 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information-Theoretic Probing for Linguistic Structure
Apr 07, 2020
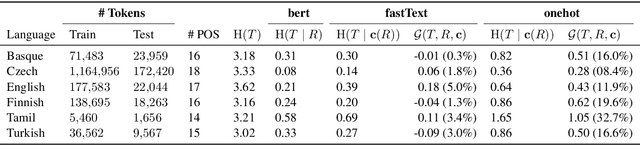
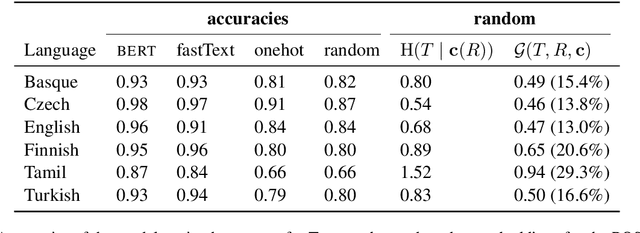
The success of neural networks on a diverse set of NLP tasks has led researchers to question how much do these networks actually know about natural language. Probes are a natural way of assessing this. When probing, a researcher chooses a linguistic task and trains a supervised model to predict annotation in that linguistic task from the network's learned representations. If the probe does well, the researcher may conclude that the representations encode knowledge related to the task. A commonly held belief is that using simpler models as probes is better; the logic is that such models will identify linguistic structure, but not learn the task itself. We propose an information-theoretic formalization of probing as estimating mutual information that contradicts this received wisdom: one should always select the highest performing probe one can, even if it is more complex, since it will result in a tighter estimate. The empirical portion of our paper focuses on obtaining tight estimates for how much information BERT knows about parts of speech in a set of five typologically diverse languages that are often underrepresented in parsing research, plus English, totaling six languages. We find BERT accounts for only at most 5% more information than traditional, type-based word embeddings.
Imagination-Augmented Natural Language Understanding
Apr 21, 2022
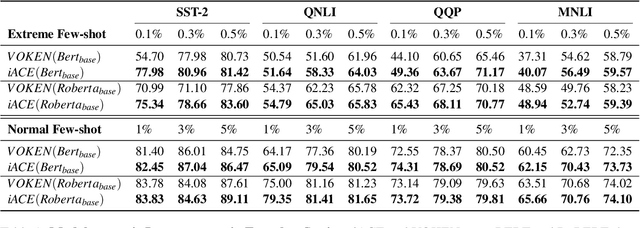
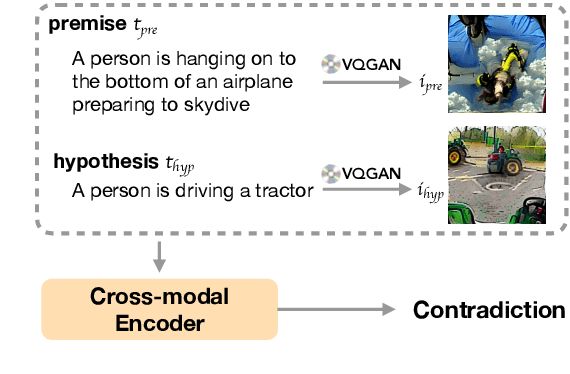
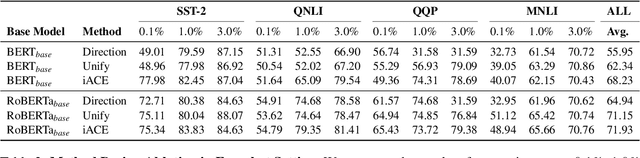
Human brains integrate linguistic and perceptual information simultaneously to understand natural language, and hold the critical ability to render imaginations. Such abilities enable us to construct new abstract concepts or concrete objects, and are essential in involving practical knowledge to solve problems in low-resource scenarios. However, most existing methods for Natural Language Understanding (NLU) are mainly focused on textual signals. They do not simulate human visual imagination ability, which hinders models from inferring and learning efficiently from limited data samples. Therefore, we introduce an Imagination-Augmented Cross-modal Encoder (iACE) to solve natural language understanding tasks from a novel learning perspective -- imagination-augmented cross-modal understanding. iACE enables visual imagination with external knowledge transferred from the powerful generative and pre-trained vision-and-language models. Extensive experiments on GLUE and SWAG show that iACE achieves consistent improvement over visually-supervised pre-trained models. More importantly, results in extreme and normal few-shot settings validate the effectiveness of iACE in low-resource natural language understanding circumstances.
