 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Modal Hypergraph Diffusion Network with Dual Prior for Alzheimer Classification
Apr 04, 2022
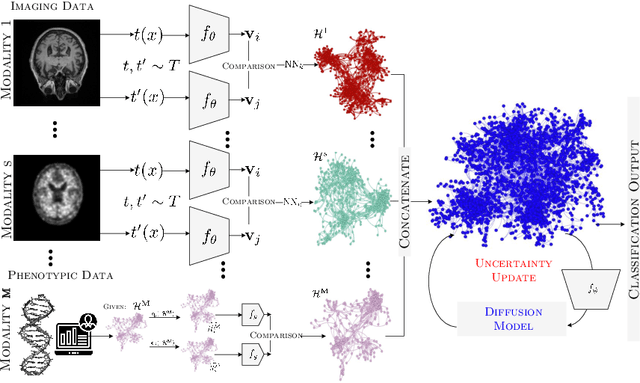
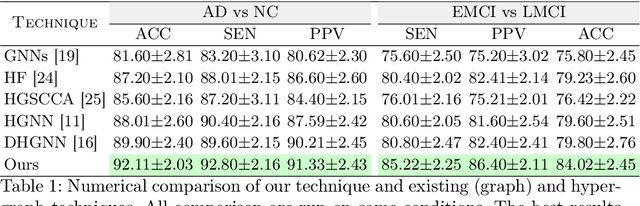
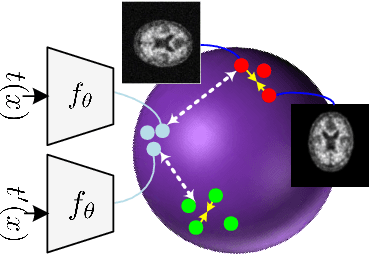
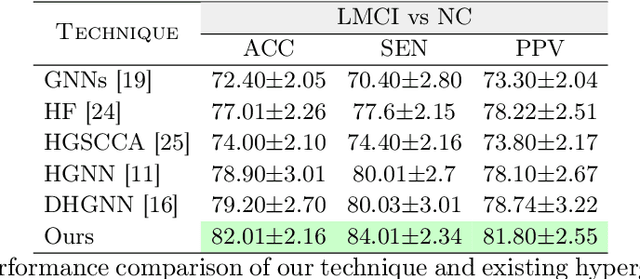
The automatic early diagnosis of prodromal stages of Alzheimer's disease is of great relevance for patient treatment to improve quality of life. We address this problem as a multi-modal classification task. Multi-modal data provides richer and complementary information. However, existing techniques only consider either lower order relations between the data and single/multi-modal imaging data. In this work, we introduce a novel semi-supervised hypergraph learning framework for Alzheimer's disease diagnosis. Our framework allows for higher-order relations among multi-modal imaging and non-imaging data whilst requiring a tiny labelled set. Firstly, we introduce a dual embedding strategy for constructing a robust hypergraph that preserves the data semantics. We achieve this by enforcing perturbation invariance at the image and graph levels using a contrastive based mechanism. Secondly, we present a dynamically adjusted hypergraph diffusion model, via a semi-explicit flow, to improve the predictive uncertainty. We demonstrate, through our experiments, that our framework is able to outperform current techniques for Alzheimer's disease diagnosis.
