 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Retrieval Augmented Classification for Long-Tail Visual Recognition
Feb 22, 2022
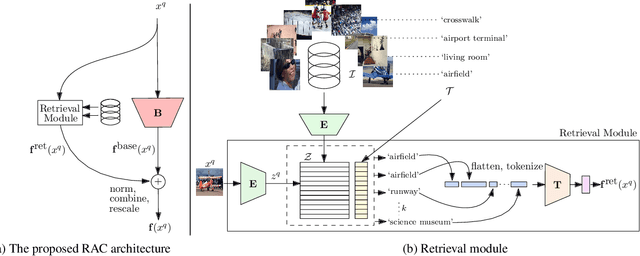
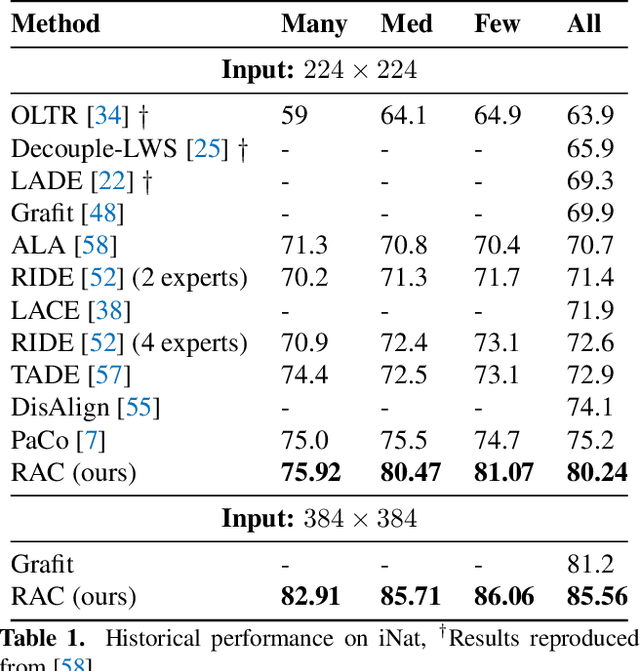
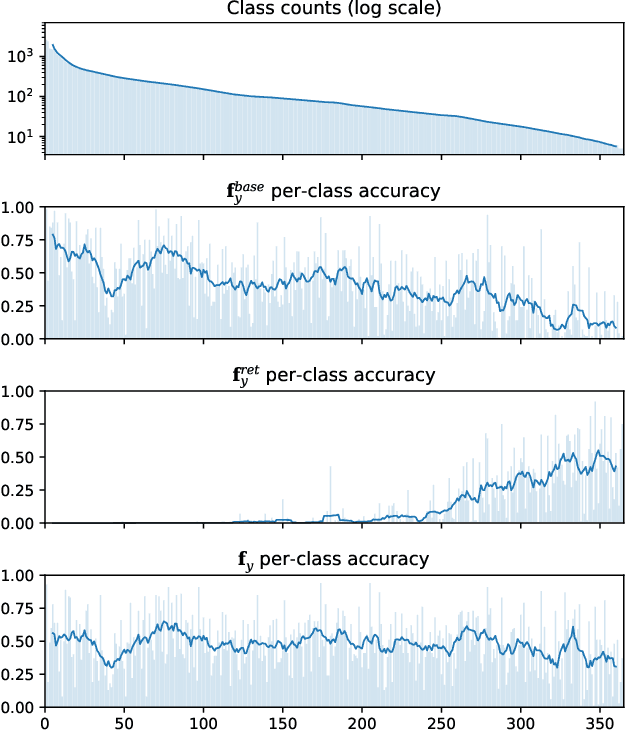
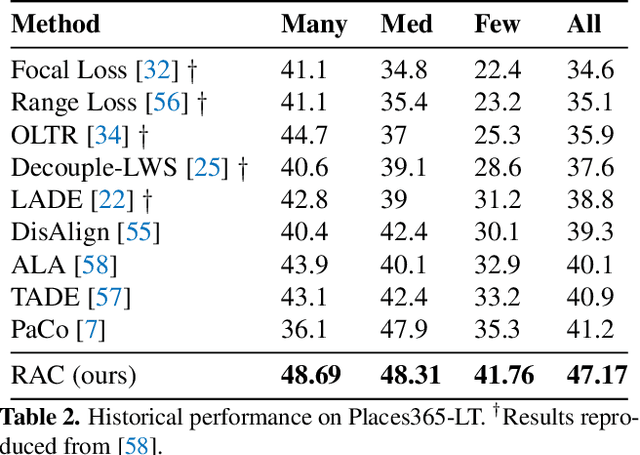
We introduce Retrieval Augmented Classification (RAC), a generic approach to augmenting standard image classification pipelines with an explicit retrieval module. RAC consists of a standard base image encoder fused with a parallel retrieval branch that queries a non-parametric external memory of pre-encoded images and associated text snippets. We apply RAC to the problem of long-tail classification and demonstrate a significant improvement over previous state-of-the-art on Places365-LT and iNaturalist-2018 (14.5% and 6.7% respectively), despite using only the training datasets themselves as the external information source. We demonstrate that RAC's retrieval module, without prompting, learns a high level of accuracy on tail classes. This, in turn, frees the base encoder to focus on common classes, and improve its performance thereon. RAC represents an alternative approach to utilizing large, pretrained models without requiring fine-tuning, as well as a first step towards more effectively making use of external memory within common computer vision architectures.