Edge-enhanced Feature Distillation Network for Efficient Super-Resolution
Apr 19, 2022
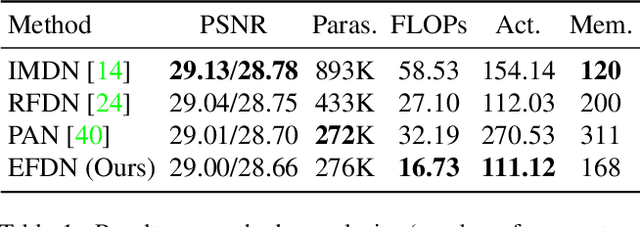
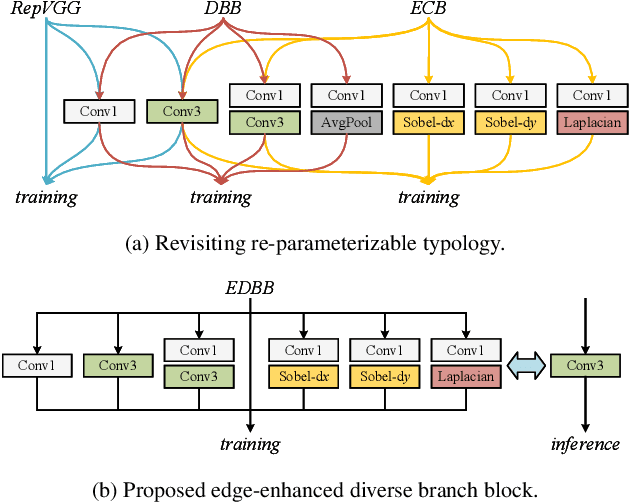

With the recently massive development in convolution neural networks, numerous lightweight CNN-based image super-resolution methods have been proposed for practical deployments on edge devices. However, most existing methods focus on one specific aspect: network or loss design, which leads to the difficulty of minimizing the model size. To address the issue, we conclude block devising, architecture searching, and loss design to obtain a more efficient SR structure. In this paper, we proposed an edge-enhanced feature distillation network, named EFDN, to preserve the high-frequency information under constrained resources. In detail, we build an edge-enhanced convolution block based on the existing reparameterization methods. Meanwhile, we propose edge-enhanced gradient loss to calibrate the reparameterized path training. Experimental results show that our edge-enhanced strategies preserve the edge and significantly improve the final restoration quality. Code is available at https://github.com/icandle/EFDN.
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Apr 17, 2021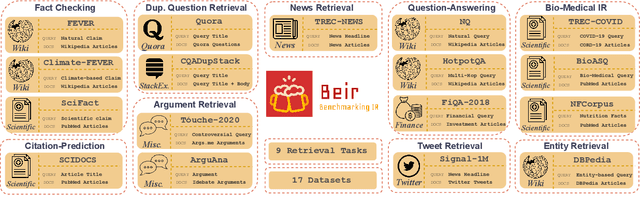
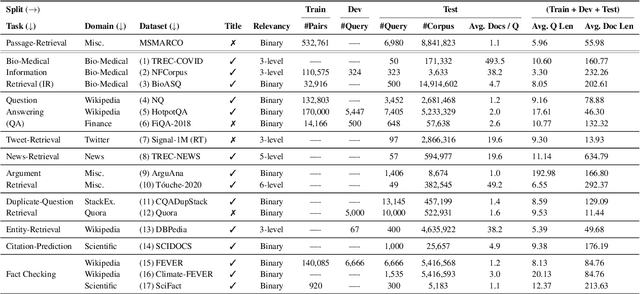
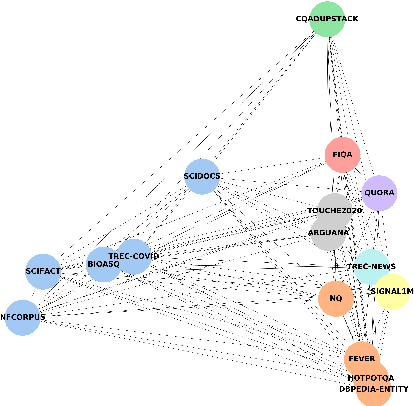
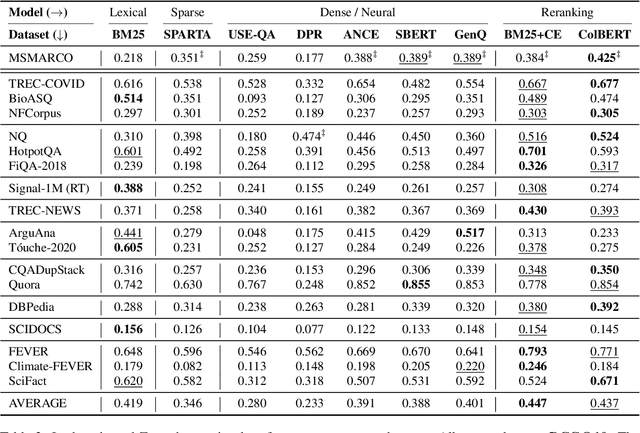
Neural IR models have often been studied in homogeneous and narrow settings, which has considerably limited insights into their generalization capabilities. To address this, and to allow researchers to more broadly establish the effectiveness of their models, we introduce BEIR (Benchmarking IR), a heterogeneous benchmark for information retrieval. We leverage a careful selection of 17 datasets for