 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy Coding of Unordered Data Structures
Aug 16, 2024We present shuffle coding, a general method for optimal compression of sequences of unordered objects using bits-back coding. Data structures that can be compressed using shuffle coding include multisets, graphs, hypergraphs, and others. We release an implementation that can easily be adapted to different data types and statistical models, and demonstrate that our implementation achieves state-of-the-art compression rates on a range of graph datasets including molecular data.
Phenaki: Variable Length Video Generation From Open Domain Textual Description
Oct 05, 2022
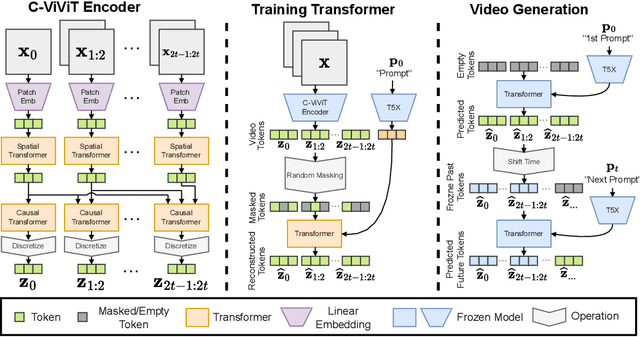


We present Phenaki, a model capable of realistic video synthesis, given a sequence of textual prompts. Generating videos from text is particularly challenging due to the computational cost, limited quantities of high quality text-video data and variable length of videos. To address these issues, we introduce a new model for learning video representation which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text we are using a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, we demonstrate how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to the previous video generation methods, Phenaki can generate arbitrary long videos conditioned on a sequence of prompts (i.e. time variable text or a story) in open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time variable prompts. In addition, compared to the per-frame baselines, the proposed video encoder-decoder computes fewer tokens per video but results in better spatio-temporal consistency.
Adaptive Optimization with Examplewise Gradients
Nov 30, 2021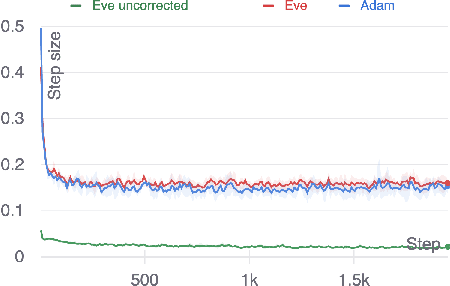

We propose a new, more general approach to the design of stochastic gradient-based optimization methods for machine learning. In this new framework, optimizers assume access to a batch of gradient estimates per iteration, rather than a single estimate. This better reflects the information that is actually available in typical machine learning setups. To demonstrate the usefulness of this generalized approach, we develop Eve, an adaptation of the Adam optimizer which uses examplewise gradients to obtain more accurate second-moment estimates. We provide preliminary experiments, without hyperparameter tuning, which show that the new optimizer slightly outperforms Adam on a small scale benchmark and performs the same or worse on larger scale benchmarks. Further work is needed to refine the algorithm and tune hyperparameters.
