 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
threaTrace: Detecting and Tracing Host-based Threats in Node Level Through Provenance Graph Learning
Nov 08, 2021
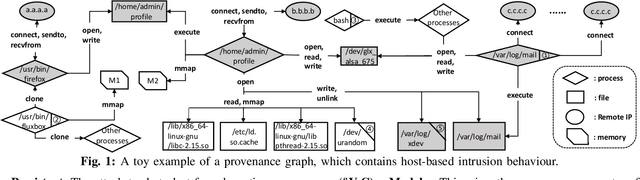
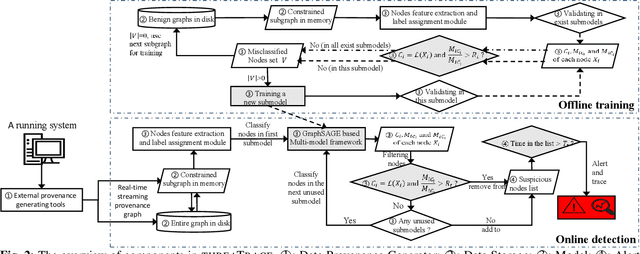
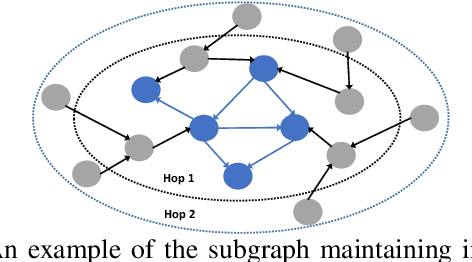
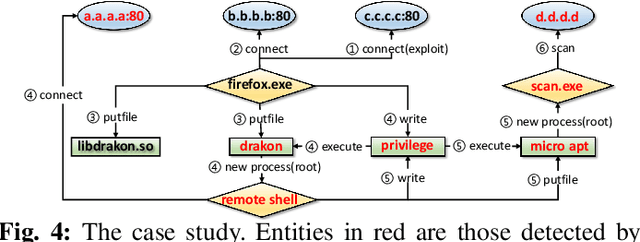
Host-based threats such as Program Attack, Malware Implantation, and Advanced Persistent Threats (APT), are commonly adopted by modern attackers. Recent studies propose leveraging the rich contextual information in data provenance to detect threats in a host. Data provenance is a directed acyclic graph constructed from system audit data. Nodes in a provenance graph represent system entities (e.g., $processes$ and $files$) and edges represent system calls in the direction of information flow. However, previous studies, which extract features of the whole provenance graph, are not sensitive to the small number of threat-related entities and thus result in low performance when hunting stealthy threats. We present threaTrace, an anomaly-based detector that detects host-based threats at system entity level without prior knowledge of attack patterns. We tailor GraphSAGE, an inductive graph neural network, to learn every benign entity's role in a provenance graph. threaTrace is a real-time system, which is scalable of monitoring a long-term running host and capable of detecting host-based intrusion in their early phase. We evaluate threaTrace on three public datasets. The results show that threaTrace outperforms three state-of-the-art host intrusion detection systems.
