 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Cross Cryptocurrency Relationship Mining for Bitcoin Price Prediction
Apr 28, 2022
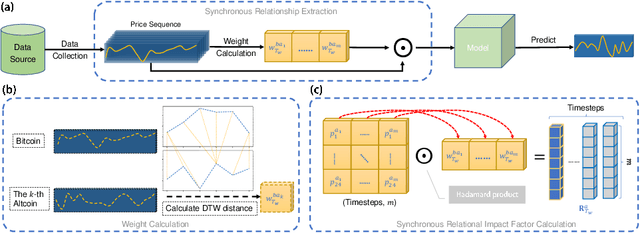
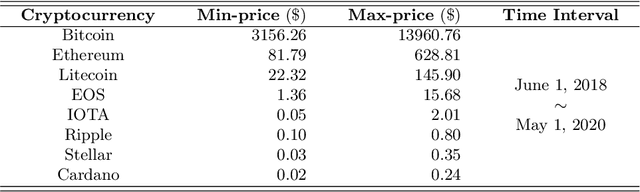
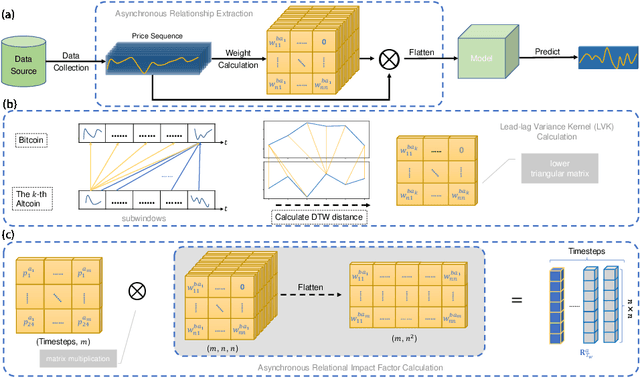
Blockchain finance has become a part of the world financial system, most typically manifested in the attention to the price of Bitcoin. However, a great deal of work is still limited to using technical indicators to capture Bitcoin price fluctuation, with little consideration of historical relationships and interactions between related cryptocurrencies. In this work, we propose a generic Cross-Cryptocurrency Relationship Mining module, named C2RM, which can effectively capture the synchronous and asynchronous impact factors between Bitcoin and related Altcoins. Specifically, we utilize the Dynamic Time Warping algorithm to extract the lead-lag relationship, yielding Lead-lag Variance Kernel, which will be used for aggregating the information of Altcoins to form relational impact factors. Comprehensive experimental results demonstrate that our C2RM can help existing price prediction methods achieve significant performance improvement, suggesting the effectiveness of Cross-Cryptocurrency interactions on benefitting Bitcoin price prediction.
STDC-MA Network for Semantic Segmentation
May 11, 2022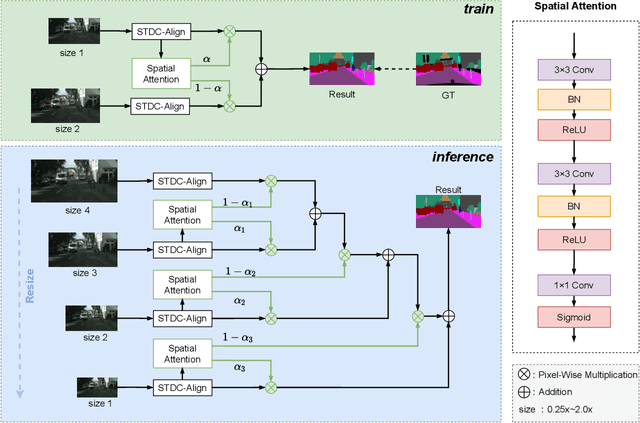

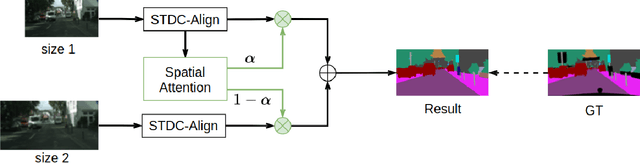
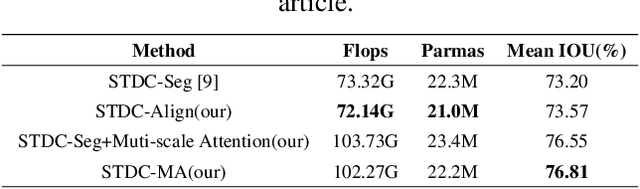
Semantic segmentation is applied extensively in autonomous driving and intelligent transportation with methods that highly demand spatial and semantic information. Here, an STDC-MA network is proposed to meet these demands. First, the STDC-Seg structure is employed in STDC-MA to ensure a lightweight and efficient structure. Subsequently, the feature alignment module (FAM) is applied to understand the offset between high-level and low-level features, solving the problem of pixel offset related to upsampling on the high-level feature map. Our approach implements the effective fusion between high-level features and low-level features. A hierarchical multiscale attention mechanism is adopted to reveal the relationship among attention regions from two different input sizes of one image. Through this relationship, regions receiving much attention are integrated into the segmentation results, thereby reducing the unfocused regions of the input image and improving the effective utilization of multiscale features. STDC- MA maintains the segmentation speed as an STDC-Seg network while improving the segmentation accuracy of small objects. STDC-MA was verified on the verification set of Cityscapes. The segmentation result of STDC-MA attained 76.81% mIOU with the input of 0.5x scale, 3.61% higher than STDC-Seg.