PercepNet+: A Phase and SNR Aware PercepNet for Real-Time Speech Enhancement
Mar 04, 2022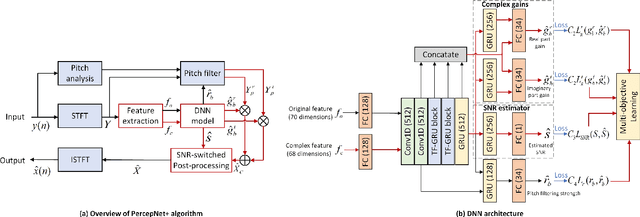
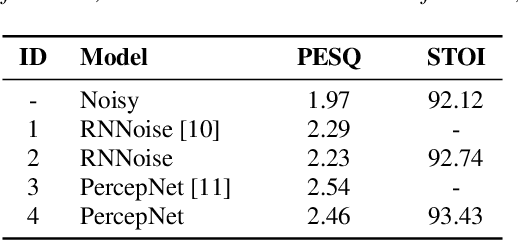
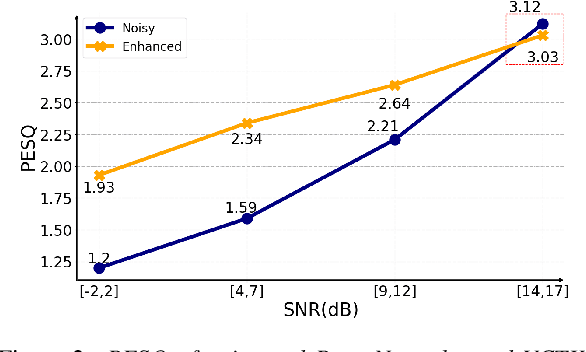
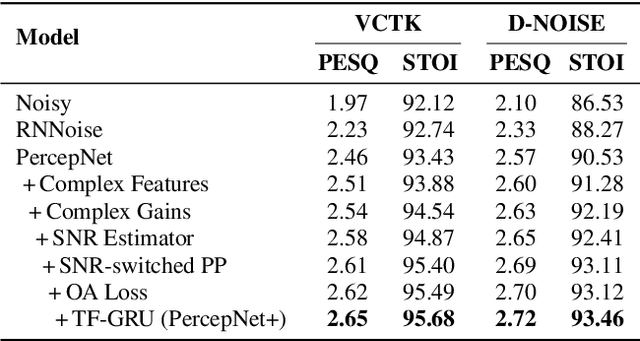
PercepNet, a recent extension of the RNNoise, an efficient, high-quality and real-time full-band speech enhancement technique, has shown promising performance in various public deep noise suppression tasks. This paper proposes a new approach, named PercepNet+, to further extend the PercepNet with four significant improvements. First, we introduce a phase-aware structure to leverage the phase information into PercepNet, by adding the complex features and complex subband gains as the deep network input and output respectively. Then, a signal-to-noise ratio (SNR) estimator and an SNR switched post-processing are specially designed to alleviate the over attenuation (OA) that appears in high SNR conditions of the original PercepNet. Moreover, the GRU layer is replaced by TF-GRU to model both temporal and frequency dependencies. Finally, we propose to integrate the loss of complex subband gain, SNR, pitch filtering strength, and an OA loss in a multi-objective learning manner to further improve the speech enhancement performance. Experimental results show that, the proposed PercepNet+ outperforms the original PercepNet significantly in terms of both PESQ and STOI, without increasing the model size too much.
