 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GenSERP: Large Language Models for Whole Page Presentation
Feb 22, 2024
The advent of large language models (LLMs) brings an opportunity to minimize the effort in search engine result page (SERP) organization. In this paper, we propose GenSERP, a framework that leverages LLMs with vision in a few-shot setting to dynamically organize intermediate search results, including generated chat answers, website snippets, multimedia data, knowledge panels into a coherent SERP layout based on a user's query. Our approach has three main stages: (1) An information gathering phase where the LLM continuously orchestrates API tools to retrieve different types of items, and proposes candidate layouts based on the retrieved items, until it's confident enough to generate the final result. (2) An answer generation phase where the LLM populates the layouts with the retrieved content. In this phase, the LLM adaptively optimize the ranking of items and UX configurations of the SERP. Consequently, it assigns a location on the page to each item, along with the UX display details. (3) A scoring phase where an LLM with vision scores all the generated SERPs based on how likely it can satisfy the user. It then send the one with highest score to rendering. GenSERP features two generation paradigms. First, coarse-to-fine, which allow it to approach optimal layout in a more manageable way, (2) beam search, which give it a better chance to hit the optimal solution compared to greedy decoding. Offline experimental results on real-world data demonstrate how LLMs can contextually organize heterogeneous search results on-the-fly and provide a promising user experience.
Linear-Time Graph Neural Networks for Scalable Recommendations
Feb 21, 2024In an era of information explosion, recommender systems are vital tools to deliver personalized recommendations for users. The key of recommender systems is to forecast users' future behaviors based on previous user-item interactions. Due to their strong expressive power of capturing high-order connectivities in user-item interaction data, recent years have witnessed a rising interest in leveraging Graph Neural Networks (GNNs) to boost the prediction performance of recommender systems. Nonetheless, classic Matrix Factorization (MF) and Deep Neural Network (DNN) approaches still play an important role in real-world large-scale recommender systems due to their scalability advantages. Despite the existence of GNN-acceleration solutions, it remains an open question whether GNN-based recommender systems can scale as efficiently as classic MF and DNN methods. In this paper, we propose a Linear-Time Graph Neural Network (LTGNN) to scale up GNN-based recommender systems to achieve comparable scalability as classic MF approaches while maintaining GNNs' powerful expressiveness for superior prediction accuracy. Extensive experiments and ablation studies are presented to validate the effectiveness and scalability of the proposed algorithm. Our implementation based on PyTorch is available.
Can You Learn Semantics Through Next-Word Prediction? The Case of Entailment
Feb 21, 2024Do LMs infer the semantics of text from co-occurrence patterns in their training data? Merrill et al. (2022) argue that, in theory, probabilities predicted by an optimal LM encode semantic information about entailment relations, but it is unclear whether neural LMs trained on corpora learn entailment in this way because of strong idealizing assumptions made by Merrill et al. In this work, we investigate whether their theory can be used to decode entailment judgments from neural LMs. We find that a test similar to theirs can decode entailment relations between natural sentences, well above random chance, though not perfectly, across many datasets and LMs. This suggests LMs implicitly model aspects of semantics to predict semantic effects on sentence co-occurrence patterns. However, we find the test that predicts entailment in practice works in the opposite direction to the theoretical test. We thus revisit the assumptions underlying the original test, finding its derivation did not adequately account for redundancy in human-written text. We argue that correctly accounting for redundancy related to explanations might derive the observed flipped test and, more generally, improve linguistic theories of human speakers.
An Explainable Transformer-based Model for Phishing Email Detection: A Large Language Model Approach
Feb 21, 2024Phishing email is a serious cyber threat that tries to deceive users by sending false emails with the intention of stealing confidential information or causing financial harm. Attackers, often posing as trustworthy entities, exploit technological advancements and sophistication to make detection and prevention of phishing more challenging. Despite extensive academic research, phishing detection remains an ongoing and formidable challenge in the cybersecurity landscape. Large Language Models (LLMs) and Masked Language Models (MLMs) possess immense potential to offer innovative solutions to address long-standing challenges. In this research paper, we present an optimized, fine-tuned transformer-based DistilBERT model designed for the detection of phishing emails. In the detection process, we work with a phishing email dataset and utilize the preprocessing techniques to clean and solve the imbalance class issues. Through our experiments, we found that our model effectively achieves high accuracy, demonstrating its capability to perform well. Finally, we demonstrate our fine-tuned model using Explainable-AI (XAI) techniques such as Local Interpretable Model-Agnostic Explanations (LIME) and Transformer Interpret to explain how our model makes predictions in the context of text classification for phishing emails.
