 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Virtual Relational Knowledge Graphs for Recommendation
Apr 03, 2022
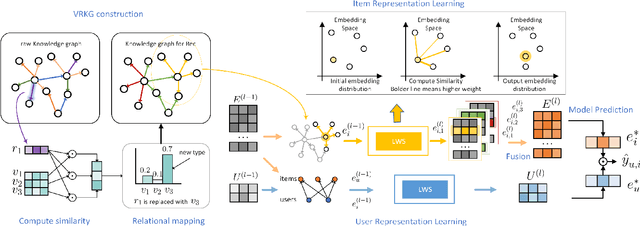
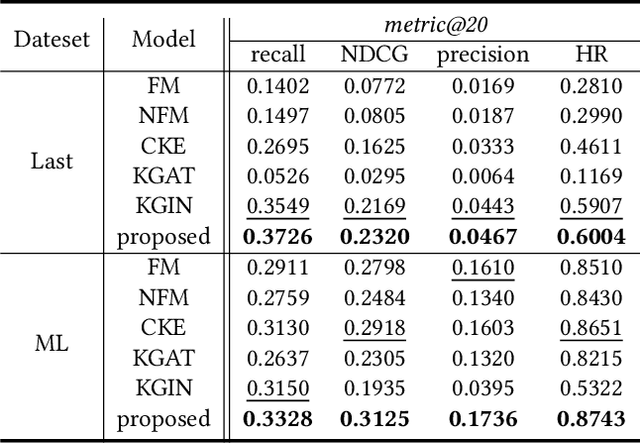
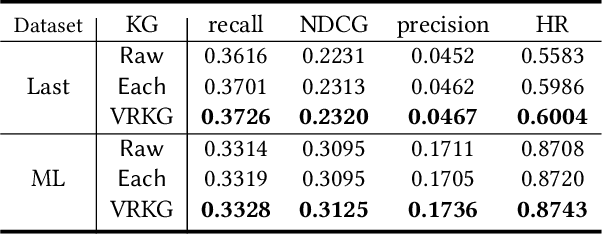
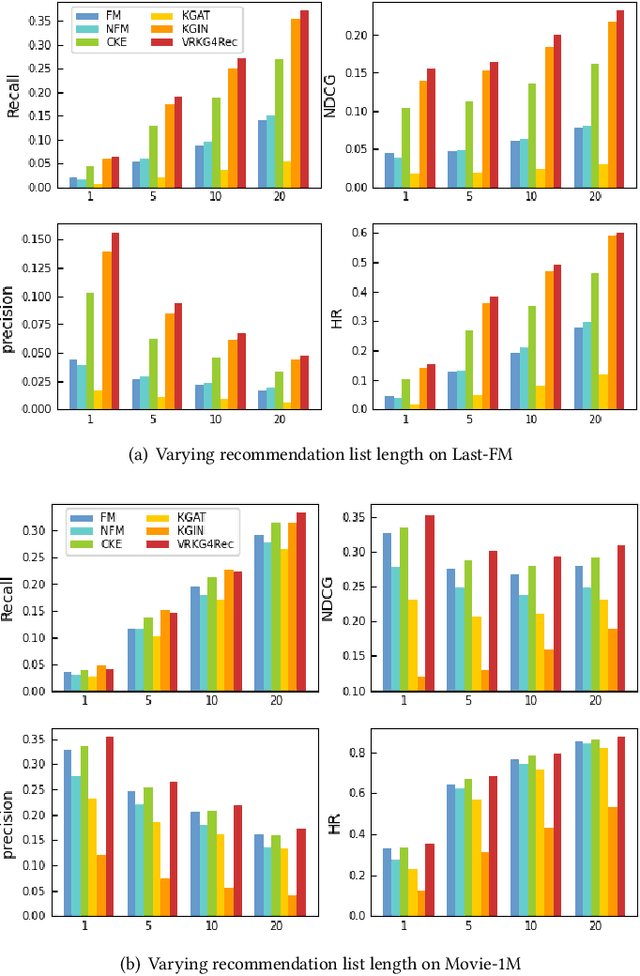
Incorporating knowledge graph as side information has become a new trend in recommendation systems. Recent studies regard items as entities of a knowledge graph and leverage graph neural networks to assist item encoding, yet by considering each relation type individually. However, relation types are often too many and sometimes one relation type involves too few entities. We argue that it is not efficient nor effective to use every relation type for item encoding. In this paper, we propose a VRKG4Rec model (Virtual Relational Knowledge Graphs for Recommendation), which explicitly distinguish the influence of different relations for item representation learning. We first construct virtual relational graphs (VRKGs) by an unsupervised learning scheme. We also design a local weighted smoothing (LWS) mechanism for encoding nodes, which iteratively updates a node embedding only depending on the embedding of its own and its neighbors, but involve no additional training parameters. We also employ the LWS mechanism on a user-item bipartite graph for user representation learning, which utilizes encodings of items with relational knowledge to help training representations of users. Experiment results on two public datasets validate that our VRKG4Rec model outperforms the state-of-the-art methods.