TaxoCom: Topic Taxonomy Completion with Hierarchical Discovery of Novel Topic Clusters
Jan 19, 2022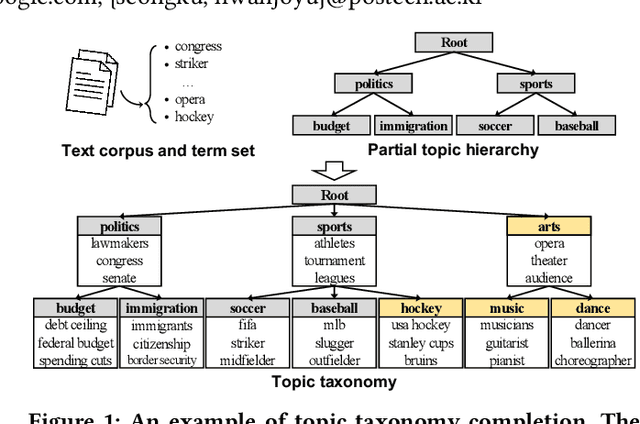
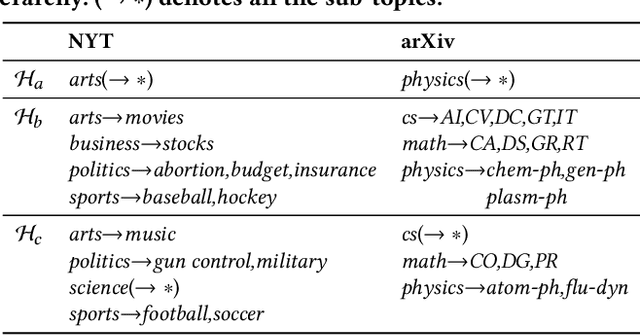
Topic taxonomies, which represent the latent topic (or category) structure of document collections, provide valuable knowledge of contents in many applications such as web search and information filtering. Recently, several unsupervised methods have been developed to automatically construct the topic taxonomy from a text corpus, but it is challenging to generate the desired taxonomy without any prior knowledge. In this paper, we study how to leverage the partial (or incomplete) information about the topic structure as guidance to find out the complete topic taxonomy. We propose a novel framework for topic taxonomy completion, named TaxoCom, which recursively expands the topic taxonomy by discovering novel sub-topic clusters of terms and documents. To effectively identify novel topics within a hierarchical topic structure, TaxoCom devises its embedding and clustering techniques to be closely-linked with each other: (i) locally discriminative embedding optimizes the text embedding space to be discriminative among known (i.e., given) sub-topics, and (ii) novelty adaptive clustering assigns terms into either one of the known sub-topics or novel sub-topics. Our comprehensive experiments on two real-world datasets demonstrate that TaxoCom not only generates the high-quality topic taxonomy in terms of term coherency and topic coverage but also outperforms all other baselines for a downstream task.