Bi-CLKT: Bi-Graph Contrastive Learning based Knowledge Tracing
Jan 22, 2022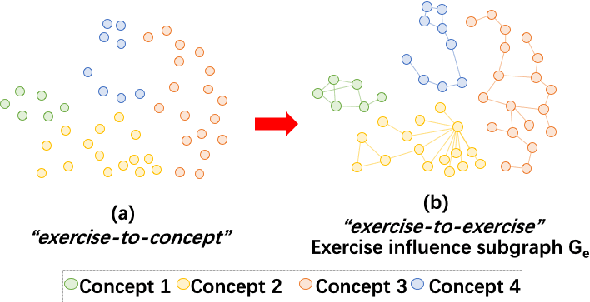
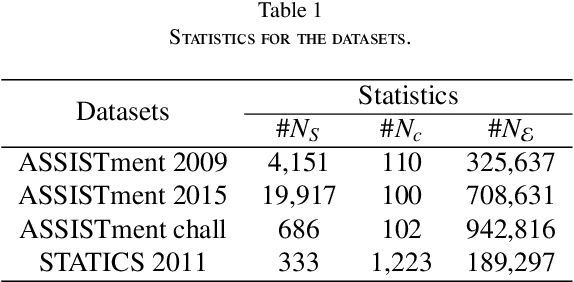
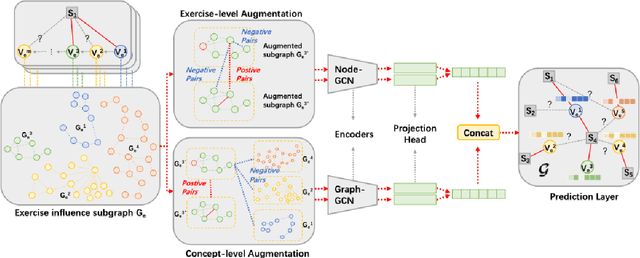
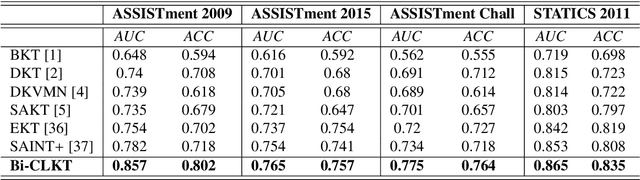
The goal of Knowledge Tracing (KT) is to estimate how well students have mastered a concept based on their historical learning of related exercises. The benefit of knowledge tracing is that students' learning plans can be better organised and adjusted, and interventions can be made when necessary. With the recent rise of deep learning, Deep Knowledge Tracing (DKT) has utilised Recurrent Neural Networks (RNNs) to accomplish this task with some success. Other works have attempted to introduce Graph Neural Networks (GNNs) and redefine the task accordingly to achieve significant improvements. However, these efforts suffer from at least one of the following drawbacks: 1) they pay too much attention to details of the nodes rather than to high-level semantic information; 2) they struggle to effectively establish spatial associations and complex structures of the nodes; and 3) they represent either concepts or exercises only, without integrating them. Inspired by recent advances in self-supervised learning, we propose a Bi-Graph Contrastive Learning based Knowledge Tracing (Bi-CLKT) to address these limitations. Specifically, we design a two-layer contrastive learning scheme based on an "exercise-to-exercise" (E2E) relational subgraph. It involves node-level contrastive learning of subgraphs to obtain discriminative representations of exercises, and graph-level contrastive learning to obtain discriminative representations of concepts. Moreover, we designed a joint contrastive loss to obtain better representations and hence better prediction performance. Also, we explored two different variants, using RNN and memory-augmented neural networks as the prediction layer for comparison to obtain better representations of exercises and concepts respectively. Extensive experiments on four real-world datasets show that the proposed Bi-CLKT and its variants outperform other baseline models.
High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification
Apr 02, 2020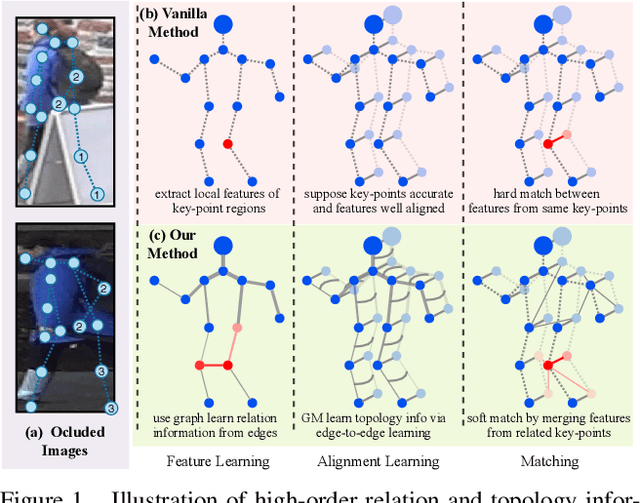
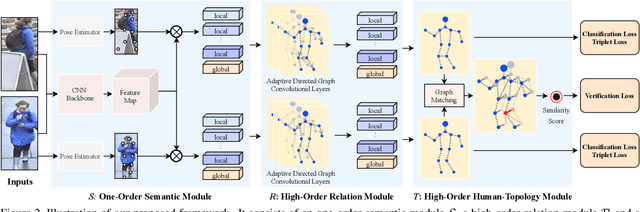
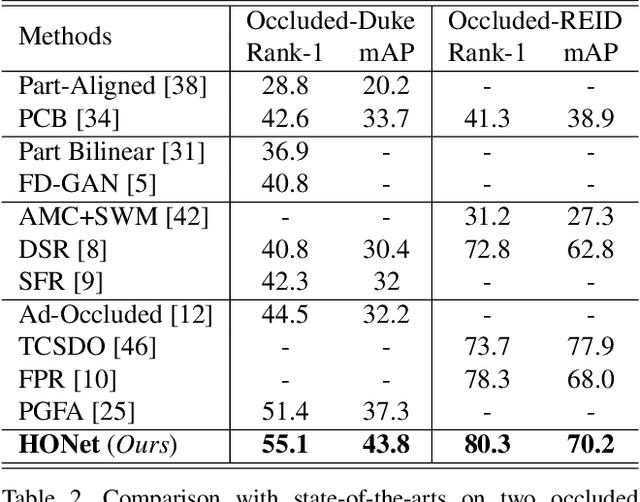
