 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MoReL: Multi-omics Relational Learning
Mar 15, 2022
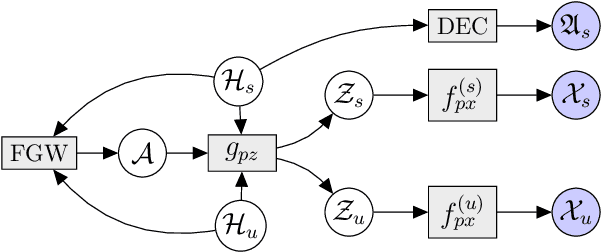

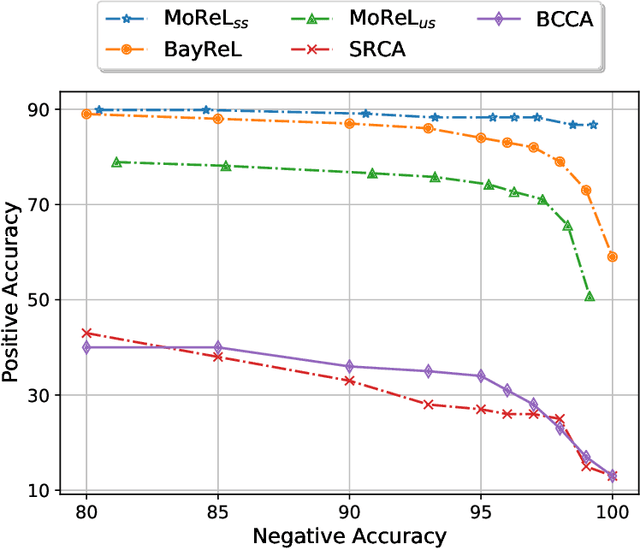
Multi-omics data analysis has the potential to discover hidden molecular interactions, revealing potential regulatory and/or signal transduction pathways for cellular processes of interest when studying life and disease systems. One of critical challenges when dealing with real-world multi-omics data is that they may manifest heterogeneous structures and data quality as often existing data may be collected from different subjects under different conditions for each type of omics data. We propose a novel deep Bayesian generative model to efficiently infer a multi-partite graph encoding molecular interactions across such heterogeneous views, using a fused Gromov-Wasserstein (FGW) regularization between latent representations of corresponding views for integrative analysis. With such an optimal transport regularization in the deep Bayesian generative model, it not only allows incorporating view-specific side information, either with graph-structured or unstructured data in different views, but also increases the model flexibility with the distribution-based regularization. This allows efficient alignment of heterogeneous latent variable distributions to derive reliable interaction predictions compared to the existing point-based graph embedding methods. Our experiments on several real-world datasets demonstrate enhanced performance of MoReL in inferring meaningful interactions compared to existing baselines.
Multi-Representation Adaptation Network for Cross-domain Image Classification
Jan 04, 2022
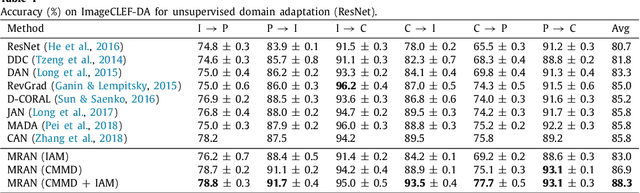
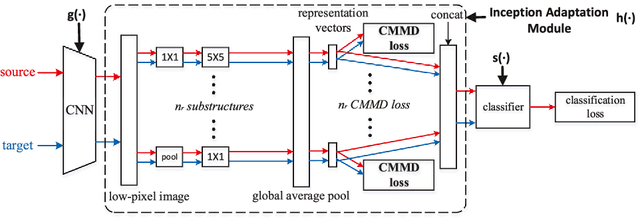
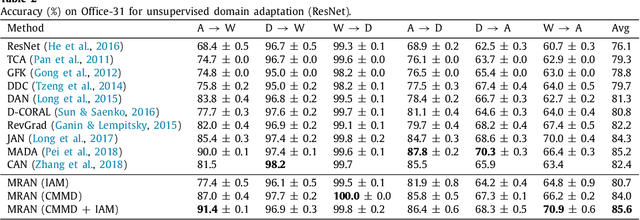
In image classification, it is often expensive and time-consuming to acquire sufficient labels. To solve this problem, domain adaptation often provides an attractive option given a large amount of labeled data from a similar nature but different domain. Existing approaches mainly align the distributions of representations extracted by a single structure and the representations may only contain partial information, e.g., only contain part of the saturation, brightness, and hue information. Along this line, we propose Multi-Representation Adaptation which can dramatically improve the classification accuracy for cross-domain image classification and specially aims to align the distributions of multiple representations extracted by a hybrid structure named Inception Adaptation Module (IAM). Based on this, we present Multi-Representation Adaptation Network (MRAN) to accomplish the cross-domain image classification task via multi-representation alignment which can capture the information from different aspects. In addition, we extend Maximum Mean Discrepancy (MMD) to compute the adaptation loss. Our approach can be easily implemented by extending most feed-forward models with IAM, and the network can be trained efficiently via back-propagation. Experiments conducted on three benchmark image datasets demonstrate the effectiveness of MRAN. The code has been available at https://github.com/easezyc/deep-transfer-learning.
