 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attention in Attention: Modeling Context Correlation for Efficient Video Classification
Apr 20, 2022
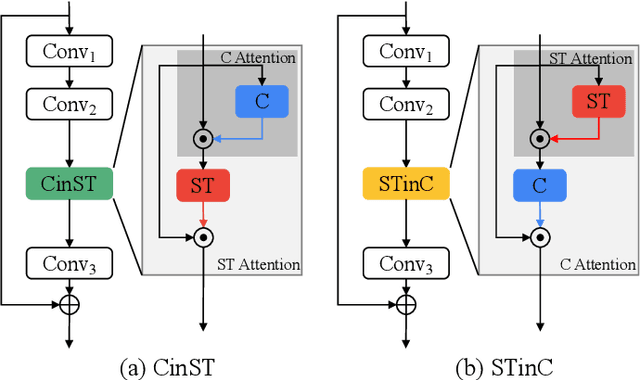
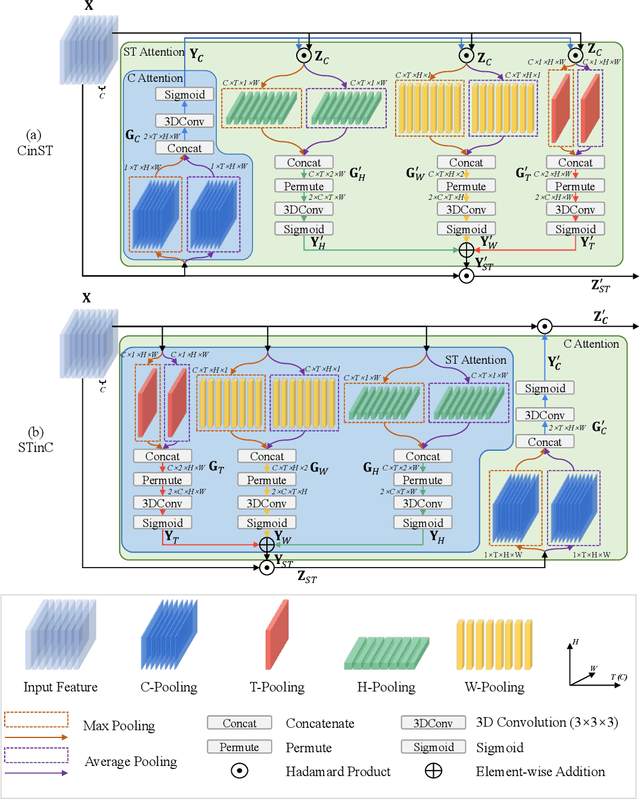
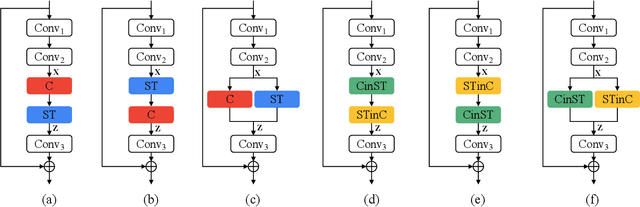
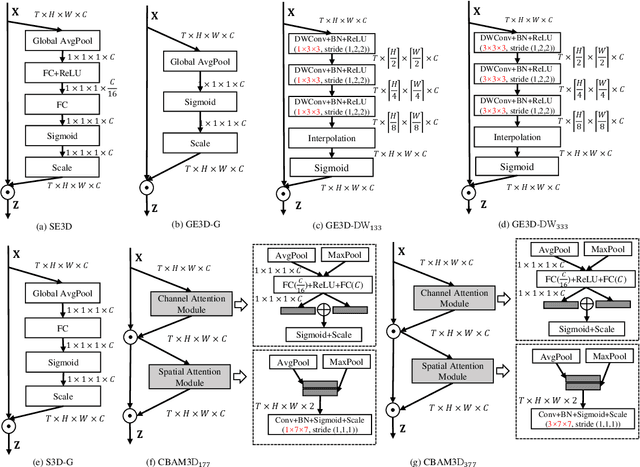
Attention mechanisms have significantly boosted the performance of video classification neural networks thanks to the utilization of perspective contexts. However, the current research on video attention generally focuses on adopting a specific aspect of contexts (e.g., channel, spatial/temporal, or global context) to refine the features and neglects their underlying correlation when computing attentions. This leads to incomplete context utilization and hence bears the weakness of limited performance improvement. To tackle the problem, this paper proposes an efficient attention-in-attention (AIA) method for element-wise feature refinement, which investigates the feasibility of inserting the channel context into the spatio-temporal attention learning module, referred to as CinST, and also its reverse variant, referred to as STinC. Specifically, we instantiate the video feature contexts as dynamics aggregated along a specific axis with global average and max pooling operations. The workflow of an AIA module is that the first attention block uses one kind of context information to guide the gating weights calculation of the second attention that targets at the other context. Moreover, all the computational operations in attention units act on the pooled dimension, which results in quite few computational cost increase ($<$0.02\%). To verify our method, we densely integrate it into two classical video network backbones and conduct extensive experiments on several standard video classification benchmarks. The source code of our AIA is available at \url{https://github.com/haoyanbin918/Attention-in-Attention}.
