 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeRe: Towards Efficient Anti-Forgetting in Continual Learning of LLM via General Samples Replay
Aug 06, 2025The continual learning capability of large language models (LLMs) is crucial for advancing artificial general intelligence. However, continual fine-tuning LLMs across various domains often suffers from catastrophic forgetting, characterized by: 1) significant forgetting of their general capabilities, and 2) sharp performance declines in previously learned tasks. To simultaneously address both issues in a simple yet stable manner, we propose General Sample Replay (GeRe), a framework that use usual pretraining texts for efficient anti-forgetting. Beyond revisiting the most prevalent replay-based practices under GeRe, we further leverage neural states to introduce a enhanced activation states constrained optimization method using threshold-based margin (TM) loss, which maintains activation state consistency during replay learning. We are the first to validate that a small, fixed set of pre-collected general replay samples is sufficient to resolve both concerns--retaining general capabilities while promoting overall performance across sequential tasks. Indeed, the former can inherently facilitate the latter. Through controlled experiments, we systematically compare TM with different replay strategies under the GeRe framework, including vanilla label fitting, logit imitation via KL divergence and feature imitation via L1/L2 losses. Results demonstrate that TM consistently improves performance and exhibits better robustness. Our work paves the way for efficient replay of LLMs for the future. Our code and data are available at https://github.com/Qznan/GeRe.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
A Little Goes a Long Way: Efficient Long Context Training and Inference with Partial Contexts
Oct 02, 2024



Training and serving long-context large language models (LLMs) incurs substantial overhead. To address this, two critical steps are often required: a pretrained LLM typically undergoes a separate stage for context length extension by training on long-context data, followed by architectural modifications to reduce the overhead of KV cache during serving. This paper argues that integrating length extension with a GPU-friendly KV cache reduction architecture not only reduces training overhead during length extension, but also achieves better long-context performance. This leads to our proposed LongGen, which finetunes a pretrained LLM into an efficient architecture during length extension. LongGen builds on three key insights: (1) Sparse attention patterns, such as window attention (attending to recent tokens), attention sink (initial ones), and blockwise sparse attention (strided token blocks) are well-suited for building efficient long-context models, primarily due to their GPU-friendly memory access patterns, enabling efficiency gains not just theoretically but in practice as well. (2) It is essential for the model to have direct access to all tokens. A hybrid architecture with 1/3 full attention layers and 2/3 efficient ones achieves a balanced trade-off between efficiency and long-context performance. (3) Lightweight training on 5B long-context data is sufficient to extend the hybrid model's context length from 4K to 128K. We evaluate LongGen on both Llama-2 7B and Llama-2 70B, demonstrating its effectiveness across different scales. During training with 128K-long contexts, LongGen achieves 1.55x training speedup and reduces wall-clock time by 36%, compared to a full-attention baseline. During inference, LongGen reduces KV cache memory by 62%, achieving 1.67x prefilling speedup and 1.41x decoding speedup.
Efficient LLM Training and Serving with Heterogeneous Context Sharding among Attention Heads
Jul 25, 2024



Existing LLM training and inference frameworks struggle in boosting efficiency with sparsity while maintaining the integrity of context and model architecture. Inspired by the sharding concept in database and the fact that attention parallelizes over heads on accelerators, we propose Sparsely-Sharded (S2) Attention, an attention algorithm that allocates heterogeneous context partitions for different attention heads to divide and conquer. S2-Attention enforces each attention head to only attend to a partition of contexts following a strided sparsity pattern, while the full context is preserved as the union of all the shards. As attention heads are processed in separate thread blocks, the context reduction for each head can thus produce end-to-end speed-up and memory reduction. At inference, LLMs trained with S2-Attention can then take the KV cache reduction as free meals with guaranteed model quality preserve. In experiments, we show S2-Attentioncan provide as much as (1) 25.3X wall-clock attention speed-up over FlashAttention-2, resulting in 6X reduction in end-to-end training time and 10X inference latency, (2) on-par model training quality compared to default attention, (3)perfect needle retrieval accuracy over 32K context window. On top of the algorithm, we build DKernel, an LLM training and inference kernel library that allows users to customize sparsity patterns for their own models. We open-sourced DKerneland make it compatible with Megatron, Pytorch, and vLLM.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
GenSERP: Large Language Models for Whole Page Presentation
Feb 22, 2024



The advent of large language models (LLMs) brings an opportunity to minimize the effort in search engine result page (SERP) organization. In this paper, we propose GenSERP, a framework that leverages LLMs with vision in a few-shot setting to dynamically organize intermediate search results, including generated chat answers, website snippets, multimedia data, knowledge panels into a coherent SERP layout based on a user's query. Our approach has three main stages: (1) An information gathering phase where the LLM continuously orchestrates API tools to retrieve different types of items, and proposes candidate layouts based on the retrieved items, until it's confident enough to generate the final result. (2) An answer generation phase where the LLM populates the layouts with the retrieved content. In this phase, the LLM adaptively optimize the ranking of items and UX configurations of the SERP. Consequently, it assigns a location on the page to each item, along with the UX display details. (3) A scoring phase where an LLM with vision scores all the generated SERPs based on how likely it can satisfy the user. It then send the one with highest score to rendering. GenSERP features two generation paradigms. First, coarse-to-fine, which allow it to approach optimal layout in a more manageable way, (2) beam search, which give it a better chance to hit the optimal solution compared to greedy decoding. Offline experimental results on real-world data demonstrate how LLMs can contextually organize heterogeneous search results on-the-fly and provide a promising user experience.
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs
Oct 07, 2023