Exploiting Bi-directional Global Transition Patterns and Personal Preferences for Missing POI Category Identification
Dec 31, 2021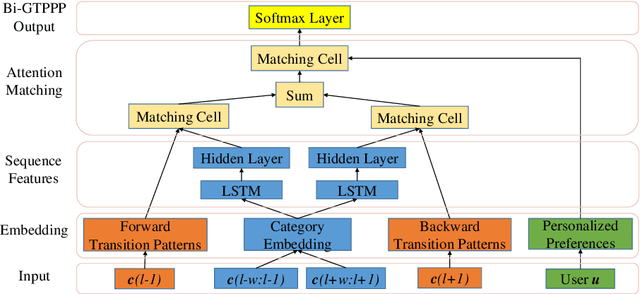

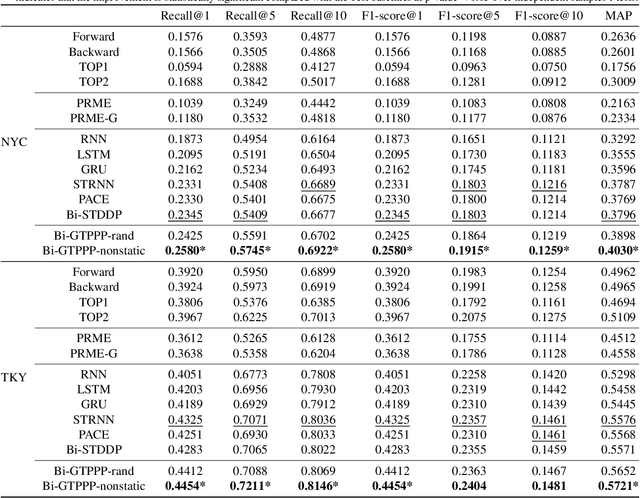
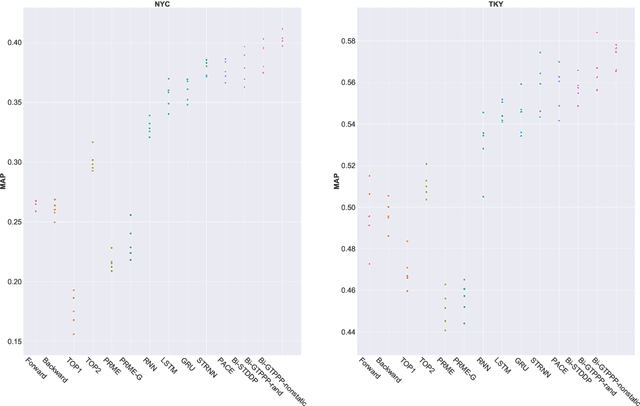
Recent years have witnessed the increasing popularity of Location-based Social Network (LBSN) services, which provides unparalleled opportunities to build personalized Point-of-Interest (POI) recommender systems. Existing POI recommendation and location prediction tasks utilize past information for future recommendation or prediction from a single direction perspective, while the missing POI category identification task needs to utilize the check-in information both before and after the missing category. Therefore, a long-standing challenge is how to effectively identify the missing POI categories at any time in the real-world check-in data of mobile users. To this end, in this paper, we propose a novel neural network approach to identify the missing POI categories by integrating both bi-directional global non-personal transition patterns and personal preferences of users. Specifically, we delicately design an attention matching cell to model how well the check-in category information matches their non-personal transition patterns and personal preferences. Finally, we evaluate our model on two real-world datasets, which clearly validate its effectiveness compared with the state-of-the-art baselines. Furthermore, our model can be naturally extended to address next POI category recommendation and prediction tasks with competitive performance.