evaluation spanning diverse retrieval tasks including open-domain datasets as well as narrow expert domains. We study the effectiveness of nine state-of-the-art retrieval models in a zero-shot evaluation setup on BEIR, finding that performing well consistently across all datasets is challenging. Our results show BM25 is a robust baseline and Reranking-based models overall achieve the best zero-shot performances, however, at high computational costs. In contrast, Dense-retrieval models are computationally more efficient but often underperform other approaches, highlighting the considerable room for improvement in their generalization capabilities. In this work, we extensively analyze different retrieval models and provide several suggestions that we believe may be useful for future work. BEIR datasets and code are available at https://github.com/UKPLab/beir.
Ultra-low Latency Spiking Neural Networks with Spatio-Temporal Compression and Synaptic Convolutional Block
Mar 18, 2022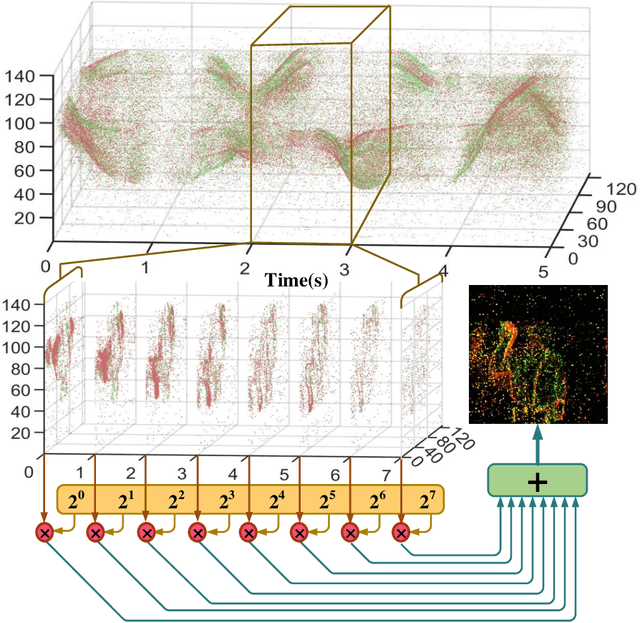
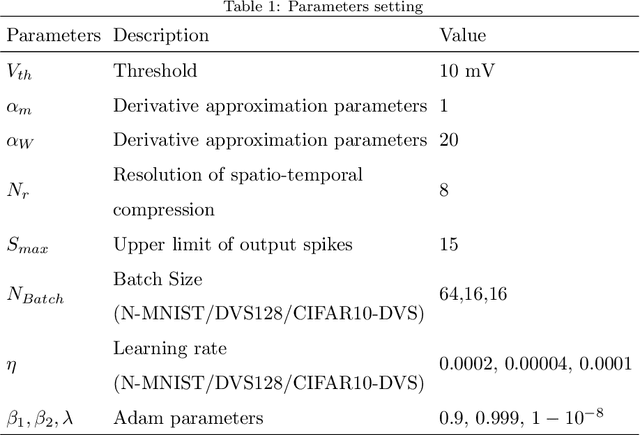
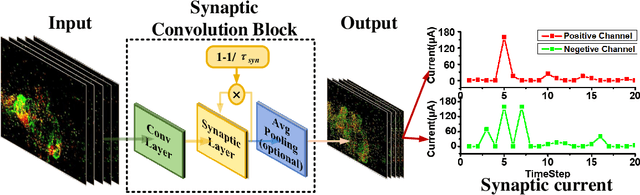
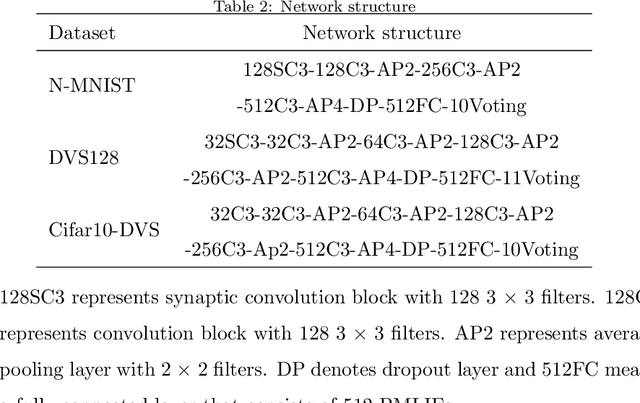
Spiking neural networks (SNNs), as one of the brain-inspired models, has spatio-temporal information processing capability, low power feature, and high biological plausibility. The effective spatio-temporal feature makes it suitable for event streams classification. However, neuromorphic datasets, such as N-MNIST, CIFAR10-DVS, DVS128-gesture, need to aggregate individual events into frames with a new higher temporal resolution for event stream classification, which causes high training and inference latency. In this work, we proposed a spatio-temporal compression method to aggregate individual events into a few time steps of synaptic current to reduce the training