 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning to Truncate Ranked Lists for Information Retrieval
Feb 25, 2021
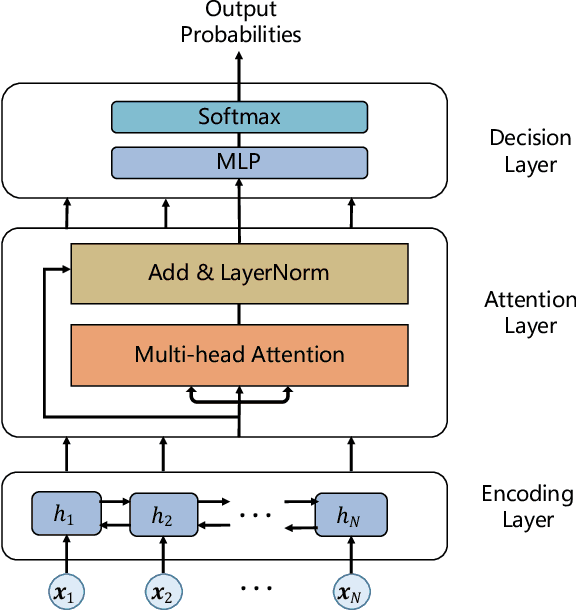

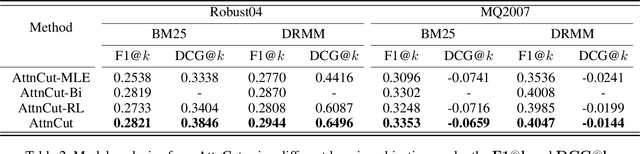
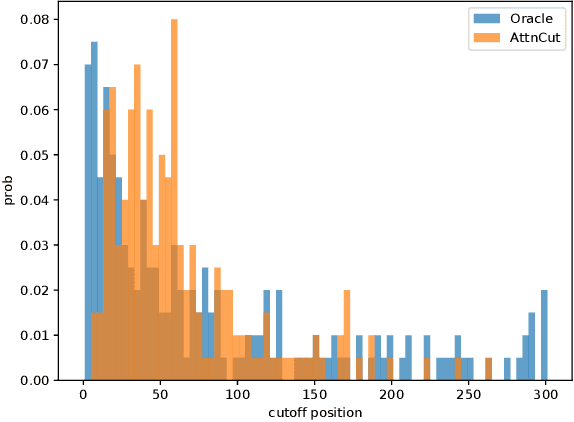
Ranked list truncation is of critical importance in a variety of professional information retrieval applications such as patent search or legal search. The goal is to dynamically determine the number of returned documents according to some user-defined objectives, in order to reach a balance between the overall utility of the results and user efforts. Existing methods formulate this task as a sequential decision problem and take some pre-defined loss as a proxy objective, which suffers from the limitation of local decision and non-direct optimization. In this work, we propose a global decision based truncation model named AttnCut, which directly optimizes user-defined objectives for the ranked list truncation. Specifically, we take the successful transformer architecture to capture the global dependency within the ranked list for truncation decision, and employ the reward augmented maximum likelihood (RAML) for direct optimization. We consider two types of user-defined objectives which are of practical usage. One is the widely adopted metric such as F1 which acts as a balanced objective, and the other is the best F1 under some minimal recall constraint which represents a typical objective in professional search. Empirical results over the Robust04 and MQ2007 datasets demonstrate the effectiveness of our approach as compared with the state-of-the-art baselines.