OneRel:Joint Entity and Relation Extraction with One Module in One Step
Mar 10, 2022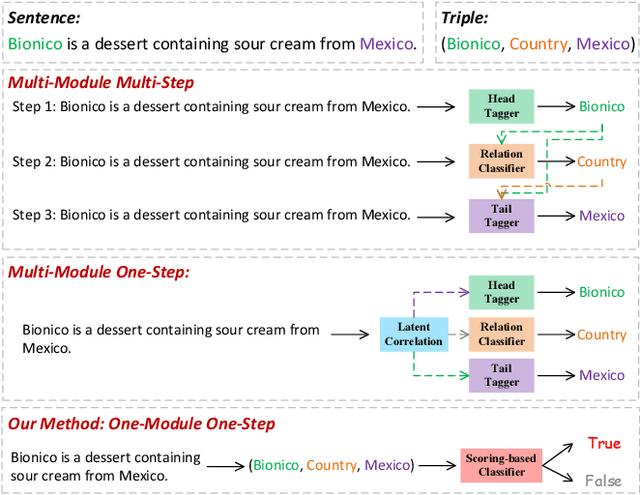
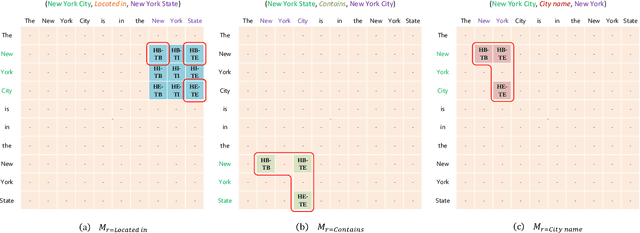
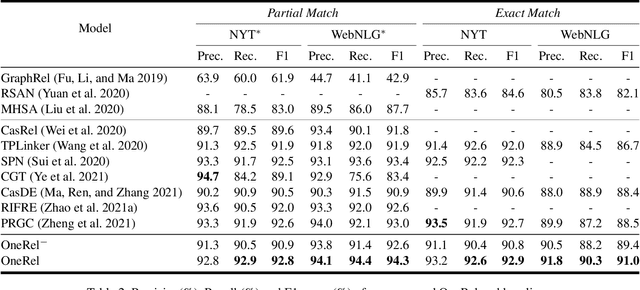
Joint entity and relation extraction is an essential task in natural language processing and knowledge graph construction. Existing approaches usually decompose the joint extraction task into several basic modules or processing steps to make it easy to conduct. However, such a paradigm ignores the fact that the three elements of a triple are interdependent and indivisible. Therefore, previous joint methods suffer from the problems of cascading errors and redundant information. To address these issues, in this paper, we propose a novel joint entity and relation extraction model, named OneRel, which casts joint extraction as a fine-grained triple classification problem. Specifically, our model consists of a scoring-based classifier and a relation-specific horns tagging strategy. The former evaluates whether a token pair and a relation belong to a factual triple. The latter ensures a simple but effective decoding process. Extensive experimental results on two widely used datasets demonstrate that the proposed method performs better than the state-of-the-art baselines, and delivers consistent performance gain on complex scenarios of various overlapping patterns and multiple triples.
