 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Apr 28, 2021
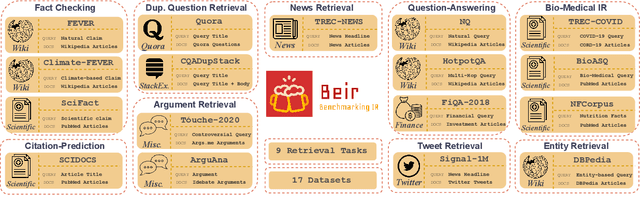
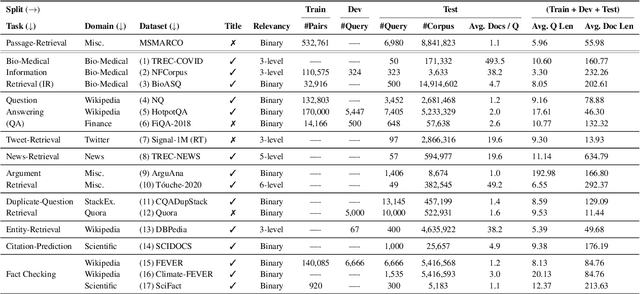
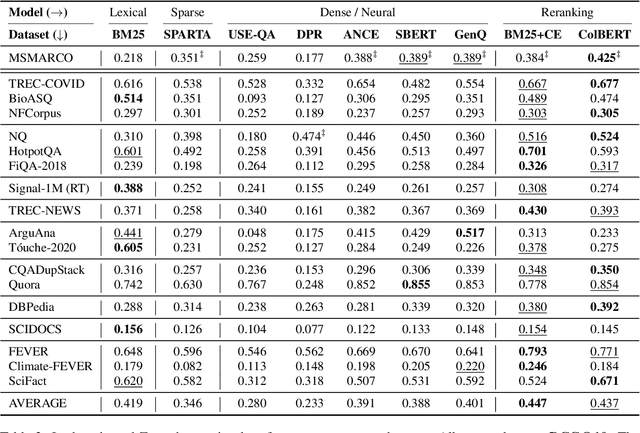
Neural IR models have often been studied in homogeneous and narrow settings, which has considerably limited insights into their generalization capabilities. To address this, and to allow researchers to more broadly establish the effectiveness of their models, we introduce BEIR (Benchmarking IR), a heterogeneous benchmark for information retrieval. We leverage a careful selection of 17 datasets for evaluation spanning diverse retrieval tasks including open-domain datasets as well as narrow expert domains. We study the effectiveness of nine state-of-the-art retrieval models in a zero-shot evaluation setup on BEIR, finding that performing well consistently across all datasets is challenging. Our results show BM25 is a robust baseline and Reranking-based models overall achieve the best zero-shot performances, however, at high computational costs. In contrast, Dense-retrieval models are computationally more efficient but often underperform other approaches, highlighting the considerable room for improvement in their generalization capabilities. In this work, we extensively analyze different retrieval models and provide several suggestions that we believe may be useful for future work. BEIR datasets and code are available at https://github.com/UKPLab/beir.