Part-Aware Self-Supervised Pre-Training for Person Re-Identification
Mar 08, 2022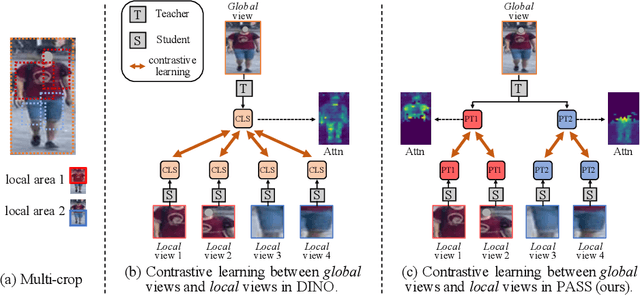
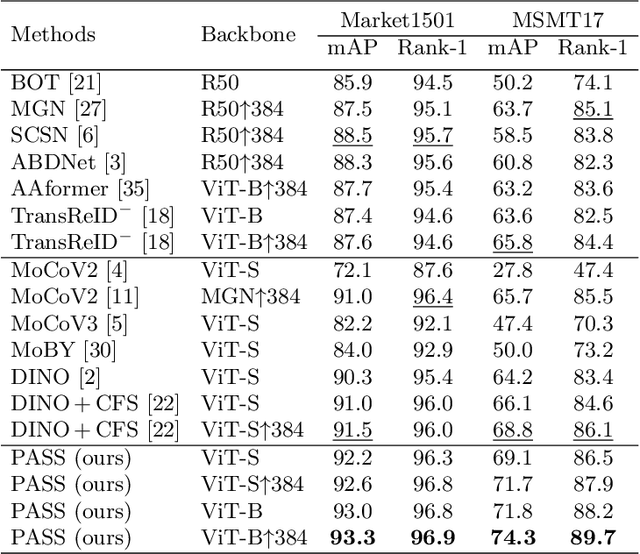
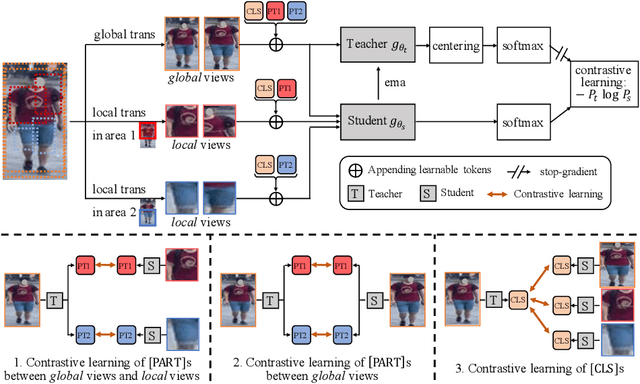
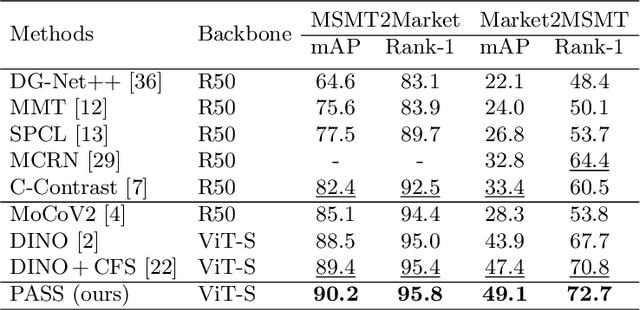
In person re-identification (ReID), very recent researches have validated pre-training the models on unlabelled person images is much better than on ImageNet. However, these researches directly apply the existing self-supervised learning (SSL) methods designed for image classification to ReID without any adaption in the framework. These SSL methods match the outputs of local views (e.g., red T-shirt, blue shorts) to those of the global views at the same time, losing lots of details. In this paper, we propose a ReID-specific pre-training method, Part-Aware Self-Supervised pre-training (PASS), which can generate part-level features to offer fine-grained information and is more suitable for ReID. PASS divides the images into several local areas, and the local views randomly cropped from each area are assigned with a specific learnable [PART] token. On the other hand, the [PART]s of all local areas are also appended to the global views. PASS learns to match the output of the local views and global views on the same [PART]. That is, the learned [PART] of the local views from a local area is only matched with the corresponding [PART] learned from the global views. As a result, each [PART] can focus on a specific local area of the image and extracts fine-grained information of this area. Experiments show PASS sets the new state-of-the-art performances on Market1501 and MSMT17 on various ReID tasks, e.g., vanilla ViT-S/16 pre-trained by PASS achieves 92.2\%/90.2\%/88.5\% mAP accuracy on Market1501 for supervised/UDA/USL ReID. Our codes are available at https://github.com/CASIA-IVA-Lab/PASS-reID.