DigNet: Digging Clues from Local-Global Interactive Graph for Aspect-level Sentiment Classification
Jan 04, 2022
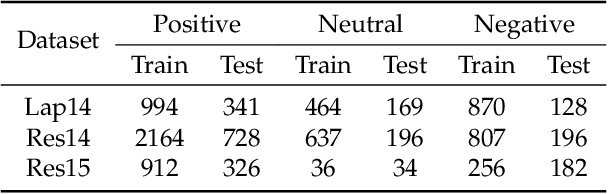
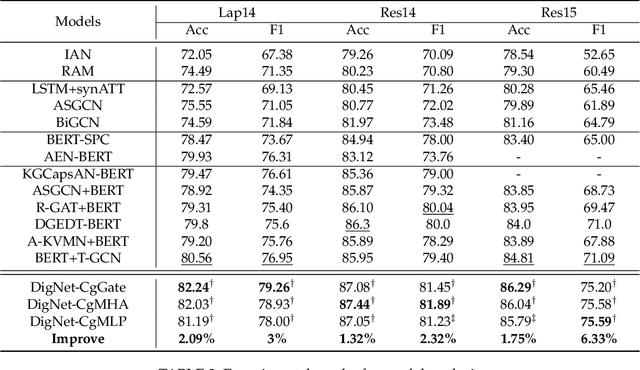
In aspect-level sentiment classification (ASC), state-of-the-art models encode either syntax graph or relation graph to capture the local syntactic information or global relational information. Despite the advantages of syntax and relation graphs, they have respective shortages which are neglected, limiting the representation power in the graph modeling process. To resolve their limitations, we design a novel local-global interactive graph, which marries their advantages by stitching the two graphs via interactive edges. To model this local-global interactive graph, we propose a novel neural network termed DigNet, whose core module is the stacked local-global interactive (LGI) layers performing two processes: intra-graph message passing and cross-graph message passing. In this way, the local syntactic and global relational information can be reconciled as a whole in understanding the aspect-level sentiment. Concretely, we design two variants of local-global interactive graphs with different kinds of interactive edges and three variants of LGI layers. We conduct experiments on several public benchmark datasets and the results show that we outperform previous best scores by 3\%, 2.32\%, and 6.33\% in terms of Macro-F1 on Lap14, Res14, and Res15 datasets, respectively, confirming the effectiveness and superiority of the proposed local-global interactive graph and DigNet.
NU HLT at CMCL 2022 Shared Task: Multilingual and Crosslingual Prediction of Human Reading Behavior in Universal Language Space
Feb 22, 2022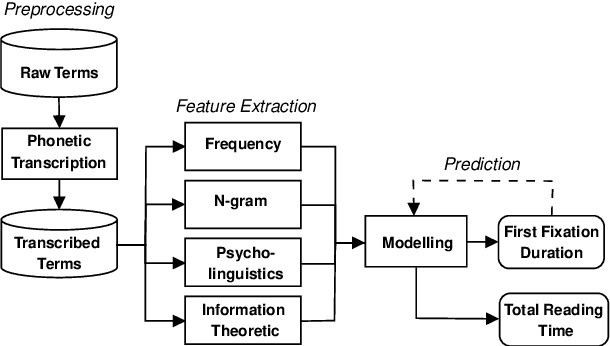
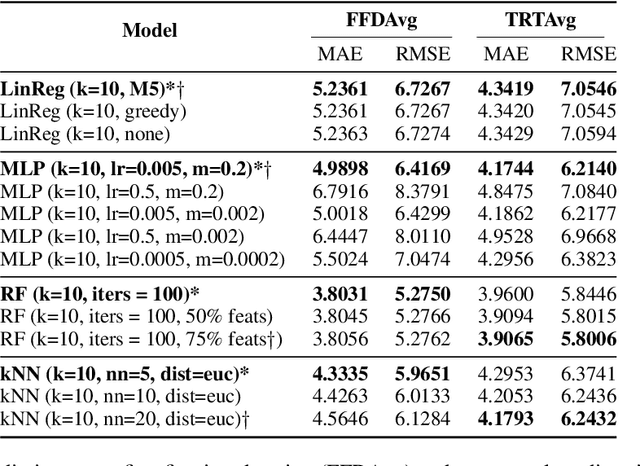
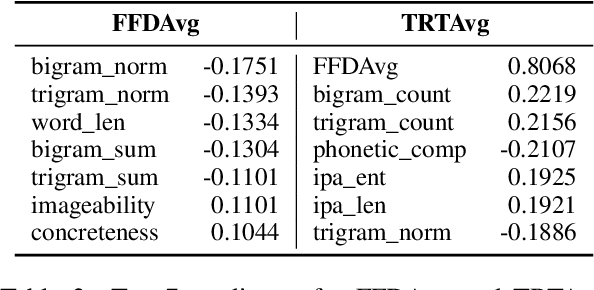
In this paper, we present a unified model that works for both multilingual and crosslingual prediction of reading times of words in various languages. The secret behind the success of this model is in the preprocessing step where all words are transformed to their universal language representation via the International Phonetic Alphabet (IPA). To the best of our knowledge, this is the first study to favorable exploit this phonological property of language for the two tasks. Various feature types were extracted covering basic frequencies, n-grams, information theoretic, and psycholinguistically-motivated predictors for model training. A finetuned Random Forest model obtained best performance for both tasks with 3.8031 and 3.9065 MAE scores for mean first fixation duration (FFDAve) and mean total reading time (TRTAve) respectively.