Learning the Proximity Operator in Unfolded ADMM for Phase Retrieval
Apr 04, 2022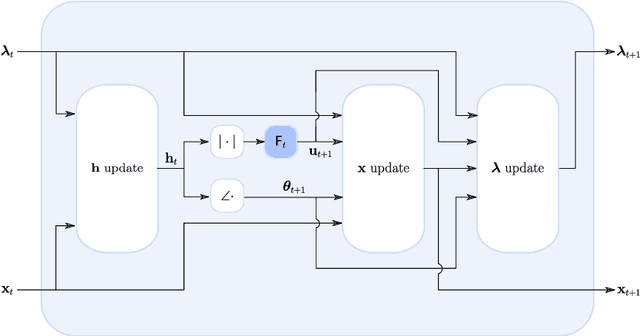
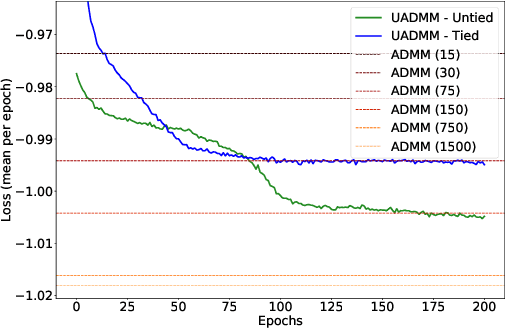
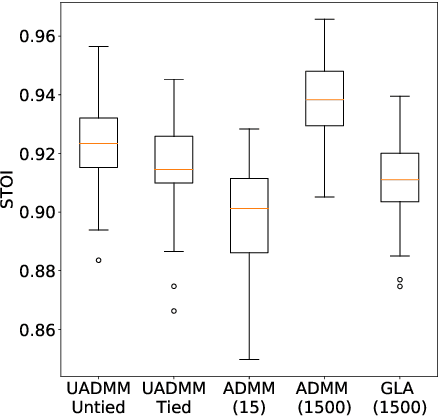
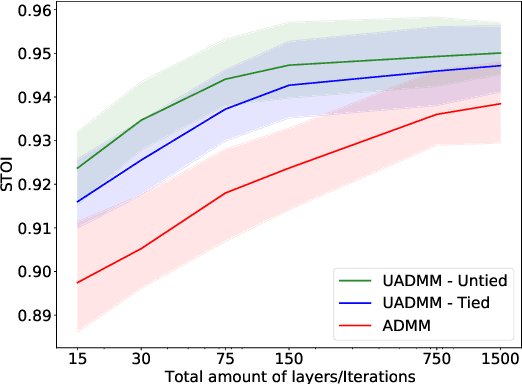
This paper considers the phase retrieval (PR) problem, which aims to reconstruct a signal from phaseless measurements such as magnitude or power spectrograms. PR is generally handled as a minimization problem involving a quadratic loss. Recent works have considered alternative discrepancy measures, such as the Bregman divergences, but it is still challenging to tailor the optimal loss for a given setting. In this paper we propose a novel strategy to automatically learn the optimal metric for PR. We unfold a recently introduced ADMM algorithm into a neural network, and we emphasize that the information about the loss used to formulate the PR problem is conveyed by the proximity operator involved in the ADMM updates. Therefore, we replace this proximity operator with trainable activation functions: learning these in a supervised setting is then equivalent to learning an optimal metric for PR. Experiments conducted with speech signals show that our approach outperforms the baseline ADMM, using a light and interpretable neural architecture.
Beyond Images: Label Noise Transition Matrix Estimation for Tasks with Lower-Quality Features
Feb 02, 2022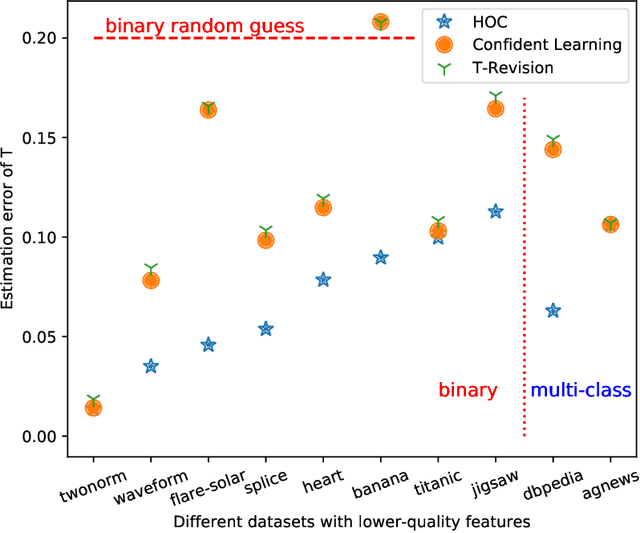
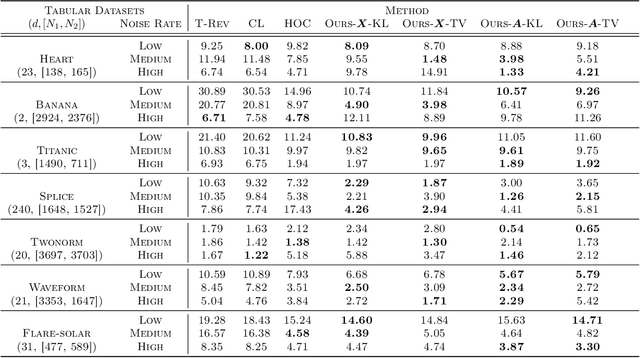
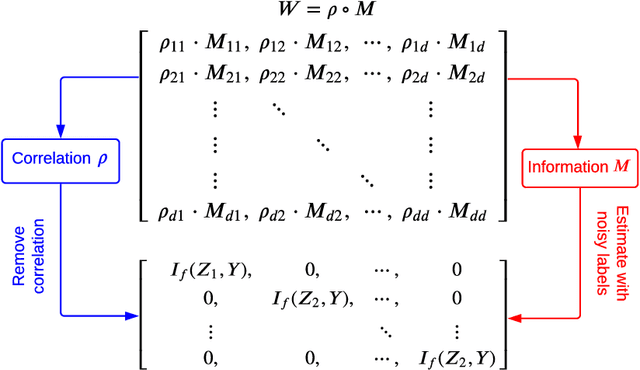
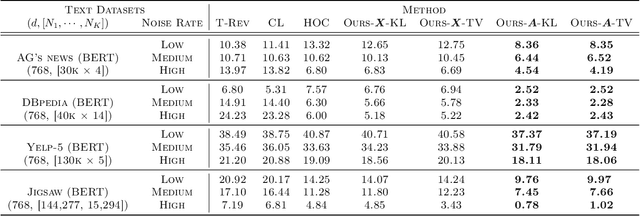
The label noise transition matrix, denoting the transition probabilities from clean labels to noisy labels, is crucial knowledge for designing statistically robust solutions. Existing estimators for noise transition matrices, e.g., using either anchor points or clusterability, focus on computer vision tasks that are relatively easier to obtain high-quality representations. However, for other tasks with lower-quality features, the uninformative variables may obscure the useful counterpart and make anchor-point or clusterability conditions hard to satisfy. We empirically observe the failures of these approaches on a number of commonly used datasets. In this paper, to handle this issue, we propose a generally practical information-theoretic approach to down-weight the less informative parts of the lower-quality features. The salient