IA-GCN: Interactive Graph Convolutional Network for Recommendation
Apr 08, 2022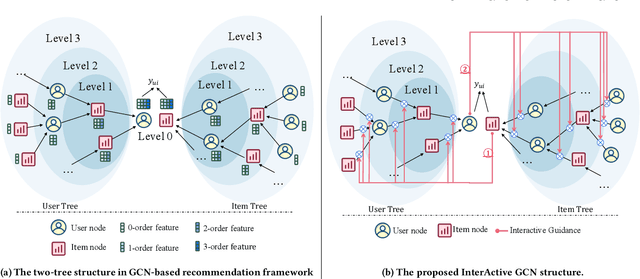

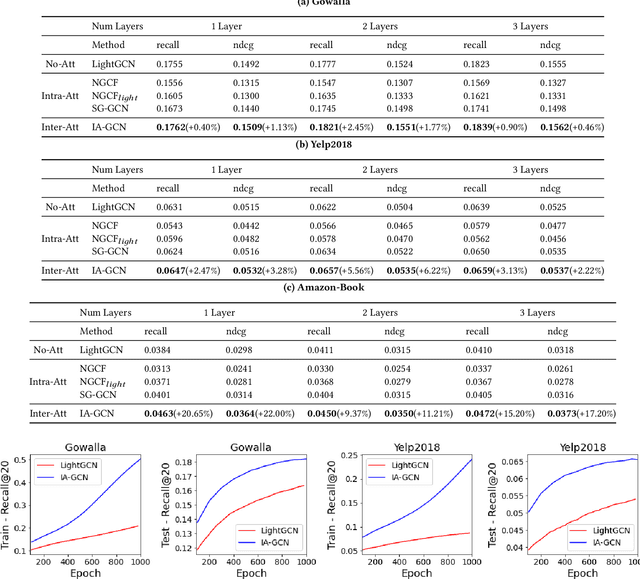
Recently, Graph Convolutional Network (GCN) has become a novel state-of-art for Collaborative Filtering (CF) based Recommender Systems (RS). It is a common practice to learn informative user and item representations by performing embedding propagation on a user-item bipartite graph, and then provide the users with personalized item suggestions based on the representations. Despite effectiveness, existing algorithms neglect precious interactive features between user-item pairs in the embedding process. When predicting a user's preference for different items, they still aggregate the user tree in the same way, without emphasizing target-related information in the user neighborhood. Such a uniform aggregation scheme easily leads to suboptimal user and item representations, limiting the model expressiveness to some extent. In this work, we address this problem by building bilateral interactive guidance between each user-item pair and proposing a new model named IA-GCN (short for InterActive GCN). Specifically, when learning the user representation from its neighborhood, we assign higher attention weights to those neighbors similar to the target item. Correspondingly, when learning the item representation, we pay more attention to those neighbors resembling the target user. This leads to interactive and interpretable features, effectively distilling target-specific information through each graph convolutional operation. Our model is built on top of LightGCN, a state-of-the-art GCN model for CF, and can be combined with various GCN-based CF architectures in an end-to-end fashion. Extensive experiments on three benchmark datasets demonstrate the effectiveness and robustness of IA-GCN.
Evidence-aware Fake News Detection with Graph Neural Networks
Feb 08, 2022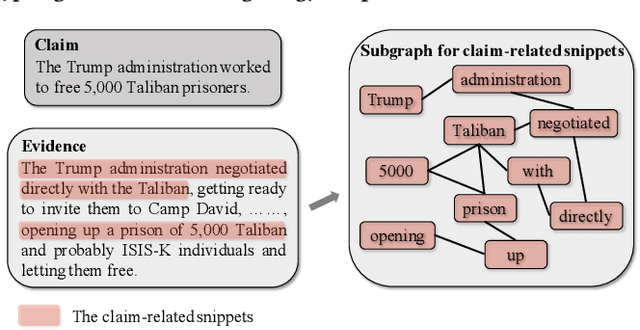
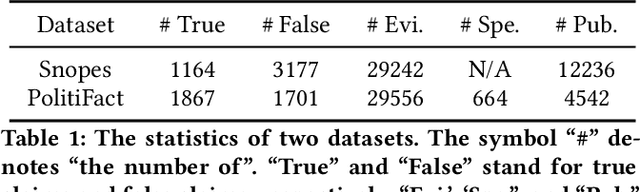
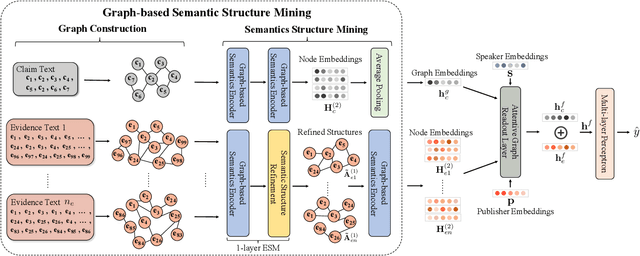
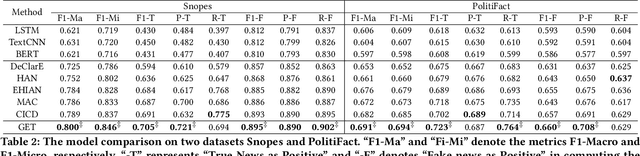
The prevalence and perniciousness of fake news has been a critical issue on the Internet, which stimulates the development of automatic fake news detection in turn. In this paper, we focus on the evidence-based fake news detection, where several evidences are utilized to probe the veracity of news (i.e., a claim). Most previous methods first employ sequential models to embed the semantic information and then capture the claim-evidence interaction based on different attention mechanisms. Despite their effectiveness, they still suffer from two main weaknesses. Firstly, due to the inherent drawbacks of sequential models, they fail to integrate the relevant information that is scattered far apart in evidences for veracity checking. Secondly, they neglect much redundant information contained in evidences that may be useless or even harmful. To solve these problems, we propose a unified Graph-based sEmantic sTructure mining framework, namely GET in short. Specifically, different from the existing work that treats claims and evidences as sequences, we model them as graph-structured data and capture the long-distance semantic dependency among dispersed relevant snippets via neighborhood propagation. After obtaining contextual semantic information, our model reduces information redundancy by performing graph structure learning. Finally, the fine-grained semantic representations are fed into the downstream claim-evidence interaction module for predictions. Comprehensive experiments have demonstrated the superiority of GET over the state-of-the-arts.