Layer-wise Model Pruning based on Mutual Information
Aug 28, 2021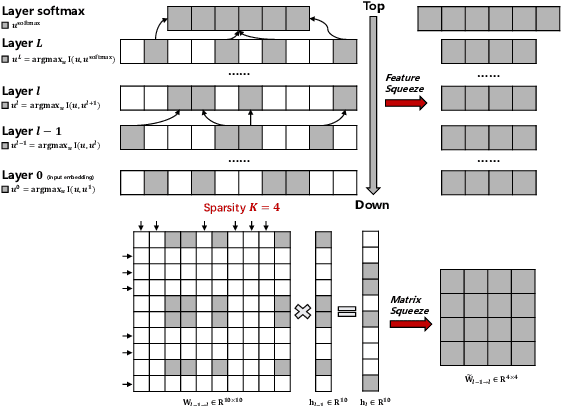
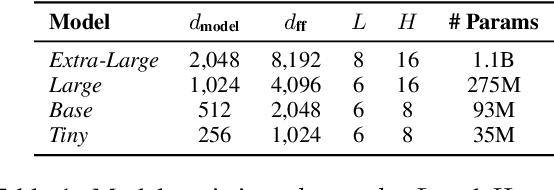
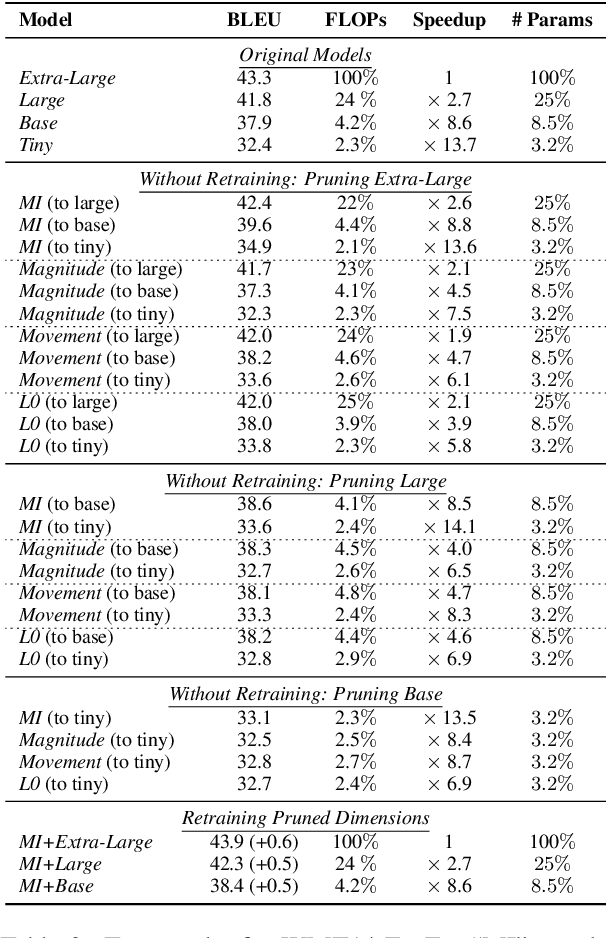
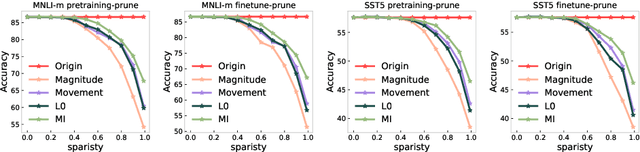
The proposed pruning strategy offers merits over weight-based pruning techniques: (1) it avoids irregular memory access since representations and matrices can be squeezed into their smaller but dense counterparts, leading to greater speedup; (2) in a manner of top-down pruning, the proposed method operates from a more global perspective based on training signals in the top layer, and prunes each layer by propagating the effect of global signals through layers, leading to better performances at the same sparsity level. Extensive experiments show that at the same sparsity level, the proposed strategy offers both greater speedup and higher performances than weight-based pruning methods (e.g., magnitude pruning, movement pruning).
