 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Shielding for Cross-Domain Wi-Fi Signal Adaptation using Relativistic Average Generative Adversarial Network
Apr 29, 2025Wi-Fi sensing uses radio-frequency signals from Wi-Fi devices to analyze environments, enabling tasks such as tracking people, detecting intrusions, and recognizing gestures. The rise of this technology is driven by the IEEE 802.11bf standard and growing demand for tools that can ensure privacy and operate through obstacles. However, the performance of Wi-Fi sensing is heavily influenced by environmental conditions, especially when extracting spatial and temporal features from the surrounding scene. A key challenge is achieving robust generalization across domains, ensuring stable performance even when the sensing environment changes significantly. This paper introduces a novel deep learning model for cross-domain adaptation of Wi-Fi signals, inspired by physical signal shielding. The model uses a Relativistic average Generative Adversarial Network (RaGAN) with Bidirectional Long Short-Term Memory (Bi-LSTM) architectures for both the generator and discriminator. To simulate physical shielding, an acrylic box lined with electromagnetic shielding fabric was constructed, mimicking a Faraday cage. Wi-Fi signal spectra were collected from various materials both inside (domain-free) and outside (domain-dependent) the box to train the model. A multi-class Support Vector Machine (SVM) was trained on domain-free spectra and tested on signals denoised by the RaGAN. The system achieved 96% accuracy and demonstrated strong material discrimination capabilities, offering potential for use in security applications to identify concealed objects based on their composition.
Autoencoder Models for Point Cloud Environmental Synthesis from WiFi Channel State Information: A Preliminary Study
Apr 29, 2025This paper introduces a deep learning framework for generating point clouds from WiFi Channel State Information data. We employ a two-stage autoencoder approach: a PointNet autoencoder with convolutional layers for point cloud generation, and a Convolutional Neural Network autoencoder to map CSI data to a matching latent space. By aligning these latent spaces, our method enables accurate environmental point cloud reconstruction from WiFi data. Experimental results validate the effectiveness of our approach, highlighting its potential for wireless sensing and environmental mapping applications.
Medicinal Boxes Recognition on a Deep Transfer Learning Augmented Reality Mobile Application
Mar 26, 2022



Taking medicines is a fundamental aspect to cure illnesses. However, studies have shown that it can be hard for patients to remember the correct posology. More aggravating, a wrong dosage generally causes the disease to worsen. Although, all relevant instructions for a medicine are summarized in the corresponding patient information leaflet, the latter is generally difficult to navigate and understand. To address this problem and help patients with their medication, in this paper we introduce an augmented reality mobile application that can present to the user important details on the framed medicine. In particular, the app implements an inference engine based on a deep neural network, i.e., a densenet, fine-tuned to recognize a medicinal from its package. Subsequently, relevant information, such as posology or a simplified leaflet, is overlaid on the camera feed to help a patient when taking a medicine. Extensive experiments to select the best hyperparameters were performed on a dataset specifically collected to address this task; ultimately obtaining up to 91.30\% accuracy as well as real-time capabilities.
Analyzing EEG Data with Machine and Deep Learning: A Benchmark
Mar 18, 2022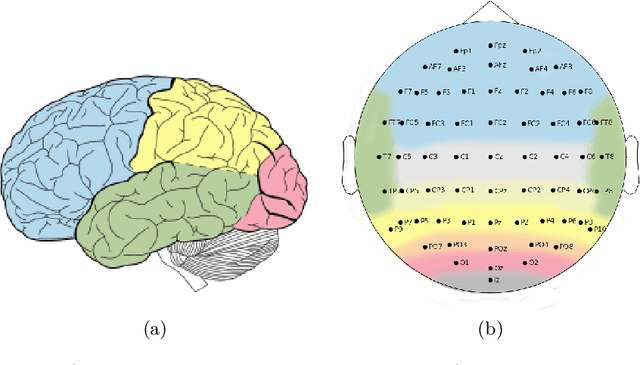

