 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Shielding for Cross-Domain Wi-Fi Signal Adaptation using Relativistic Average Generative Adversarial Network
Apr 29, 2025Wi-Fi sensing uses radio-frequency signals from Wi-Fi devices to analyze environments, enabling tasks such as tracking people, detecting intrusions, and recognizing gestures. The rise of this technology is driven by the IEEE 802.11bf standard and growing demand for tools that can ensure privacy and operate through obstacles. However, the performance of Wi-Fi sensing is heavily influenced by environmental conditions, especially when extracting spatial and temporal features from the surrounding scene. A key challenge is achieving robust generalization across domains, ensuring stable performance even when the sensing environment changes significantly. This paper introduces a novel deep learning model for cross-domain adaptation of Wi-Fi signals, inspired by physical signal shielding. The model uses a Relativistic average Generative Adversarial Network (RaGAN) with Bidirectional Long Short-Term Memory (Bi-LSTM) architectures for both the generator and discriminator. To simulate physical shielding, an acrylic box lined with electromagnetic shielding fabric was constructed, mimicking a Faraday cage. Wi-Fi signal spectra were collected from various materials both inside (domain-free) and outside (domain-dependent) the box to train the model. A multi-class Support Vector Machine (SVM) was trained on domain-free spectra and tested on signals denoised by the RaGAN. The system achieved 96% accuracy and demonstrated strong material discrimination capabilities, offering potential for use in security applications to identify concealed objects based on their composition.
Autoencoder Models for Point Cloud Environmental Synthesis from WiFi Channel State Information: A Preliminary Study
Apr 29, 2025This paper introduces a deep learning framework for generating point clouds from WiFi Channel State Information data. We employ a two-stage autoencoder approach: a PointNet autoencoder with convolutional layers for point cloud generation, and a Convolutional Neural Network autoencoder to map CSI data to a matching latent space. By aligning these latent spaces, our method enables accurate environmental point cloud reconstruction from WiFi data. Experimental results validate the effectiveness of our approach, highlighting its potential for wireless sensing and environmental mapping applications.
ReViT: Enhancing Vision Transformers with Attention Residual Connections for Visual Recognition
Feb 17, 2024



Vision Transformer (ViT) self-attention mechanism is characterized by feature collapse in deeper layers, resulting in the vanishing of low-level visual features. However, such features can be helpful to accurately represent and identify elements within an image and increase the accuracy and robustness of vision-based recognition systems. Following this rationale, we propose a novel residual attention learning method for improving ViT-based architectures, increasing their visual feature diversity and model robustness. In this way, the proposed network can capture and preserve significant low-level features, providing more details about the elements within the scene being analyzed. The effectiveness and robustness of the presented method are evaluated on five image classification benchmarks, including ImageNet1k, CIFAR10, CIFAR100, Oxford Flowers-102, and Oxford-IIIT Pet, achieving improved performances. Additionally, experiments on the COCO2017 dataset show that the devised approach discovers and incorporates semantic and spatial relationships for object detection and instance segmentation when implemented into spatial-aware transformer models.
Medicinal Boxes Recognition on a Deep Transfer Learning Augmented Reality Mobile Application
Mar 26, 2022



Taking medicines is a fundamental aspect to cure illnesses. However, studies have shown that it can be hard for patients to remember the correct posology. More aggravating, a wrong dosage generally causes the disease to worsen. Although, all relevant instructions for a medicine are summarized in the corresponding patient information leaflet, the latter is generally difficult to navigate and understand. To address this problem and help patients with their medication, in this paper we introduce an augmented reality mobile application that can present to the user important details on the framed medicine. In particular, the app implements an inference engine based on a deep neural network, i.e., a densenet, fine-tuned to recognize a medicinal from its package. Subsequently, relevant information, such as posology or a simplified leaflet, is overlaid on the camera feed to help a patient when taking a medicine. Extensive experiments to select the best hyperparameters were performed on a dataset specifically collected to address this task; ultimately obtaining up to 91.30\% accuracy as well as real-time capabilities.