DeLoRes: Decorrelating Latent Spaces for Low-Resource Audio Representation Learning
Mar 25, 2022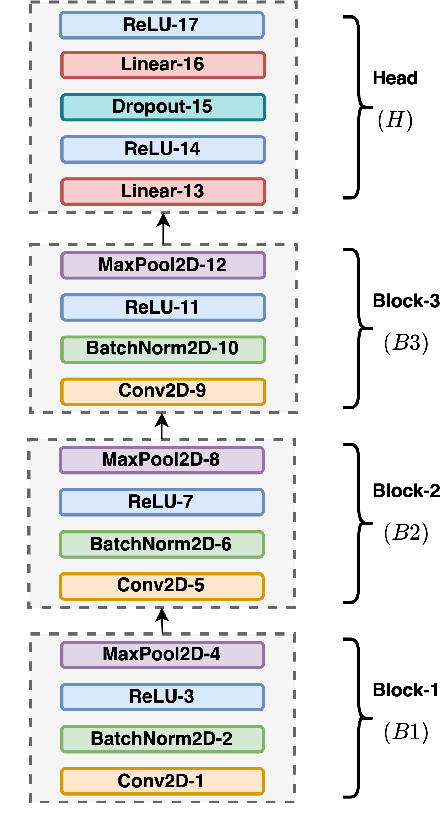
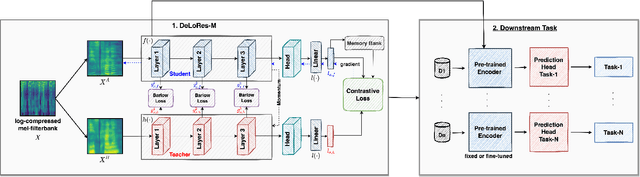
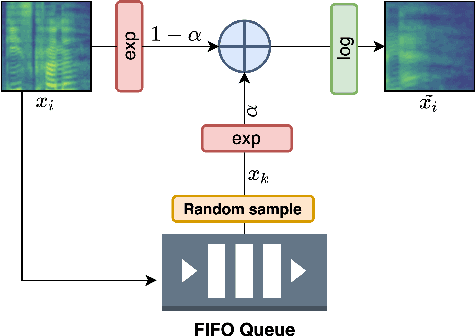
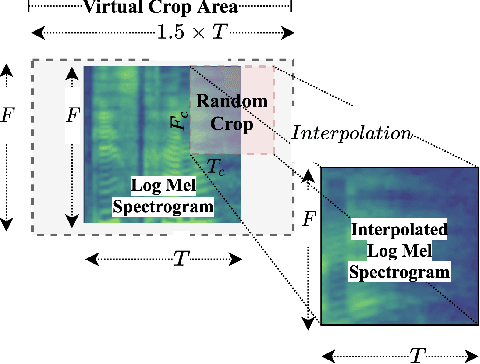
Inspired by the recent progress in self-supervised learning for computer vision, in this paper, through the DeLoRes learning framework, we introduce two new general-purpose audio representation learning approaches, the DeLoRes-S and DeLoRes-M. Our main objective is to make our network learn representations in a resource-constrained setting (both data and compute), that can generalize well across a diverse set of downstream tasks. Inspired from the Barlow Twins objective function, we propose to learn embeddings that are invariant to distortions of an input audio sample, while making sure that they contain non-redundant information about the sample. To achieve this, we measure the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of an audio segment sampled from an audio file and make it as close to the identity matrix as possible. We call this the DeLoRes learning framework, which we employ in different fashions with the DeLoRes-S and DeLoRes-M. We use a combination of a small subset of the large-scale AudioSet dataset and FSD50K for self-supervised learning and are able to learn with less than half the parameters compared to state-of-the-art algorithms. For evaluation, we transfer these learned representations to 11 downstream classification tasks, including speech, music, and animal sounds, and achieve state-of-the-art results on 7 out of 11 tasks on linear evaluation with DeLoRes-M and show competitive results with DeLoRes-S, even when pre-trained using only a fraction of the total data when compared to prior art. Our transfer learning evaluation setup also shows extremely competitive results for both DeLoRes-S and DeLoRes-M, with DeLoRes-M achieving state-of-the-art in 4 tasks.