technical challenge is to compute the relevant information-theoretical metrics using only noisy labels instead of clean ones. We prove that the celebrated $f$-mutual information measure can often preserve the order when calculated using noisy labels. The necessity and effectiveness of the proposed method is also demonstrated by evaluating the estimation error on a varied set of tabular data and text classification tasks with lower-quality features. Code is available at github.com/UCSC-REAL/Est-T-MI.
Graph neural networks and attention-based CNN-LSTM for protein classification
Apr 20, 2022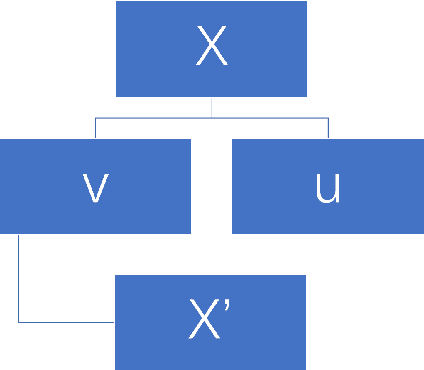
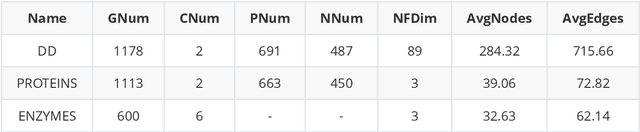
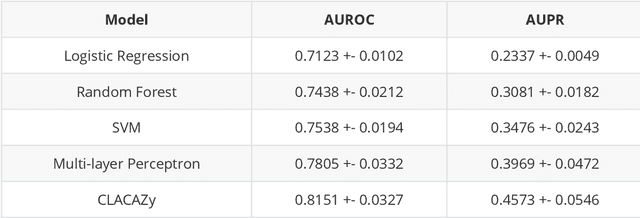
This paper focuses on three critical problems on protein classification. Firstly, Carbohydrate-active enzyme (CAZyme) classification can help people to understand the properties of enzymes. However, one CAZyme may belong to several classes. This leads to Multi-label CAZyme classification. Secondly, to capture information from the secondary structure of protein, protein classification is modeled as graph classification problem. Thirdly, compound-protein interactions prediction employs graph learning for compound with sequential embedding for protein. This can be seen as classification task for compound-protein pairs. This paper proposes three models for protein classification. Firstly, this paper proposes a Multi-label CAZyme classification model using CNN-LSTM with Attention mechanism. Secondly, this paper proposes a variational graph autoencoder based subspace learning model for protein graph classification. Thirdly, this paper proposes graph isomorphism networks (GIN) and Attention-based CNN-LSTM for compound-protein interactions prediction, as well as comparing GIN with graph convolution networks (GCN) and graph attention networks (GAT) in this task. The proposed models are effective for protein classification. Source code and data are available at https://github.com/zshicode/GNN-AttCL-protein. Besides, this repository collects and collates the benchmark datasets with respect to above problems, including CAZyme classification, enzyme protein graph classification, compound-protein interactions prediction, drug-target affinities prediction and drug-drug interactions prediction. Hence, the usage for evaluation by benchmark datasets can be more conveniently.