Clustering Aided Weakly Supervised Training to Detect Anomalous Events in Surveillance Videos
Mar 25, 2022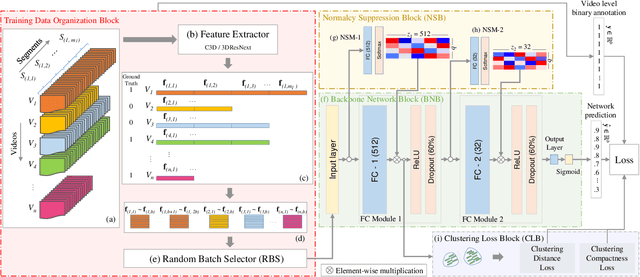
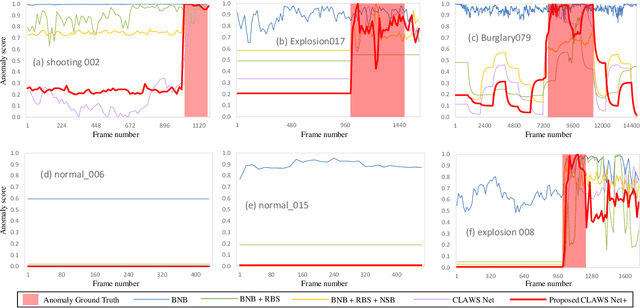
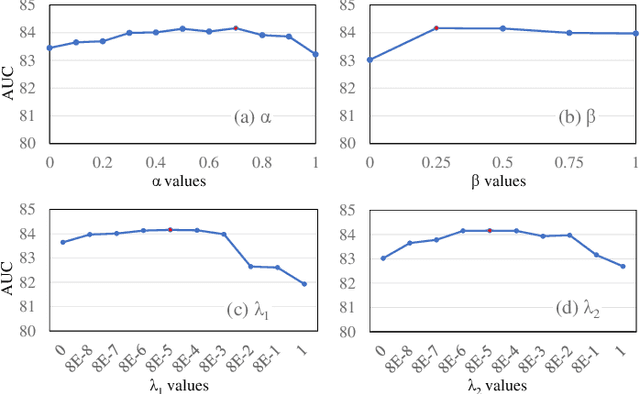
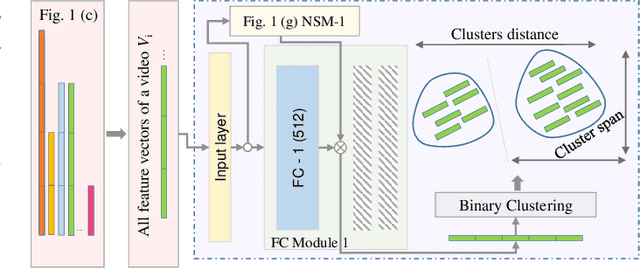
Formulating learning systems for the detection of real-world anomalous events using only video-level labels is a challenging task mainly due to the presence of noisy labels as well as the rare occurrence of anomalous events in the training data. We propose a weakly supervised anomaly detection system which has multiple contributions including a random batch selection mechanism to reduce inter-batch correlation and a normalcy suppression block which learns to minimize anomaly scores over normal regions of a video by utilizing the overall information available in a training batch. In addition, a clustering loss block is proposed to mitigate the label noise and to improve the representation learning for the anomalous and normal regions. This block encourages the backbone network to produce two distinct feature clusters representing normal and anomalous events. Extensive analysis of the proposed approach is provided using three popular anomaly detection datasets including UCF-Crime, ShanghaiTech, and UCSD Ped2. The experiments demonstrate a superior anomaly detection capability of our approach.