HiLLoC: Lossless Image Compression with Hierarchical Latent Variable Models
Dec 20, 2019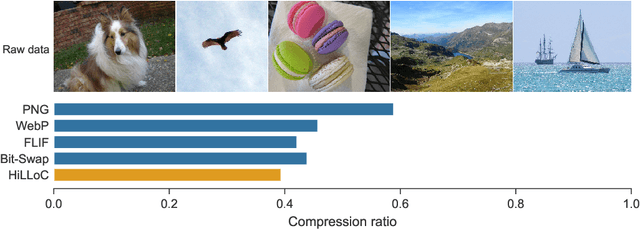
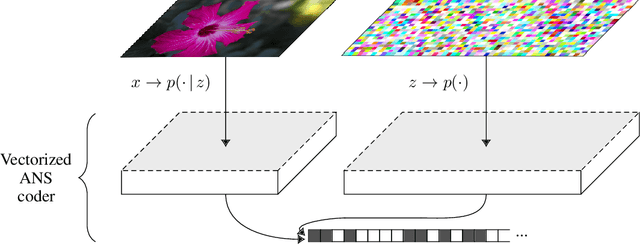
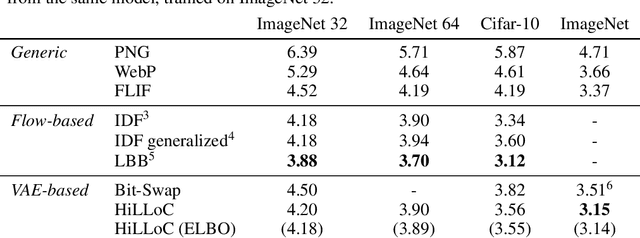
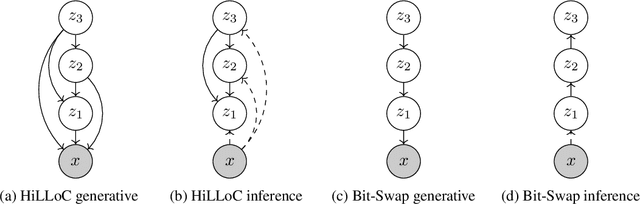
We make the following striking observation: fully convolutional VAE models trained on 32x32 ImageNet can generalize well, not just to 64x64 but also to far larger photographs, with no changes to the model. We use this property, applying fully convolutional models to lossless compression, demonstrating a method to scale the VAE-based 'Bits-Back with ANS' algorithm for lossless compression to large color photographs, and achieving state of the art for compression of full size ImageNet images. We release Craystack, an open source library for convenient prototyping of lossless compression using probabilistic models, along with full implementations of all of our compression results.
Gaussian Mean Field Regularizes by Limiting Learned Information
Feb 12, 2019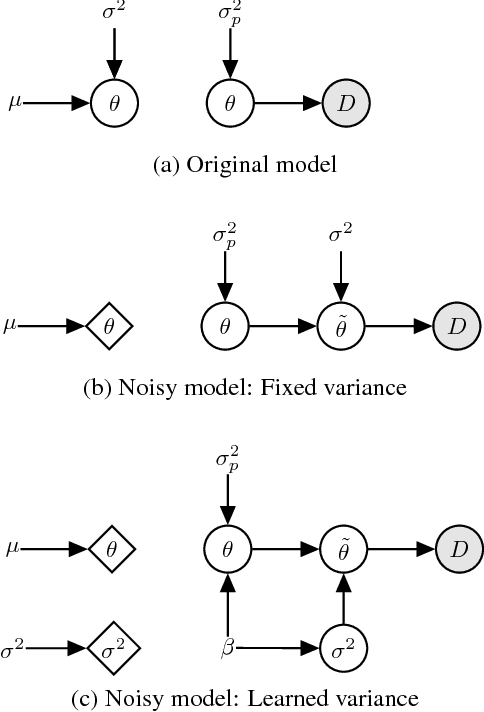
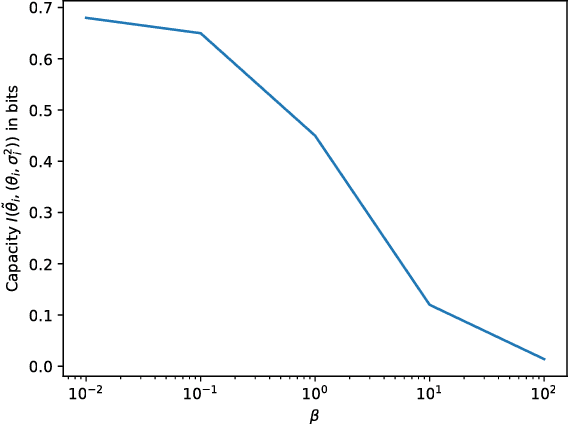
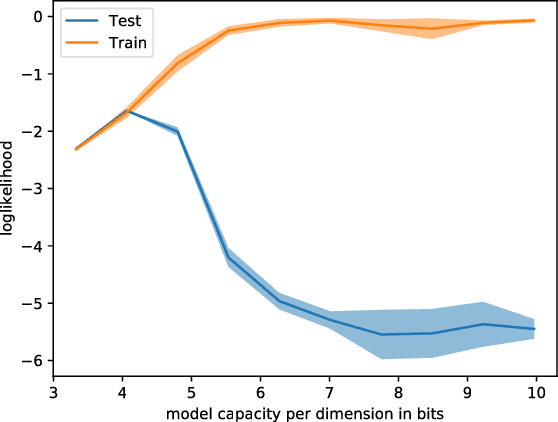
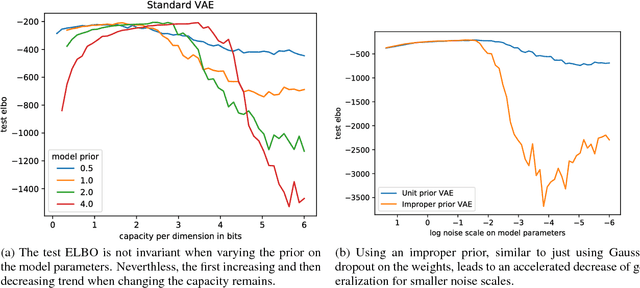
Variational inference with a factorized Gaussian posterior estimate is a widely used approach for learning parameters and hidden variables. Empirically, a regularizing effect can be observed that is poorly understood. In this work, we show how mean