An Efficient Deep Learning Approach Using Improved Generative Adversarial Networks for Incomplete Information Completion of Self-driving
Sep 01, 2021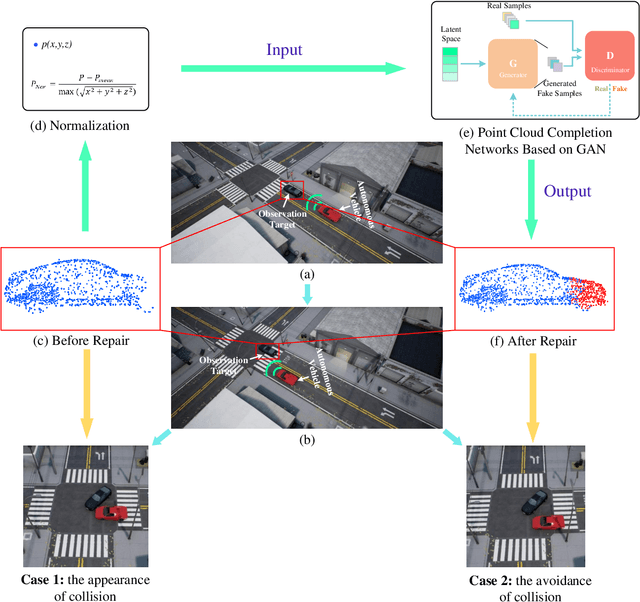
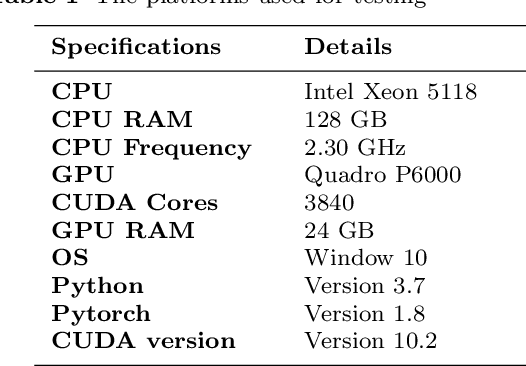
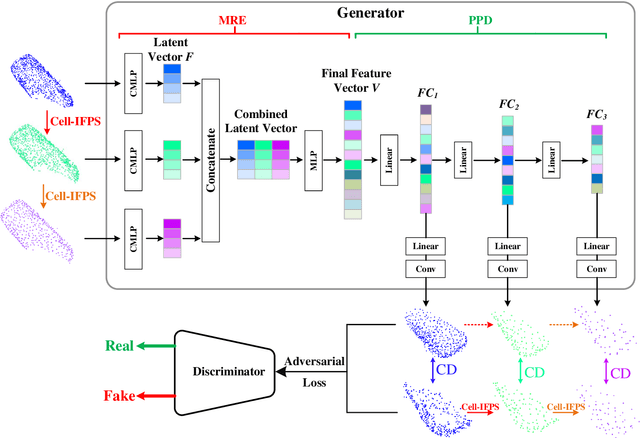
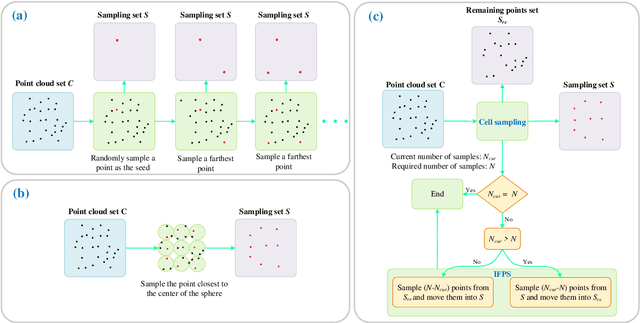
Autonomous driving is the key technology of intelligent logistics in Industrial Internet of Things (IIoT). In autonomous driving, the appearance of incomplete point clouds losing geometric and semantic information is inevitable owing to limitations of occlusion, sensor resolution, and viewing angle when the Light Detection And Ranging (LiDAR) is applied. The emergence of incomplete point clouds, especially incomplete vehicle point clouds, would lead to the reduction of the accuracy of autonomous driving vehicles in object detection, traffic alert, and collision avoidance. Existing point cloud completion networks, such as Point Fractal Network (PF-Net), focus on the accuracy of point cloud completion, without considering the efficiency of inference process, which makes it difficult for them to be deployed for vehicle point cloud repair in autonomous driving. To address the above problem, in this paper, we propose an efficient deep learning approach to repair incomplete vehicle point cloud accurately and efficiently in autonomous driving. In the proposed method, an efficient downsampling algorithm combining incremental sampling and one-time sampling is presented to improves the inference speed of the PF-Net based on Generative Adversarial Network (GAN). To evaluate the performance of the proposed method, a real dataset is used, and an autonomous driving scene is created, where three incomplete vehicle point clouds with 5 different sizes are set for three autonomous driving situations. The improved PF-Net can achieve the speedups of over 19x with almost the same accuracy when compared to the original PF-Net. Experimental results demonstrate that the improved PF-Net can be applied to efficiently complete vehicle point clouds in autonomous driving.