Pre-Training Transformer Decoder for End-to-End ASR Model with Unpaired Speech Data
Mar 31, 2022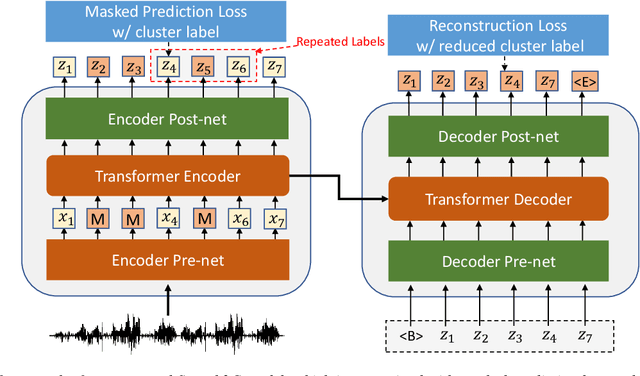
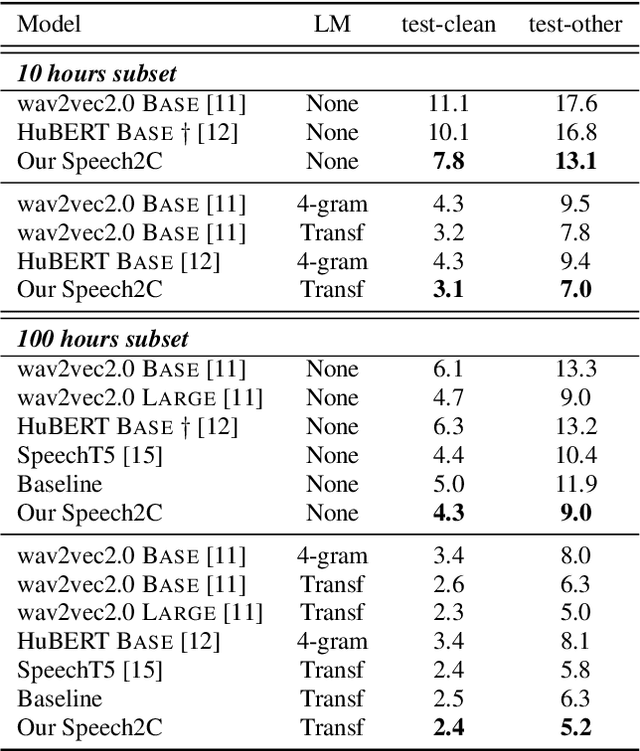

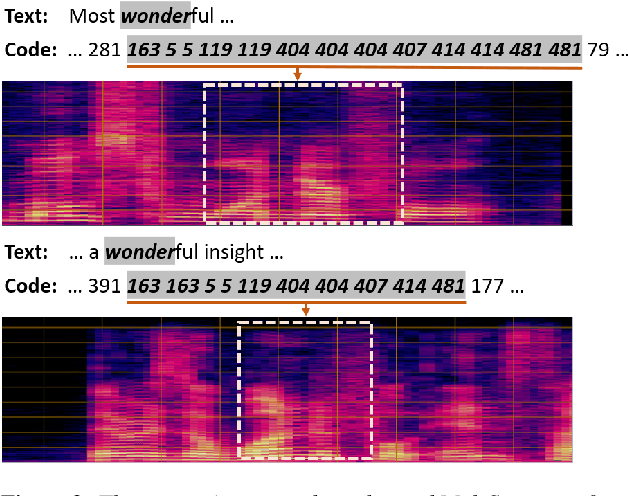
This paper studies a novel pre-training technique with unpaired speech data, Speech2C, for encoder-decoder based automatic speech recognition (ASR). Within a multi-task learning framework, we introduce two pre-training tasks for the encoder-decoder network using acoustic units, i.e., pseudo codes, derived from an offline clustering model. One is to predict the pseudo codes via masked language modeling in encoder output, like HuBERT model, while the other lets the decoder learn to reconstruct pseudo codes autoregressively instead of generating textual scripts. In this way, the decoder learns to reconstruct original speech information with codes before learning to generate correct text. Comprehensive experiments on the LibriSpeech corpus show that the proposed Speech2C can relatively reduce the word error rate (WER) by 19.2% over the method without decoder pre-training, and also outperforms significantly the state-of-the-art wav2vec 2.0 and HuBERT on fine-tuning subsets of 10h and 100h.