Occluded person re-identification (ReID) aims to match occluded person images to holistic ones across dis-joint cameras. In this paper, we propose a novel framework by learning high-order relation and topology information for discriminative features and robust alignment. At first, we use a CNN backbone and a key-points estimation model to extract semantic local features. Even so, occluded images still suffer from occlusion and outliers. Then, we view the local features of an image as nodes of a graph and propose an adaptive direction graph convolutional (ADGC)layer to pass relation information between nodes. The proposed ADGC layer can automatically suppress the message-passing of meaningless features by dynamically learning di-rection and degree of linkage. When aligning two groups of local features from two images, we view it as a graph matching problem and propose a cross-graph embedded-alignment (CGEA) layer to jointly learn and embed topology information to local features, and straightly predict similarity score. The proposed CGEA layer not only take full use of alignment learned by graph matching but also re-place sensitive one-to-one matching with a robust soft one. Finally, extensive experiments on occluded, partial, and holistic ReID tasks show the effectiveness of our proposed method. Specifically, our framework significantly outperforms state-of-the-art by6.5%mAP scores on Occluded-Duke dataset.
Discovering Differential Features: Adversarial Learning for Information Credibility Evaluation
Sep 16, 2019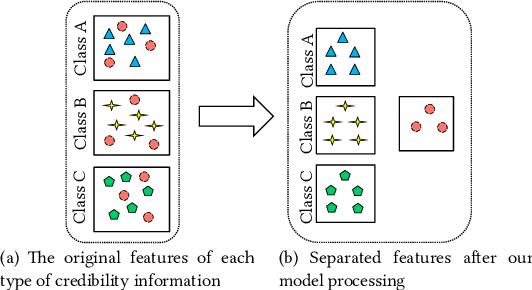
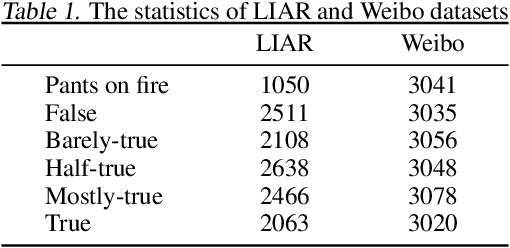
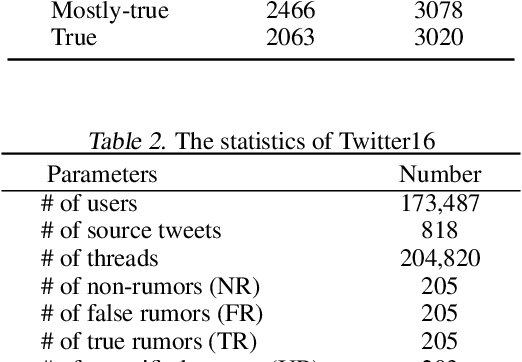
A series of deep learning approaches extract a large number of credibility features to detect fake news on the Internet. However, these extracted features still suffer from many irrelevant and noisy features that restrict severely the performance of the approaches. In this paper, we propose a novel model based on Adversarial Networks and inspirited by the Shared-Private model (ANSP), which aims at reducing common, irrelevant features from the extracted features for information credibility evaluation. Specifically, ANSP involves two tasks: one is to prevent the binary classification of true and false information for capturing common features relying on adversarial networks guided by reinforcement learning. Another extracts credibility features (henceforth, private features) from multiple types of credibility information and compares with the common features through two strategies, i.e., orthogonality constraints and KL-divergence for making the private features more differential. Experiments first on two six-label LIAR and Weibo datasets demonstrate that ANSP achieves the state-of-the-art performance, boosting the accuracy by 2.1%, 3.1%, respectively and then on four-label Twitter16 validate the robustness of the model with 1.8% performance improvements.