In this study, we introduce adaptive KV cache compression, a plug-and-play method that reduces the memory footprint of generative inference for Large Language Models (LLMs). Different from the conventional KV cache that retains key and value vectors for all context tokens, we conduct targeted profiling to discern the intrinsic structure of attention modules. Based on the recognized structure, we then construct the KV cache in an adaptive manner: evicting long-range contexts on attention heads emphasizing local contexts, discarding non-special tokens on attention heads centered on special tokens, and only employing the standard KV cache for attention heads that broadly attend to all tokens. Moreover, with the lightweight attention profiling used to guide the construction of the adaptive KV cache, FastGen can be deployed without resource-intensive fine-tuning or re-training. In our experiments across various asks, FastGen demonstrates substantial reduction on GPU memory consumption with negligible generation quality loss. We will release our code and the compatible CUDA kernel for reproducibility.
A Neural Span-Based Continual Named Entity Recognition Model
Feb 23, 2023



Named Entity Recognition (NER) models capable of Continual Learning (CL) are realistically valuable in areas where entity types continuously increase (e.g., personal assistants). Meanwhile the learning paradigm of NER advances to new patterns such as the span-based methods. However, its potential to CL has not been fully explored. In this paper, we propose SpanKL1, a simple yet effective Span-based model with Knowledge distillation (KD) to preserve memories and multi-Label prediction to prevent conflicts in CL-NER. Unlike prior sequence labeling approaches, the inherently independent modeling in span and entity level with the designed coherent optimization on SpanKL promotes its learning at each incremental step and mitigates the forgetting. Experiments on synthetic CL datasets derived from OntoNotes and Few-NERD show that SpanKL significantly outperforms previous SoTA in many aspects, and obtains the smallest gap from CL to the upper bound revealing its high practiced value.
Towards Disentangling Relevance and Bias in Unbiased Learning to Rank
Dec 28, 2022



Unbiased learning to rank (ULTR) studies the problem of mitigating various biases from implicit user feedback data such as clicks, and has been receiving considerable attention recently. A popular ULTR approach for real-world applications uses a two-tower architecture, where click modeling is factorized into a relevance tower with regular input features, and a bias tower with bias-relevant inputs such as the position of a document. A successful factorization will allow the relevance tower to be exempt from biases. In this work, we identify a critical issue that existing ULTR methods ignored - the bias tower can be confounded with the relevance tower via the underlying true relevance. In particular, the positions were determined by the logging policy, i.e., the previous production model, which would possess relevance information. We give both theoretical analysis and empirical results to show the negative effects on relevance tower due to such a correlation. We then propose three methods to mitigate the negative confounding effects by better disentangling relevance and bias. Empirical results on both controlled public datasets and a large-scale industry dataset show the effectiveness of the proposed approaches.
Unifying Model Explainability and Robustness for Joint Text Classification and Rationale Extraction
Dec 20, 2021
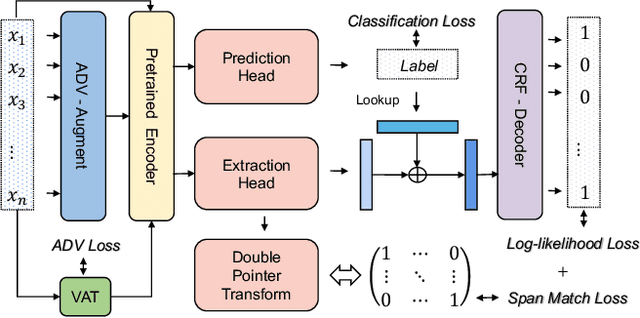
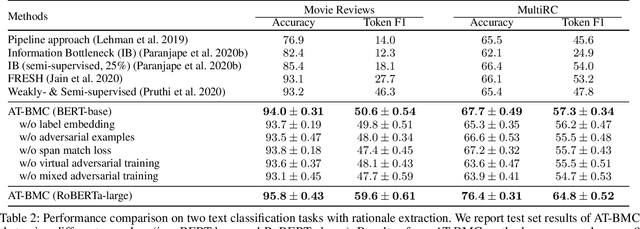
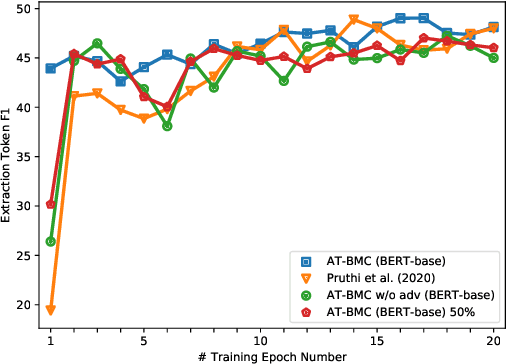
Recent works have shown explainability and robustness are two crucial ingredients of trustworthy and reliable text classification. However, previous works usually address one of two aspects: i) how to extract accurate rationales for explainability while being beneficial to prediction; ii) how to make the predictive model robust to different types of adversarial attacks. Intuitively, a model that produces helpful explanations should be more robust against adversarial attacks, because we cannot trust the model that outputs explanations but changes its prediction under small perturbations. To this end, we propose a joint classification and rationale extraction model named AT-BMC. It includes two key mechanisms: mixed Adversarial Training (AT) is designed to use various perturbations in discrete and embedding space to improve the model's robustness, and Boundary Match Constraint (BMC) helps to locate rationales more precisely with the guidance of boundary information. Performances on benchmark datasets demonstrate that the proposed AT-BMC outperforms baselines on both classification and rationale extraction by a large margin. Robustness analysis shows that the proposed AT-BMC decreases the attack success rate effectively by up to 69%. The empirical results indicate that there are connections between robust models and better explanations.