An Initialization Scheme for Meeting Separation with Spatial Mixture Models
Apr 04, 2022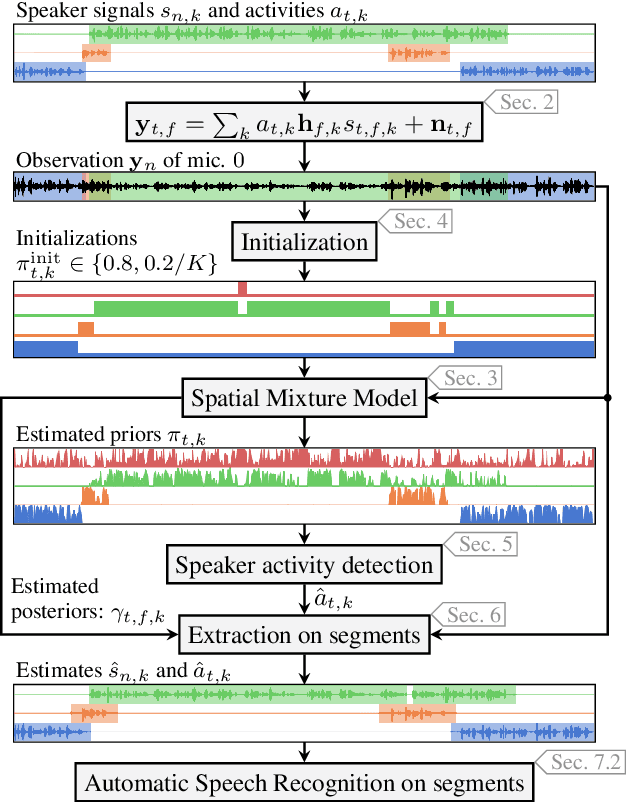
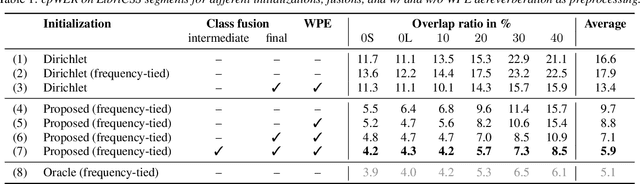
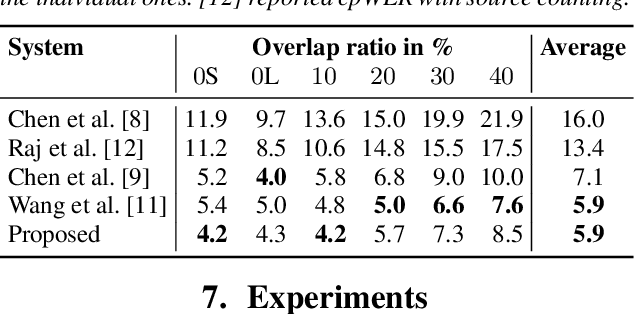
Spatial mixture model (SMM) supported acoustic beamforming has been extensively used for the separation of simultaneously active speakers. However, it has hardly been considered for the separation of meeting data, that are characterized by long recordings and only partially overlapping speech. In this contribution, we show that the fact that often only a single speaker is active can be utilized for a clever initialization of an SMM that employs time-varying class priors. In experiments on LibriCSS we show that the proposed initialization scheme achieves a significantly lower Word Error Rate (WER) on a downstream speech recognition task than a random initialization of the class probabilities by drawing from a Dirichlet distribution. With the only requirement that the number of speakers has to be known, we obtain a WER of 5.9 %, which is comparable to the best reported WER on this data set. Furthermore, the estimated speaker activity from the mixture model serves as a diarization based on spatial information.