Analyzing EEG Data with Machine and Deep Learning: A Benchmark
Mar 18, 2022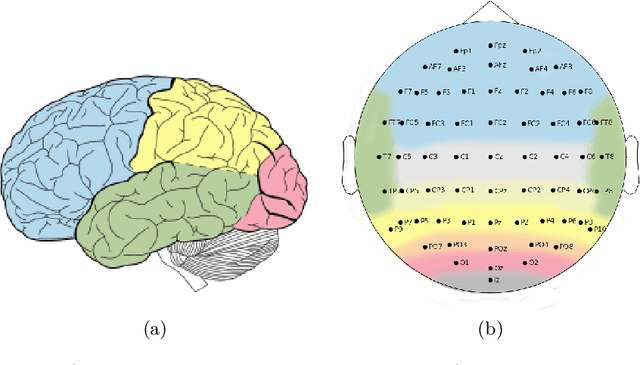


Nowadays, machine and deep learning techniques are widely used in different areas, ranging from economics to biology. In general, these techniques can be used in two ways: trying to adapt well-known models and architectures to the available data, or designing custom architectures. In both cases, to speed up the research process, it is useful to know which type of models work best for a specific problem and/or data type. By focusing on EEG signal analysis, and for the first time in literature, in this paper a benchmark of machine and deep learning for EEG signal classification is proposed. For our experiments we used the four most widespread models, i.e., multilayer perceptron, convolutional neural network, long short-term memory, and gated recurrent unit, highlighting which one can be a good starting point for developing EEG classification models.
Human Silhouette and Skeleton Video Synthesis through Wi-Fi signals
Mar 11, 2022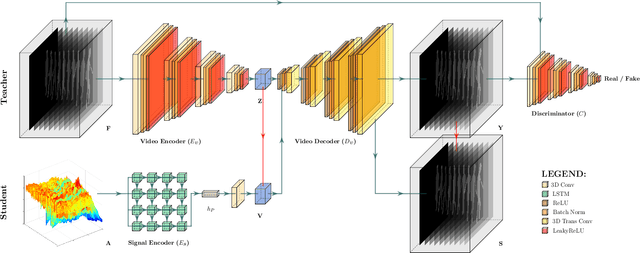
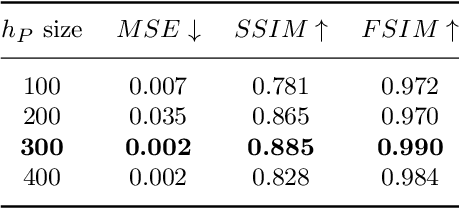
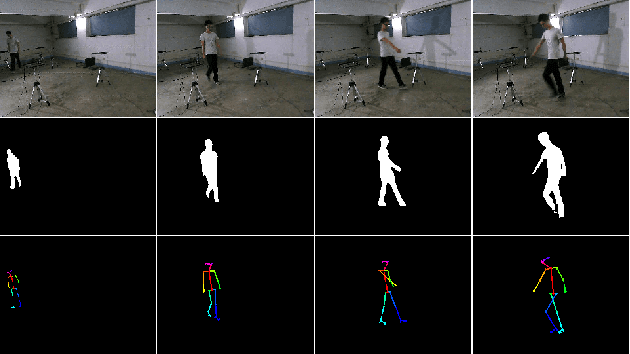
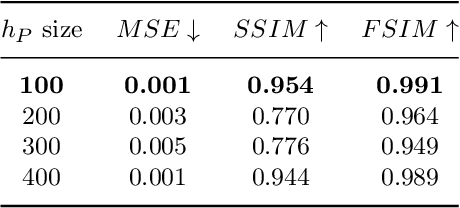
The increasing availability of wireless access points (APs) is leading towards human sensing applications based on Wi-Fi signals as support or alternative tools to the widespread visual sensors, where the signals enable to address well-known vision-related problems such as illumination changes or occlusions. Indeed, using image synthesis techniques to translate radio frequencies to the visible spectrum can become essential to obtain otherwise unavailable visual data. This domain-to-domain translation is feasible because both objects and people affect electromagnetic waves, causing radio and optical frequencies variations. In literature, models capable of inferring radio-to-visual features mappings have gained momentum in the last few years since frequency changes can be observed in the radio domain through the channel state information (CSI) of Wi-Fi APs, enabling signal-based feature extraction, e.g., amplitude. On this account, this paper presents a novel two-branch generative neural network that effectively maps radio data into visual features, following a teacher-student design that exploits a cross-modality supervision strategy. The latter conditions signal-based features in the visual domain to completely replace visual data. Once trained, the proposed method synthesizes human silhouette and skeleton videos using exclusively Wi-Fi signals. The approach is evaluated on publicly available data, where it obtains remarkable results for both silhouette and skeleton videos generation, demonstrating the effectiveness of the proposed cross-modality supervision strategy.
