 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridCodec: Fast Dual-Stream, Semantically Enhanced Neural Audio Codec
Jun 04, 2026The popularity of neural audio codecs as speech tokenizers has surged with the advent of Multimodal Large Language Models. New codec architectures with semantic and acoustic disentanglement have emerged. There are two main approaches to introduce semantic information into codec models: one distills semantic information from SSL representations into the first RVQ layer, while the other maintains separate streams for semantic and acoustic features. We propose HybridCodec, a unified architecture that combines both paradigms. It employs separate semantic and acoustic branches while distilling SSL representations into the semantic stream. This design ensures strong disentanglement without requiring an SSL model during inference. HybridCodec shows superior semantic specialization (RVQ-1) on in-domain test set and competitive reconstruction (RVQ-all). We demonstrate its robustness in out-of-domain and zero-shot cross-lingual settings, achieving a 3x speedup over existing dual-stream models.
Multilingual Multi-Speaker Unit Vocoders: A Systematic Analysis of Discrete Speech Representations
Jun 04, 2026Discrete speech units obtained via k-means clustering of self supervised embeddings entangle phonetic, speaker, and language information, causing speaker mixing and cross-lingual interference in multilingual multi-speaker speech generation. Despite growing use in Audio LLMs and speech to speech systems, unit vocoders remain underexplored. We analyze a BigVGAN based unit vocoder, across four Indian languages. We study the interaction between cluster size and conditioning strategies using WER, speaker similarity, and unit level metrics. Results show that cluster size governs intelligibility by improving phonetic discriminability, while explicit speaker conditioning is indispensable for preventing identity collapse. Language supervision yields further gains mainly at lower cluster sizes where units remain ambiguous. Our analysis shows similar phonemes across languages collapse to the same cluster IDs at smaller inventories, with larger clusters progressively separating them.
SPRING-INX: A Multilingual Indian Language Speech Corpus by SPRING Lab, IIT Madras
Oct 24, 2023


India is home to a multitude of languages of which 22 languages are recognised by the Indian Constitution as official. Building speech based applications for the Indian population is a difficult problem owing to limited data and the number of languages and accents to accommodate. To encourage the language technology community to build speech based applications in Indian languages, we are open sourcing SPRING-INX data which has about 2000 hours of legally sourced and manually transcribed speech data for ASR system building in Assamese, Bengali, Gujarati, Hindi, Kannada, Malayalam, Marathi, Odia, Punjabi and Tamil. This endeavor is by SPRING Lab , Indian Institute of Technology Madras and is a part of National Language Translation Mission (NLTM), funded by the Indian Ministry of Electronics and Information Technology (MeitY), Government of India. We describe the data collection and data cleaning process along with the data statistics in this paper.
SALTTS: Leveraging Self-Supervised Speech Representations for improved Text-to-Speech Synthesis
Aug 02, 2023

While FastSpeech2 aims to integrate aspects of speech such as pitch, energy, and duration as conditional inputs, it still leaves scope for richer representations. As a part of this work, we leverage representations from various Self-Supervised Learning (SSL) models to enhance the quality of the synthesized speech. In particular, we pass the FastSpeech2 encoder's length-regulated outputs through a series of encoder layers with the objective of reconstructing the SSL representations. In the SALTTS-parallel implementation, the representations from this second encoder are used for an auxiliary reconstruction loss with the SSL features. The SALTTS-cascade implementation, however, passes these representations through the decoder in addition to having the reconstruction loss. The richness of speech characteristics from the SSL features reflects in the output speech quality, with the objective and subjective evaluation measures of the proposed approach outperforming the baseline FastSpeech2.
Technology Pipeline for Large Scale Cross-Lingual Dubbing of Lecture Videos into Multiple Indian Languages
Nov 01, 2022