Demystifying Deep Learning in Predictive Spatio-Temporal Analytics: An Information-Theoretic Framework
Sep 17, 2020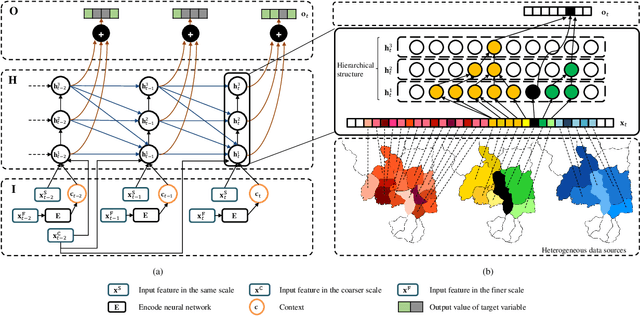
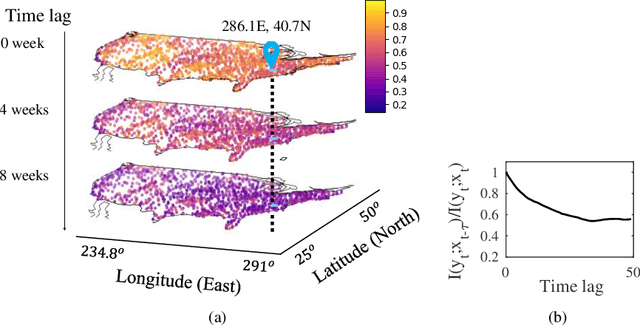
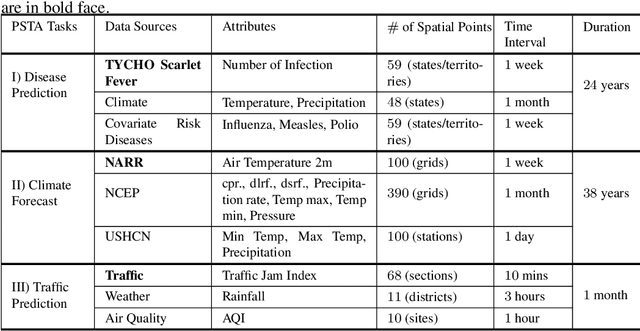
Deep learning has achieved incredible success over the past years, especially in various challenging predictive spatio-temporal analytics (PSTA) tasks, such as disease prediction, climate forecast, and traffic prediction, where intrinsic dependency relationships among data exist and generally manifest at multiple spatio-temporal scales. However, given a specific PSTA task and the corresponding dataset, how to appropriately determine the desired configuration of a deep learning model, theoretically analyze the model's learning behavior, and quantitatively characterize the model's learning capacity remains a mystery. In order to demystify the power of deep learning for PSTA, in this paper, we provide a comprehensive framework for deep learning model design and information-theoretic analysis. First, we develop and demonstrate a novel interactively- and integratively-connected deep recurrent neural network (I$^2$DRNN) model. I$^2$DRNN consists of three modules: an Input module that integrates data from heterogeneous sources; a Hidden module that captures the information at different scales while allowing the information to flow interactively between layers; and an Output module that models the integrative effects of information from various hidden layers to generate the output predictions. Second, to theoretically prove that our designed model can learn multi-scale spatio-temporal dependency in PSTA tasks, we provide an information-theoretic analysis to examine the information-based learning capacity (i-CAP) of the proposed model. Third, to validate the I$^2$DRNN model and confirm its i-CAP, we systematically conduct a series of experiments involving both synthetic datasets and real-world PSTA tasks. The experimental results show that the I$^2$DRNN model outperforms both classical and state-of-the-art models, and is able to capture meaningful multi-scale spatio-temporal dependency.
Settling the Communication Complexity for Distributed Offline Reinforcement Learning
Feb 10, 2022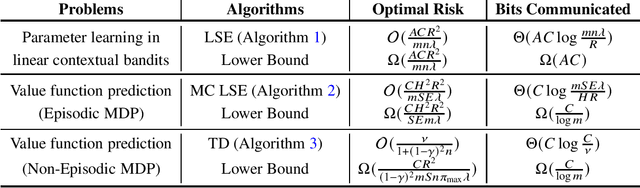
We study a novel setting in offline reinforcement learning (RL) where a number of distributed machines jointly cooperate to solve the problem but only one single round of communication is allowed and there is a budget constraint on the total number of information (in terms of bits) that each machine can send out. For value function prediction in contextual bandits, and both episodic and non-episodic MDPs, we establish information-theoretic lower bounds on the minimax risk for distributed statistical estimators; this reveals the minimum amount of communication required by any offline RL algorithms. Specifically, for contextual bandits, we show that the number of bits must scale at least as $\Omega(AC)$ to match the centralised minimax optimal rate, where $A$ is the number of actions and $C$ is the context dimension; meanwhile, we reach similar results in the MDP settings. Furthermore, we develop learning algorithms based on least-squares estimates and Monte-Carlo return estimates and provide a sharp analysis showing that they can achieve optimal risk up to logarithmic factors. Additionally, we also show that temporal difference is unable to efficiently utilise information from all available devices under the single-round communication setting due to the initial bias of this method. To our best knowledge, this paper presents the first minimax lower bounds for distributed offline RL problems.