FisherMatch: Semi-Supervised Rotation Regression via Entropy-based Filtering
Mar 29, 2022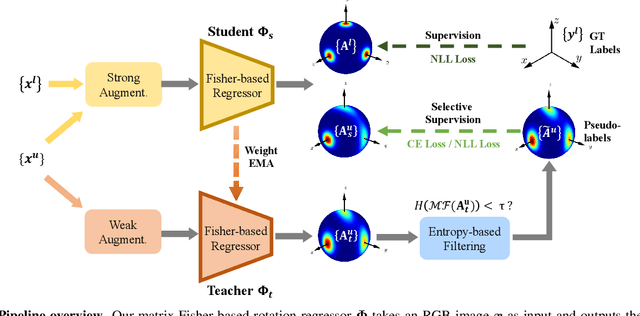
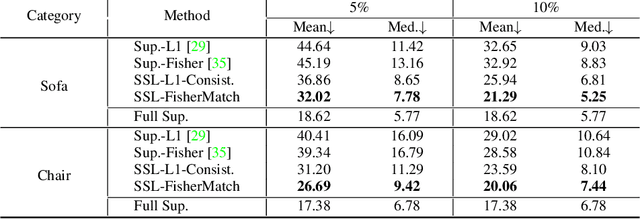
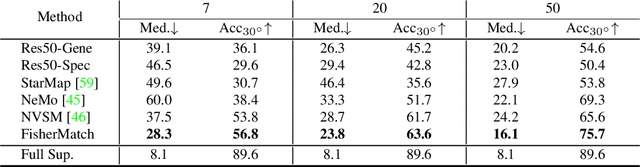
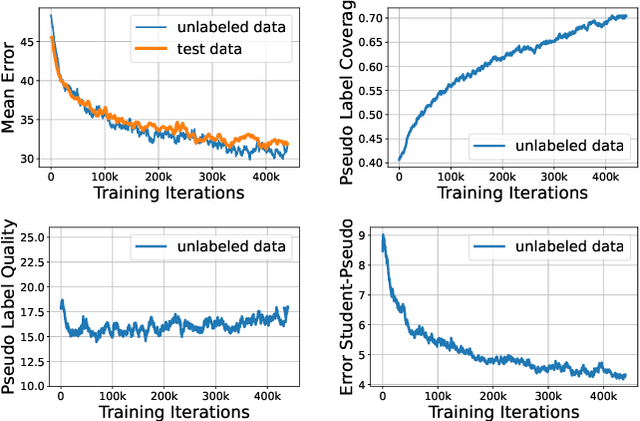
Estimating the 3DoF rotation from a single RGB image is an important yet challenging problem. Recent works achieve good performance relying on a large amount of expensive-to-obtain labeled data. To reduce the amount of supervision, we for the first time propose a general framework, FisherMatch, for semi-supervised rotation regression, without assuming any domain-specific knowledge or paired data. Inspired by the popular semi-supervised approach, FixMatch, we propose to leverage pseudo label filtering to facilitate the information flow from labeled data to unlabeled data in a teacher-student mutual learning framework. However, incorporating the pseudo label filtering mechanism into semi-supervised rotation regression is highly non-trivial, mainly due to the lack of a reliable confidence measure for rotation prediction. In this work, we propose to leverage matrix Fisher distribution to build a probabilistic model of rotation and devise a matrix Fisher-based regressor for jointly predicting rotation along with its prediction uncertainty. We then propose to use the entropy of the predicted distribution as a confidence measure, which enables us to perform pseudo label filtering for rotation regression. For supervising such distribution-like pseudo labels, we further investigate the problem of how to enforce loss between two matrix Fisher distributions. Our extensive experiments show that our method can work well even under very low labeled data ratios on different benchmarks, achieving significant and consistent performance improvement over supervised learning and other semi-supervised learning baselines. Our project page is at https://yd-yin.github.io/FisherMatch.