Cross-lingual dubbing of lecture videos requires the transcription of the original audio, correction and removal of disfluencies, domain term discovery, text-to-text translation into the target language, chunking of text using target language rhythm, text-to-speech synthesis followed by isochronous lipsyncing to the original video. This task becomes challenging when the source and target languages belong to different language families, resulting in differences in generated audio duration. This is further compounded by the original speaker's rhythm, especially for extempore speech. This paper describes the challenges in regenerating English lecture videos in Indian languages semi-automatically. A prototype is developed for dubbing lectures into 9 Indian languages. A mean-opinion-score (MOS) is obtained for two languages, Hindi and Tamil, on two different courses. The output video is compared with the original video in terms of MOS (1-5) and lip synchronisation with scores of 4.09 and 3.74, respectively. The human effort also reduces by 75%.
DeLoRes: Decorrelating Latent Spaces for Low-Resource Audio Representation Learning
Apr 13, 2022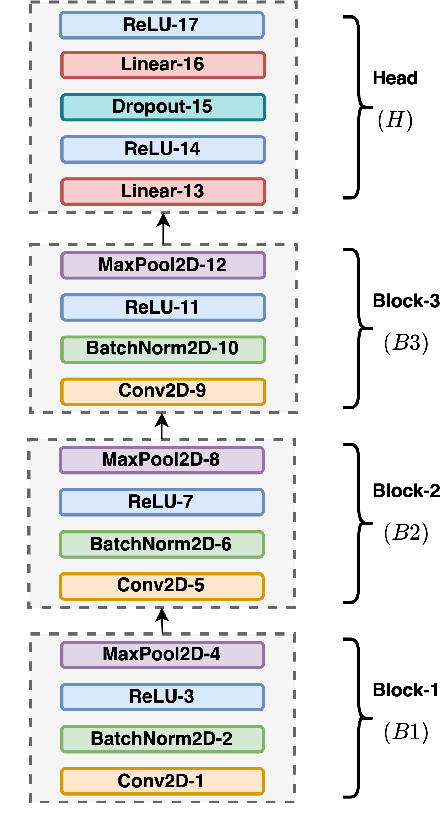
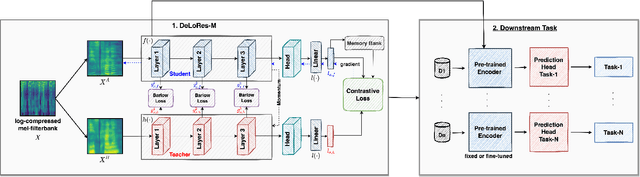
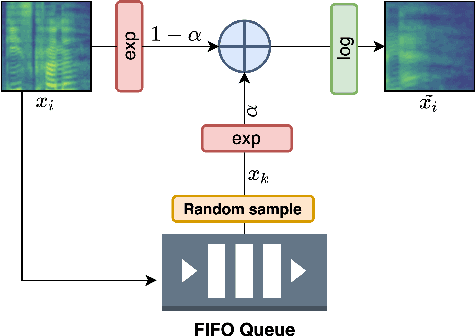
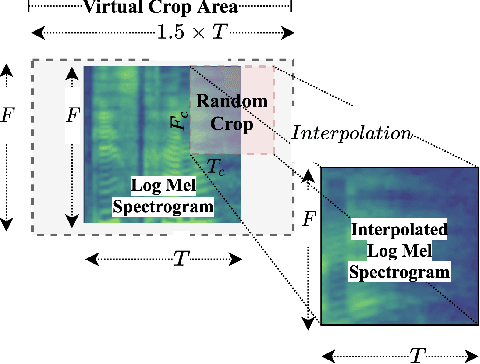
Inspired by the recent progress in self-supervised learning for computer vision, in this paper, through the DeLoRes learning framework, we introduce two new general-purpose audio representation learning approaches, the DeLoRes-S and DeLoRes-M. Our main objective is to make our network learn representations in a resource-constrained setting (both data and compute), that can generalize well across a diverse set of downstream tasks. Inspired from the Barlow Twins objective function, we propose to learn embeddings that are invariant to distortions of an input audio sample, while making sure that they contain non-redundant information about the sample. To achieve this, we measure the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of an audio segment sampled from an audio file and make it as close to the identity matrix as possible. We call this the DeLoRes learning framework, which we employ in different fashions with the DeLoRes-S and DeLoRes-M. We use a combination of a small subset of the large-scale AudioSet dataset and FSD50K for self-supervised learning and are able to learn with less than half the parameters compared to state-of-the-art algorithms. For evaluation, we transfer these learned representations to 11 downstream classification tasks, including speech, music, and animal sounds, and achieve state-of-the-art results on 7 out of 11 tasks on linear evaluation with DeLoRes-M and show competitive results with DeLoRes-S, even when pre-trained using only a fraction of the total data when compared to prior art. Our transfer learning evaluation setup also shows extremely competitive results for both DeLoRes-S and DeLoRes-M, with DeLoRes-M achieving state-of-the-art in 4 tasks.