Explainability and Graph Learning from Social Interactions
Mar 14, 2022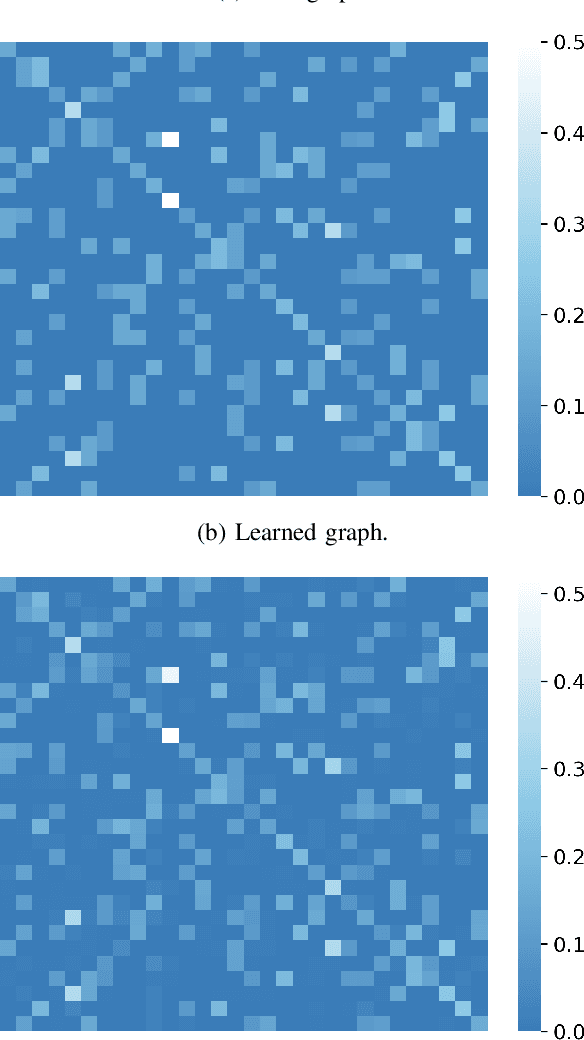
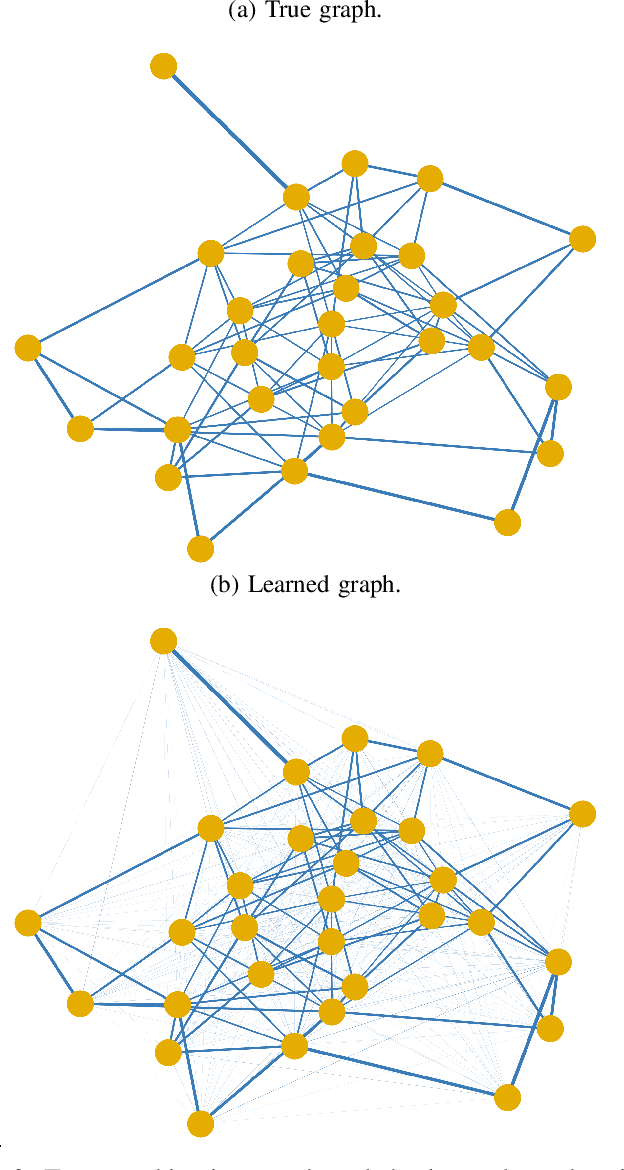
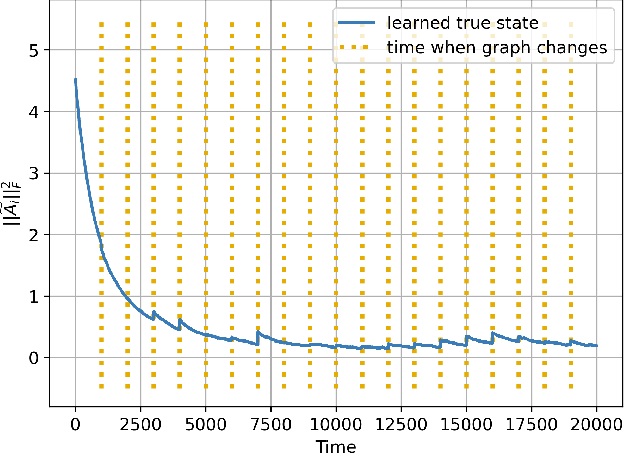
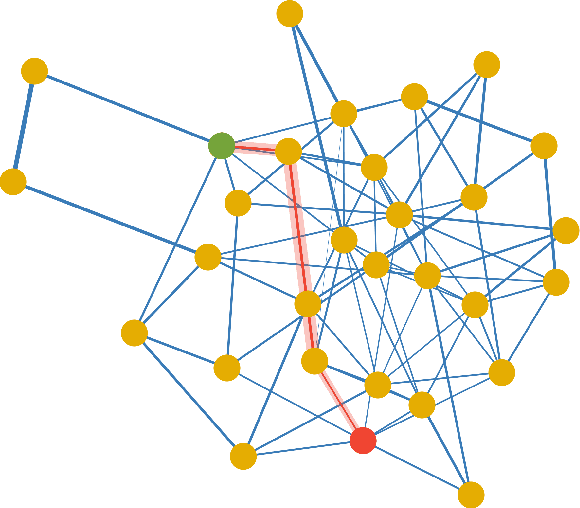
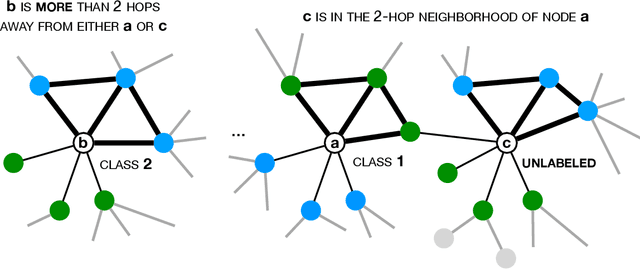
Social learning algorithms provide models for the formation of opinions over social networks resulting from local reasoning and peer-to-peer exchanges. Interactions occur over an underlying graph topology, which describes the flow of information among the agents. In this work, we propose a technique that addresses questions of explainability and interpretability when the graph is hidden. Given observations of the evolution of the belief over time, we aim to infer the underlying graph topology, discover pairwise influences between the agents, and identify significant trajectories in the network. The proposed framework is online in nature and can adapt dynamically to changes in the graph topology or the true hypothesis.
Learning Dual-Pixel Alignment for Defocus Deblurring
Apr 26, 2022



It is a challenging task to recover all-in-focus image from a single defocus blurry image in real-world applications. On many modern cameras, dual-pixel (DP) sensors create two-image views, based on which stereo information can be exploited to benefit defocus deblurring. Despite existing DP defocus deblurring methods achieving impressive results, they directly take naive concatenation of DP views as input, while neglecting the disparity between left and right views in the regions out of camera's depth of field (DoF). In this work, we propose a Dual-Pixel Alignment Network (DPANet) for defocus deblurring. Generally, DPANet is an encoder-decoder with skip-connections, where two branches with shared parameters in the encoder are employed to extract and align deep features from left and right views, and one decoder is adopted to fuse aligned features for predicting the all-in-focus image. Due to that DP views suffer from different blur amounts, it is not trivial to align left and right views. To this end, we propose novel encoder alignment module (EAM) and decoder alignment module (DAM). In particular, a correlation layer