MAESTRO: Matched Speech Text Representations through Modality Matching
Apr 07, 2022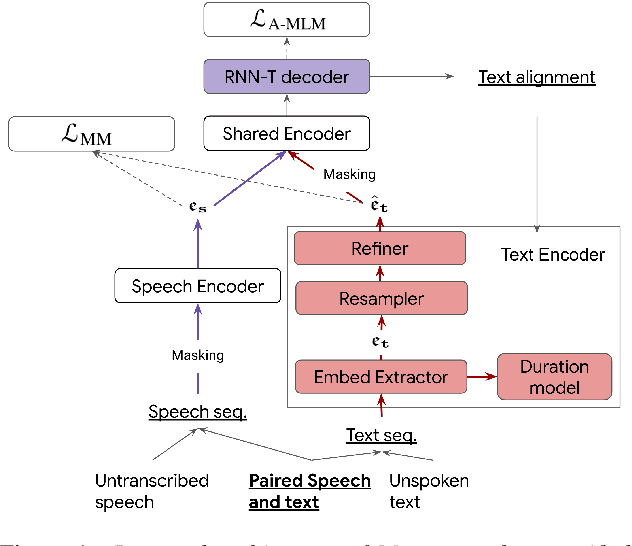
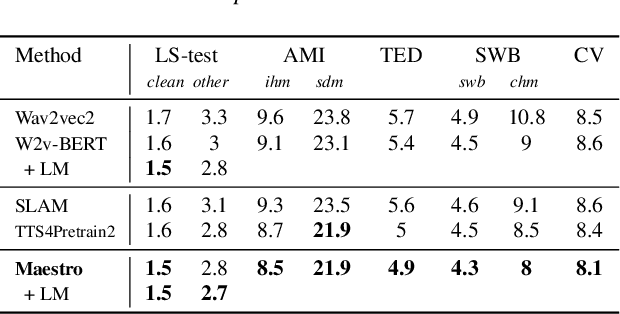
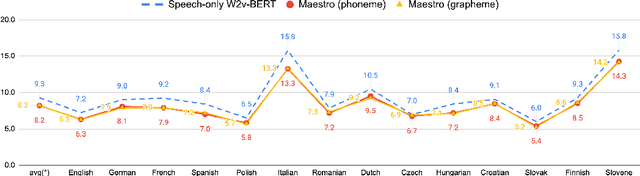
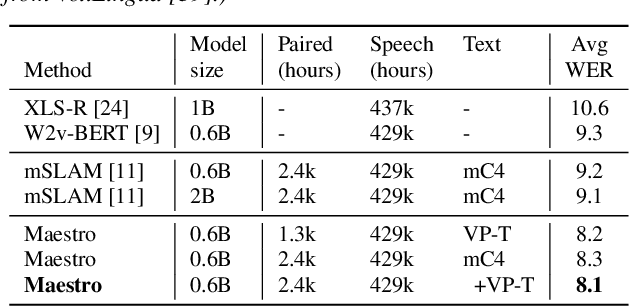
We present Maestro, a self-supervised training method to unify representations learnt from speech and text modalities. Self-supervised learning from speech signals aims to learn the latent structure inherent in the signal, while self-supervised learning from text attempts to capture lexical information. Learning aligned representations from unpaired speech and text sequences is a challenging task. Previous work either implicitly enforced the representations learnt from these two modalities to be aligned in the latent space through multitasking and parameter sharing or explicitly through conversion of modalities via speech synthesis. While the former suffers from interference between the two modalities, the latter introduces additional complexity. In this paper, we propose Maestro, a novel algorithm to learn unified representations from both these modalities simultaneously that can transfer to diverse downstream tasks such as Automated Speech Recognition (ASR) and Speech Translation (ST). Maestro learns unified representations through sequence alignment, duration prediction and matching embeddings in the learned space through an aligned masked-language model loss. We establish a new state-of-the-art (SOTA) on VoxPopuli multilingual ASR with a 11% relative reduction in Word Error Rate (WER), multidomain SpeechStew ASR (3.7% relative) and 21 languages to English multilingual ST on CoVoST 2 with an improvement of 2.8 BLEU averaged over 21 languages.