Single Image Internal Distribution Measurement Using Non-Local Variational Autoencoder
Apr 02, 2022
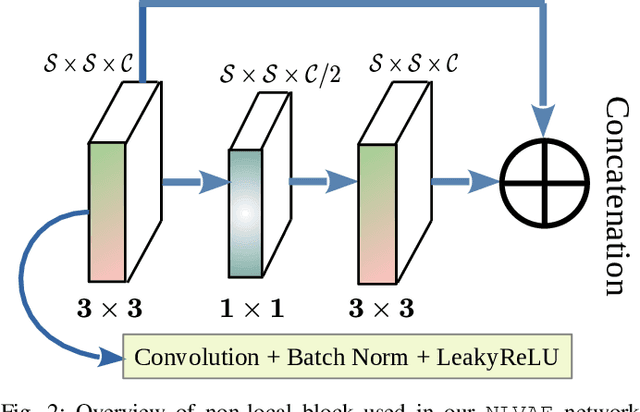
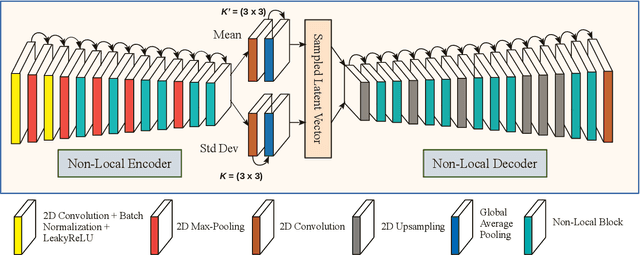

Deep learning-based super-resolution methods have shown great promise, especially for single image super-resolution (SISR) tasks. Despite the performance gain, these methods are limited due to their reliance on copious data for model training. In addition, supervised SISR solutions rely on local neighbourhood information focusing only on the feature learning processes for the reconstruction of low-dimensional images. Moreover, they fail to capitalize on global context due to their constrained receptive field. To combat these challenges, this paper proposes a novel image-specific solution, namely non-local variational autoencoder (\texttt{NLVAE}), to reconstruct a high-resolution (HR) image from a single low-resolution (LR) image without the need for any prior training. To harvest maximum details for various receptive regions and high-quality synthetic images, \texttt{NLVAE} is introduced as a self-supervised strategy that reconstructs high-resolution images using disentangled information from the non-local neighbourhood. Experimental results from seven benchmark datasets demonstrate the effectiveness of the \texttt{NLVAE} model. Moreover, our proposed model outperforms a number of baseline and state-of-the-art methods as confirmed through extensive qualitative and quantitative evaluations.
Toward a Geometrical Understanding of Self-supervised Contrastive Learning
May 13, 2022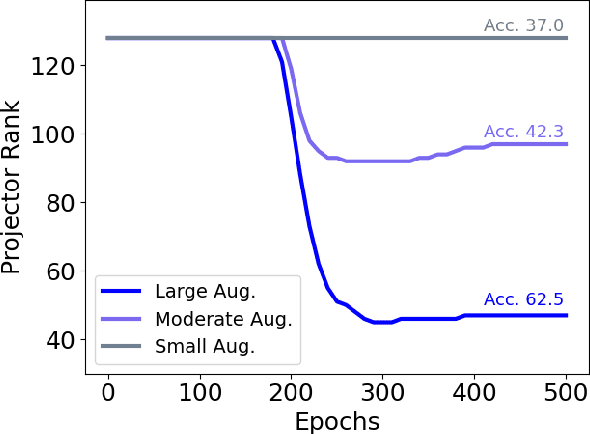

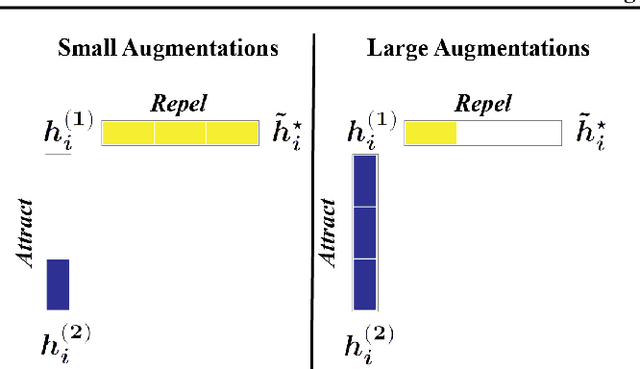

Self-supervised learning (SSL) is currently one of the premier techniques to create data representations that are actionable for transfer learning in the absence of human annotations. Despite their success, the underlying geometry of these representations remains elusive, which obfuscates the quest for more robust, trustworthy, and interpretable models. In particular, mainstream SSL techniques rely on a specific deep neural network architecture with two cascaded neural networks: the encoder and the projector. When used for transfer learning, the projector is discarded since empirical results show that its representation generalizes more poorly than the encoder's. In this paper, we investigate this curious phenomenon and analyze how the strength of the data augmentation policies affects the data embedding. We discover a non-trivial relation between the encoder, the projector, and the data augmentation strength: with increasingly larger augmentation policies, the projector, rather than the encoder, is more strongly driven to become invariant to the augmentations. It does so by eliminating crucial information about the data by learning to project it into a low-dimensional space, a noisy estimate of the data manifold tangent plane in the encoder representation. This analysis is substantiated through a geometrical perspective with theoretical and empirical results.