Unlocking Instructive In-Context Learning with Tabular Prompting for Relational Triple Extraction
Feb 21, 2024The in-context learning (ICL) for relational triple extraction (RTE) has achieved promising performance, but still encounters two key challenges: (1) how to design effective prompts and (2) how to select proper demonstrations. Existing methods, however, fail to address these challenges appropriately. On the one hand, they usually recast RTE task to text-to-text prompting formats, which is unnatural and results in a mismatch between the output format at the pre-training time and the inference time for large language models (LLMs). On the other hand, they only utilize surface natural language features and lack consideration of triple semantics in sample selection. These issues are blocking improved performance in ICL for RTE, thus we aim to tackle prompt designing and sample selection challenges simultaneously. To this end, we devise a tabular prompting for RTE (\textsc{TableIE}) which frames RTE task into a table generation task to incorporate explicit structured information into ICL, facilitating conversion of outputs to RTE structures. Then we propose instructive in-context learning (I$^2$CL) which only selects and annotates a few samples considering internal triple semantics in massive unlabeled samples.
SaGE: Evaluating Moral Consistency in Large Language Models
Feb 21, 2024Despite recent advancements showcasing the impressive capabilities of Large Language Models (LLMs) in conversational systems, we show that even state-of-the-art LLMs are morally inconsistent in their generations, questioning their reliability (and trustworthiness in general). Prior works in LLM evaluation focus on developing ground-truth data to measure accuracy on specific tasks. However, for moral scenarios that often lack universally agreed-upon answers, consistency in model responses becomes crucial for their reliability. To address this issue, we propose an information-theoretic measure called Semantic Graph Entropy (SaGE), grounded in the concept of "Rules of Thumb" (RoTs) to measure a model's moral consistency. RoTs are abstract principles learned by a model and can help explain their decision-making strategies effectively. To this extent, we construct the Moral Consistency Corpus (MCC), containing 50K moral questions, responses to them by LLMs, and the RoTs that these models followed. Furthermore, to illustrate the generalizability of SaGE, we use it to investigate LLM consistency on two popular datasets -- TruthfulQA and HellaSwag. Our results reveal that task-accuracy and consistency are independent problems, and there is a dire need to investigate these issues further.
Hybrid Reasoning Based on Large Language Models for Autonomous Car Driving
Feb 21, 2024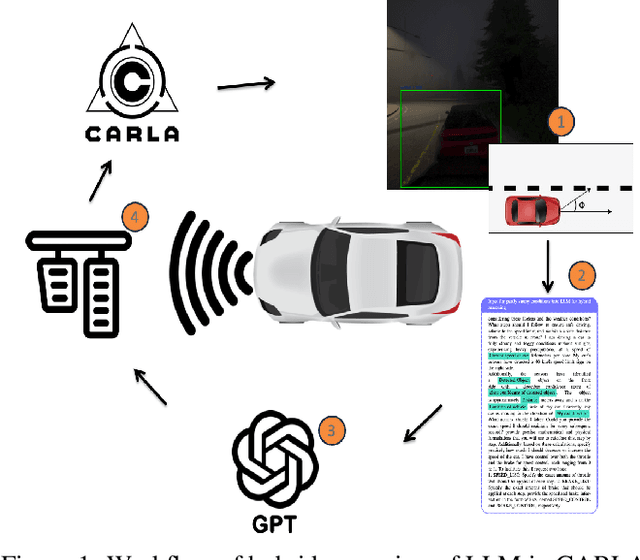
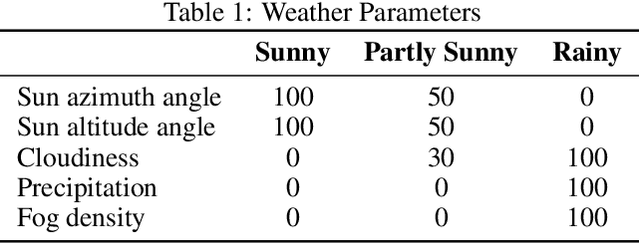
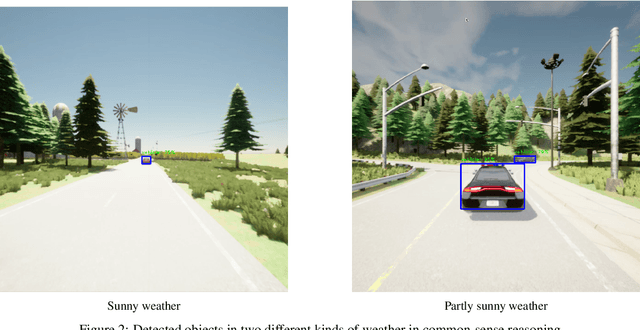

Large Language Models (LLMs) have garnered significant attention for their ability to understand text and images, generate human-like text, and perform complex reasoning tasks. However, their ability to generalize this advanced reasoning with a combination of natural language text for decision-making in dynamic situations requires further exploration. In this study, we investigate how well LLMs can adapt and apply a combination of arithmetic and common-sense reasoning, particularly in autonomous driving scenarios. We hypothesize that LLMs hybrid reasoning abilities can improve autonomous driving by enabling them to analyze detected object and sensor data, understand driving regulations and physical laws, and offer additional context. This addresses complex scenarios, like decisions in low visibility (due to weather conditions), where traditional methods might fall short. We evaluated Large Language Models (LLMs) based on accuracy by comparing their answers with human-generated ground truth inside CARLA. The results showed that when a combination of images (detected objects) and sensor data is fed into the LLM, it can offer precise information for brake and throttle control in autonomous vehicles across various weather conditions. This formulation and answers can assist in decision-making for auto-pilot systems.