and inference latency. To keep the accuracy of SNNs under high compression ratios, we also proposed a synaptic convolutional block to balance the dramatic change between adjacent time steps. And multi-threshold Leaky Integrate-and-Fire (LIF) with learnable membrane time constant is introduced to increase its information processing capability. We evaluate the proposed method for event streams classification tasks on neuromorphic N-MNIST, CIFAR10-DVS, DVS128 gesture datasets. The experiment results show that our proposed method outperforms the state-of-the-art accuracy on nearly all datasets, using fewer time steps.
Planes vs. Chairs: Category-guided 3D shape learning without any 3D cues
Apr 21, 2022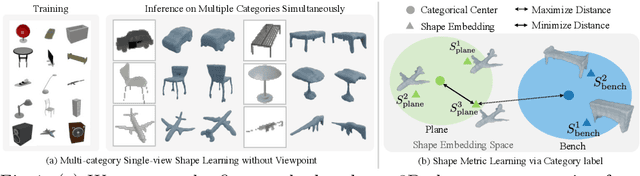

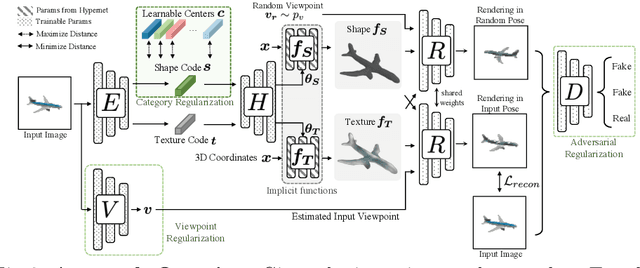
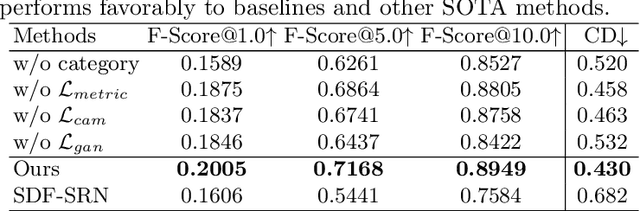
We present a novel 3D shape reconstruction method which learns to predict an implicit 3D shape representation from a single RGB image. Our approach uses a set of single-view images of multiple object categories without viewpoint annotation, forcing the model to learn across multiple object categories without 3D supervision. To facilitate learning with such minimal supervision, we use category labels to guide shape learning with a novel categorical metric learning approach. We also utilize adversarial and viewpoint regularization techniques to further disentangle the effects of viewpoint and shape. We obtain the first results for large-scale (more than 50 categories) single-viewpoint shape prediction using a single model without any 3D cues. We are also the first to examine and quantify the benefit of class information in single-view supervised 3D shape reconstruction. Our method achieves superior performance over state-of-the-art methods on ShapeNet-13, ShapeNet-55 and Pascal3D+.