MAP-Gen: An Automated 3D-Box Annotation Flow with Multimodal Attention Point Generator
Mar 29, 2022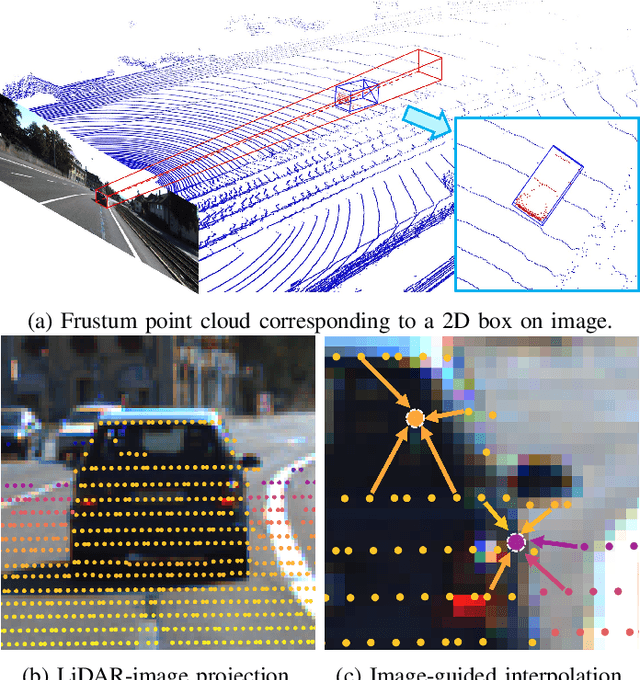
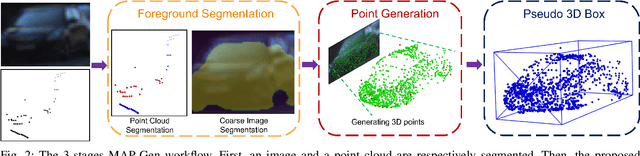
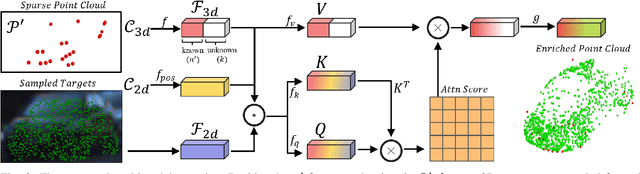
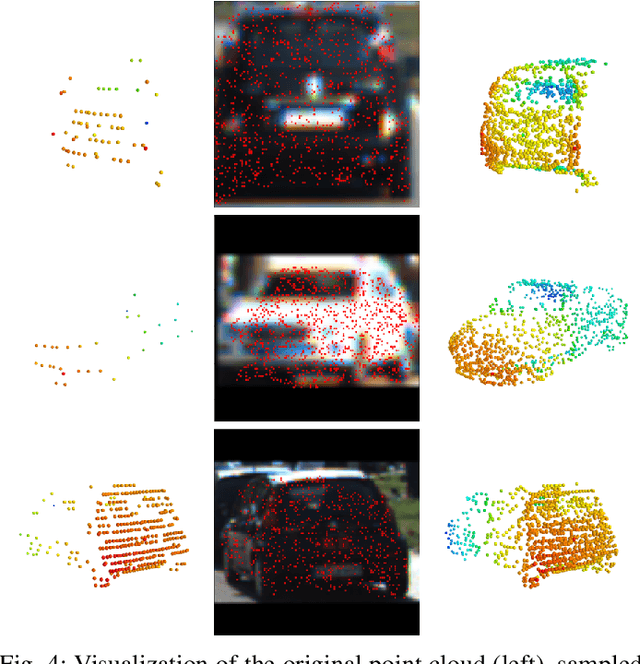
Manually annotating 3D point clouds is laborious and costly, limiting the training data preparation for deep learning in real-world object detection. While a few previous studies tried to automatically generate 3D bounding boxes from weak labels such as 2D boxes, the quality is sub-optimal compared to human annotators. This work proposes a novel autolabeler, called multimodal attention point generator (MAP-Gen), that generates high-quality 3D labels from weak 2D boxes. It leverages dense image information to tackle the sparsity issue of 3D point clouds, thus improving label quality. For each 2D pixel, MAP-Gen predicts its corresponding 3D coordinates by referencing context points based on their 2D semantic or geometric relationships. The generated 3D points densify the original sparse point clouds, followed by an encoder to regress 3D bounding boxes. Using MAP-Gen, object detection networks that are weakly supervised by 2D boxes can achieve 94~99% performance of those fully supervised by 3D annotations. It is hopeful this newly proposed MAP-Gen autolabeling flow can shed new light on utilizing multimodal information for enriching sparse point clouds.