DFTR: Depth-supervised Hierarchical Feature Fusion Transformer for Salient Object Detection
Mar 12, 2022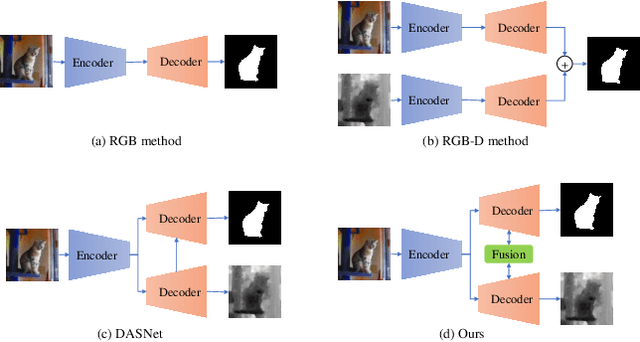
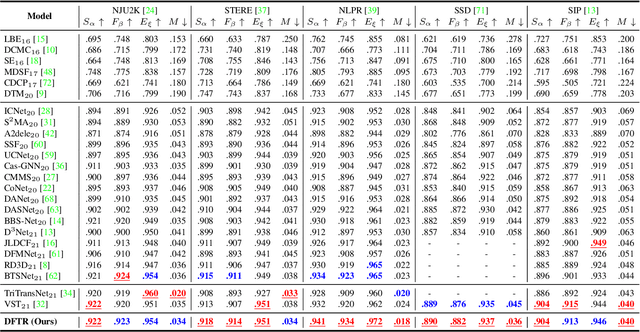
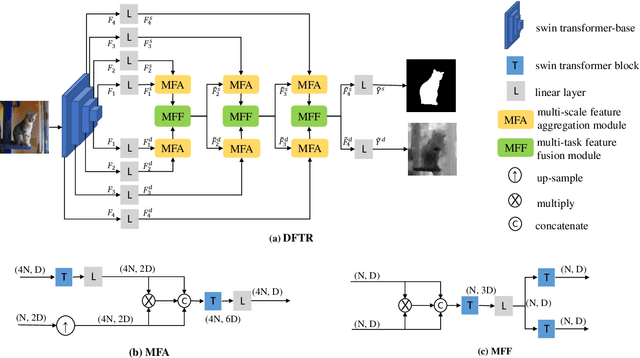
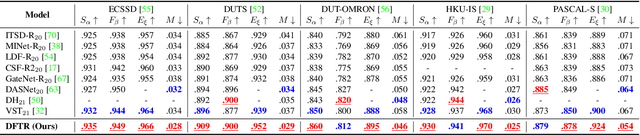
Automated salient object detection (SOD) plays an increasingly crucial role in many computer vision applications. Although existing frameworks achieve impressive SOD performances especially with the development of deep learning techniques, their performances still have room for improvement. In this work, we propose a novel pure Transformer-based SOD framework, namely Depth-supervised hierarchical feature Fusion TRansformer (DFTR), to further improve the accuracy of both RGB and RGB-D SOD. The proposed DFTR involves three primary improvements: 1) The backbone of feature encoder is switched from a convolutional neural network to a Swin Transformer for more effective feature extraction; 2) We propose a multi-scale feature aggregation (MFA) module to fully exploit the multi-scale features encoded by the Swin Transformer in a coarse-to-fine manner; 3) Following recent studies, we formulate an auxiliary task of depth map prediction and use the ground-truth depth maps as extra supervision signals for network learning. To enable bidirectional information flow between saliency and depth branches, a novel multi-task feature fusion (MFF) module is integrated into our DFTR. We extensively evaluate the proposed DFTR on ten benchmarking datasets. Experimental results show that our DFTR consistently outperforms the existing state-of-the-art methods for both RGB and RGB-D SOD tasks. The code and model will be released.
Look Closer: Bridging Egocentric and Third-Person Views with Transformers for Robotic Manipulation
Jan 19, 2022
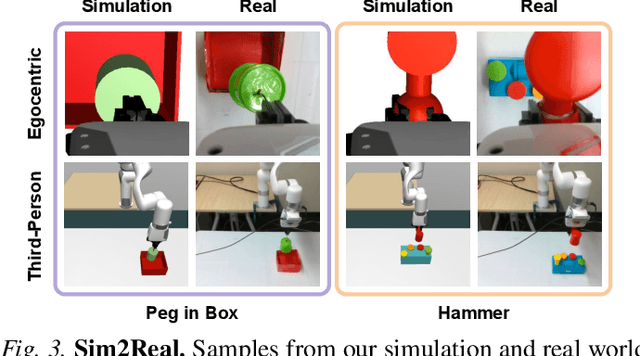
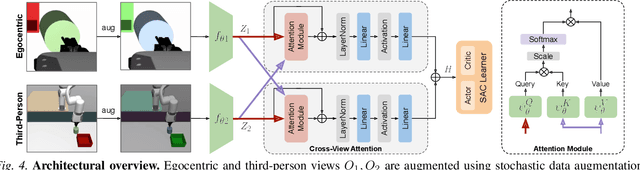

Learning to solve precision-based manipulation tasks from visual feedback using Reinforcement Learning (RL) could drastically reduce the engineering efforts required by traditional robot systems. However, performing fine-grained motor control from visual inputs alone is challenging, especially with a static third-person camera as often used in previous work. We propose a setting for robotic manipulation in which the agent receives visual feedback from both a third-person camera and an egocentric camera mounted on the robot's wrist. While the third-person camera is static, the egocentric camera enables the robot to actively control its vision to aid in precise manipulation. To fuse visual information from both cameras effectively, we additionally propose to use Transformers with a cross-view attention mechanism that models spatial attention from one view to another (and vice-versa), and use the learned features as input to an RL policy. Our method improves learning over strong single-view and multi-view baselines, and successfully transfers to a set of challenging manipulation tasks on a real robot with uncalibrated cameras, no access to state information, and a high degree of task variability. In a hammer manipulation task, our method succeeds in 75% of trials versus 38% and 13% for multi-view and single-view baselines, respectively.