B-DRRN: A Block Information Constrained Deep Recursive Residual Network for Video Compression Artifacts Reduction
Jan 22, 2021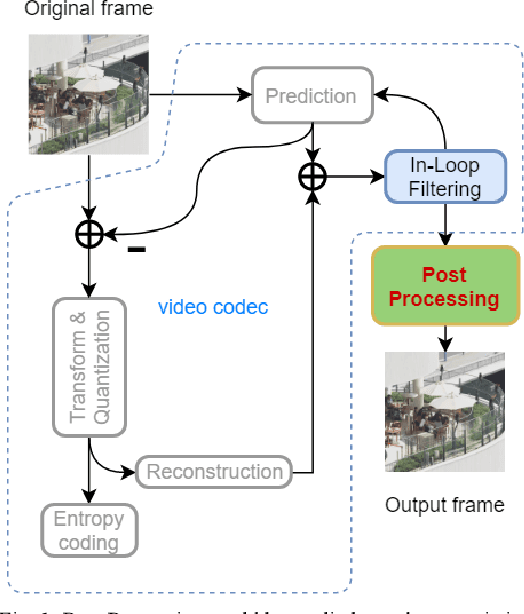

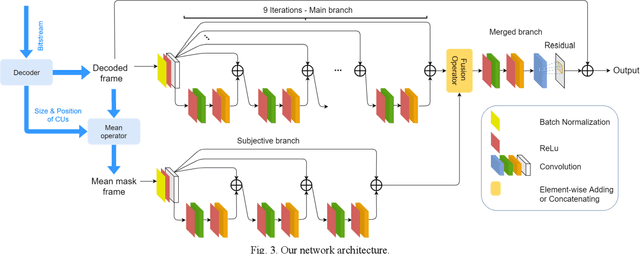

Although the video compression ratio nowadays becomes higher, the video coders such as H.264/AVC, H.265/HEVC, H.266/VVC always suffer from the video artifacts. In this paper, we design a neural network to enhance the quality of the compressed frame by leveraging the block information, called B-DRRN (Deep Recursive Residual Network with Block information). Firstly, an extra network branch is designed for leveraging the block information of the coding unit (CU). Moreover, to avoid a great increase in the network size, Recursive Residual structure and sharing weight techniques are applied. We also conduct a new large-scale dataset with 209,152 training samples. Experimental results show that the proposed B-DRRN can reduce 6.16% BD-rate compared to the HEVC standard. After efficiently adding an extra network branch, this work can improve the performance of the main network without increasing any memory for storing.