is suggested in EAM to measure the disparity between DP views, whose deep features can then be accordingly aligned using deformable convolutions. And DAM can further enhance the alignment of skip-connected features from encoder and deep features in decoder. By introducing several EAMs and DAMs, DP views in DPANet can be well aligned for better predicting latent all-in-focus image. Experimental results on real-world datasets show that our DPANet is notably superior to state-of-the-art deblurring methods in reducing defocus blur while recovering visually plausible sharp structures and textures.
Sparsity-aware neural user behavior modeling in online interaction platforms
Feb 28, 2022


Modern online platforms offer users an opportunity to participate in a variety of content-creation, social networking, and shopping activities. With the rapid proliferation of such online services, learning data-driven user behavior models is indispensable to enable personalized user experiences. Recently, representation learning has emerged as an effective strategy for user modeling, powered by neural networks trained over large volumes of interaction data. Despite their enormous potential, we encounter the unique challenge of data sparsity for a vast majority of entities, e.g., sparsity in ground-truth labels for entities and in entity-level interactions (cold-start users, items in the long-tail, and ephemeral groups). In this dissertation, we develop generalizable neural representation learning frameworks for user behavior modeling designed to address different sparsity challenges across applications. Our problem settings span transductive and inductive learning scenarios, where transductive learning models entities seen during training and inductive learning targets entities that are only observed during inference. We leverage different facets of information reflecting user behavior (e.g., interconnectivity in social networks, temporal and attributed interaction information) to enable personalized inference at scale. Our proposed models are complementary to concurrent advances in neural architectural choices and are adaptive to the rapid addition of new applications in online platforms.
