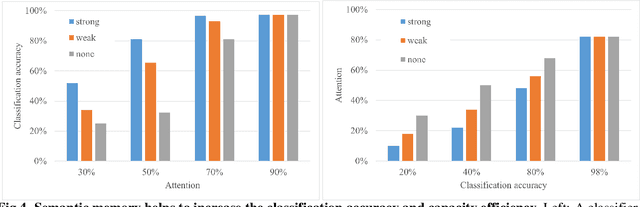
Many different studies have suggested that episodic memory is a generative process, but most computational models adopt a storage view. In this work, we propose a computational model for generative episodic memory. It is based on the central hypothesis that the hippocampus stores and retrieves selected aspects of an episode as a memory trace, which is necessarily incomplete. At recall, the neocortex reasonably fills in the missing information based on general semantic information in a process we call semantic completion. As episodes we use images of digits (MNIST) augmented by different backgrounds representing context. Our model is based on a VQ-VAE which generates a compressed latent representation in form of an index matrix, which still has some spatial resolution. We assume that attention selects some part of the index matrix while others are discarded, this then represents the gist of the episode and is stored as a memory trace. At recall the missing parts are filled in by a PixelCNN, modeling semantic completion, and the completed index matrix is then decoded into a full image by the VQ-VAE. The model is able to complete missing parts of a memory trace in a semantically plausible way up to the point where it can generate plausible images from scratch. Due to the combinatorics in the index matrix, the model generalizes well to images not trained on. Compression as well as semantic completion contribute to a strong reduction in memory requirements and robustness to noise. Finally we also model an episodic memory experiment and can reproduce that semantically congruent contexts are always recalled better than incongruent ones, high attention levels improve memory accuracy in both cases, and contexts that are not remembered correctly are more often remembered semantically congruently than completely wrong.
Light-Field Microscopy for optical imaging of neuronal activity: when model-based methods meet data-driven approaches
Oct 24, 2021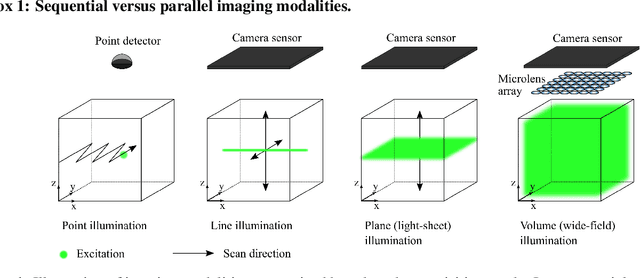
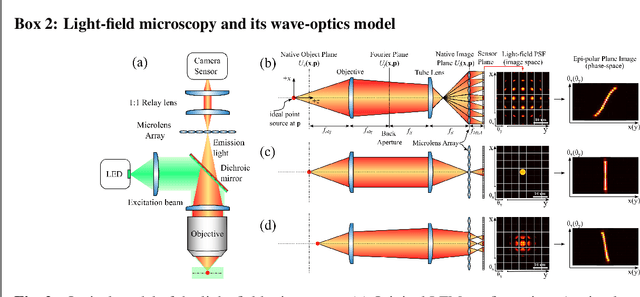
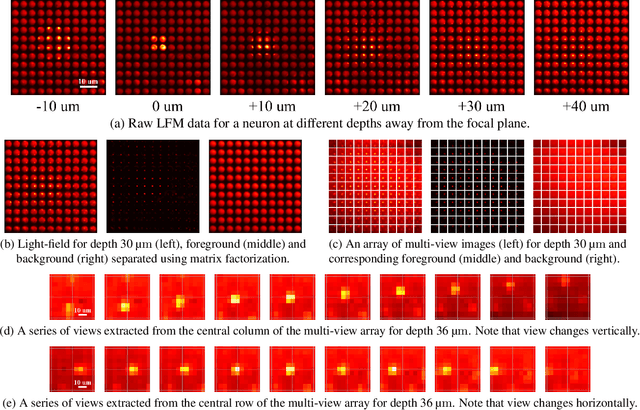
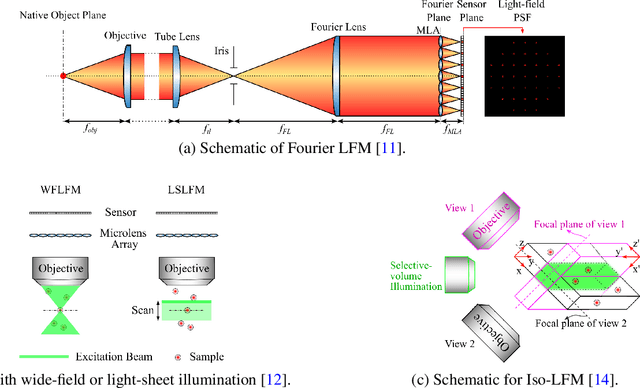
Understanding how networks of neurons process information is one of the key challenges in modern neuroscience. A necessary step to achieve this goal is to be able to observe the dynamics of large populations of neurons over a large area of the brain. Light-field microscopy (LFM), a type of scanless microscope, is a particularly attractive candidate for high-speed three-dimensional (3D) imaging. It captures volumetric information in a single snapshot, allowing volumetric imaging at video frame-rates. Specific features of imaging neuronal activity using LFM call for the development of novel machine learning approaches that fully exploit priors embedded in physics and optics models. Signal processing theory and wave-optics theory could play a key role in filling this gap, and contribute to novel computational methods with enhanced interpretability and generalization by integrating model-driven and data-driven approaches. This paper is devoted to a comprehensive survey to state-of-the-art of computational methods for LFM, with a focus on model-based and data-driven approaches.