Medicinal Boxes Recognition on a Deep Transfer Learning Augmented Reality Mobile Application
Mar 26, 2022



Taking medicines is a fundamental aspect to cure illnesses. However, studies have shown that it can be hard for patients to remember the correct posology. More aggravating, a wrong dosage generally causes the disease to worsen. Although, all relevant instructions for a medicine are summarized in the corresponding patient information leaflet, the latter is generally difficult to navigate and understand. To address this problem and help patients with their medication, in this paper we introduce an augmented reality mobile application that can present to the user important details on the framed medicine. In particular, the app implements an inference engine based on a deep neural network, i.e., a densenet, fine-tuned to recognize a medicinal from its package. Subsequently, relevant information, such as posology or a simplified leaflet, is overlaid on the camera feed to help a patient when taking a medicine. Extensive experiments to select the best hyperparameters were performed on a dataset specifically collected to address this task; ultimately obtaining up to 91.30\% accuracy as well as real-time capabilities.
Target-aware Dual Adversarial Learning and a Multi-scenario Multi-Modality Benchmark to Fuse Infrared and Visible for Object Detection
Mar 30, 2022

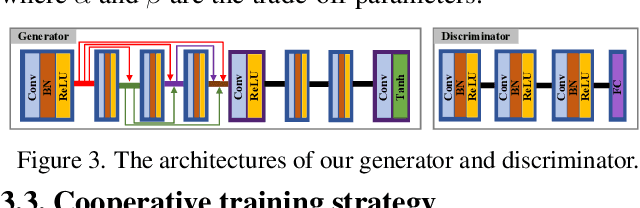

This study addresses the issue of fusing infrared and visible images that appear differently for object detection. Aiming at generating an image of high visual quality, previous approaches discover commons underlying the two modalities and fuse upon the common space either by iterative optimization or deep networks. These approaches neglect that modality differences implying the complementary information are extremely important for both fusion and subsequent detection task. This paper proposes a bilevel optimization formulation for the joint problem of fusion and detection, and then unrolls to a target-aware Dual Adversarial Learning (TarDAL) network for fusion and a commonly used detection network. The fusion network with one generator and dual discriminators seeks commons while learning from differences, which preserves structural information of targets from the infrared and textural details from the visible. Furthermore, we build a synchronized imaging system with calibrated infrared and optical sensors, and collect currently the most comprehensive benchmark covering a wide range of scenarios. Extensive experiments on several public datasets and our benchmark demonstrate that our method outputs not only visually appealing fusion but also higher detection mAP than the state-of-the-art approaches.