Probably Reasonable Search in eDiscovery
Jan 28, 2022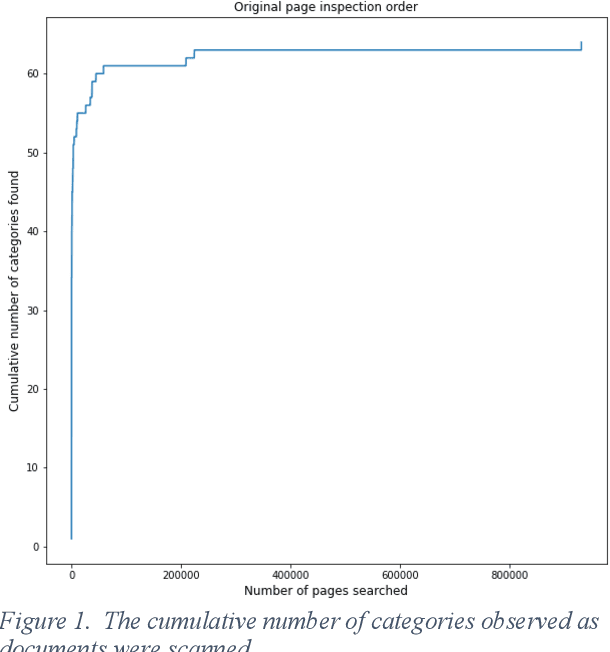
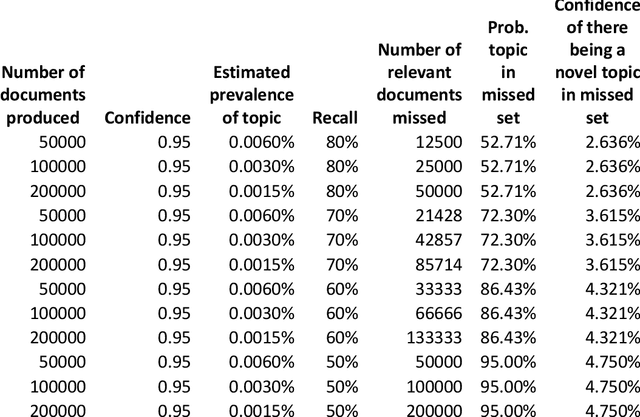
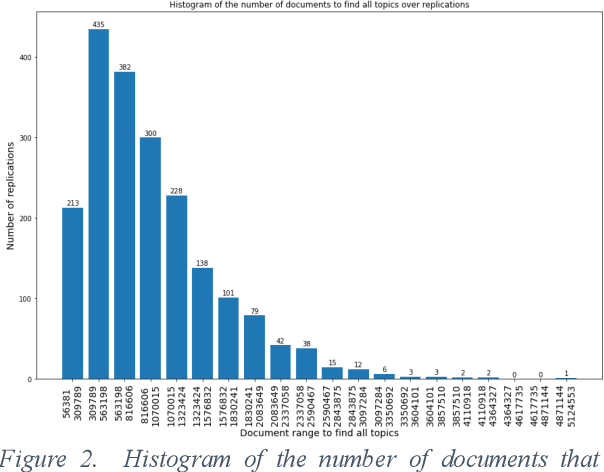
In eDiscovery, a party to a lawsuit or similar action must search through available information to identify those documents and files that are relevant to the suit. Search efforts tend to identify less than 100% of the relevant documents and courts are frequently asked to adjudicate whether the search effort has been reasonable, or whether additional effort to find more of the relevant documents is justified. This article provides a method for estimating the probability that significant additional information will be found from extended effort. Modeling and two data sets indicate that the probability that facts/topics exist among the so-far unidentified documents that have not been observed in the identified documents is low for even moderate levels of Recall.
Single UHD Image Dehazing via Interpretable Pyramid Network
Feb 17, 2022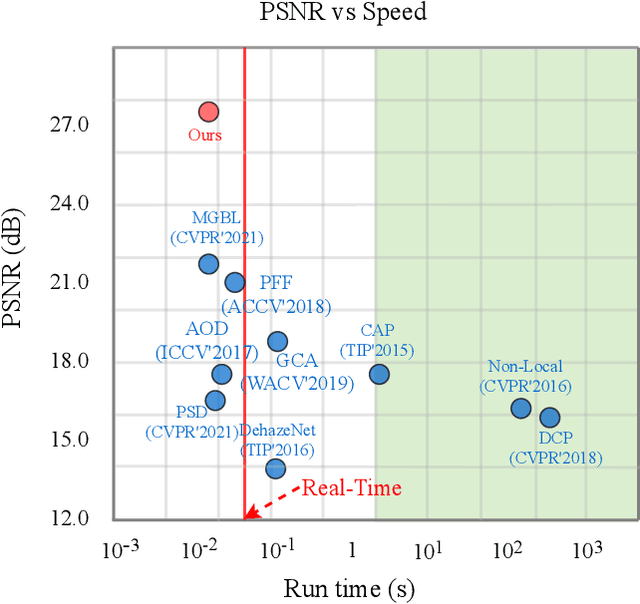

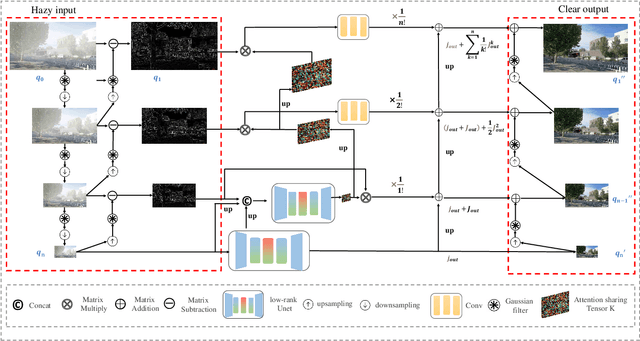

Currently, most single image dehazing models cannot run an ultra-high-resolution (UHD) image with a single GPU shader in real-time. To address the problem, we introduce the principle of infinite approximation of Taylor's theorem with the Laplace pyramid pattern to build a model which is capable of handling 4K hazy images in real-time. The N branch networks of the pyramid network correspond to the N constraint terms in Taylor's theorem. Low-order polynomials reconstruct the low-frequency information of the image (e.g. color, illumination). High-order polynomials regress the high-frequency information of the image (e.g. texture). In addition, we propose a Tucker reconstruction-based regularization term that acts on each branch network of the pyramid model. It further constrains the generation of anomalous signals in the feature space. Extensive experimental results demonstrate that our approach can not only run 4K images with haze in real-time on a single GPU (80FPS) but also has unparalleled interpretability. The developed method achieves state-of-the-art (SOTA) performance on two benchmarks (O/I-HAZE) and our updated 4KID dataset while providing the reliable groundwork for subsequent optimization schemes.