Study on Transfer Learning Capabilities for Pneumonia Classification in Chest-X-Rays Image
Oct 06, 2021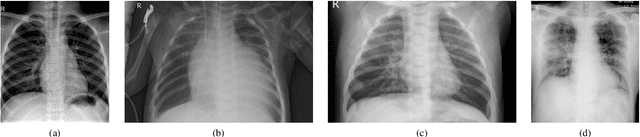
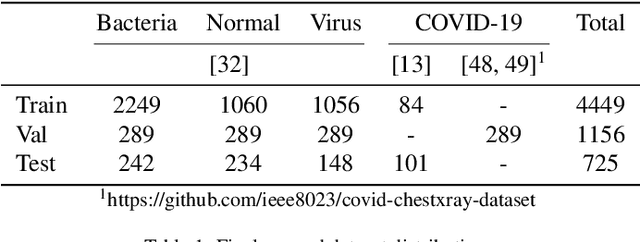
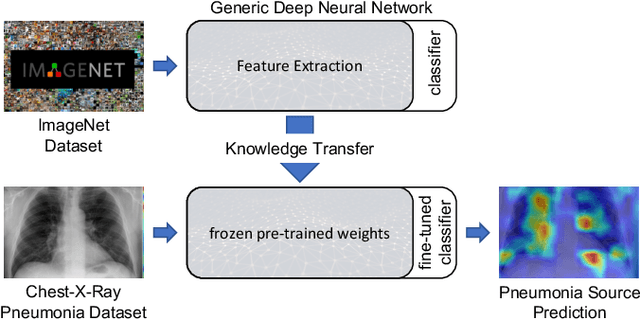
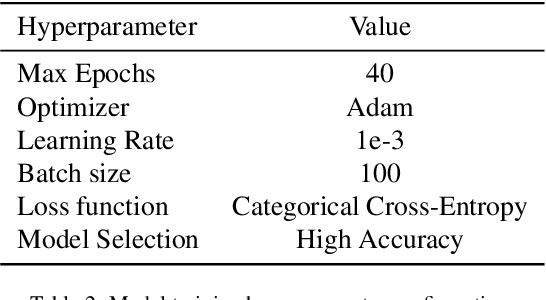
Over the last year, the severe acute respiratory syndrome coronavirus-2 (SARS-CoV-2) and its variants have highlighted the importance of screening tools with high diagnostic accuracy for new illnesses such as COVID-19. To that regard, deep learning approaches have proven as effective solutions for pneumonia classification, especially when considering chest-x-rays images. However, this lung infection can also be caused by other viral, bacterial or fungi pathogens. Consequently, efforts are being poured toward distinguishing the infection source to help clinicians to diagnose the correct disease origin. Following this tendency, this study further explores the effectiveness of established neural network architectures on the pneumonia classification task through the transfer learning paradigm. To present a comprehensive comparison, 12 well-known ImageNet pre-trained models were fine-tuned and used to discriminate among chest-x-rays of healthy people, and those showing pneumonia symptoms derived from either a viral (i.e., generic or SARS-CoV-2) or bacterial source. Furthermore, since a common public collection distinguishing between such categories is currently not available, two distinct datasets of chest-x-rays images, describing the aforementioned sources, were combined and employed to evaluate the various architectures. The experiments were performed using a total of 6330 images split between train, validation and test sets. For all models, common classification metrics were computed (e.g., precision, f1-score) and most architectures obtained significant performances, reaching, among the others, up to 84.46% average f1-score when discriminating the 4 identified classes. Moreover, confusion matrices and activation maps computed via the Grad-CAM algorithm were also reported to present an informed discussion on the networks classifications.