Lattices from Linear Codes: Source and Channel Networks
Feb 23, 2022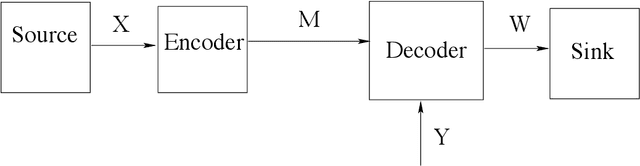
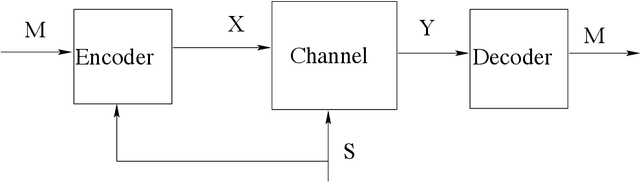
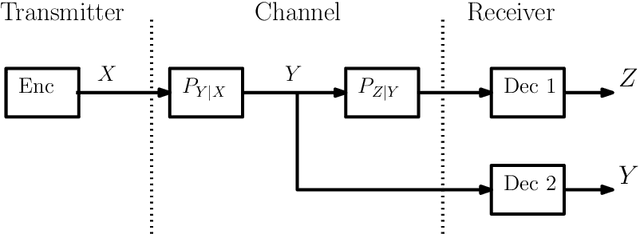
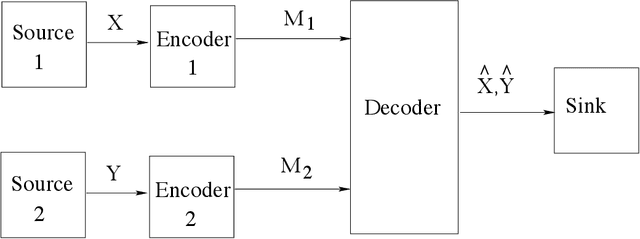
In this paper, we consider the information-theoretic characterization of the set of achievable rates and distortions in a broad class of multiterminal communication scenarios with general continuous-valued sources and channels. A framework is presented which involves fine discretization of the source and channel variables followed by communication over the resulting discretized network. In order to evaluate fundamental performance limits, convergence results for information measures are provided under the proposed discretization process. Using this framework, we consider point-to-point source coding and channel coding with side-information, distributed source coding with distortion constraints, the function reconstruction problems (two-help-one), computation over multiple access channel, the interference channel, and the multiple-descriptions source coding problem. We construct lattice-like codes for general sources and channels, and derive inner-bounds to set of achievable rates and distortions in these communication scenarios.
Cost-effective End-to-end Information Extraction for Semi-structured Document Images
Apr 16, 2021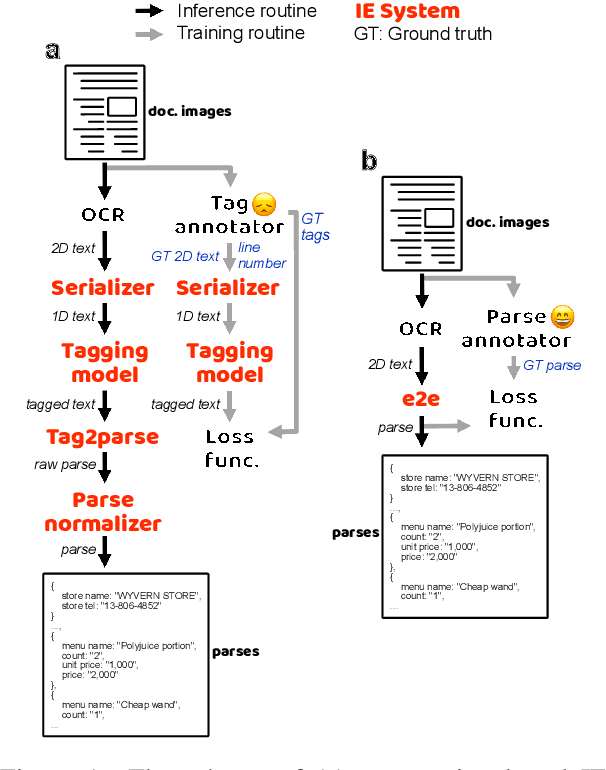

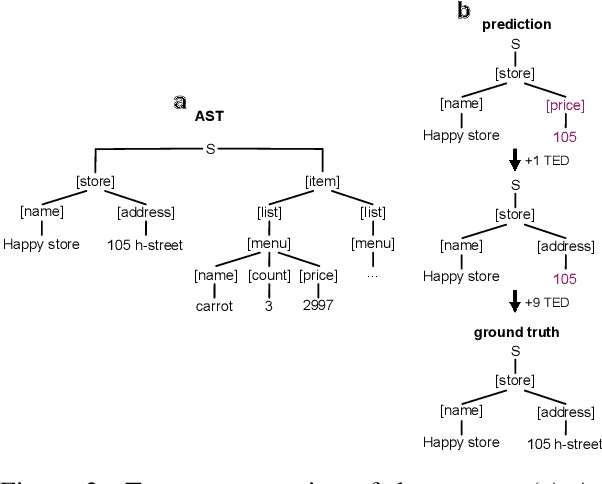

A real-world information extraction (IE) system for semi-structured document images often involves a long pipeline of multiple modules, whose complexity dramatically increases its development and maintenance cost. One can instead consider an end-to-end model that directly maps the input to the target output and simplify the entire process. However, such generation approach is known to lead to unstable performance if not designed carefully. Here we present our recent effort on transitioning from our existing pipeline-based IE system to an end-to-end system focusing on practical challenges that are associated with replacing and deploying the system in real, large-scale production. By carefully formulating document IE as a sequence generation task, we show that a single end-to-end IE system can be built and still achieve competent performance.