field inference improves generalization by limiting mutual information between learned parameters and the data through noise. We quantify a maximum capacity when the posterior variance is either fixed or learned and connect it to generalization error, even when the KL-divergence in the objective is rescaled. Our experiments demonstrate that bounding information between parameters and data effectively regularizes neural networks on both supervised and unsupervised tasks.
Modular Networks: Learning to Decompose Neural Computation
Nov 13, 2018
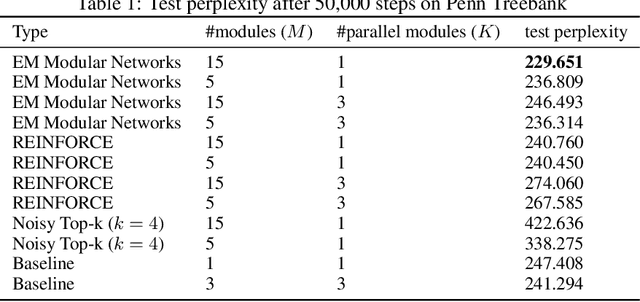
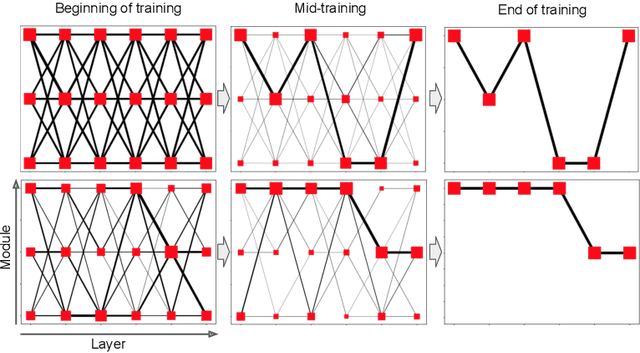

Scaling model capacity has been vital in the success of deep learning. For a typical network, necessary compute resources and training time grow dramatically with model size. Conditional computation is a promising way to increase the number of parameters with a relatively small increase in resources. We propose a training algorithm that flexibly chooses neural modules based on the data to be processed. Both the decomposition and modules are learned end-to-end. In contrast to existing approaches, training does not rely on regularization to enforce diversity in module use. We apply modular networks both to image recognition and language modeling tasks, where we achieve superior performance compared to several baselines. Introspection reveals that modules specialize in interpretable contexts.