Reinforcement Learned Distributed Multi-Robot Navigation with Reciprocal Velocity Obstacle Shaped Rewards
Mar 19, 2022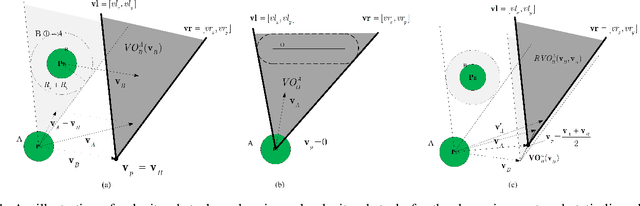
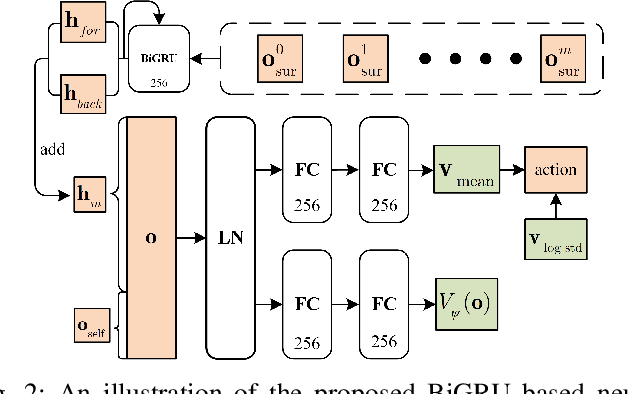
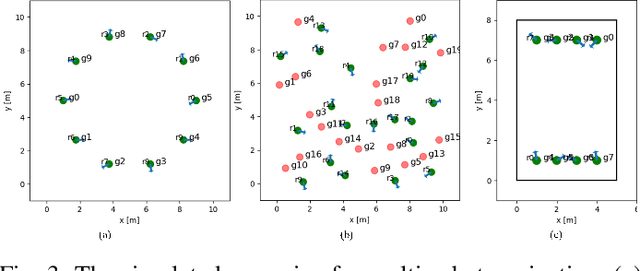
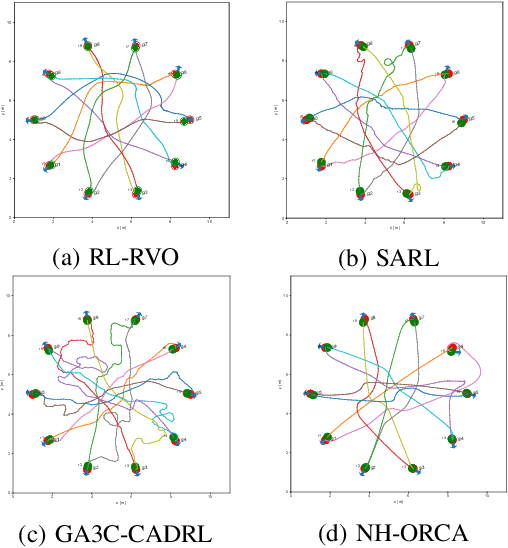
The challenges to solving the collision avoidance problem lie in adaptively choosing optimal robot velocities in complex scenarios full of interactive obstacles. In this paper, we propose a distributed approach for multi-robot navigation which combines the concept of reciprocal velocity obstacle (RVO) and the scheme of deep reinforcement learning (DRL) to solve the reciprocal collision avoidance problem under limited information. The novelty of this work is threefold: (1) using a set of sequential VO and RVO vectors to represent the interactive environmental states of static and dynamic obstacles, respectively; (2) developing a bidirectional recurrent module based neural network, which maps the states of a varying number of surrounding obstacles to the actions directly; (3) developing a RVO area and expected collision time based reward function to encourage reciprocal collision avoidance behaviors and trade off between collision risk and travel time. The proposed policy is trained through simulated scenarios and updated by the actor-critic based DRL algorithm. We validate the policy in complex environments with various numbers of differential drive robots and obstacles. The experiment results demonstrate that our approach outperforms the state-of-art methods and other learning based approaches in terms of the success rate, travel time, and average speed. Source code of this approach is available at https://github.com/hanruihua/rl_rvo_nav.
