 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Localized and Disentangled Knowledge Editing for Multimodal Large Language Models
May 28, 2026Existing methods in Multimodal Knowledge Editing (MKE) have advanced the ability to correct outdated or inaccurate knowledge in Multimodal Large Language Models (MLLMs). However, they exhibit a critical limitation: while effectively modifying target factual pairs, they fail to generalize edits to logically related queries and often cause unintended alterations to unrelated but visually or semantically linked information. We identify and formalize two underlying failure modes causing this issue: Causal Misalignment, which confines edits to the specific sample, and Feature Entanglement, which causes unintended alterations to coupled but irrelevant information. To address these issues, we propose Localized and Disentangled Knowledge Editing (LDKE), a new framework that achieves precise and generalized editing by localizing fact-specific model layers and disentangling target-relevant inputs from irrelevant ones. Our approach introduces a Fast Localization module to identify and update critical layers efficiently, along with a Disentanglement Classifier that routes inputs appropriately to preserve unrelated knowledge. Extensive experiments across various benchmarks and MLLMs demonstrate that LDKE achieves superior performance in propagating edits to related contexts while maintaining high locality.
Layer Consistency Matters: Elegant Latent Transition Discrepancy for Generalizable Synthetic Image Detection
Mar 11, 2026Recent rapid advancement of generative models has significantly improved the fidelity and accessibility of AI-generated synthetic images. While enabling various innovative applications, the unprecedented realism of these synthetics makes them increasingly indistinguishable from authentic photographs, posing serious security risks, such as media credibility and content manipulation. Although extensive efforts have been dedicated to detecting synthetic images, most existing approaches suffer from poor generalization to unseen data due to their reliance on model-specific artifacts or low-level statistical cues. In this work, we identify a previously unexplored distinction that real images maintain consistent semantic attention and structural coherence in their latent representations, exhibiting more stable feature transitions across network layers, whereas synthetic ones present discernible distinct patterns. Therefore, we propose a novel approach termed latent transition discrepancy (LTD), which captures the inter-layer consistency differences of real and synthetic images. LTD adaptively identifies the most discriminative layers and assesses the transition discrepancies across layers. Benefiting from the proposed inter-layer discriminative modeling, our approach exceeds the base model by 14.35\% in mean Acc across three datasets containing diverse GANs and DMs. Extensive experiments demonstrate that LTD outperforms recent state-of-the-art methods, achieving superior detection accuracy, generalizability, and robustness. The code is available at https://github.com/yywencs/LTD
Attention in Attention: Modeling Context Correlation for Efficient Video Classification
Apr 20, 2022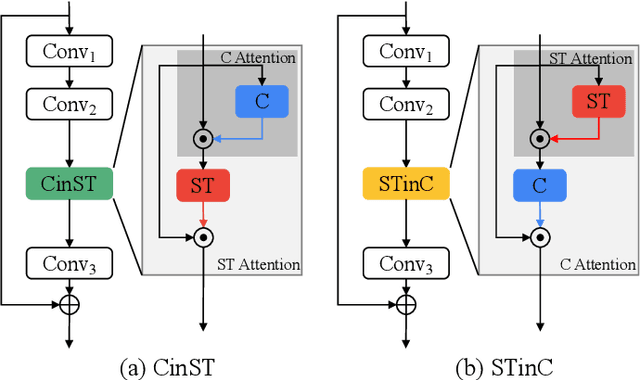
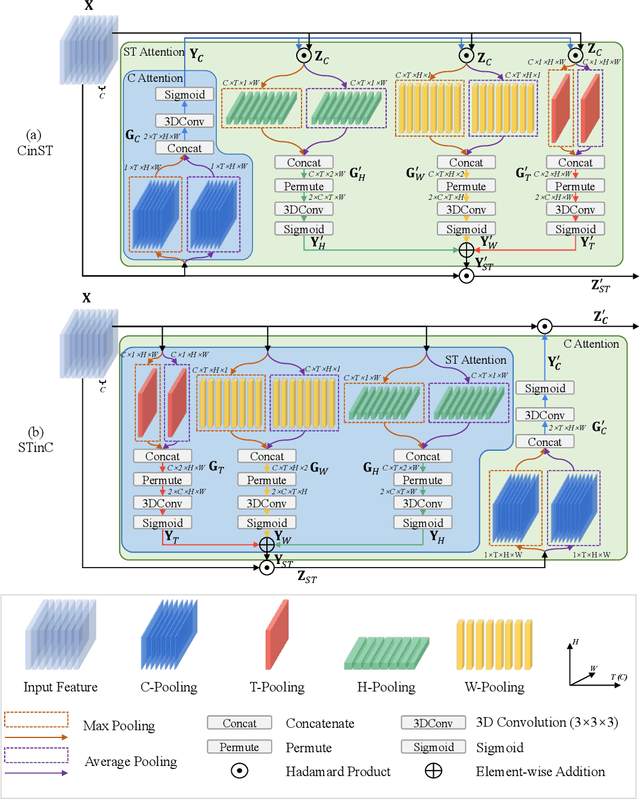
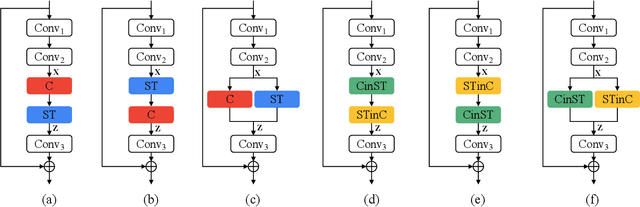
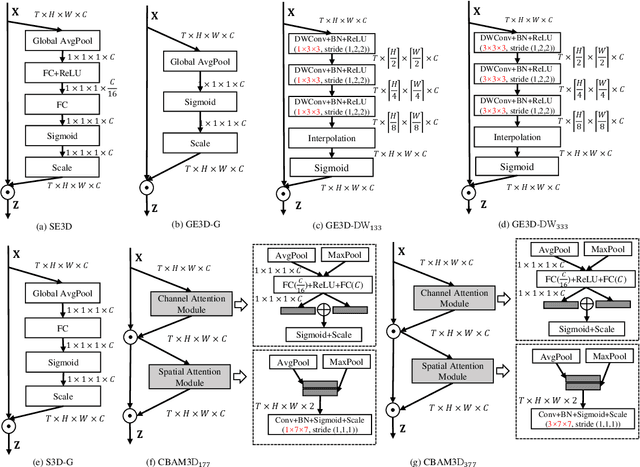
Attention mechanisms have significantly boosted the performance of video classification neural networks thanks to the utilization of perspective contexts. However, the current research on video attention generally focuses on adopting a specific aspect of contexts (e.g., channel, spatial/temporal, or global context) to refine the features and neglects their underlying correlation when computing attentions. This leads to incomplete context utilization and hence bears the weakness of limited performance improvement. To tackle the problem, this paper proposes an efficient attention-in-attention (AIA) method for element-wise feature refinement, which investigates the feasibility of inserting the channel context into the spatio-temporal attention learning module, referred to as CinST, and also its reverse variant, referred to as STinC. Specifically, we instantiate the video feature contexts as dynamics aggregated along a specific axis with global average and max pooling operations. The workflow of an AIA module is that the first attention block uses one kind of context information to guide the gating weights calculation of the second attention that targets at the other context. Moreover, all the computational operations in attention units act on the pooled dimension, which results in quite few computational cost increase ($<$0.02\%). To verify our method, we densely integrate it into two classical video network backbones and conduct extensive experiments on several standard video classification benchmarks. The source code of our AIA is available at \url{https://github.com/haoyanbin918/Attention-in-Attention}.