SIRe-Networks: Skip Connections over Interlaced Multi-Task Learning and Residual Connections for Structure Preserving Object Classification
Oct 06, 2021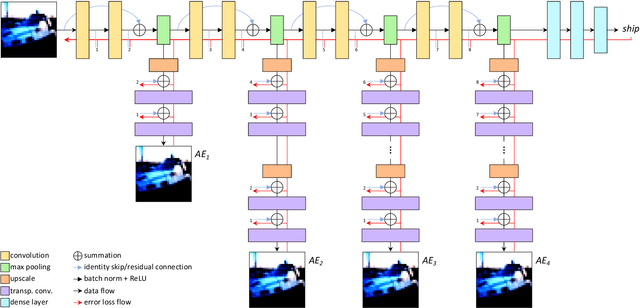
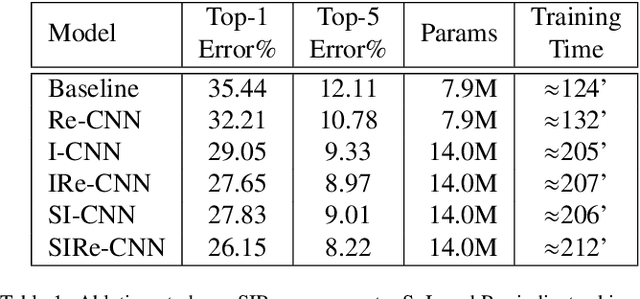

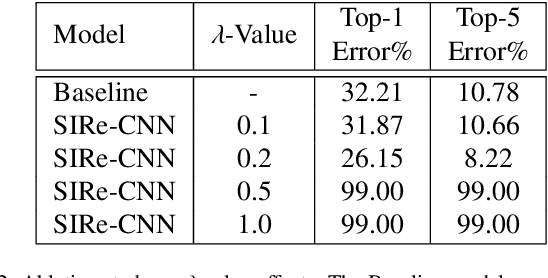
Improving existing neural network architectures can involve several design choices such as manipulating the loss functions, employing a diverse learning strategy, exploiting gradient evolution at training time, optimizing the network hyper-parameters, or increasing the architecture depth. The latter approach is a straightforward solution, since it directly enhances the representation capabilities of a network; however, the increased depth generally incurs in the well-known vanishing gradient problem. In this paper, borrowing from different methods addressing this issue, we introduce an interlaced multi-task learning strategy, defined SIRe, to reduce the vanishing gradient in relation to the object classification task. The presented methodology directly improves a convolutional neural network (CNN) by enforcing the input image structure preservation through interlaced auto-encoders, and further refines the base network architecture by means of skip and residual connections. To validate the presented methodology, a simple CNN and various implementations of famous networks are extended via the SIRe strategy and extensively tested on the CIFAR100 dataset; where the SIRe-extended architectures achieve significantly increased performances across all models, thus confirming the presented approach effectiveness.
3D Hand Pose and Shape Estimation from RGB Images for Improved Keypoint-Based Hand-Gesture Recognition
Sep 28, 2021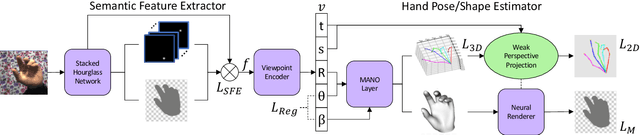

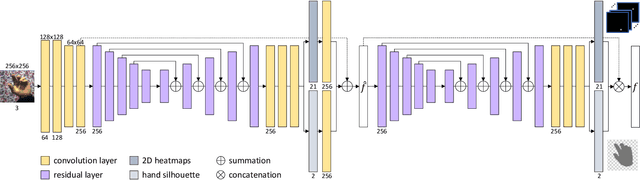
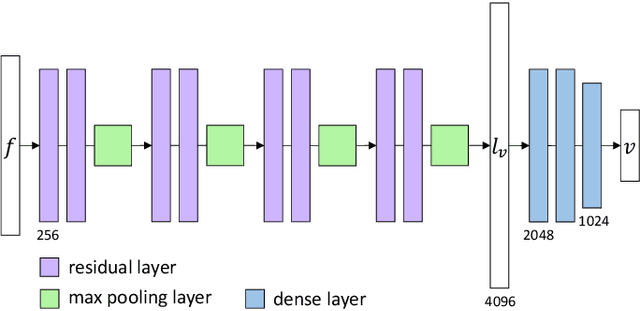
Estimating the 3D hand pose from a 2D image is a well-studied problem and a requirement for several real-life applications such as virtual reality, augmented reality, and hand-gesture recognition. Currently, good estimations can be computed starting from single RGB images, especially when forcing the system to also consider, through a multi-task learning approach, the hand shape when the pose is determined. However, when addressing the aforementioned real-life tasks, performances can drop considerably depending on the hand representation, thus suggesting that stable descriptions are required to achieve satisfactory results. As a consequence, in this paper we present a keypoint-based end-to-end framework for the 3D hand and pose estimation, and successfully apply