HMSG: Heterogeneous Graph Neural Network based on Metapath Subgraph Learning
Sep 07, 2021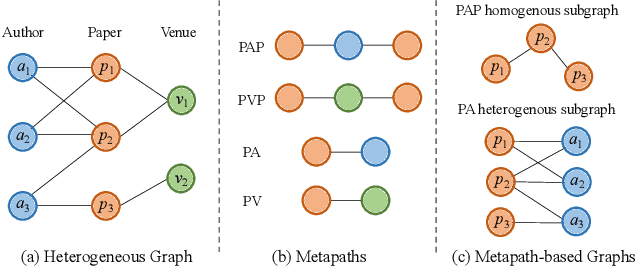

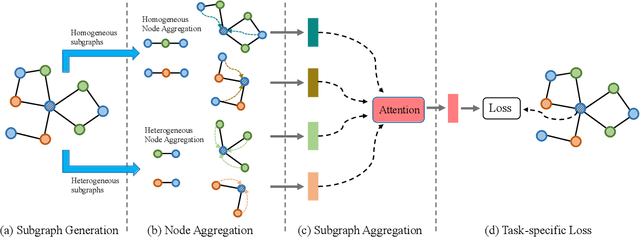
Many real-world data can be represented as heterogeneous graphs with different types of nodes and connections. Heterogeneous graph neural network model aims to embed nodes or subgraphs into low-dimensional vector space for various downstream tasks such as node classification, link prediction, etc. Although several models were proposed recently, they either only aggregate information from the same type of neighbors, or just indiscriminately treat homogeneous and heterogeneous neighbors in the same way. Based on these observations, we propose a new heterogeneous graph neural network model named HMSG to comprehensively capture structural, semantic and attribute information from both homogeneous and heterogeneous neighbors. Specifically, we first decompose the heterogeneous graph into multiple metapath-based homogeneous and heterogeneous subgraphs, and each subgraph associates specific semantic and structural information. Then message aggregation methods are applied to each subgraph independently, so that information can be learned in a more targeted and efficient manner. Through a type-specific attribute transformation, node attributes can also be transferred among different types of nodes. Finally, we fuse information from subgraphs together to get the complete representation. Extensive experiments on several datasets for node classification, node clustering and link prediction tasks show that HMSG achieves the best performance in all evaluation metrics than state-of-the-art baselines.