Table Structure Recognition with Conditional Attention
Mar 08, 2022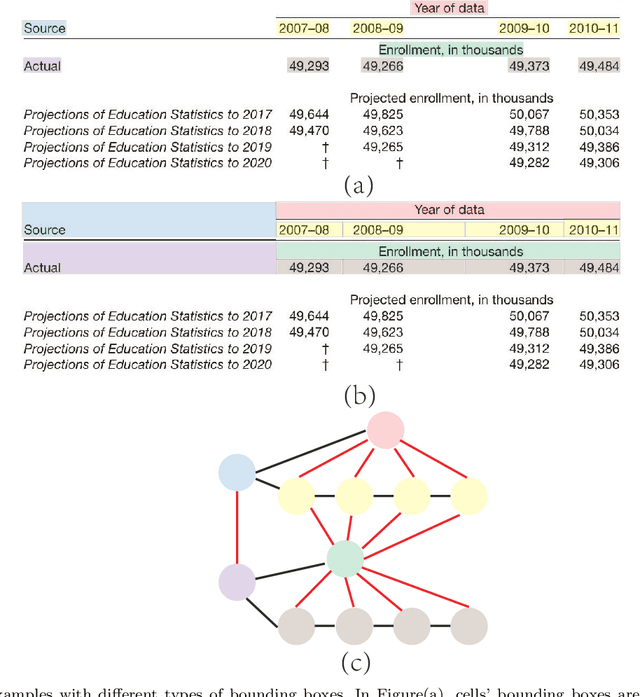

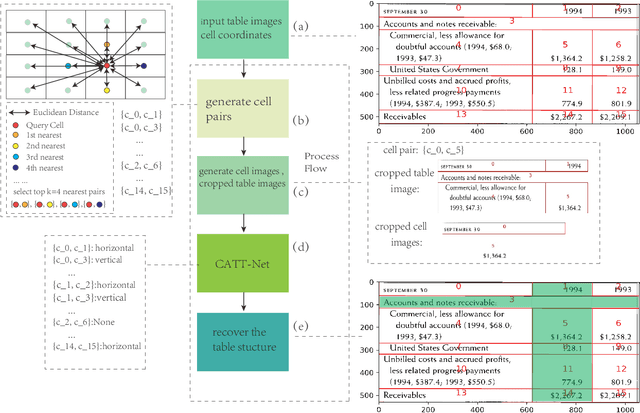

Tabular data in digital documents is widely used to express compact and important information for readers. However, it is challenging to parse tables from unstructured digital documents, such as PDFs and images, into machine-readable format because of the complexity of table structures and the missing of meta-information. Table Structure Recognition (TSR) problem aims to recognize the structure of a table and transform the unstructured tables into a structured and machine-readable format so that the tabular data can be further analysed by the down-stream tasks, such as semantic modeling and information retrieval. In this study, we hypothesize that a complicated table structure can be represented by a graph whose vertices and edges represent the cells and association between cells, respectively. Then we define the table structure recognition problem as a cell association classification problem and propose a conditional attention network (CATT-Net). The experimental results demonstrate the superiority of our proposed method over the state-of-the-art methods on various datasets. Besides, we investigate whether the alignment of a cell bounding box or a text-focused approach has more impact on the model performance. Due to the lack of public dataset annotations based on these two approaches, we further annotate the ICDAR2013 dataset providing both types of bounding boxes, which can be a new benchmark dataset for evaluating the methods in this field. Experimental results show that the alignment of a cell bounding box can help improve the Micro-averaged F1 score from 0.915 to 0.963, and the Macro-average F1 score from 0.787 to 0.923.