Stochastic Variational Optimization
Sep 13, 2018
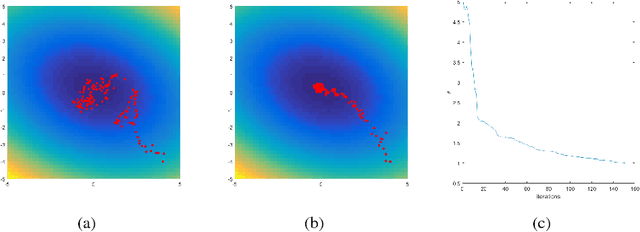
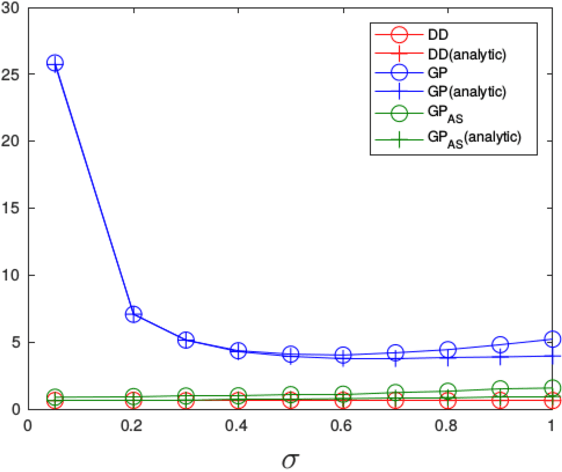
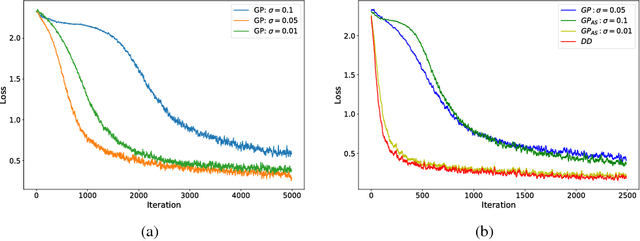
Variational Optimization forms a differentiable upper bound on an objective. We show that approaches such as Natural Evolution Strategies and Gaussian Perturbation, are special cases of Variational Optimization in which the expectations are approximated by Gaussian sampling. These approaches are of particular interest because they are parallelizable. We calculate the approximate bias and variance of the corresponding gradient estimators and demonstrate that using antithetic sampling or a baseline is crucial to mitigate their problems. We contrast these methods with an alternative parallelizable method, namely Directional Derivatives. We conclude that, for differentiable objectives, using Directional Derivatives is preferable to using Variational Optimization to perform parallel Stochastic Gradient Descent.