Unified Interactive Image Matting
May 17, 2022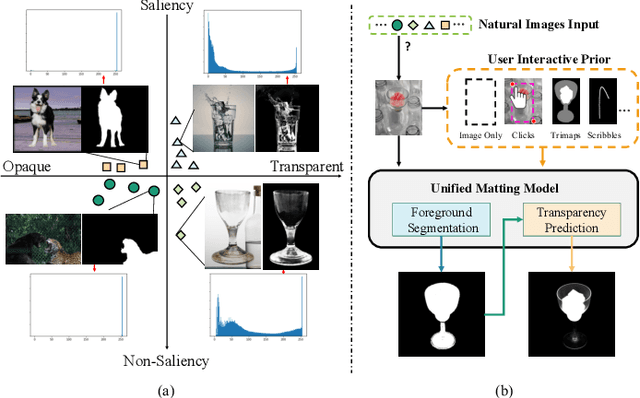

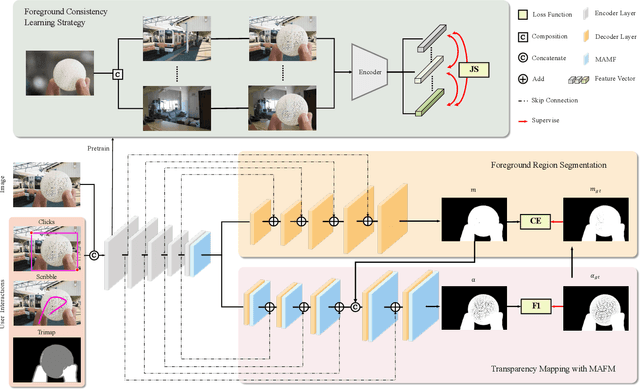
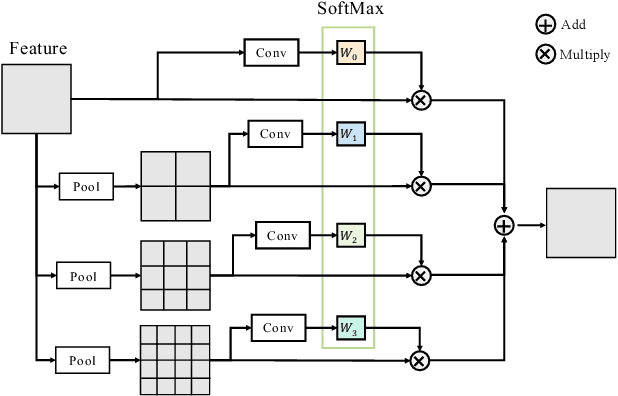
Recent image matting studies are developing towards proposing trimap-free or interactive methods for complete complex image matting tasks. Although avoiding the extensive labors of trimap annotation, existing methods still suffer from two limitations: (1) For the single image with multiple objects, it is essential to provide extra interaction information to help determining the matting target; (2) For transparent objects, the accurate regression of alpha matte from RGB image is much more difficult compared with the opaque ones. In this work, we propose a Unified Interactive image Matting method, named UIM, which solves the limitations and achieves satisfying matting results for any scenario. Specifically, UIM leverages multiple types of user interaction to avoid the ambiguity of multiple matting targets, and we compare the pros and cons of different annotation types in detail. To unify the matting performance for transparent and opaque objects, we decouple image matting into two stages, i.e., foreground segmentation and transparency prediction. Moreover, we design a multi-scale attentive fusion module to alleviate the vagueness in the boundary region. Experimental results demonstrate that UIM achieves state-of-the-art performance on the Composition-1K test set and a synthetic unified dataset. Our code and models will be released soon.
Cross-stitched Multi-modal Encoders
Apr 20, 2022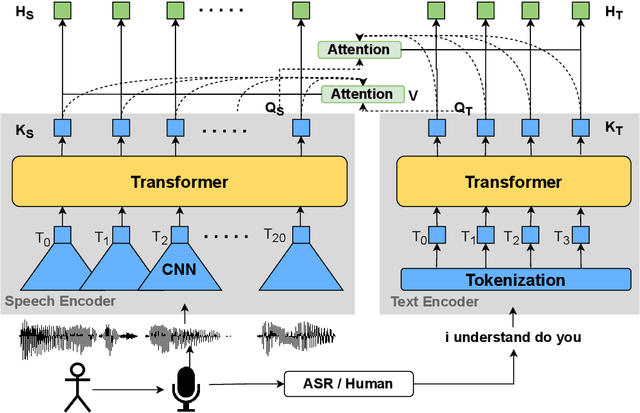
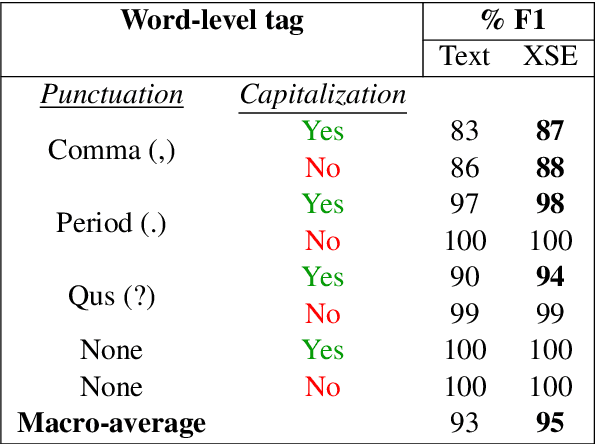
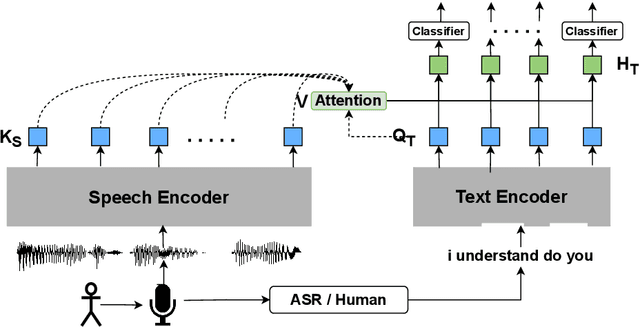
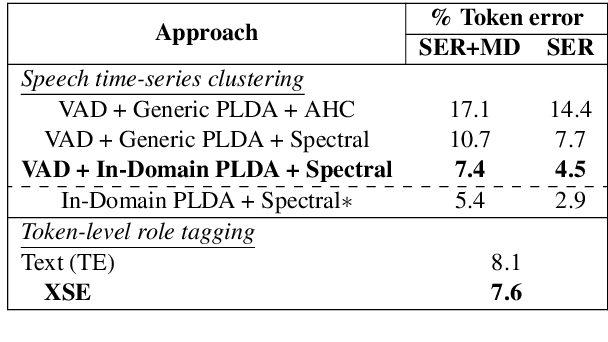
In this paper, we propose a novel architecture for multi-modal speech and text input. We combine pretrained speech and text encoders using multi-headed cross-modal attention and jointly fine-tune on the target problem. The resultant architecture can be used for continuous token-level classification or utterance-level