Multi-Scale Adaptive Network for Single Image Denoising
Mar 08, 2022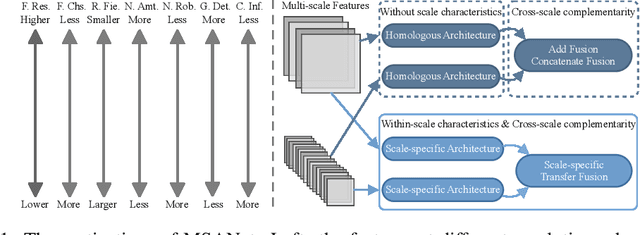
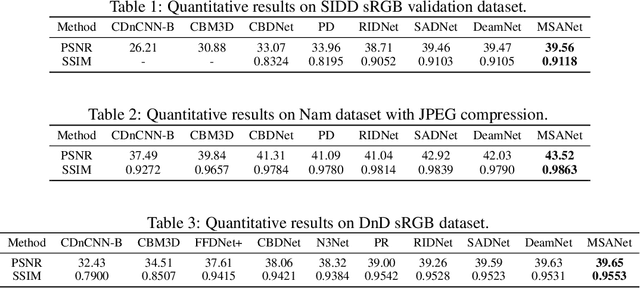
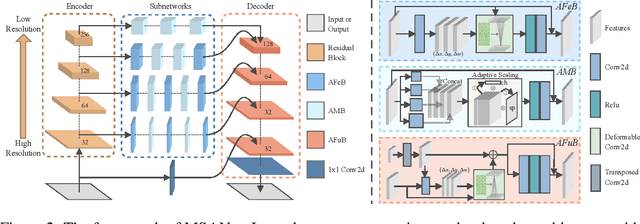

Multi-scale architectures have shown effectiveness in a variety of tasks including single image denoising, thanks to appealing cross-scale complementarity. However, existing methods treat different scale features equally without considering their scale-specific characteristics, i.e., the within-scale characteristics are ignored. In this paper, we reveal this missing piece for multi-scale architecture design and accordingly propose a novel Multi-Scale Adaptive Network (MSANet) for single image denoising. To be specific, MSANet simultaneously embraces the within-scale characteristics and the cross-scale complementarity thanks to three novel neural blocks, i.e., adaptive feature block (AFeB), adaptive multi-scale block (AMB), and adaptive fusion block (AFuB). In brief, AFeB is designed to adaptively select details and filter noises, which is highly expected for fine-grained features. AMB could enlarge the receptive field and aggregate the multi-scale information, which is designed to satisfy the demands of both fine- and coarse-grained features. AFuB devotes to adaptively sampling and transferring the features from one scale to another scale, which is used to fuse the features with varying characteristics from coarse to fine. Extensive experiments on both three real and six synthetic noisy image datasets show the superiority of MSANet compared with 12 methods.