GIMO: Gaze-Informed Human Motion Prediction in Context
Apr 20, 2022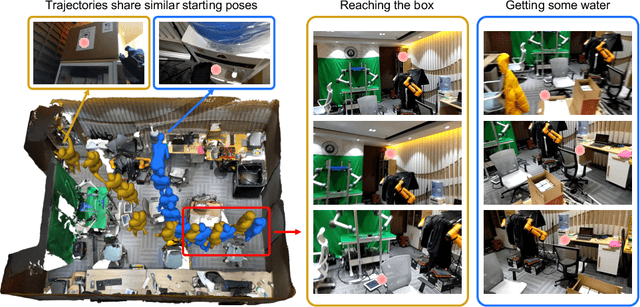
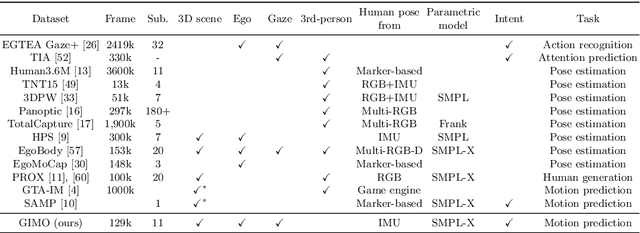
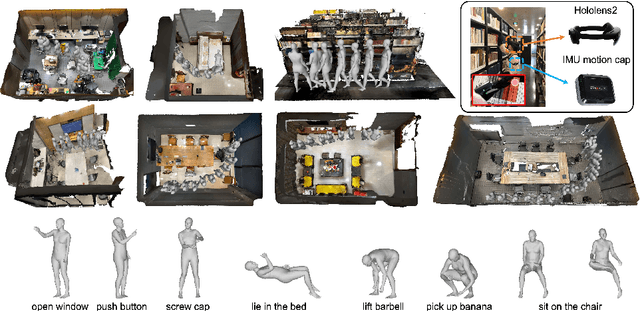
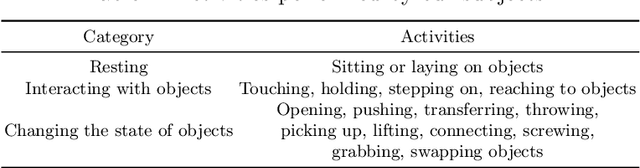
Predicting human motion is critical for assistive robots and AR/VR applications, where the interaction with humans needs to be safe and comfortable. Meanwhile, an accurate prediction depends on understanding both the scene context and human intentions. Even though many works study scene-aware human motion prediction, the latter is largely underexplored due to the lack of ego-centric views that disclose human intent and the limited diversity in motion and scenes. To reduce the gap, we propose a large-scale human motion dataset that delivers high-quality body pose sequences, scene scans, as well as ego-centric views with eye gaze that serves as a surrogate for inferring human intent. By employing inertial sensors for motion capture, our data collection is not tied to specific scenes, which further boosts the motion dynamics observed from our subjects. We perform an extensive study of the benefits of leveraging eye gaze for ego-centric human motion prediction with various state-of-the-art architectures. Moreover, to realize the full potential of gaze, we propose a novel network architecture that enables bidirectional communication between the gaze and motion branches. Our network achieves the top performance in human motion prediction on the proposed dataset, thanks to the intent information from the gaze and the denoised gaze feature modulated by the motion. The proposed dataset and our network implementation will be publicly available.