prediction acting on simultaneous text and speech. The resultant encoder efficiently captures both acoustic-prosodic and lexical information. We compare the benefits of multi-headed attention-based fusion for multi-modal utterance-level classification against a simple concatenation of pre-pooled, modality-specific representations. Our model architecture is compact, resource efficient, and can be trained on a single consumer GPU card.
X-Trans2Cap: Cross-Modal Knowledge Transfer using Transformer for 3D Dense Captioning
Apr 06, 2022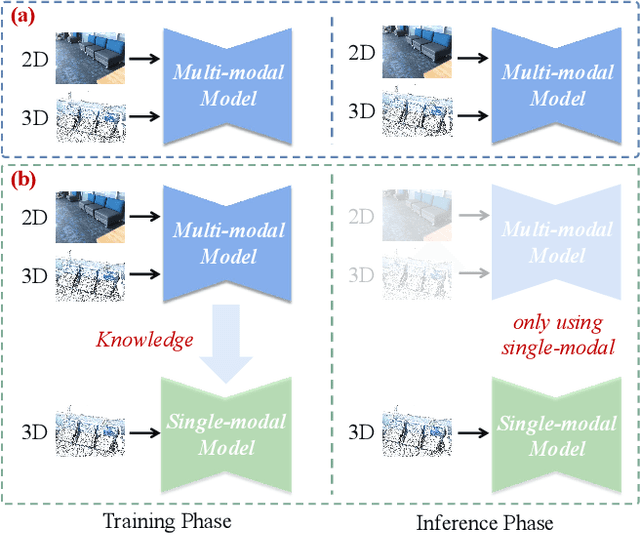
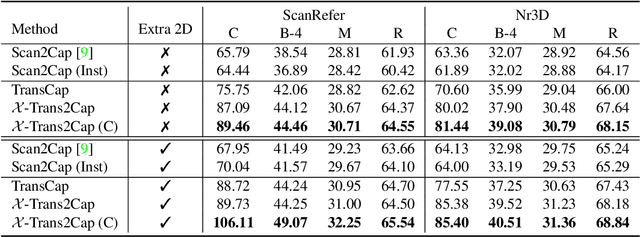
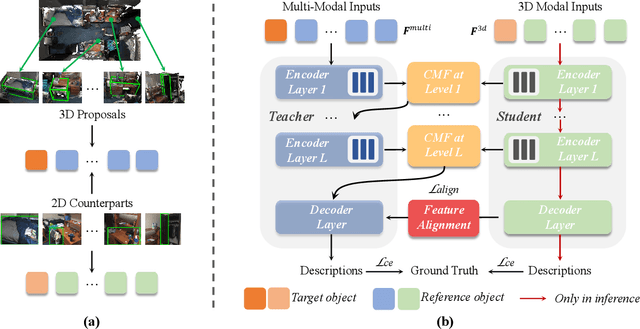

3D dense captioning aims to describe individual objects by natural language in 3D scenes, where 3D scenes are usually represented as RGB-D scans or point clouds. However, only exploiting single modal information, e.g., point cloud, previous approaches fail to produce faithful descriptions. Though aggregating 2D features into point clouds may be beneficial, it introduces an extra computational burden, especially in inference phases. In this study, we investigate a cross-modal knowledge transfer using Transformer for 3D dense captioning, X-Trans2Cap, to effectively boost the performance of single-modal 3D caption through knowledge distillation using a teacher-student framework. In practice, during the training phase, the teacher network exploits auxiliary 2D modality and guides the student network that only takes point clouds as input through the feature consistency constraints. Owing to the well-designed cross-modal feature fusion module and the feature alignment in the training phase, X-Trans2Cap acquires rich appearance information embedded in 2D images with ease. Thus, a more faithful caption can be generated only using point clouds during the inference. Qualitative and quantitative results confirm that X-Trans2Cap outperforms previous state-of-the-art by a large margin, i.e., about +21 and about +16 absolute CIDEr score on ScanRefer and Nr3D datasets, respectively.