Conditional $β$-VAE for De Novo Molecular Generation
May 01, 2022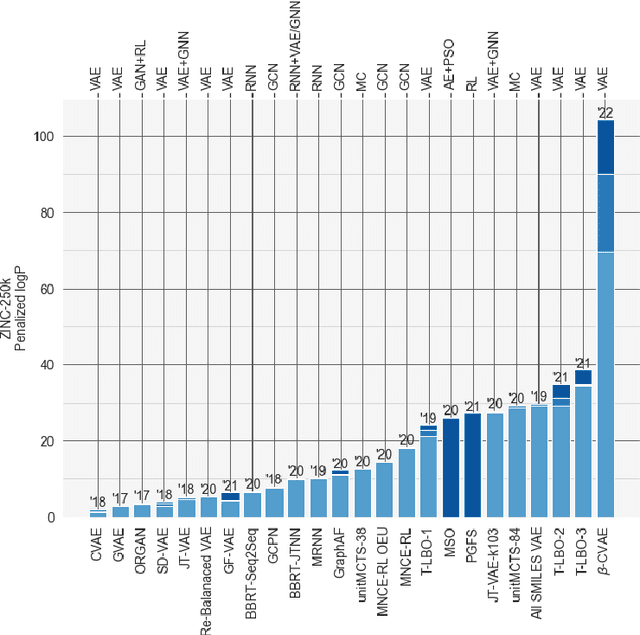
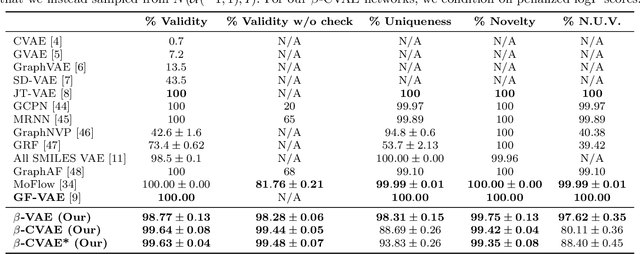
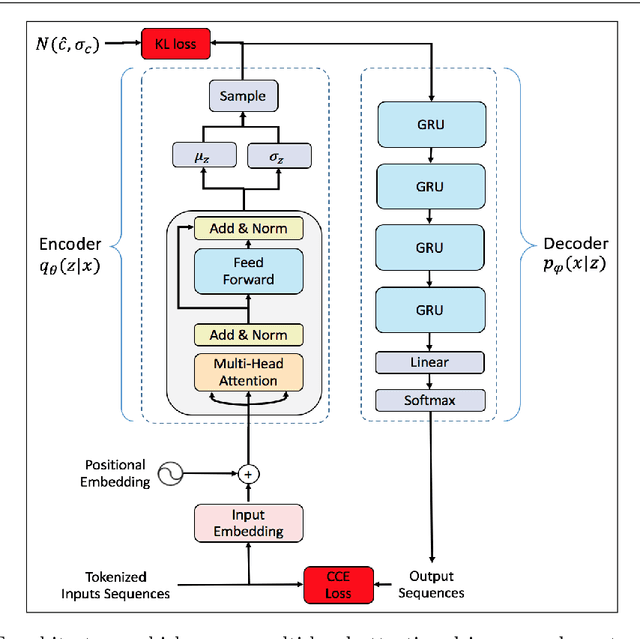
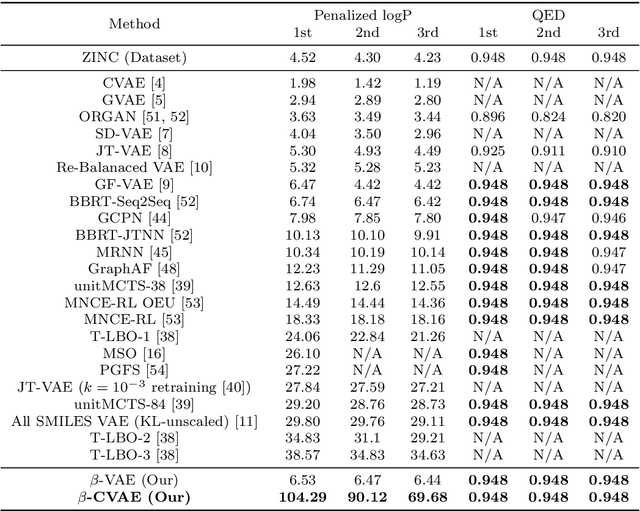
Deep learning has significantly advanced and accelerated de novo molecular generation. Generative networks, namely Variational Autoencoders (VAEs) can not only randomly generate new molecules, but also alter molecular structures to optimize specific chemical properties which are pivotal for drug-discovery. While VAEs have been proposed and researched in the past for pharmaceutical applications, they possess deficiencies which limit their ability to both optimize properties and decode syntactically valid molecules. We present a recurrent, conditional $\beta$-VAE which disentangles the latent space to enhance post hoc molecule optimization. We create a mutual information driven training protocol and data augmentations to both increase molecular validity and promote longer sequence generation. We demonstrate the efficacy of our framework on the ZINC-250k dataset, achieving SOTA unconstrained optimization results on the penalized LogP (pLogP) and QED scores, while also matching current SOTA results for validity, novelty and uniqueness scores for random generation. We match the current SOTA on QED for top-3 molecules at 0.948, while setting a new SOTA for pLogP optimization at 104.29, 90.12, 69.68 and demonstrating improved results on the constrained optimization task.
A Summary of the ALQAC 2021 Competition
Apr 25, 2022