An analysis of reconstruction noise from undersampled 4D flow MRI
Jan 11, 2022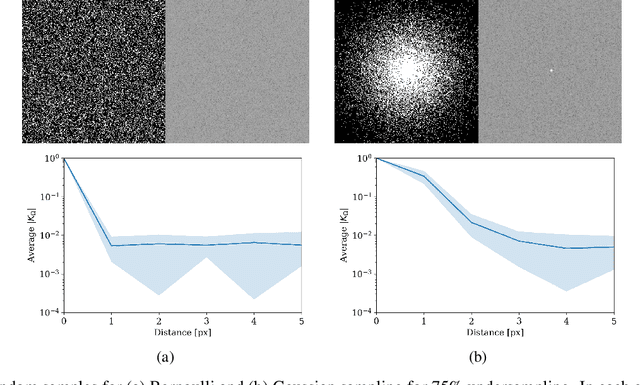


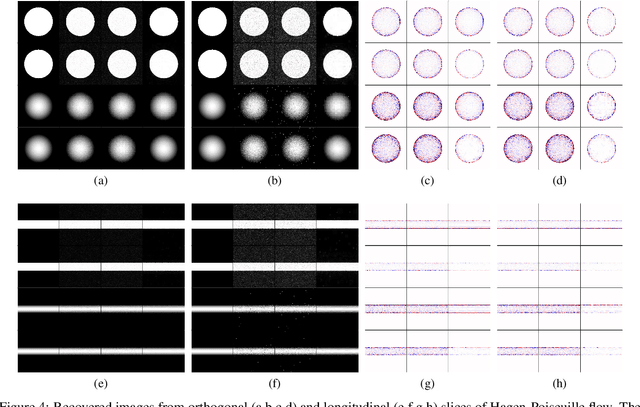
Novel Magnetic Resonance (MR) imaging modalities can quantify hemodynamics but require long acquisition times, precluding its widespread use for early diagnosis of cardiovascular disease. To reduce the acquisition times, reconstruction methods from undersampled measurements are routinely used, that leverage representations designed to increase image compressibility. Reconstructed anatomical and hemodynamic images may present visual artifacts. Although some of these artifact are essentially reconstruction errors, and thus a consequence of undersampling, others may be due to measurement noise or the random choice of the sampled frequencies. Said otherwise, a reconstructed image becomes a random variable, and both its bias and its covariance can lead to visual artifacts; the latter leads to spatial correlations that may be misconstrued for visual information. Although the nature of the former has been studied in the literature, the latter has not received as much attention. In this study, we investigate the theoretical properties of the random perturbations arising from the reconstruction process, and perform a number of numerical experiments on simulated and MR aortic flow. Our results show that the correlation length remains limited to two to three pixels when a Gaussian undersampling pattern is combined with recovery algorithms based on $\ell_1$-norm minimization. However, the correlation length may increase significantly for other undersampling patterns, higher undersampling factors (i.e., 8x or 16x compression), and different reconstruction methods.
Construction Cost Index Forecasting: A Multi-feature Fusion Approach
Aug 18, 2021
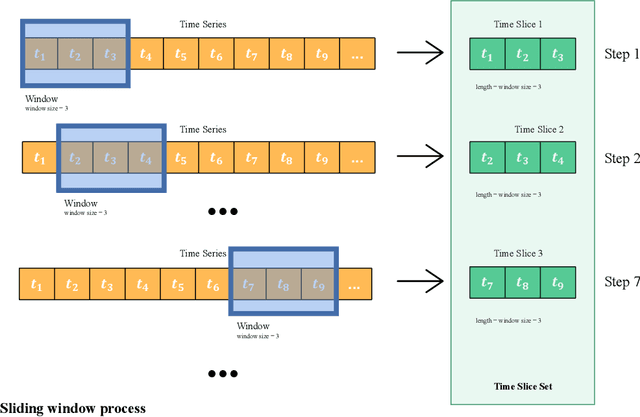

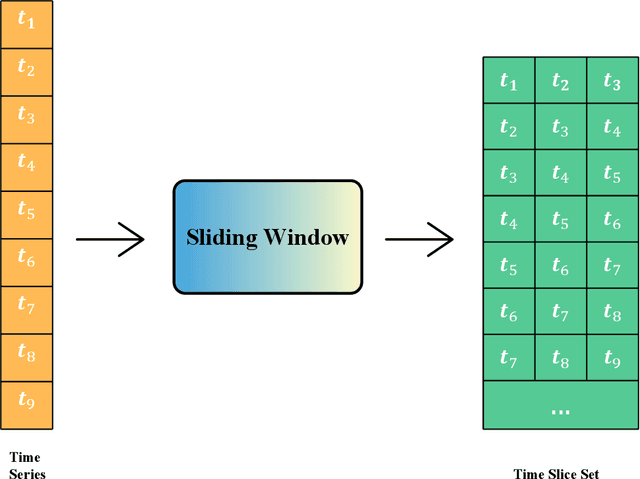
The construction cost index is an important indicator in the construction industry. Predicting CCI has great practical significance. This paper combines information fusion with machine learning, and proposes a Multi-feature Fusion framework for time series forecasting. MFF uses a sliding window algorithm and proposes a function sequence to convert the time sequence into a feature sequence for information fusion. MFF replaces the traditional information method with machine learning to achieve information fusion, which greatly improves the CCI prediction effect. MFF is of great significance to CCI and time series forecasting.