A Structured Analysis of Journalistic Evaluations for News Source Reliability
May 05, 2022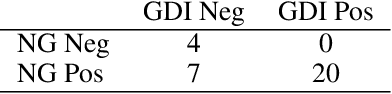
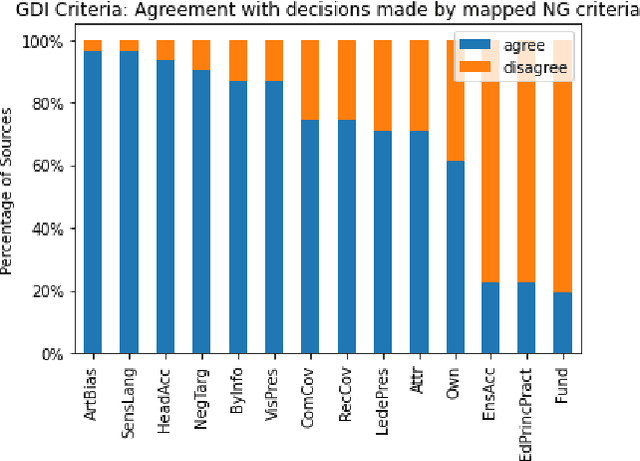
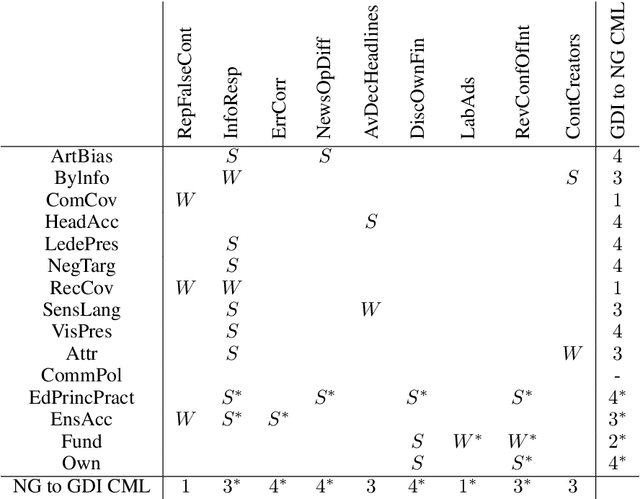
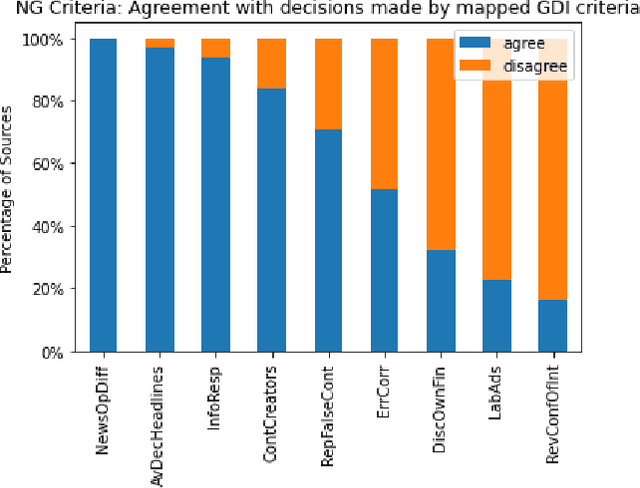
In today's era of information disorder, many organizations are moving to verify the veracity of news published on the web and social media. In particular, some agencies are exploring the world of online media and, through a largely manual process, ranking the credibility and transparency of news sources around the world. In this paper, we evaluate two procedures for assessing the risk of online media exposing their readers to m/disinformation. The procedures have been dictated by NewsGuard and The Global Disinformation Index, two well-known organizations combating d/misinformation via practices of good journalism. Specifically, considering a fixed set of media outlets, we examine how many of them were rated equally by the two procedures, and which aspects led to disagreement in the assessment. The result of our analysis shows a good degree of agreement, which in our opinion has a double value: it fortifies the correctness of the procedures and lays the groundwork for their automation.