ParkPredict+: Multimodal Intent and Motion Prediction for Vehicles in Parking Lots with CNN and Transformer
Apr 17, 2022



The problem of multimodal intent and trajectory prediction for human-driven vehicles in parking lots is addressed in this paper. Using models designed with CNN and Transformer networks, we extract temporal-spatial and contextual information from trajectory history and local bird's eye view (BEV) semantic images, and generate predictions about intent distribution and future trajectory sequences. Our methods outperforms existing models in accuracy, while allowing an arbitrary number of modes, encoding complex multi-agent scenarios, and adapting to different parking maps. In addition, we present the first public human driving dataset in parking lot with high resolution and rich traffic scenarios for relevant research in this field.
ProxyMix: Proxy-based Mixup Training with Label Refinery for Source-Free Domain Adaptation
May 29, 2022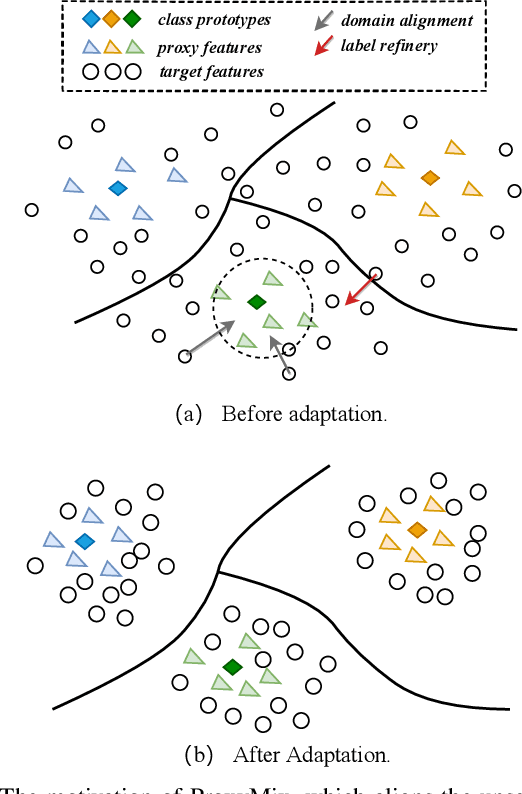
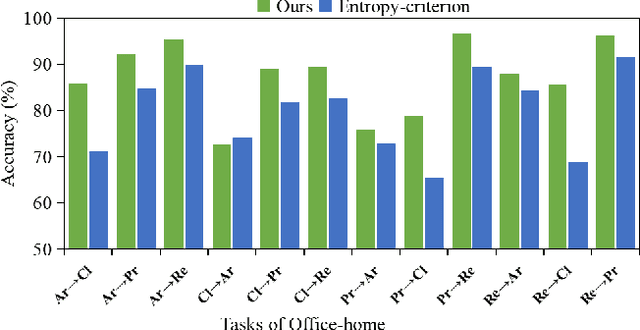
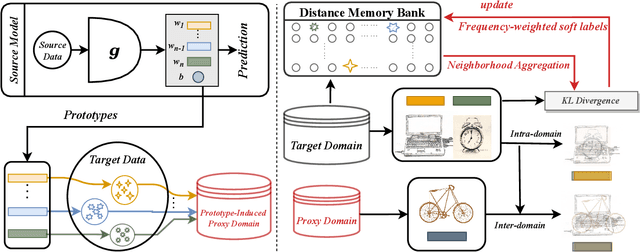
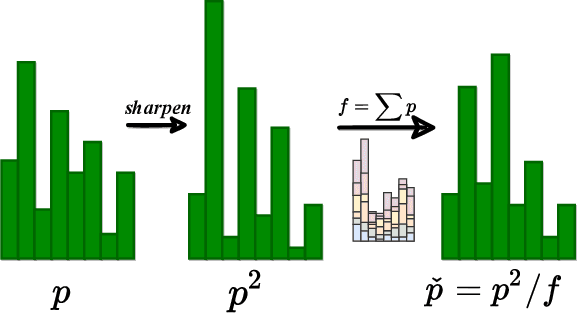
Unsupervised domain adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain. Owing to privacy concerns and heavy data transmission, source-free UDA, exploiting the pre-trained source models instead of the raw source data for target learning, has been gaining popularity in recent years. Some works attempt to recover unseen source domains with generative models, however introducing additional network parameters. Other works propose to fine-tune the source model by pseudo labels, while noisy pseudo labels may misguide the decision boundary, leading to unsatisfied results. To tackle these issues, we propose an effective method named Proxy-based Mixup training with label refinery (ProxyMix). First of all, to avoid additional parameters and explore the information in the source model, ProxyMix defines the weights of the classifier as the class prototypes and then constructs a class-balanced proxy source domain by the nearest neighbors of the prototypes to bridge the unseen source domain and the target domain. To improve the reliability of pseudo labels, we further propose the frequency-weighted aggregation strategy to generate soft pseudo labels for unlabeled target data. The proposed strategy exploits the internal structure of target features, pulls target features to their semantic neighbors, and increases the weights of low-frequency classes samples during gradient updating. With the proxy domain and the reliable pseudo labels, we employ two kinds of mixup regularization, i.e., inter- and intra-domain mixup, in our framework, to align the proxy and the target domain, enforcing the consistency of predictions, thereby further mitigating the negative impacts of noisy labels. Experiments on three 2D image and one 3D point cloud object recognition benchmarks demonstrate that ProxyMix yields state-of-the-art performance for source-free UDA tasks.