We summarize the evaluation of the first Automated Legal Question Answering Competition (ALQAC 2021). The competition this year contains three tasks, which aims at processing the statute law document, which are Legal Text Information Retrieval (Task 1), Legal Text Entailment Prediction (Task 2), and Legal Text Question Answering (Task 3). The final goal of these tasks is to build a system that can automatically determine whether a particular statement is lawful. There is no limit to the approaches of the participating teams. This year, there are 5 teams participating in Task 1, 6 teams participating in Task 2, and 5 teams participating in Task 3. There are in total 36 runs submitted to the organizer. In this paper, we summarize each team's approaches, official results, and some discussion about the competition. Only results of the teams who successfully submit their approach description paper are reported in this paper.
Visual-Thermal Camera Dataset Release and Multi-Modal Alignment without Calibration Information
Dec 29, 2020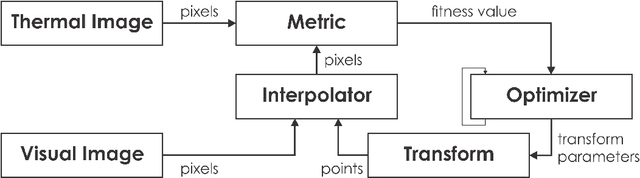

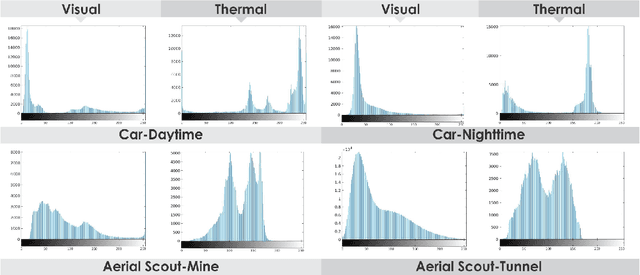

This report accompanies a dataset release on visual and thermal camera data and details a procedure followed to align such multi-modal camera frames in order to provide pixel-level correspondence between the two without using intrinsic or extrinsic calibration information. To achieve this goal we benefit from progress in the domain of multi-modal image alignment and specifically employ the Mattes Mutual Information Metric to guide the registration process. In the released dataset we release both the raw visual and thermal camera data, as well as the aligned frames, alongside calibration parameters with the goal to better facilitate the investigation on common local/global features across such multi-modal image streams.
