 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemioLLM: Assessing Large Language Models for Semiological Analysis in Epilepsy Research
Jul 03, 2024



Large Language Models have shown promising results in their ability to encode general medical knowledge in standard medical question-answering datasets. However, their potential application in clinical practice requires evaluation in domain-specific tasks, where benchmarks are largely missing. In this study semioLLM, we test the ability of state-of-the-art LLMs (GPT-3.5, GPT-4, Mixtral 8x7B, and Qwen-72chat) to leverage their internal knowledge and reasoning for epilepsy diagnosis. Specifically, we obtain likelihood estimates linking unstructured text descriptions of seizures to seizure-generating brain regions, using an annotated clinical database containing 1269 entries. We evaluate the LLM's performance, confidence, reasoning, and citation abilities in comparison to clinical evaluation. Models achieve above-chance classification performance with prompt engineering significantly improving their outcome, with some models achieving close-to-clinical performance and reasoning. However, our analyses also reveal significant pitfalls with several models being overly confident while showing poor performance, as well as exhibiting citation errors and hallucinations. In summary, our work provides the first extensive benchmark comparing current SOTA LLMs in the medical domain of epilepsy and highlights their ability to leverage unstructured texts from patients' medical history to aid diagnostic processes in health care.
DeViL: Decoding Vision features into Language
Sep 04, 2023



Post-hoc explanation methods have often been criticised for abstracting away the decision-making process of deep neural networks. In this work, we would like to provide natural language descriptions for what different layers of a vision backbone have learned. Our DeViL method decodes vision features into language, not only highlighting the attribution locations but also generating textual descriptions of visual features at different layers of the network. We train a transformer network to translate individual image features of any vision layer into a prompt that a separate off-the-shelf language model decodes into natural language. By employing dropout both per-layer and per-spatial-location, our model can generalize training on image-text pairs to generate localized explanations. As it uses a pre-trained language model, our approach is fast to train, can be applied to any vision backbone, and produces textual descriptions at different layers of the vision network. Moreover, DeViL can create open-vocabulary attribution maps corresponding to words or phrases even outside the training scope of the vision model. We demonstrate that DeViL generates textual descriptions relevant to the image content on CC3M surpassing previous lightweight captioning models and attribution maps uncovering the learned concepts of the vision backbone. Finally, we show DeViL also outperforms the current state-of-the-art on the neuron-wise descriptions of the MILANNOTATIONS dataset. Code available at https://github.com/ExplainableML/DeViL
An Efficient Anchor-free Universal Lesion Detection in CT-scans
Mar 30, 2022
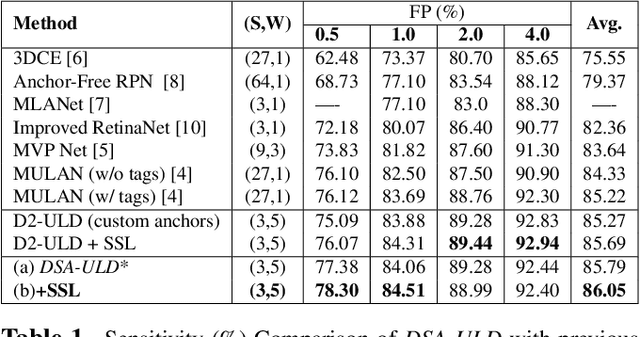
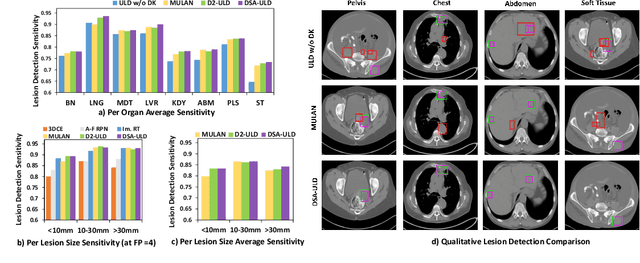
Existing universal lesion detection (ULD) methods utilize compute-intensive anchor-based architectures which rely on predefined anchor boxes, resulting in unsatisfactory detection performance, especially in small and mid-sized lesions. Further, these default fixed anchor-sizes and ratios do not generalize well to different datasets. Therefore, we propose a robust one-stage anchor-free lesion detection network that can perform well across varying lesions sizes by exploiting the fact that the box predictions can be sorted for relevance based on their center rather than their overlap with the object. Furthermore, we demonstrate that the ULD can be improved by explicitly providing it the domain-specific information in the form of multi-intensity images generated using multiple HU windows, followed by self-attention based feature-fusion and backbone initialization using weights learned via self-supervision over CT-scans. We obtain comparable results to the state-of-the-art methods, achieving an overall sensitivity of 86.05% on the DeepLesion dataset, which comprises of approximately 32K CT-scans with lesions annotated across various body organs.