Multiple Residual Dense Networks for Reconfigurable Intelligent Surfaces Cascaded Channel Estimation
Dec 09, 2021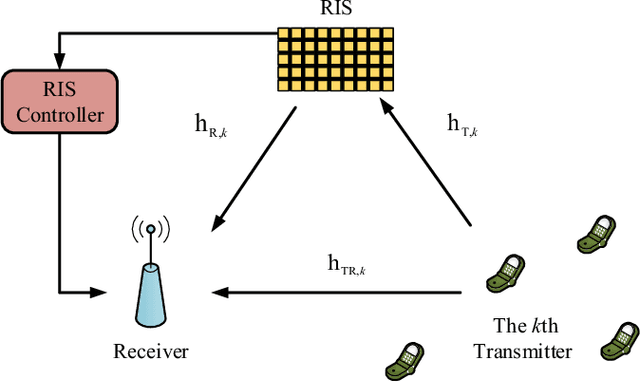
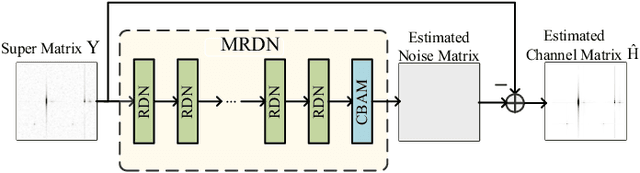
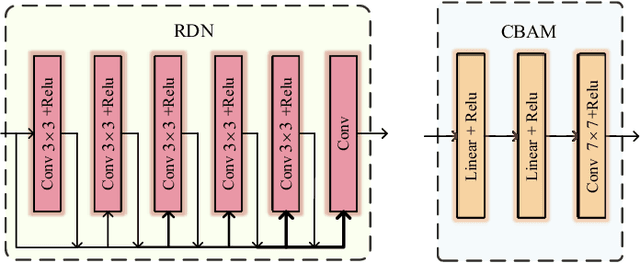
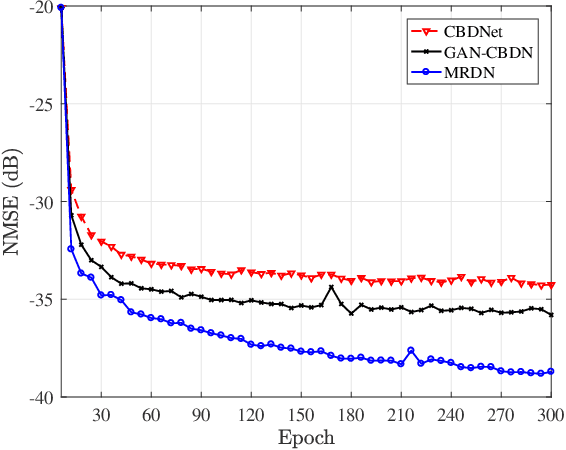
Reconfigurable intelligent surface (RIS) constitutes an essential and promising paradigm that relies programmable wireless environment and provides capability for space-intensive communications, due to the use of low-cost massive reflecting elements over the entire surfaces of man-made structures. However, accurate channel estimation is a fundamental technical prerequisite to achieve the huge performance gains from RIS. By leveraging the low rank structure of RIS channels, three practical residual neural networks, named convolutional blind denoising network, convolutional denoising generative adversarial networks and multiple residual dense network, are proposed to obtain accurate channel state information, which can reflect the impact of different methods on the estimation performance. Simulation results reveal the evolution direction of these three methods and reveal their superior performance compared with existing benchmark schemes.