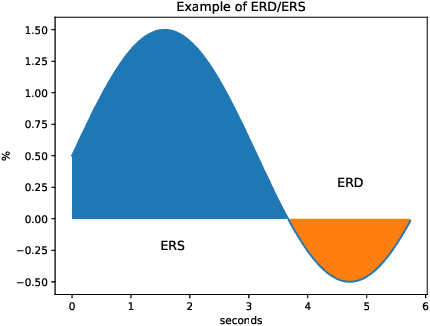

Nowadays, machine and deep learning techniques are widely used in different areas, ranging from economics to biology. In general, these techniques can be used in two ways: trying to adapt well-known models and architectures to the available data, or designing custom architectures. In both cases, to speed up the research process, it is useful to know which type of models work best for a specific problem and/or data type. By focusing on EEG signal analysis, and for the first time in literature, in this paper a benchmark of machine and deep learning for EEG signal classification is proposed. For our experiments we used the four most widespread models, i.e., multilayer perceptron, convolutional neural network, long short-term memory, and gated recurrent unit, highlighting which one can be a good starting point for developing EEG classification models.
3D Hand Pose and Shape Estimation from RGB Images for Improved Keypoint-Based Hand-Gesture Recognition
Sep 28, 2021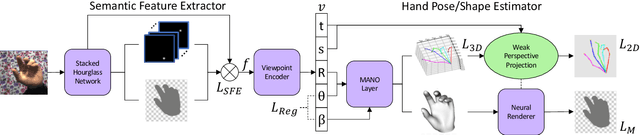

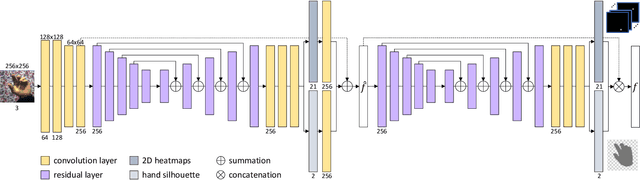
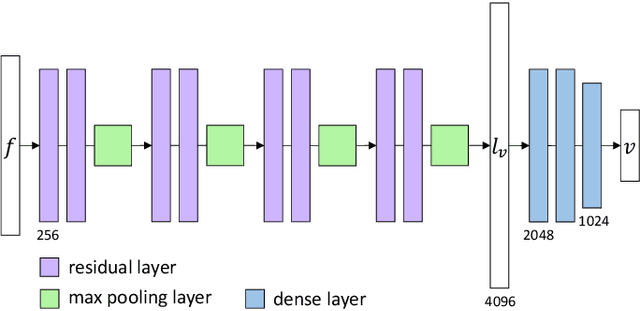
Estimating the 3D hand pose from a 2D image is a well-studied problem and a requirement for several real-life applications such as virtual reality, augmented reality, and hand-gesture recognition. Currently, good estimations can be computed starting from single RGB images, especially when forcing the system to also consider, through a multi-task learning approach, the hand shape when the pose is determined. However, when addressing the aforementioned real-life tasks, performances can drop considerably depending on the hand representation, thus suggesting that stable descriptions are required to achieve satisfactory results. As a consequence, in this paper we present a keypoint-based end-to-end framework for the 3D hand and pose estimation, and successfully apply it to the hand-gesture recognition task as a study case. Specifically, after a pre-processing step where the images are normalized, the proposed pipeline comprises a multi-task semantic feature extractor generating 2D heatmaps and hand silhouettes from RGB images; a viewpoint encoder predicting hand and camera view parameters; a stable hand estimator producing the 3D hand pose and shape; and a loss function designed to jointly guide all of the components during the learning phase. To assess the proposed framework, tests were performed on a 3D pose and shape estimation benchmark dataset, obtaining state-of-the-art performances. What is more, the devised system was also evaluated on 2 hand-gesture recognition benchmark datasets, where the framework significantly outperforms other keypoint-based approaches; indicating that the presented method is an effective solution able to generate stable 3D estimates for the hand pose and shape.
The UMCD Dataset
Apr 05, 2017



In recent years, the technological improvements of low-cost small-scale Unmanned Aerial Vehicles (UAVs) are promoting an ever-increasing use of them in different tasks. In particular, the use of small-scale UAVs is useful in all these low-altitude tasks in which common UAVs cannot be adopted, such as recurrent comprehensive view of wide environments, frequent monitoring of military areas, real-time classification of static and moving entities (e.g., people, cars, etc.). These tasks can be supported by mosaicking and change detection algorithms achieved at low-altitude. Currently, public datasets for testing these algorithms are not available. This paper presents the UMCD dataset, the first collection of geo-referenced video sequences acquired at low-altitude for mosaicking and change detection purposes. Five reference scenarios are also reported.