vue4logs -- Automatic Structuring of Heterogeneous Computer System Logs
Feb 14, 2022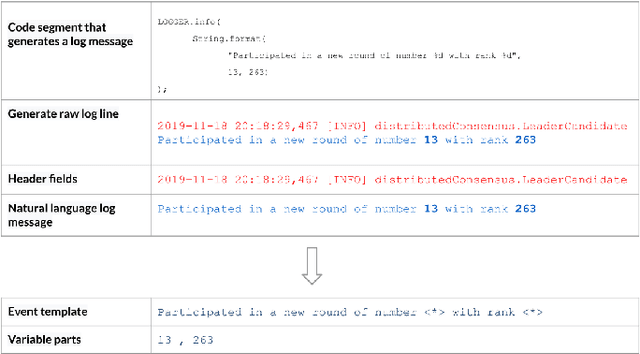

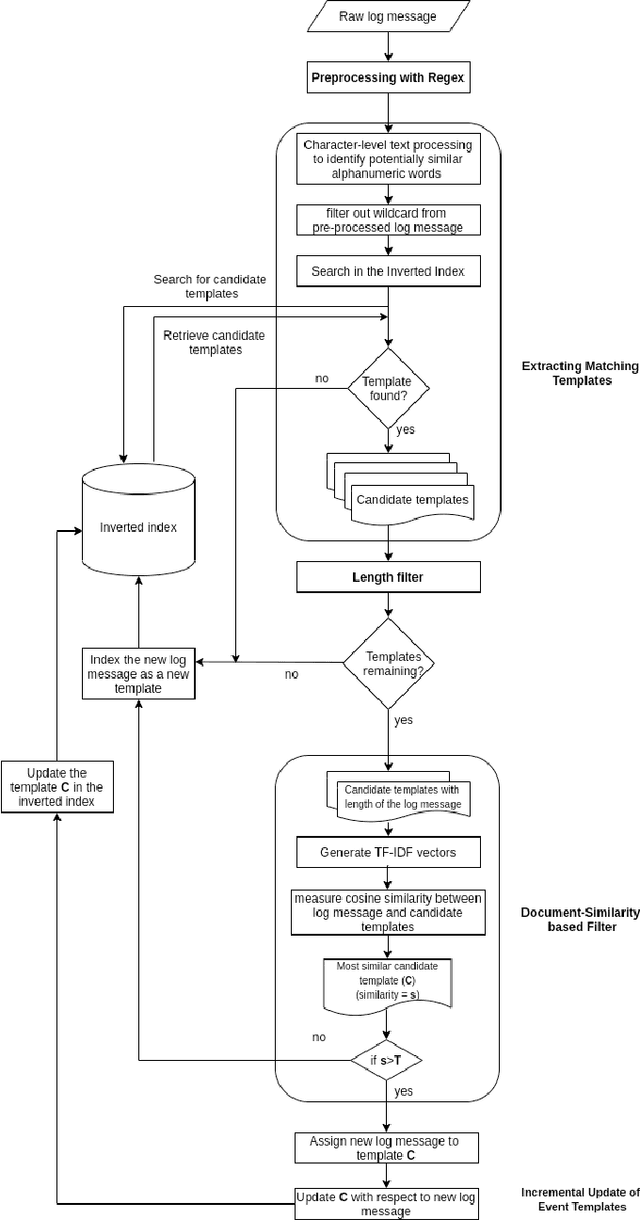
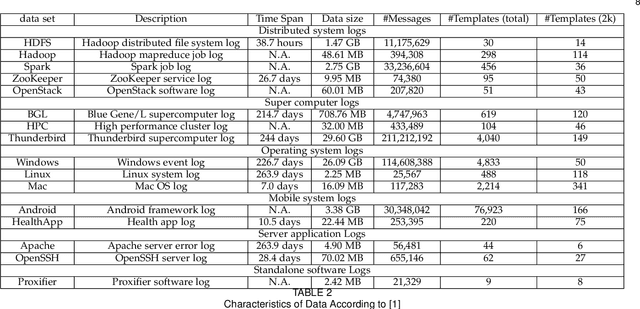
Computer system log data is commonly used in system monitoring, performance characteristic investigation, workflow modeling and anomaly detection. Log data is inherently unstructured or semi-structured, which makes it harder to understand the event flow or other important information of a system by reading raw logs. The process of structuring log files first identifies the log message groups based on the system events that triggered them, and extracts an event template to represent the log messages of each event. This paper introduces a novel method to extract event templates from raw system log files, by using the vector space model commonly used in the field of Information Retrieval to vectorize log data and group log messages into event templates based on their vector similarity. Template extraction process is further enhanced with the use of character and length based filters. When evaluated on publicly available real-world log data benchmarks, this proposed method outperforms all the available state-of-the-art systems in terms of accuracy and robustness.