Iterative Corresponding Geometry: Fusing Region and Depth for Highly Efficient 3D Tracking of Textureless Objects
Mar 10, 2022
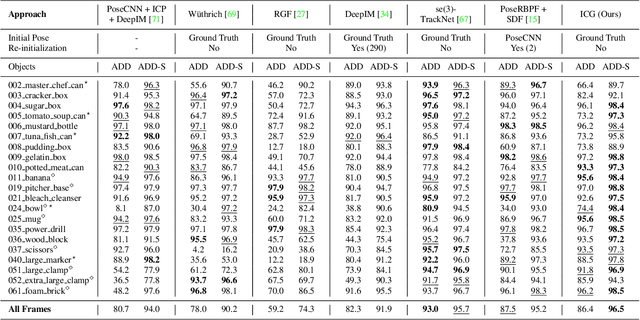
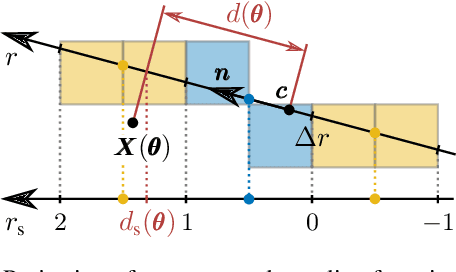

Tracking objects in 3D space and predicting their 6DoF pose is an essential task in computer vision. State-of-the-art approaches often rely on object texture to tackle this problem. However, while they achieve impressive results, many objects do not contain sufficient texture, violating the main underlying assumption. In the following, we thus propose ICG, a novel probabilistic tracker that fuses region and depth information and only requires the object geometry. Our method deploys correspondence lines and points to iteratively refine the pose. We also implement robust occlusion handling to improve performance in real-world settings. Experiments on the YCB-Video, OPT, and Choi datasets demonstrate that, even for textured objects, our approach outperforms the current state of the art with respect to accuracy and robustness. At the same time, ICG shows fast convergence and outstanding efficiency, requiring only 1.3 ms per frame on a single CPU core. Finally, we analyze the influence of individual components and discuss our performance compared to deep learning-based methods. The source code of our tracker is publicly available.
Diffractive all-optical computing for quantitative phase imaging