* 4 Pages, 2 figures, 2 tables. Paper accepted at IEEE International Symposium on Biomedical Imaging (ISBI'22)
DKMA-ULD: Domain Knowledge augmented Multi-head Attention based Robust Universal Lesion Detection
Mar 14, 2022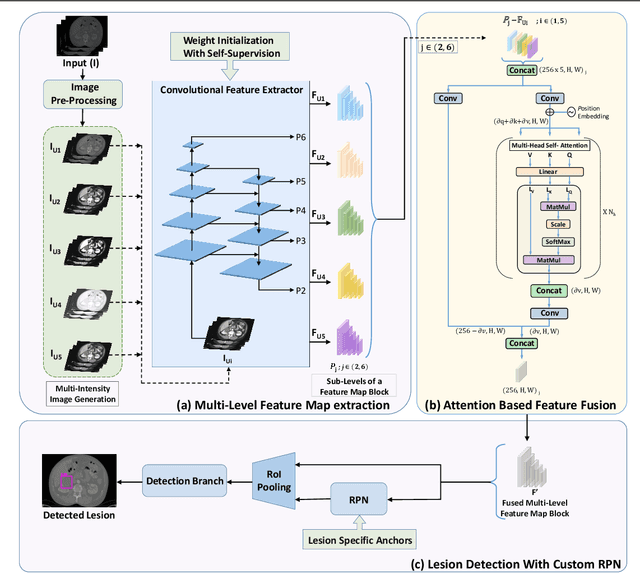
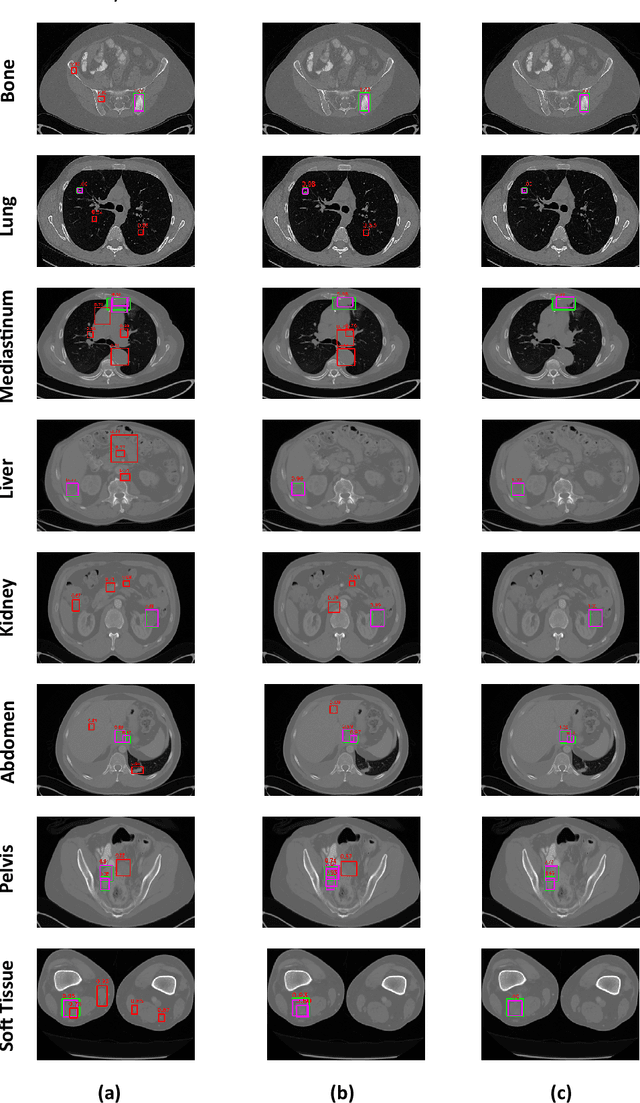
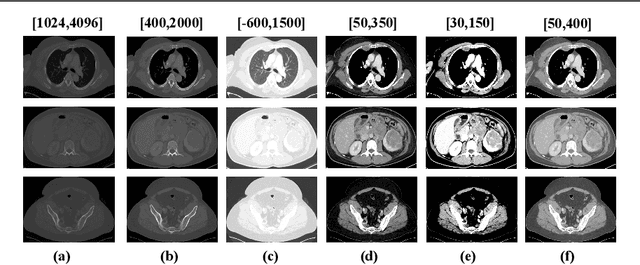
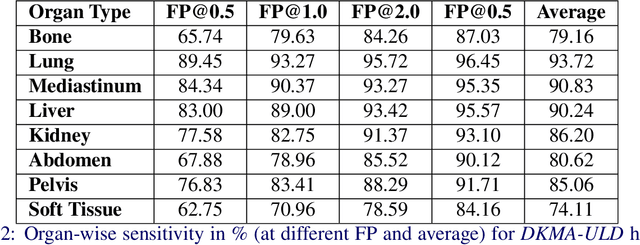
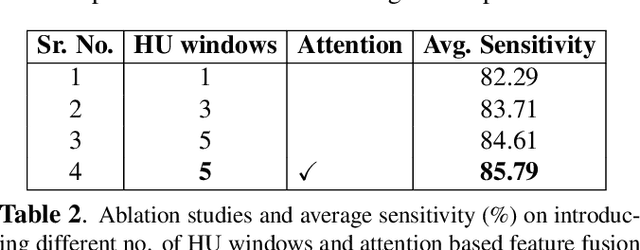
Incorporating data-specific domain knowledge in deep networks explicitly can provide important cues beneficial for lesion detection and can mitigate the need for diverse heterogeneous datasets for learning robust detectors. In this paper, we exploit the domain information present in computed tomography (CT) scans and propose a robust universal lesion detection (ULD) network that can detect lesions across all organs of the body by training on a single dataset, DeepLesion. We analyze CT-slices of varying intensities, generated using heuristically determined Hounsfield Unit(HU) windows that individually highlight different organs and are given as inputs to the deep network. The features obtained from the multiple intensity images are fused using a novel convolution augmented multi-head self-attention module and subsequently, passed to a Region Proposal Network (RPN) for lesion detection. In addition, we observed that traditional anchor boxes used in RPN for natural images are not suitable for lesion sizes often found in medical images. Therefore, we propose to use lesion-specific anchor sizes and ratios in the RPN for improving the detection performance. We use self-supervision to initialize weights of our network on the DeepLesion dataset to further imbibe domain knowledge. Our proposed Domain Knowledge augmented Multi-head Attention based Universal Lesion Detection Network DMKA-ULD produces refined and precise bounding boxes around lesions across different organs. We evaluate the efficacy of our network on the publicly available DeepLesion dataset which comprises of approximately 32K CT scans with annotated lesions across all organs of the body. Results demonstrate that we outperform existing state-of-the-art methods achieving an overall sensitivity of 87.16%.
* Main Paper: 13 Pages, 5 Figures, 2 Tables. Supplementary: 4 Pages, 1 Figure, 3 Tables. Paper accepted at The 32nd British Machine Vision Conference (BMVC'21)