Neural Forecasting of the Italian Sovereign Bond Market with Economic News
Mar 11, 2022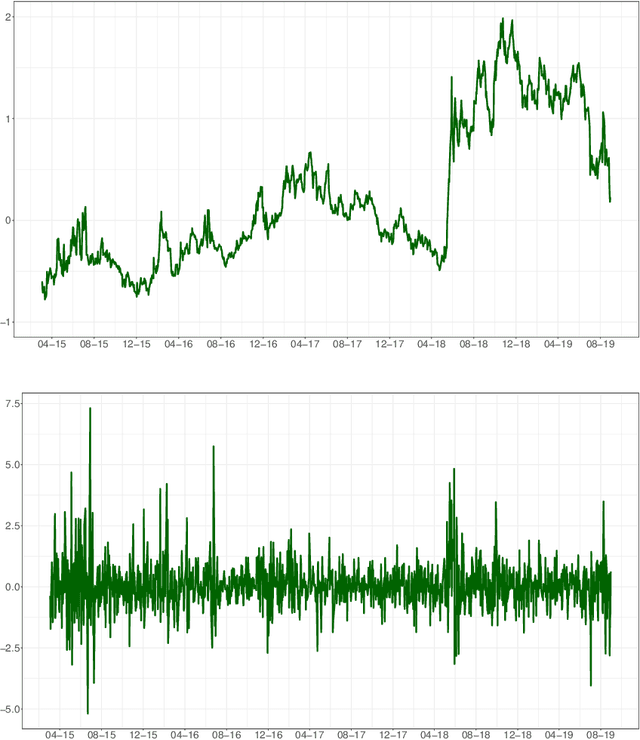
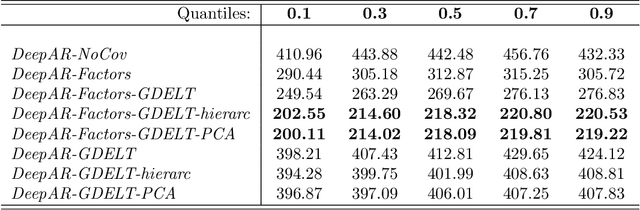
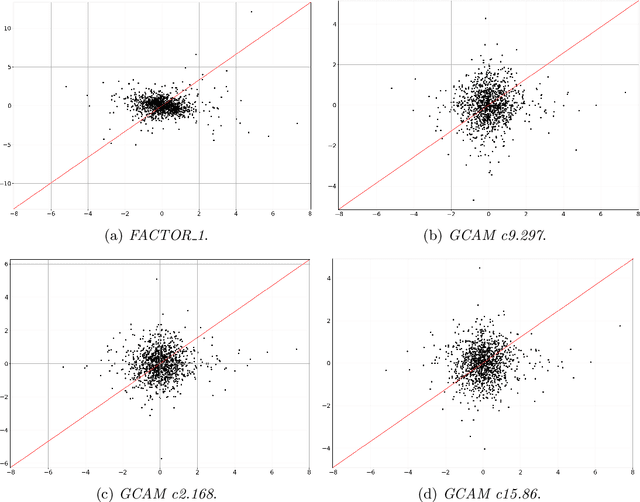
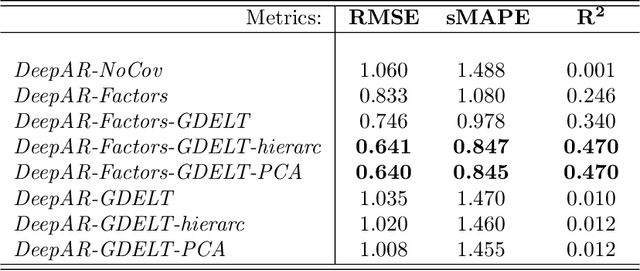
In this paper we employ economic news within a neural network framework to forecast the Italian 10-year interest rate spread. We use a big, open-source, database known as Global Database of Events, Language and Tone to extract topical and emotional news content linked to bond markets dynamics. We deploy such information within a probabilistic forecasting framework with autoregressive recurrent networks (DeepAR). Our findings suggest that a deep learning network based on Long-Short Term Memory cells outperforms classical machine learning techniques and provides a forecasting performance that is over and above that obtained by using conventional determinants of interest rates alone.