Deep Reinforcement Learning Using a Low-Dimensional Observation Filter for Visual Complex Video Game Playing
Apr 24, 2022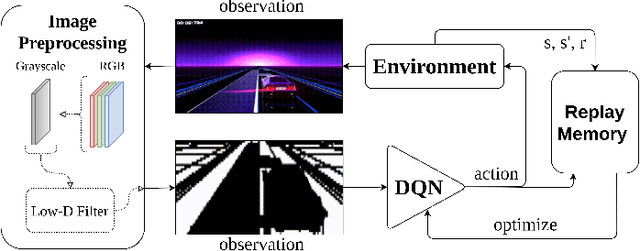
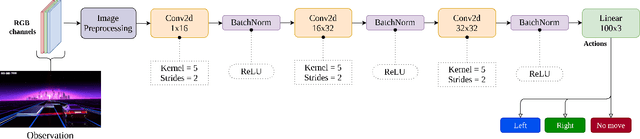
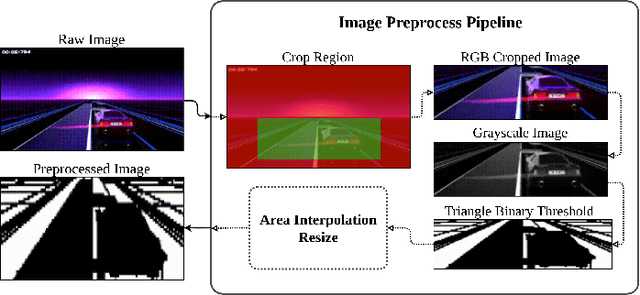
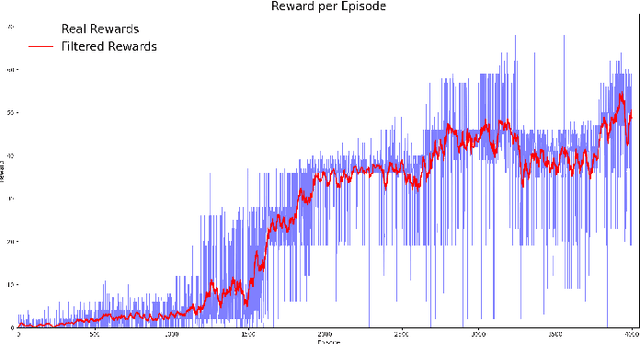
Deep Reinforcement Learning (DRL) has produced great achievements since it was proposed, including the possibility of processing raw vision input data. However, training an agent to perform tasks based on image feedback remains a challenge. It requires the processing of large amounts of data from high-dimensional observation spaces, frame by frame, and the agent's actions are computed according to deep neural network policies, end-to-end. Image pre-processing is an effective way of reducing these high dimensional spaces, eliminating unnecessary information present in the scene, supporting the extraction of features and their representations in the agent's neural network. Modern video-games are examples of this type of challenge for DRL algorithms because of their visual complexity. In this paper, we propose a low-dimensional observation filter that allows a deep Q-network agent to successfully play in a visually complex and modern video-game, called Neon Drive.