Jan 22, 2022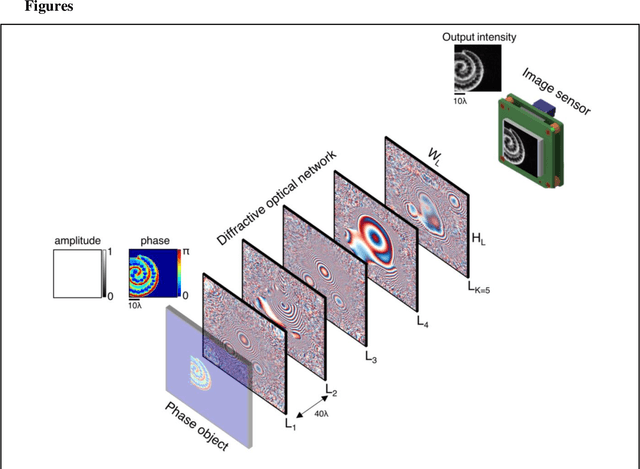

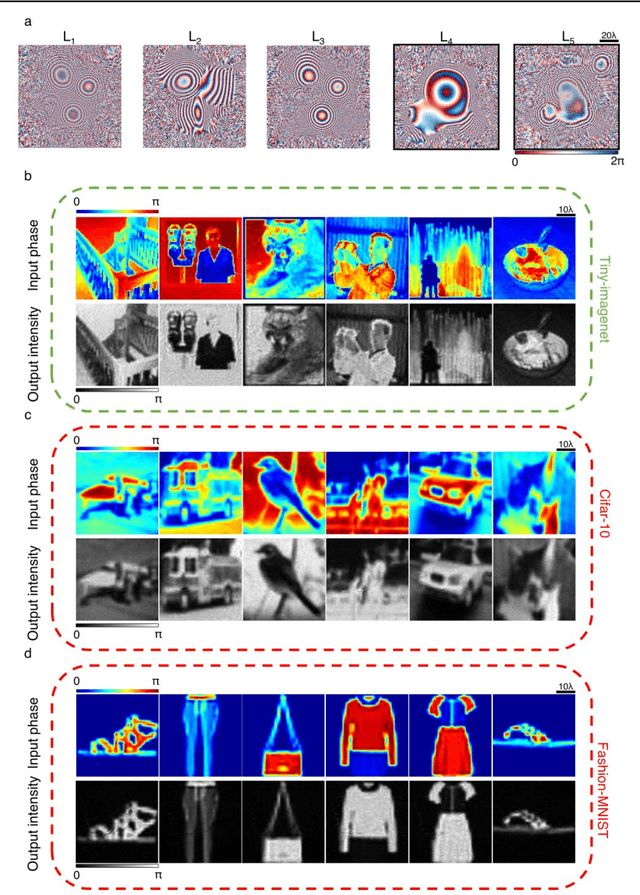
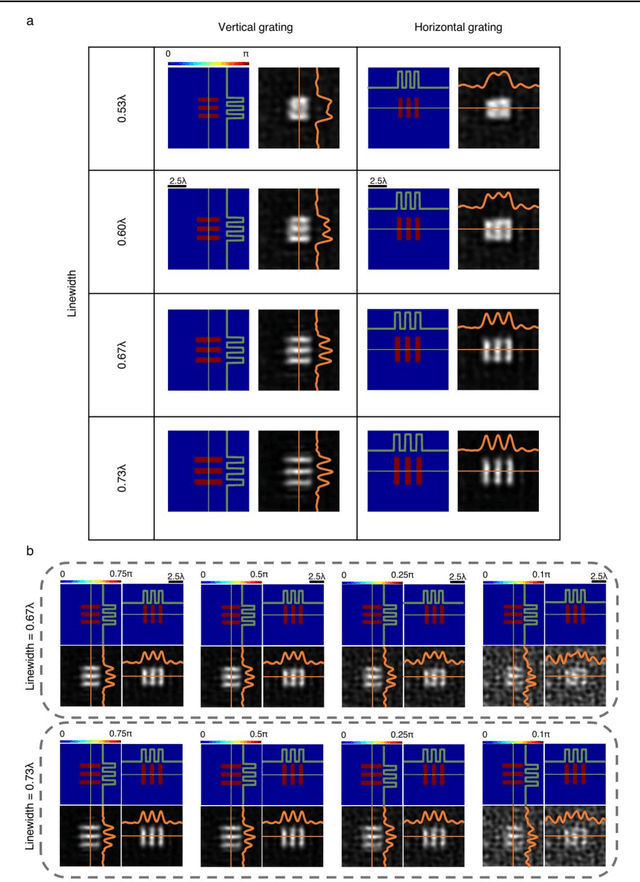
Quantitative phase imaging (QPI) is a label-free computational imaging technique that provides optical path length information of specimens. In modern implementations, the quantitative phase image of an object is reconstructed digitally through numerical methods running in a computer, often using iterative algorithms. Here, we demonstrate a diffractive QPI network that can synthesize the quantitative phase image of an object by converting the input phase information of a scene into intensity variations at the output plane. A diffractive QPI network is a specialized all-optical processor designed to perform a quantitative phase-to-intensity transformation through passive diffractive surfaces that are spatially engineered using deep learning and image data. Forming a compact, all-optical network that axially extends only ~200-300 times the illumination wavelength, this framework can replace traditional QPI systems and related digital computational burden with a set of passive transmissive layers. All-optical diffractive QPI networks can potentially enable power-efficient, high frame-rate and compact phase imaging systems that might be useful for various applications, including, e.g., on-chip microscopy and sensing.