An Efficient Anchor-free Universal Lesion Detection in CT-scans
Mar 30, 2022
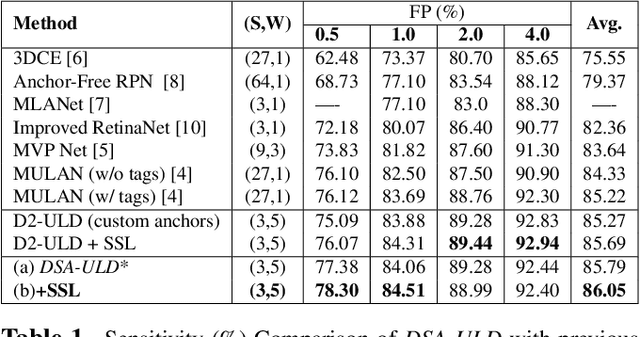
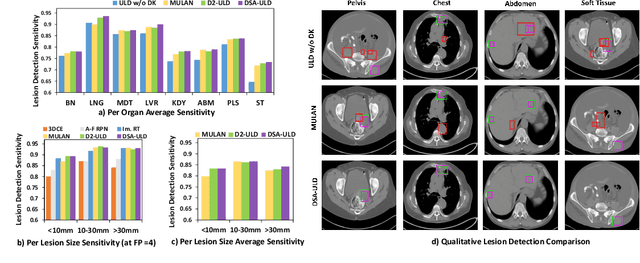
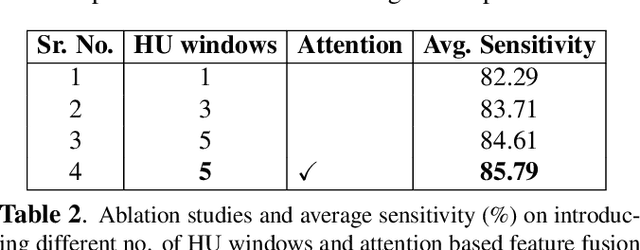
Existing universal lesion detection (ULD) methods utilize compute-intensive anchor-based architectures which rely on predefined anchor boxes, resulting in unsatisfactory detection performance, especially in small and mid-sized lesions. Further, these default fixed anchor-sizes and ratios do not generalize well to different datasets. Therefore, we propose a robust one-stage anchor-free lesion detection network that can perform well across varying lesions sizes by exploiting the fact that the box predictions can be sorted for relevance based on their center rather than their overlap with the object. Furthermore, we demonstrate that the ULD can be improved by explicitly providing it the domain-specific information in the form of multi-intensity images generated using multiple HU windows, followed by self-attention based feature-fusion and backbone initialization using weights learned via self-supervision over CT-scans. We obtain comparable results to the state-of-the-art methods, achieving an overall sensitivity of 86.05% on the DeepLesion dataset, which comprises of approximately 32K CT-scans with lesions annotated across various body organs.