Delay-adaptive step-sizes for asynchronous learning
Feb 17, 2022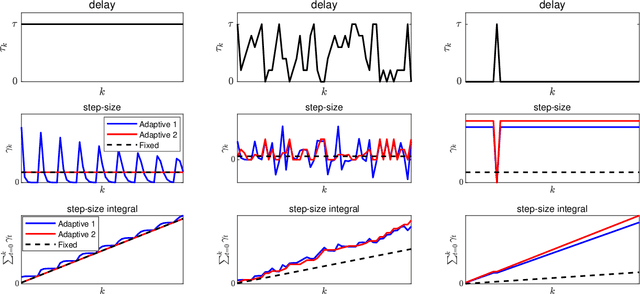
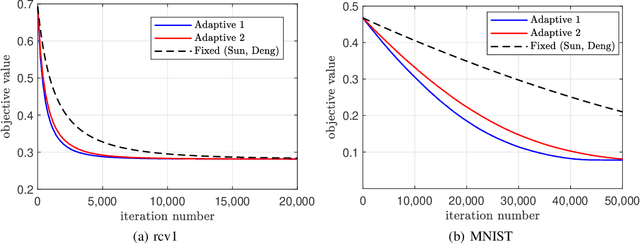
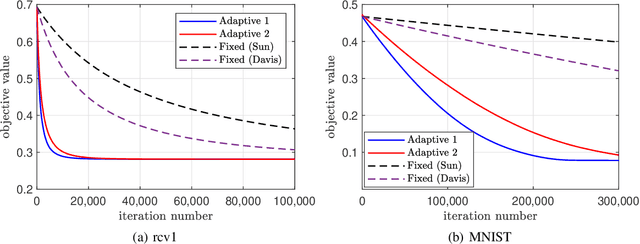
In scalable machine learning systems, model training is often parallelized over multiple nodes that run without tight synchronization. Most analysis results for the related asynchronous algorithms use an upper bound on the information delays in the system to determine learning rates. Not only are such bounds hard to obtain in advance, but they also result in unnecessarily slow convergence. In this paper, we show that it is possible to use learning rates that depend on the actual time-varying delays in the system. We develop general convergence results for delay-adaptive asynchronous iterations and specialize these to proximal incremental gradient descent and block-coordinate descent algorithms. For each of these methods, we demonstrate how delays can be measured on-line, present delay-adaptive step-size policies, and illustrate their theoretical and practical advantages over the state-of-the-art.
Differentially Private Community Detection for Stochastic Block Models
Jan 31, 2022
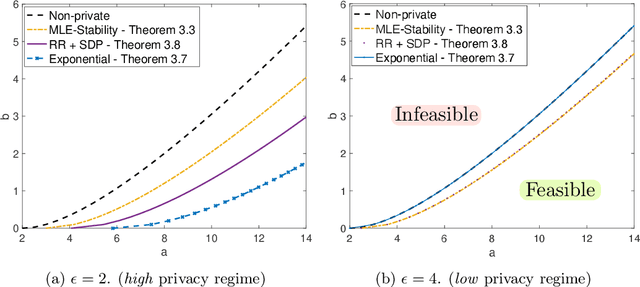
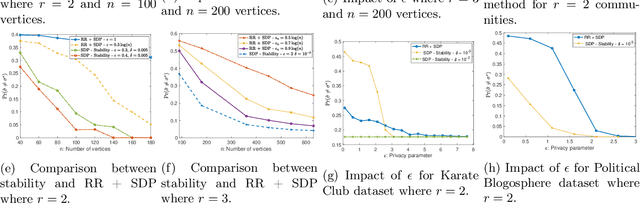

The goal of community detection over graphs is to recover underlying labels/attributes of users (e.g., political affiliation) given the connectivity between users (represented by adjacency matrix of a graph). There has been significant recent progress on understanding the fundamental limits of community detection when the graph is generated from a stochastic block model (SBM). Specifically, sharp information theoretic limits and efficient algorithms have been obtained for SBMs as a function of $p$ and $q$, which represent the intra-community and inter-community connection probabilities. In this paper, we study the community detection problem while preserving the privacy of the individual connections (edges) between the vertices. Focusing on the notion of $(\epsilon, \delta)$-edge differential privacy (DP), we seek to understand the fundamental tradeoffs between $(p, q)$, DP budget $(\epsilon, \delta)$, and computational efficiency for exact recovery of the community labels. To this end, we present and analyze the associated information-theoretic tradeoffs for three broad classes of differentially private community recovery mechanisms: a) stability based mechanism; b) sampling based mechanisms; and c) graph perturbation mechanisms. Our main findings are that stability and sampling based mechanisms lead to a superior tradeoff between $(p,q)$ and the privacy budget $(\epsilon, \delta)$; however this comes at the expense of higher computational complexity. On the other hand, albeit low complexity, graph perturbation mechanisms require the privacy budget $\epsilon$ to scale as $\Omega(\log(n))$ for exact recovery. To the best of our knowledge, this is the first work to study the impact of privacy constraints on the fundamental limits for community detection.