it to the hand-gesture recognition task as a study case. Specifically, after a pre-processing step where the images are normalized, the proposed pipeline comprises a multi-task semantic feature extractor generating 2D heatmaps and hand silhouettes from RGB images; a viewpoint encoder predicting hand and camera view parameters; a stable hand estimator producing the 3D hand pose and shape; and a loss function designed to jointly guide all of the components during the learning phase. To assess the proposed framework, tests were performed on a 3D pose and shape estimation benchmark dataset, obtaining state-of-the-art performances. What is more, the devised system was also evaluated on 2 hand-gesture recognition benchmark datasets, where the framework significantly outperforms other keypoint-based approaches; indicating that the presented method is an effective solution able to generate stable 3D estimates for the hand pose and shape.
Knowledge-Driven Learning via Experts Consult for Thyroid Nodule Classification
May 28, 2020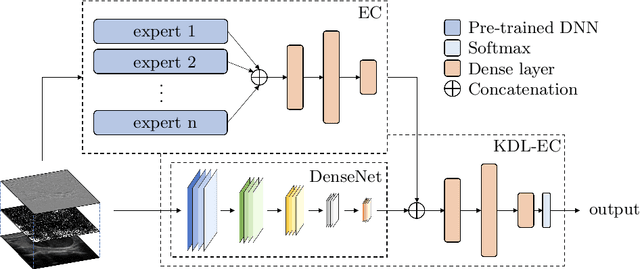
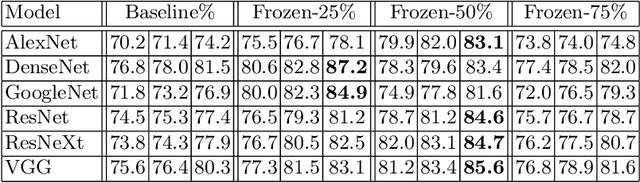

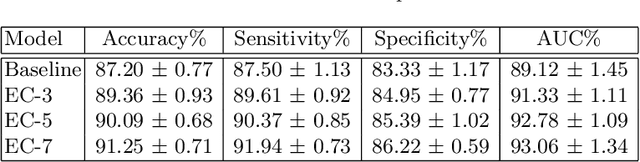
Computer-aided diagnosis (CAD) is becoming a prominent approach to assist clinicians spanning across multiple fields. These automated systems take advantage of various computer vision (CV) procedures, as well as artificial intelligence (AI) techniques, so that a diagnosis of a given image (e.g., computed tomography and ultrasound) can be formulated. Advances in both areas (CV and AI) are enabling ever increasing performances of CAD systems, which can ultimately avoid performing invasive procedures such as fine-needle aspiration. In this study, we focus on thyroid ultrasonography to present a novel knowledge-driven classification framework. The proposed system leverages cues provided by an ensemble of experts, in order to guide the learning phase of a densely connected convolutional network (DenseNet). The ensemble is composed by various networks pretrained on ImageNet, including AlexNet, ResNet, VGG, and others, so that previously computed feature parameters could be used to create ultrasonography domain experts via transfer learning, decreasing, moreover, the number of samples required for training. To validate the proposed method, extensive experiments were performed, providing detailed performances for both the experts ensemble and the knowledge-driven DenseNet. The obtained results, show how the the proposed system can become a great asset when formulating a diagnosis, by leveraging previous knowledge derived from a consult.