PoseKernelLifter: Metric Lifting of 3D Human Pose using Sound
Dec 01, 2021
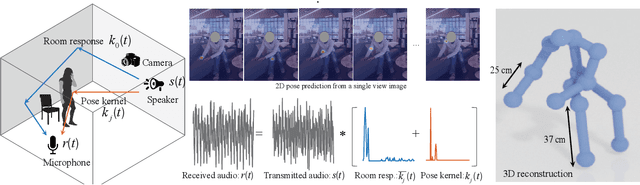
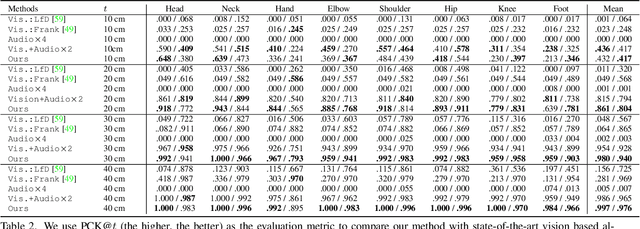
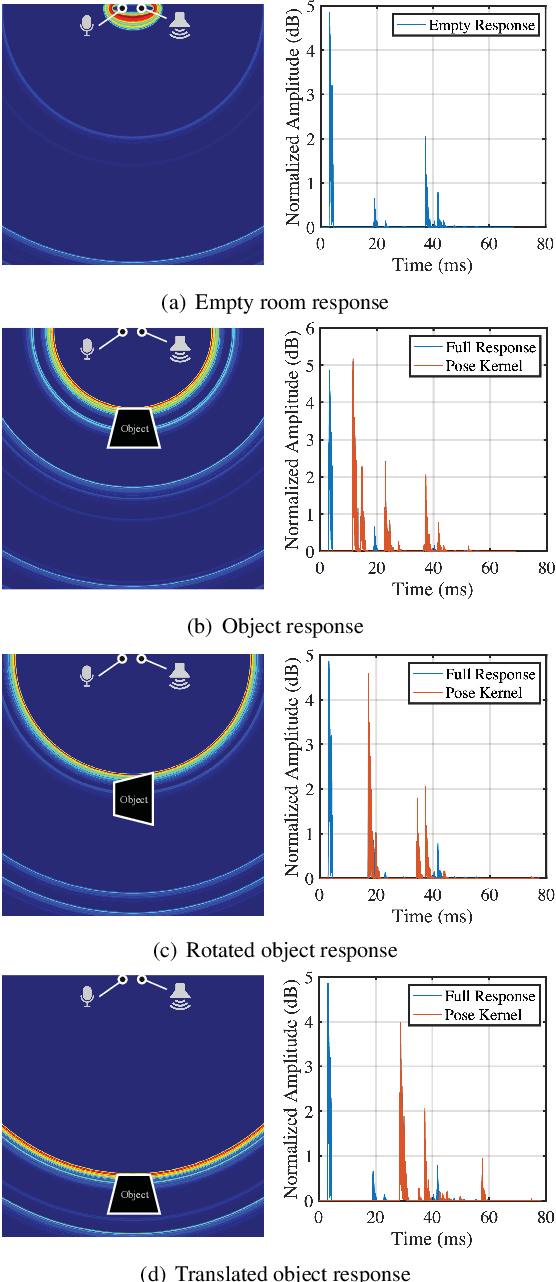
Reconstructing the 3D pose of a person in metric scale from a single view image is a geometrically ill-posed problem. For example, we can not measure the exact distance of a person to the camera from a single view image without additional scene assumptions (e.g., known height). Existing learning based approaches circumvent this issue by reconstructing the 3D pose up to scale. However, there are many applications such as virtual telepresence, robotics, and augmented reality that require metric scale reconstruction. In this paper, we show that audio signals recorded along with an image, provide complementary information to reconstruct the metric 3D pose of the person. The key insight is that as the audio signals traverse across the 3D space, their interactions with the body provide metric information about the body's pose. Based on this insight, we introduce a time-invariant transfer function called pose kernel -- the impulse response of audio signals induced by the body pose. The main properties of the pose kernel are that (1) its envelope highly correlates with 3D pose, (2) the time response corresponds to arrival time, indicating the metric distance to the microphone, and (3) it is invariant to changes in the scene geometry configurations. Therefore, it is readily generalizable to unseen scenes. We design a multi-stage 3D CNN that fuses audio and visual signals and learns to reconstruct 3D pose in a metric scale. We show that our multi-modal method produces accurate metric reconstruction in real world scenes, which is not possible with state-of-the-art lifting approaches including parametric mesh regression and depth regression.