IMFNet: Interpretable Multimodal Fusion for Point Cloud Registration
Nov 18, 2021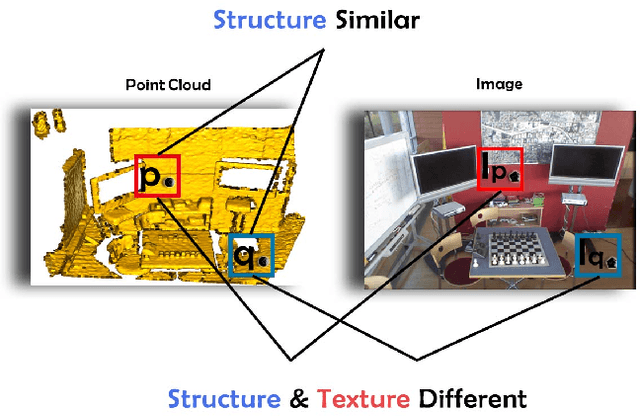
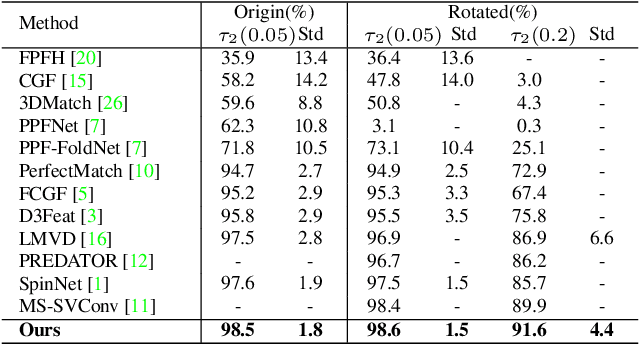
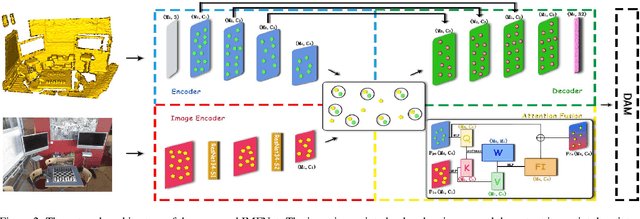
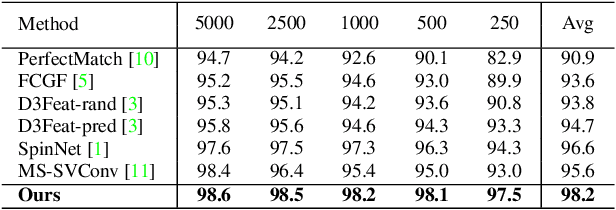
The existing state-of-the-art point descriptor relies on structure information only, which omit the texture information. However, texture information is crucial for our humans to distinguish a scene part. Moreover, the current learning-based point descriptors are all black boxes which are unclear how the original points contribute to the final descriptor. In this paper, we propose a new multimodal fusion method to generate a point cloud registration descriptor by considering both structure and texture information. Specifically, a novel attention-fusion module is designed to extract the weighted texture information for the descriptor extraction. In addition, we propose an interpretable module to explain the original points in contributing to the final descriptor. We use the descriptor element as the loss to backpropagate to the target layer and consider the gradient as the significance of this point to the final descriptor. This paper moves one step further to explainable deep learning in the registration task. Comprehensive experiments on 3DMatch, 3DLoMatch and KITTI demonstrate that the multimodal fusion descriptor achieves state-of-the-art accuracy and improve the descriptor's distinctiveness. We also demonstrate that our interpretable module in explaining the registration descriptor extraction.