* 24 pages, 8 figures, in press
Scalable Motif Counting for Large-scale Temporal Graphs
Apr 20, 2022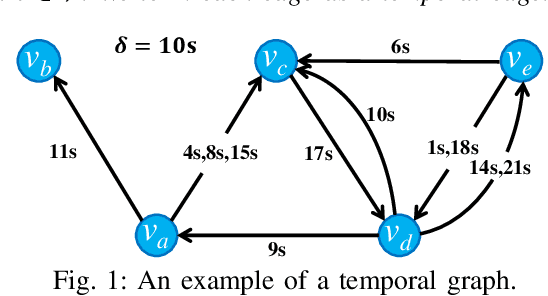
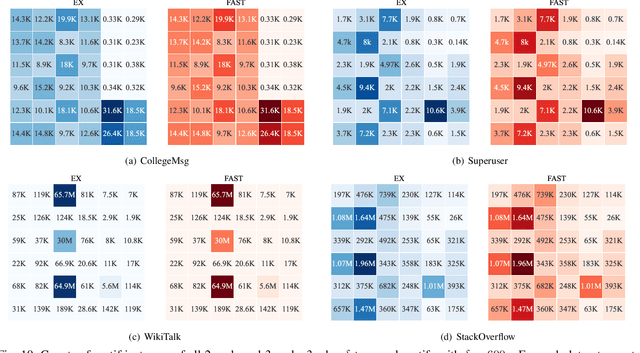
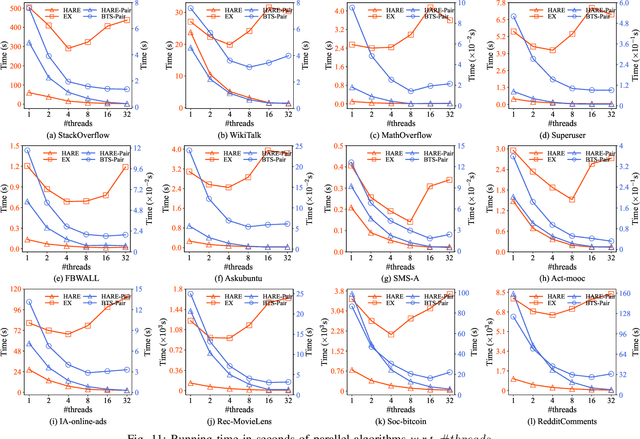
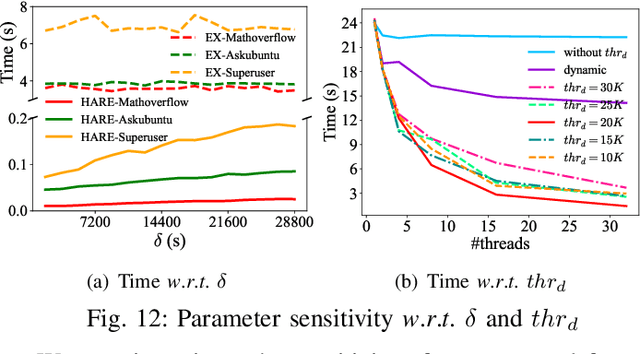
One fundamental problem in temporal graph analysis is to count the occurrences of small connected subgraph patterns (i.e., motifs), which benefits a broad range of real-world applications, such as anomaly detection, structure prediction, and network representation learning. However, existing works focused on exacting temporal motif are not scalable to large-scale temporal graph data, due to their heavy computational costs or inherent inadequacy of parallelism. In this work, we propose a scalable parallel framework for exactly counting temporal motifs in large-scale temporal graphs. We first categorize the temporal motifs based on their distinct properties, and then design customized algorithms that offer efficient strategies to exactly count the motif instances of each category. Moreover, our compact data structures, namely triple and quadruple counters, enable our algorithms to directly identify the temporal motif instances of each category, according to edge information and the relationship between edges, therefore significantly improving the counting efficiency. Based on the proposed counting algorithms, we design a hierarchical parallel framework that features both inter- and intra-node parallel strategies, and fully leverages the multi-threading capacity of modern CPU to concurrently count all temporal motifs. Extensive experiments on sixteen real-world temporal graph datasets demonstrate the superiority and capability of our proposed framework for temporal motif counting, achieving up to 538* speedup compared to the state-of-the-art methods. The source code of our method is available at: https://github.com/steven-ccq/FAST-temporal-motif.