* 4 Pages, 2 figures, 2 tables. Paper accepted at IEEE International Symposium on Biomedical Imaging (ISBI'22)
Where Does the Performance Improvement Come From? - A Reproducibility Concern about Image-Text Retrieval
Mar 08, 2022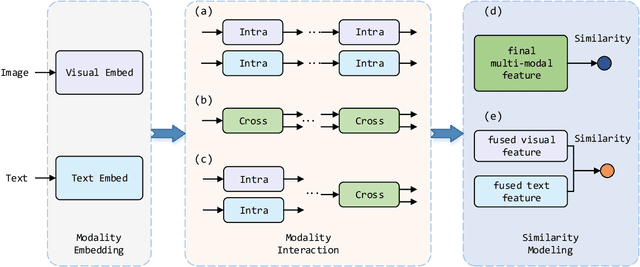
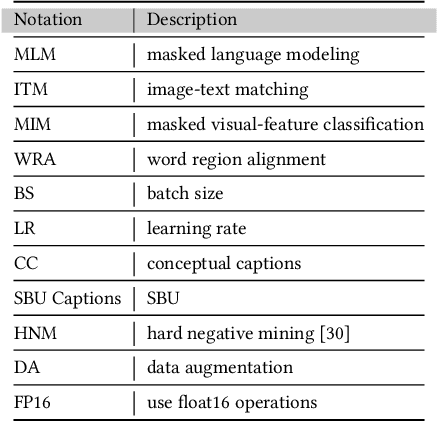
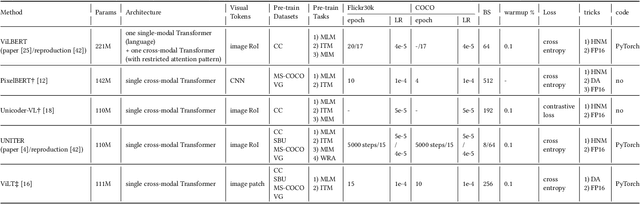
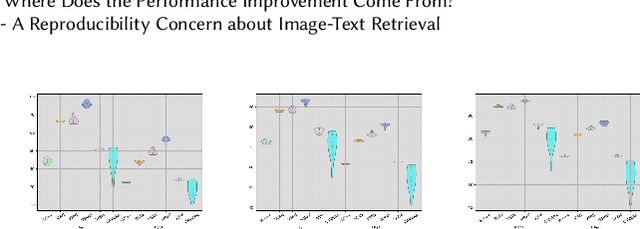
This paper seeks to provide the information retrieval community with some reflections on the current improvements of retrieval learning through the analysis of the reproducibility aspects of image-text retrieval models. For the latter part of the past decade, image-text retrieval has gradually become a major research direction in the field of information retrieval because of the growth of multi-modal data. Many researchers use benchmark datasets like MS-COCO and Flickr30k to train and assess the performance of image-text retrieval algorithms. Research in the past has mostly focused on performance, with several state-of-the-art methods being proposed in various ways. According to their claims, these approaches achieve better modal interactions and thus better multimodal representations with greater precision. In contrast to those previous works, we focus on the repeatability of the approaches and the overall examination of the elements that lead to improved performance by pretrained and nonpretrained models in retrieving images and text. To be more specific, we first examine the related reproducibility concerns and why the focus is on image-text retrieval tasks, and then we systematically summarize the current paradigm of image-text retrieval models and the stated contributions of those approaches. Second, we analyze various aspects of the reproduction of pretrained and nonpretrained retrieval models. Based on this, we conducted ablation experiments and obtained some influencing factors that affect retrieval recall more than the improvement claimed in the original paper. Finally, we also present some reflections and issues that should be considered by the retrieval community in the future. Our code is freely available at https://github.com/WangFei-2019/Image-text-Retrieval.