Accelerated Continuous-Time Approximate Dynamic Programming via Data-Assisted Hybrid Control
Apr 27, 2022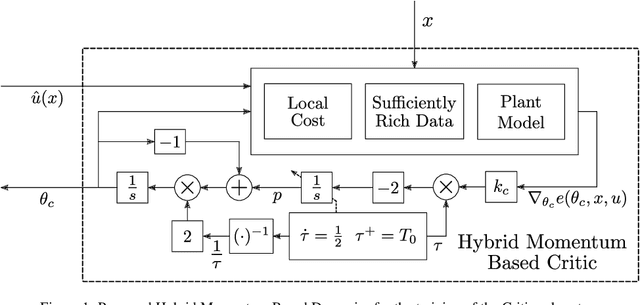
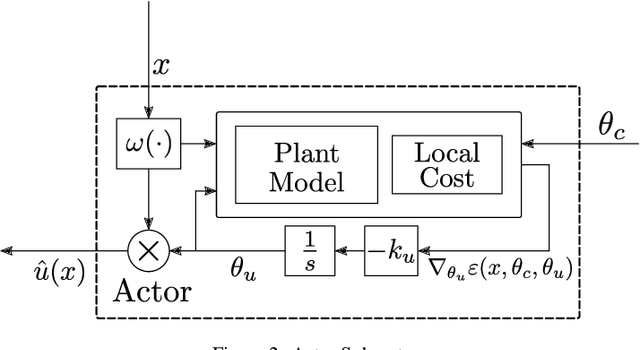
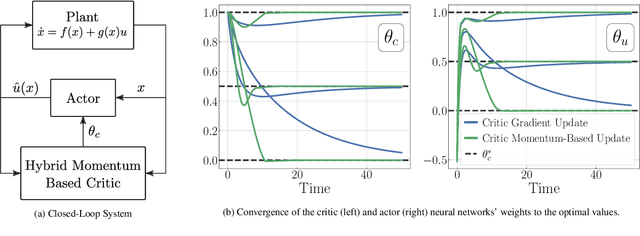
We introduce a new closed-loop architecture for the online solution of approximate optimal control problems in the context of continuous-time systems. Specifically, we introduce the first algorithm that incorporates dynamic momentum in actor-critic structures to control continuous-time dynamic plants with an affine structure in the input. By incorporating dynamic momentum in our algorithm, we are able to accelerate the convergence properties of the closed-loop system, achieving superior transient performance compared to traditional gradient-descent based techniques. In addition, by leveraging the existence of past recorded data with sufficiently rich information properties, we dispense with the persistence of excitation condition traditionally imposed on the regressors of the critic and the actor. Given that our continuous-time momentum-based dynamics also incorporate periodic discrete-time resets that emulate restarting techniques used in the machine learning literature, we leverage tools from hybrid dynamical systems theory to establish asymptotic stability properties for the closed-loop system. We illustrate our results with a numerical example.
NeuralTree: A 256-Channel 0.227uJ/class Versatile Neural Activity Classification and Closed-Loop Neuromodulation SoC
May 21, 2022



Closed-loop neural interfaces with on-chip machine learning can detect and suppress disease symptoms in neurological disorders or restore lost functions in paralyzed patients. While high-density neural recording can provide rich neural activity information for accurate disease-state detection, existing systems have low channel count and poor scalability, which could limit their therapeutic efficacy. This work presents a highly scalable and versatile closed-loop neural interface SoC that can overcome these limitations. A 256-channel time-division multiplexed (TDM) front-end with a two-step fast-settling mixed-signal DC servo loop (DSL) is proposed to record high-spatial-resolution neural activity and perform channel-selective brain-state inference. A tree-structured neural network (NeuralTree) classification processor extracts a rich set of neural biomarkers in a patient- and disease-specific manner. Trained with an energy-aware learning algorithm, the NeuralTree classifier detects the symptoms of underlying disorders (e.g., epilepsy and movement disorders) at an optimal energy-accuracy trade-off. A 16-channel high-voltage (HV) compliant neurostimulator closes the therapeutic loop by delivering charge-balanced biphasic current pulses to the brain. The proposed SoC was fabricated in 65nm CMOS and achieved a 0.227uJ/class energy efficiency in a compact area of 0.014mm^2/channel. The SoC was extensively verified on human electroencephalography (EEG) and intracranial EEG (iEEG) epilepsy datasets, obtaining 95.6%/94% sensitivity and 96.8%/96.9% specificity, respectively. In-vivo neural recordings using soft uECoG arrays and multi-domain biomarker extraction were further performed on a rat model of epilepsy. In addition, for the first time in literature, on-chip classification of rest-state tremor in Parkinson's disease from human local field potentials (LFPs) was demonstrated.