Analysis of Multi-Source Language Training in Cross-Lingual Transfer
Feb 21, 2024The successful adaptation of multilingual language models (LMs) to a specific language-task pair critically depends on the availability of data tailored for that condition. While cross-lingual transfer (XLT) methods have contributed to addressing this data scarcity problem, there still exists ongoing debate about the mechanisms behind their effectiveness. In this work, we focus on one of promising assumptions about inner workings of XLT, that it encourages multilingual LMs to place greater emphasis on language-agnostic or task-specific features. We test this hypothesis by examining how the patterns of XLT change with a varying number of source languages involved in the process. Our experimental findings show that the use of multiple source languages in XLT-a technique we term Multi-Source Language Training (MSLT)-leads to increased mingling of embedding spaces for different languages, supporting the claim that XLT benefits from making use of language-independent information. On the other hand, we discover that using an arbitrary combination of source languages does not always guarantee better performance. We suggest simple heuristics for identifying effective language combinations for MSLT and empirically prove its effectiveness.
SRNDiff: Short-term Rainfall Nowcasting with Condition Diffusion Model
Feb 21, 2024Diffusion models are widely used in image generation because they can generate high-quality and realistic samples. This is in contrast to generative adversarial networks (GANs) and variational autoencoders (VAEs), which have some limitations in terms of image quality.We introduce the diffusion model to the precipitation forecasting task and propose a short-term precipitation nowcasting with condition diffusion model based on historical observational data, which is referred to as SRNDiff. By incorporating an additional conditional decoder module in the denoising process, SRNDiff achieves end-to-end conditional rainfall prediction. SRNDiff is composed of two networks: a denoising network and a conditional Encoder network. The conditional network is composed of multiple independent UNet networks. These networks extract conditional feature maps at different resolutions, providing accurate conditional information that guides the diffusion model for conditional generation.SRNDiff surpasses GANs in terms of prediction accuracy, although it requires more computational resources.The SRNDiff model exhibits higher stability and efficiency during training than GANs-based approaches, and generates high-quality precipitation distribution samples that better reflect future actual precipitation conditions. This fully validates the advantages and potential of diffusion models in precipitation forecasting, providing new insights for enhancing rainfall prediction.
Large Language Models for Data Annotation: A Survey
Feb 21, 2024Data annotation is the labeling or tagging of raw data with relevant information, essential for improving the efficacy of machine learning models. The process, however, is labor-intensive and expensive. The emergence of advanced Large Language Models (LLMs), exemplified by GPT-4, presents an unprecedented opportunity to revolutionize and automate the intricate process of data annotation. While existing surveys have extensively covered LLM architecture, training, and general applications, this paper uniquely focuses on their specific utility for data annotation. This survey contributes to three core aspects: LLM-Based Data Annotation, Assessing LLM-generated Annotations, and Learning with LLM-generated annotations. Furthermore, the paper includes an in-depth taxonomy of methodologies employing LLMs for data annotation, a comprehensive review of learning strategies for models incorporating LLM-generated annotations, and a detailed discussion on primary challenges and limitations associated with using LLMs for data annotation. As a key guide, this survey aims to direct researchers and practitioners in exploring the potential of the latest LLMs for data annotation, fostering future advancements in this critical domain. We provide a comprehensive papers list at \url{https://github.com/Zhen-Tan-dmml/LLM4Annotation.git}.