BinsFormer: Revisiting Adaptive Bins for Monocular Depth Estimation
Apr 03, 2022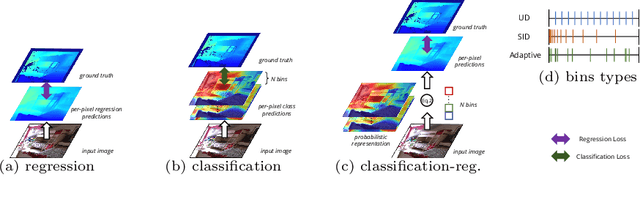
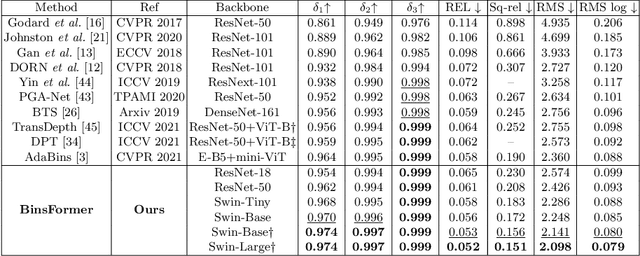
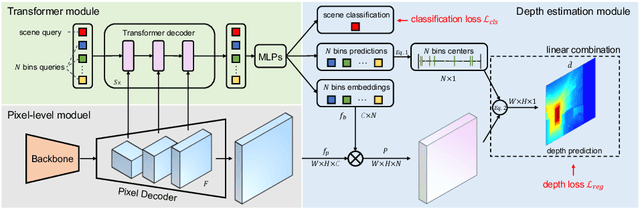
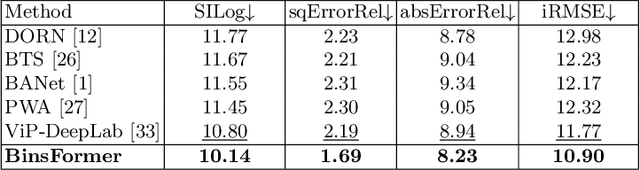
Monocular depth estimation is a fundamental task in computer vision and has drawn increasing attention. Recently, some methods reformulate it as a classification-regression task to boost the model performance, where continuous depth is estimated via a linear combination of predicted probability distributions and discrete bins. In this paper, we present a novel framework called BinsFormer, tailored for the classification-regression-based depth estimation. It mainly focuses on two crucial components in the specific task: 1) proper generation of adaptive bins and 2) sufficient interaction between probability distribution and bins predictions. To specify, we employ the Transformer decoder to generate bins, novelly viewing it as a direct set-to-set prediction problem. We further integrate a multi-scale decoder structure to achieve a comprehensive understanding of spatial geometry information and estimate depth maps in a coarse-to-fine manner. Moreover, an extra scene understanding query is proposed to improve the estimation accuracy, which turns out that models can implicitly learn useful information from an auxiliary environment classification task. Extensive experiments on the KITTI, NYU, and SUN RGB-D datasets demonstrate that BinsFormer surpasses state-of-the-art monocular depth estimation methods with prominent margins. Code and pretrained models will be made publicly available at \url{https://github.com/zhyever/Monocular-Depth-Estimation-Toolbox}.