A New Automatic Change Detection Frame-work Based on Region Growing and Weighted Local Mutual Information: Analysis of Breast Tumor Response to Chemotherapy in Serial MR Images
Oct 19, 2021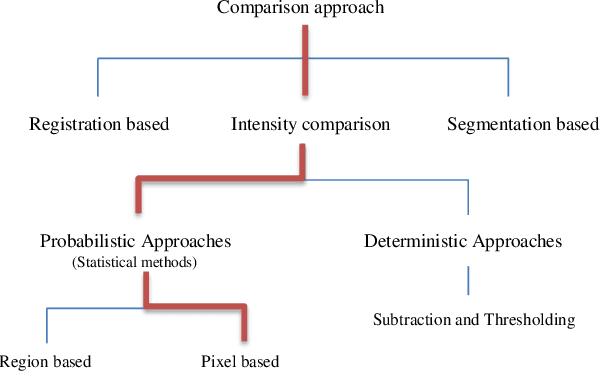
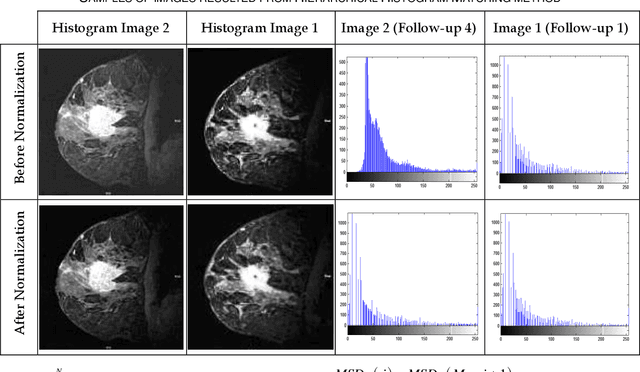
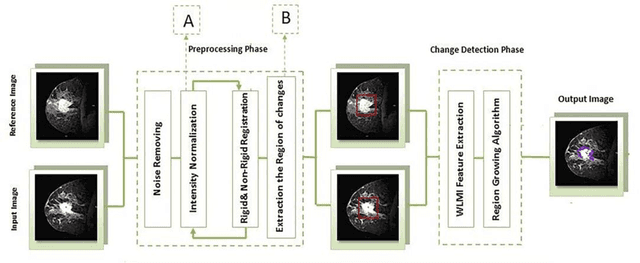
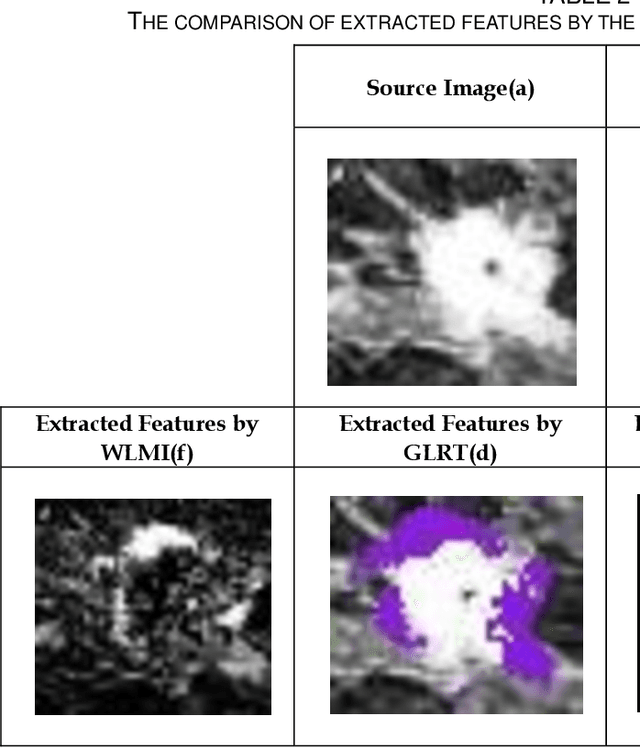
The automatic analysis of subtle changes between longitudinal MR images is an important task as it is still a challenging issue in scope of the breast medical image processing. In this paper we propose an effective automatic change detection framework composed of two phases since previously used methods have features with low distinctive power. First, in the preprocessing phase an intensity normalization method is suggested based on Hierarchical Histogram Matching (HHM) that is more robust to noise than previous methods. To eliminate undesirable changes and extract the regions containing significant changes the proposed Extraction Region of Changes (EROC) method is applied based on intensity distribution and Hill-Climbing algorithm. Second, in the detection phase a region growing-based approach is suggested to differentiate significant changes from unreal ones. Due to using proposed Weighted Local Mutual Information (WLMI) method to extract high level features and also utilizing the principle of the local consistency of changes, the proposed approach enjoys reasonable performance. The experimental results on both simulated and real longitudinal Breast MR Images confirm the effectiveness of the proposed framework. Also, this framework outperforms the human expert in some cases which can detect many lesion evolutions that are missed by expert.