Soft-CP: A Credible and Effective Data Augmentation for Semantic Segmentation of Medical Lesions
Mar 20, 2022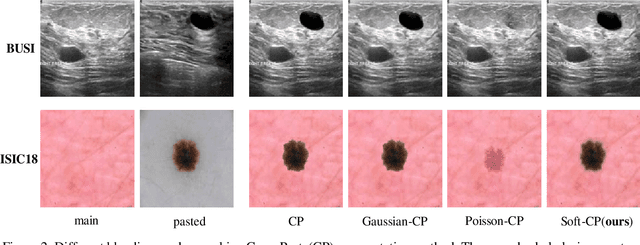
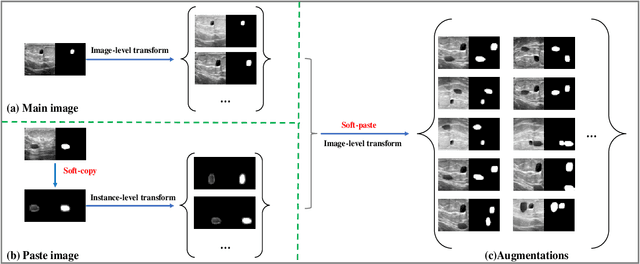
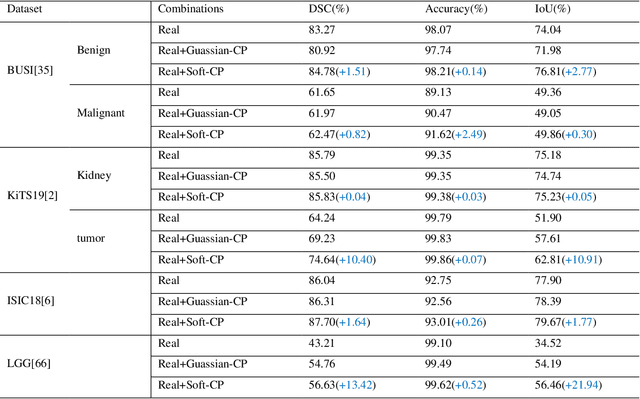
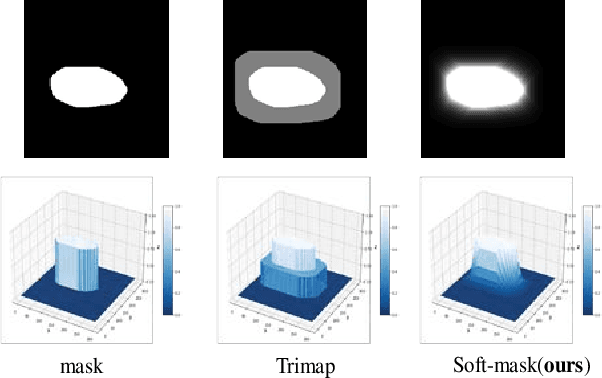
The medical datasets are usually faced with the problem of scarcity and data imbalance. Moreover, annotating large datasets for semantic segmentation of medical lesions is domain-knowledge and time-consuming. In this paper, we propose a new object-blend method(short in soft-CP) that combines the Copy-Paste augmentation method for semantic segmentation of medical lesions offline, ensuring the correct edge information around the lession to solve the issue above-mentioned. We proved the method's validity with several datasets in different imaging modalities. In our experiments on the KiTS19[2] dataset, Soft-CP outperforms existing medical lesions synthesis approaches. The Soft-CP augementation provides gains of +26.5% DSC in the low data regime(10% of data) and +10.2% DSC in the high data regime(all of data), In offline training data, the ratio of real images to synthetic images is 3:1.
Task-Oriented Semantic Communication Systems Based on Extended Rate-Distortion Theory
Jan 26, 2022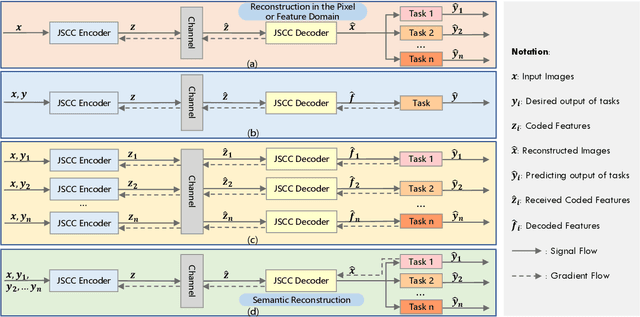


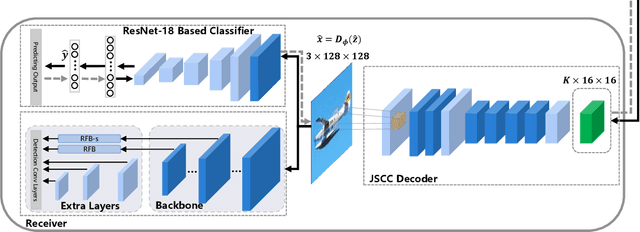
Considering the performance of intelligent task during signal exchange can help the communication system to automatically select those semantic parts which are helpful to perform the target task for compression and reconstruction, which can both greatly reduce the redundancy in signal and ensure the performance of the task. The traditional communication system based on rate-distortion theory treats all the information in the signal equally, but ignores their different importance to accomplish the task, which leads to waste of communication resources. In this paper, combined with the information bottleneck method, we present an extended rate-distortion theory which considers both concise representation and semantic distortion. Based on this theory, a task-oriented semantic image communication system is proposed. In order to verify that the proposed system can achieve performance improvement on different intelligent tasks, we apply the basic system trained with classification task to the system with object detection as the target task. The experimental results demonstrate that the proposed method outperforms the traditional and multi-task based communication system in terms of task performance at the same signal compression degree and noise interference degree. Furthermore, it is necessary to consider a compromise between rate-distortion theory and information bottleneck theory by comparing the pure rate-distortion scheme and the pure IB scheme.