Fourier Document Restoration for Robust Document Dewarping and Recognition
Mar 18, 2022
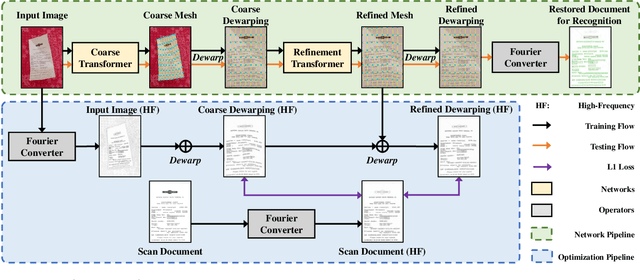
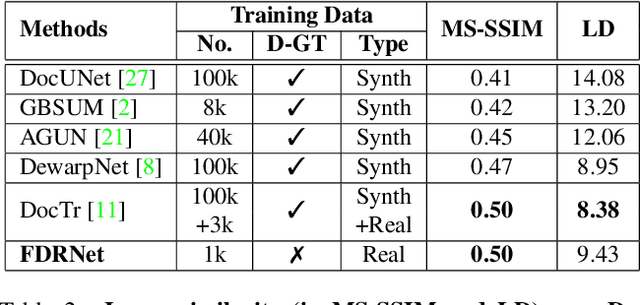
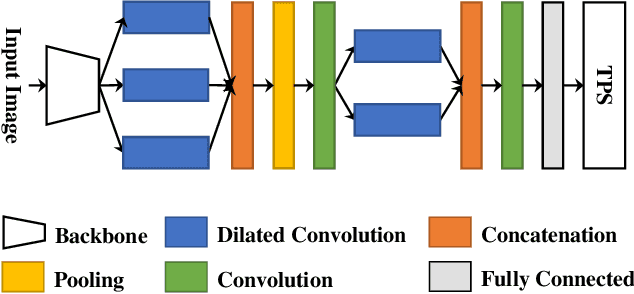
State-of-the-art document dewarping techniques learn to predict 3-dimensional information of documents which are prone to errors while dealing with documents with irregular distortions or large variations in depth. This paper presents FDRNet, a Fourier Document Restoration Network that can restore documents with different distortions and improve document recognition in a reliable and simpler manner. FDRNet focuses on high-frequency components in the Fourier space that capture most structural information but are largely free of degradation in appearance. It dewarps documents by a flexible Thin-Plate Spline transformation which can handle various deformations effectively without requiring deformation annotations in training. These features allow FDRNet to learn from a small amount of simply labeled training images, and the learned model can dewarp documents with complex geometric distortion and recognize the restored texts accurately. To facilitate document restoration research, we create a benchmark dataset consisting of over one thousand camera documents with different types of geometric and photometric distortion. Extensive experiments show that FDRNet outperforms the state-of-the-art by large margins on both dewarping and text recognition tasks. In addition, FDRNet requires a small amount of simply labeled training data and is easy to deploy.
Show Me What and Tell Me How: Video Synthesis via Multimodal Conditioning
Mar 04, 2022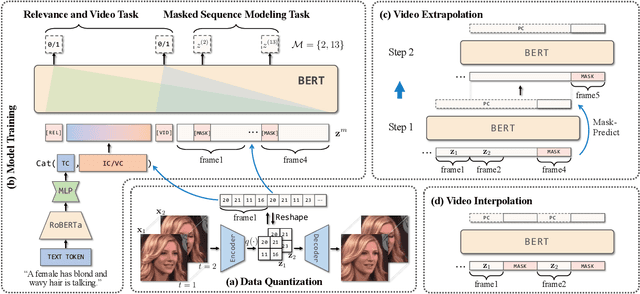
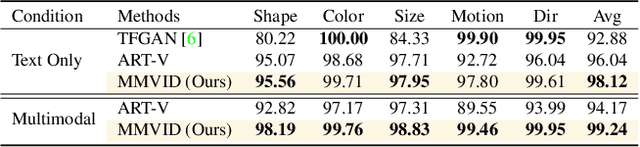


Most methods for conditional video synthesis use a single modality as the condition. This comes with major limitations. For example, it is problematic for a model conditioned on an image to generate a specific motion trajectory desired by the user since there is no means to provide motion information. Conversely, language information can describe the desired motion, while not precisely defining the content of the video. This work presents a multimodal video generation framework that benefits from text and images provided jointly or separately. We leverage the recent progress in quantized representations for videos and apply a bidirectional transformer with multiple modalities as inputs to predict a discrete video representation. To improve video quality and consistency, we propose a new video token trained with self-learning and an improved mask-prediction algorithm for sampling video tokens. We introduce text augmentation to improve the robustness of the textual representation and diversity of generated videos. Our framework can incorporate various visual modalities, such as segmentation masks, drawings, and partially occluded images. It can generate much longer sequences than the one used for training. In addition, our model can extract visual information as suggested by the text prompt, e.g., "an object in image one is moving northeast", and generate corresponding videos. We run evaluations on three public datasets and a newly collected dataset labeled with facial attributes, achieving state-of-the-art generation results on all four.