Functional Model of Residential Consumption Elasticity under Dynamic Tariffs
Nov 22, 2021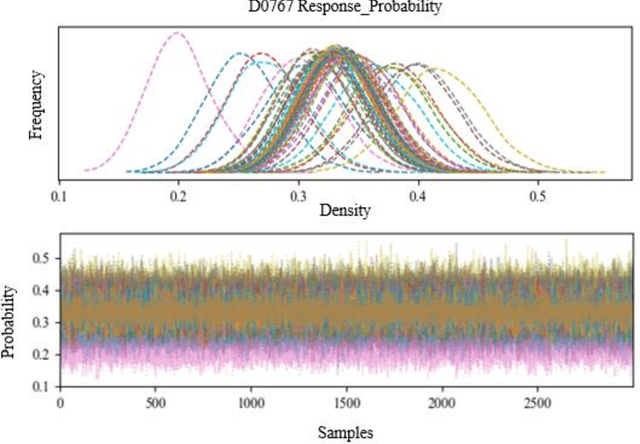
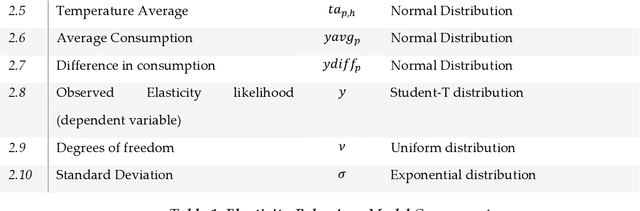
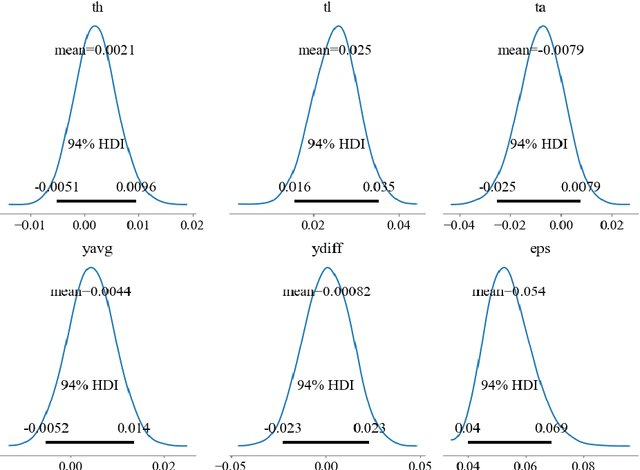
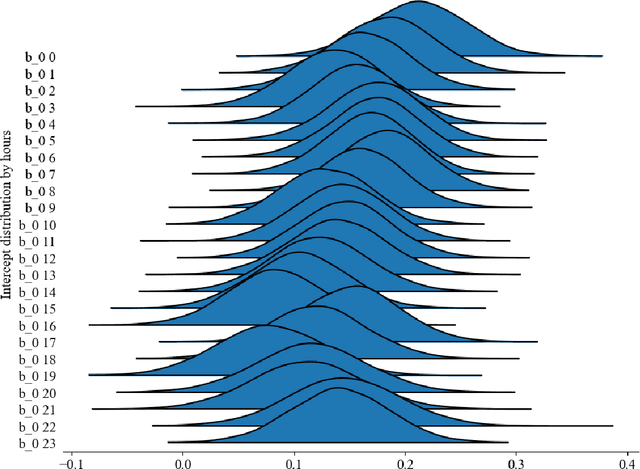
One of the major barriers for the retailers is to understand the consumption elasticity they can expect from their contracted demand response (DR) clients. The current trend of DR products provided by retailers are not consumer-specific, which poses additional barriers for the active engagement of consumers in these programs. The elasticity of consumers demand behavior varies from individual to individual. The utility will benefit from knowing more accurately how changes in its prices will modify the consumption pattern of its clients. This work proposes a functional model for the consumption elasticity of the DR contracted consumers. The model aims to determine the load adjustment the DR consumers can provide to the retailers or utilities for different price levels. The proposed model uses a Bayesian probabilistic approach to identify the actual load adjustment an individual contracted client can provide for different price levels it can experience. The developed framework provides the retailers or utilities with a tool to obtain crucial information on how an individual consumer will respond to different price levels. This approach is able to quantify the likelihood with which the consumer reacts to a DR signal and identify the actual load adjustment an individual contracted DR client provides for different price levels they can experience. This information can be used to maximize the control and reliability of the services the retailer or utility can offer to the System Operators.