Masked Transformer for Neighhourhood-aware Click-Through Rate Prediction
Jan 25, 2022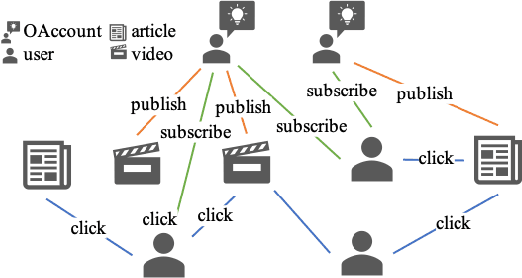
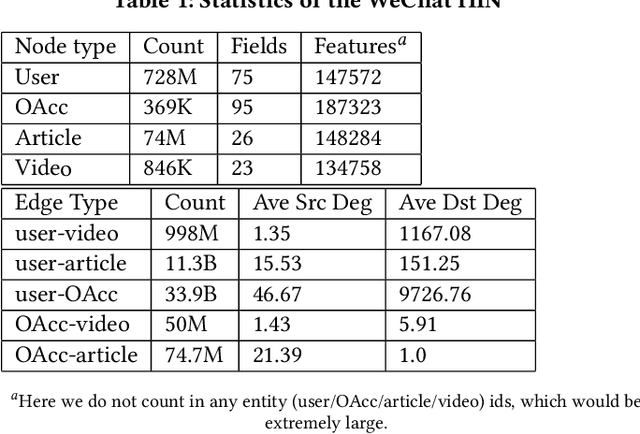
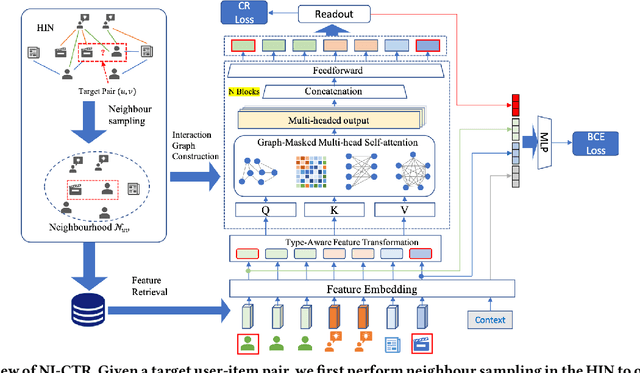
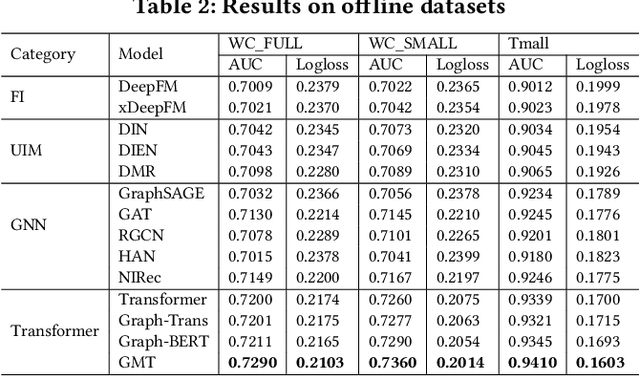
Click-Through Rate (CTR) prediction, is an essential component of online advertising. The mainstream techniques mostly focus on feature interaction or user interest modeling, which rely on users' directly interacted items. The performance of these methods are usally impeded by inactive behaviours and system's exposure, incurring that the features extracted do not contain enough information to represent all potential interests. For this sake, we propose Neighbor-Interaction based CTR prediction, which put this task into a Heterogeneous Information Network (HIN) setting, then involves local neighborhood of the target user-item pair in the HIN to predict their linkage. In order to enhance the representation of the local neighbourhood, we consider four types of topological interaction among the nodes, and propose a novel Graph-masked Transformer architecture to effectively incorporates both feature and topological information. We conduct comprehensive experiments on two real world datasets and the experimental results show that our proposed method outperforms state-of-the-art CTR models significantly.
Generative Forensics: Procedural Generation and Information Games
Apr 03, 2020


Procedural generation is used across game design to achieve a wide variety of ends, and has led to the creation of several game subgenres by injecting variance, surprise or unpredictability into otherwise static designs. Information games are a type of mystery game in which the player is tasked with gathering knowledge and developing an understanding of an event or system. Their reliance on player knowledge leaves them vulnerable to spoilers and hard to replay. In this paper we introduce the notion of generative forensics games, a subgenre of information games that challenge the player to understand the output of a generative system. We introduce information games, show how generative forensics develops the idea, report on two prototype games we created, and evaluate our work on generative forensics so far from a player and a designer perspective.