Transfer Learning for Speech Recognition on a Budget
Jun 01, 2017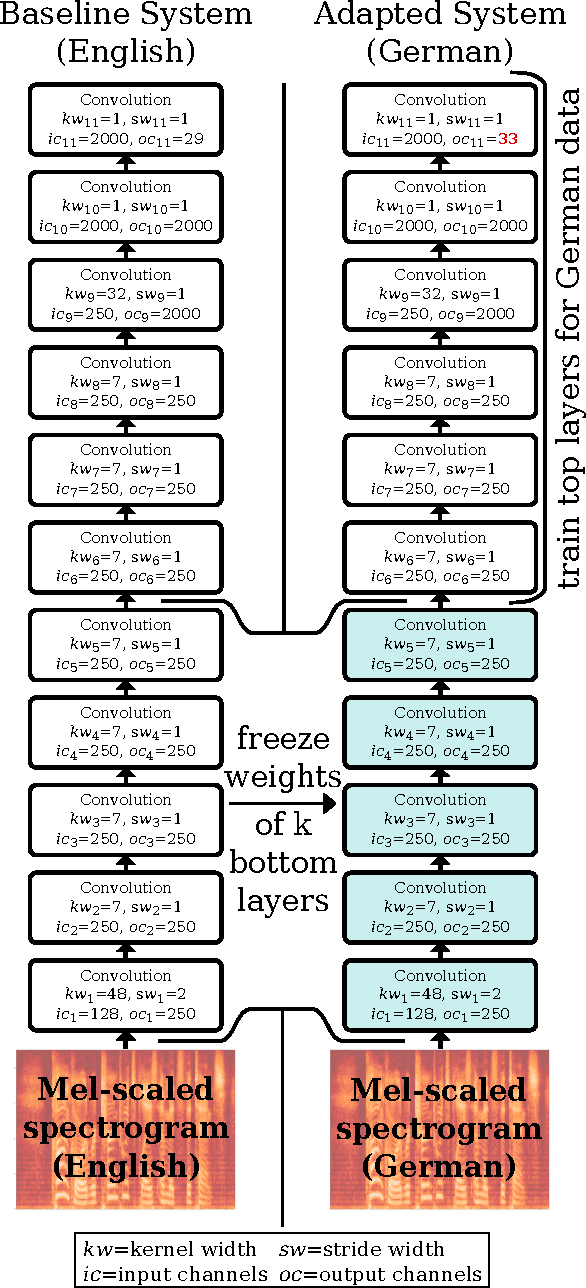
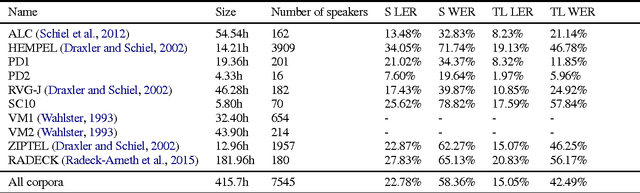
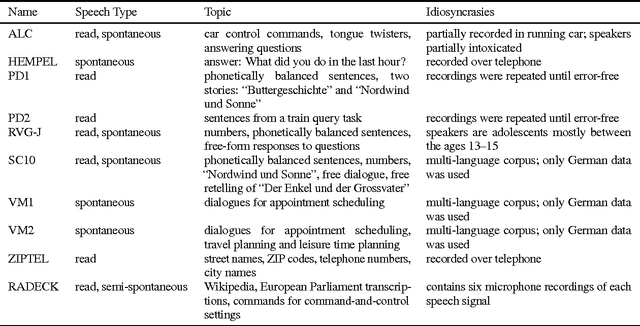
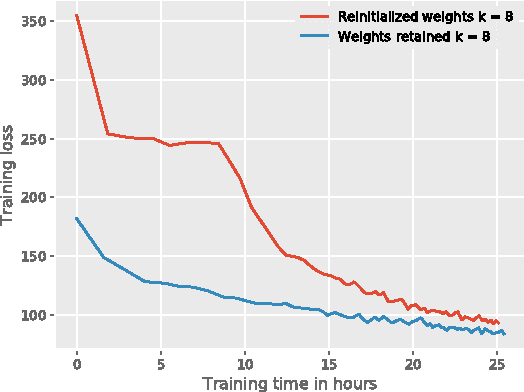
End-to-end training of automated speech recognition (ASR) systems requires massive data and compute resources. We explore transfer learning based on model adaptation as an approach for training ASR models under constrained GPU memory, throughput and training data. We conduct several systematic experiments adapting a Wav2Letter convolutional neural network originally trained for English ASR to the German language. We show that this technique allows faster training on consumer-grade resources while requiring less training data in order to achieve the same accuracy, thereby lowering the cost of training ASR models in other languages. Model introspection revealed that small adaptations to the network's weights were sufficient for good performance, especially for inner layers.