On consistency of constrained spectral clustering under representation-aware stochastic block model
Mar 03, 2022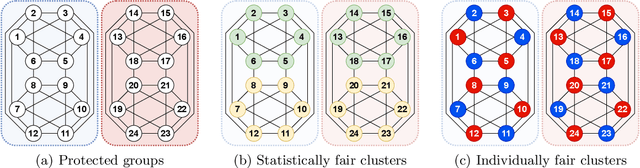
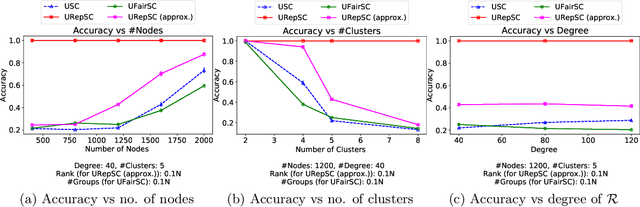
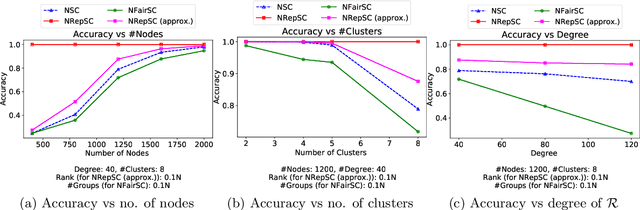
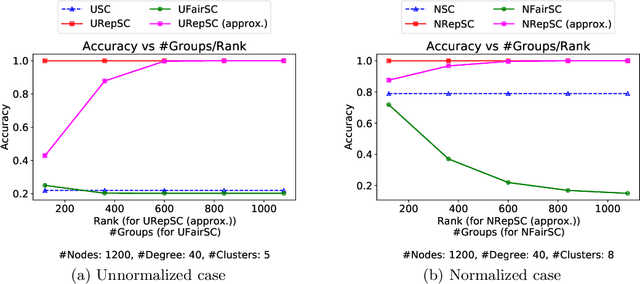
Spectral clustering is widely used in practice due to its flexibility, computational efficiency, and well-understood theoretical performance guarantees. Recently, spectral clustering has been studied to find balanced clusters under population-level constraints. These constraints are specified by additional information available in the form of auxiliary categorical node attributes. In this paper, we consider a scenario where these attributes may not be observable, but manifest as latent features of an auxiliary graph. Motivated by this, we study constrained spectral clustering with the aim of finding balanced clusters in a given \textit{similarity graph} $\mathcal{G}$, such that each individual is adequately represented with respect to an auxiliary graph $\mathcal{R}$ (we refer to this as representation graph). We propose an individual-level balancing constraint that formalizes this idea. Our work leads to an interesting stochastic block model that not only plants the given partitions in $\mathcal{G}$ but also plants the auxiliary information encoded in the representation graph $\mathcal{R}$. We develop unnormalized and normalized variants of spectral clustering in this setting. These algorithms use $\mathcal{R}$ to find clusters in $\mathcal{G}$ that approximately satisfy the proposed constraint. We also establish the first statistical consistency result for constrained spectral clustering under individual-level constraints for graphs sampled from the above-mentioned variant of the stochastic block model. Our experimental results corroborate our theoretical findings.
Dynamic Neural Textures: Generating Talking-Face Videos with Continuously Controllable Expressions
Apr 13, 2022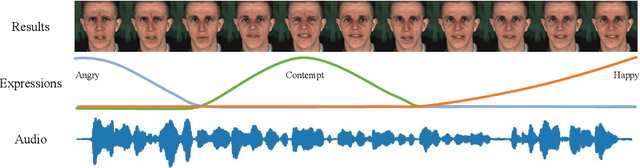
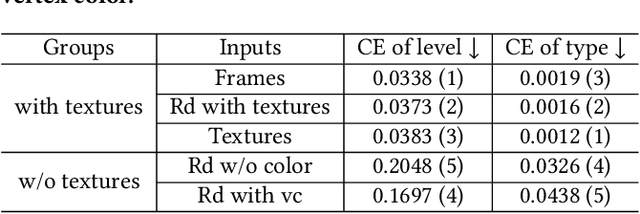
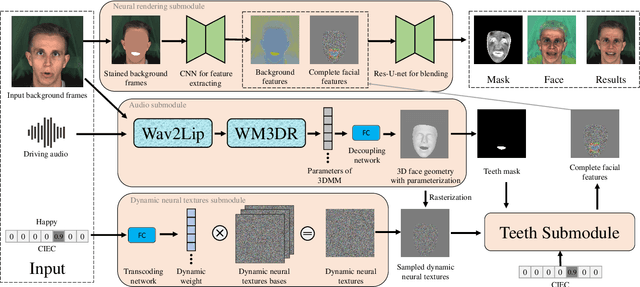
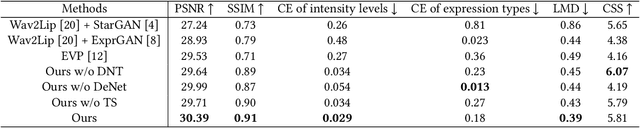
Recently, talking-face video generation has received considerable attention. So far most methods generate results with neutral expressions or expressions that are implicitly determined by neural networks in an uncontrollable way. In this paper, we propose a method to generate talking-face videos with continuously controllable expressions in real-time. Our method is based on an important observation: In contrast to facial geometry of moderate resolution, most expression information lies in textures. Then we make use of neural textures to generate high-quality talking face videos and design a novel neural network that can generate neural textures for image frames (which we called dynamic neural textures) based on the input expression and continuous intensity expression coding (CIEC). Our method uses 3DMM as a 3D model to sample the dynamic neural texture. The 3DMM does not cover the teeth area, so we propose a teeth submodule to complete the details in teeth. Results and an ablation study show the effectiveness of our method in generating high-quality talking-face videos with continuously controllable expressions. We also set up four baseline methods by combining existing representative methods and compare them with our method. Experimental results including a user study show that our method has the best performance.