Outage Analysis of Energy Efficiency in a Finite-Element-IRS Aided Communication System
May 17, 2022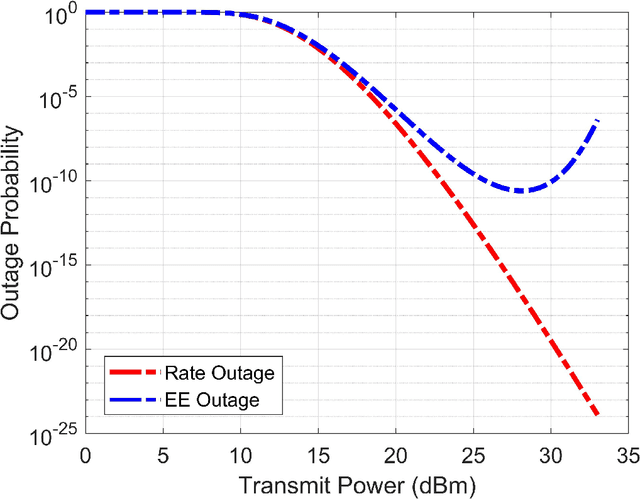
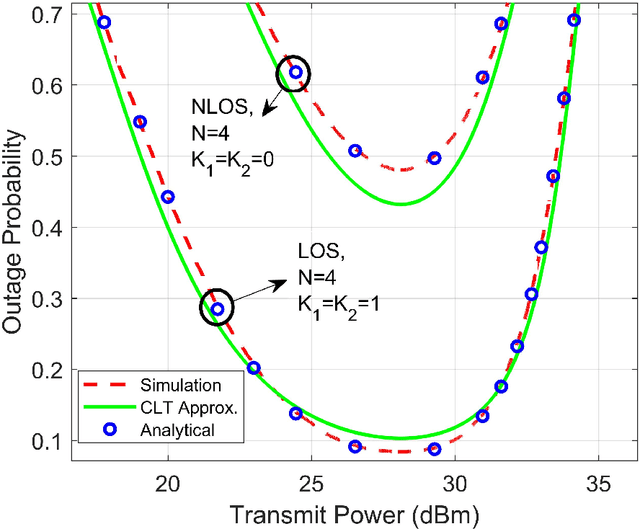
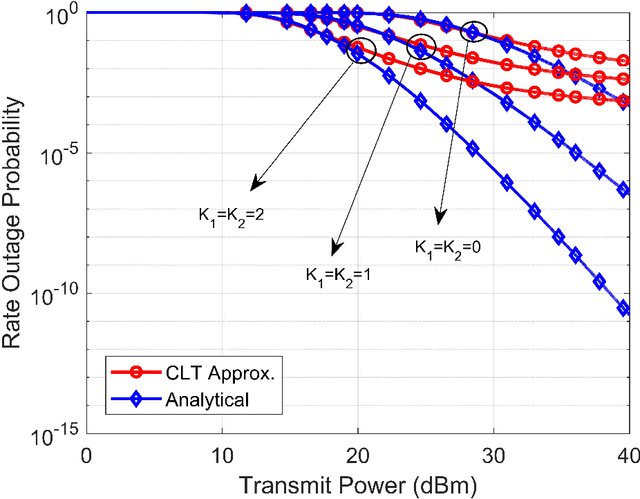
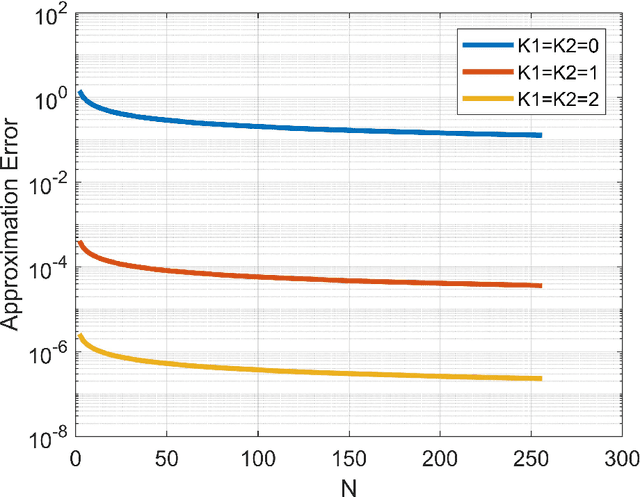
In this paper, we study the performance of an energy efficient wireless communication system, assisted by a finite-element-intelligent reflecting surface (IRS). With no instantaneous channel state information (CSI) at the transmitter, we characterize the system performance in terms of the outage probability (OP) of energy efficiency (EE). Depending upon the availability of line-of-sight (LOS) paths, we analyze the system for two different channel models, viz. Rician and Rayleigh. For an arbitrary number of IRS elements $(N)$, we derive the approximate closed-form solutions for the OP of EE, using Laguerre series and moment matching methods. The analytical results are validated using the Monte-Carlo simulations. Moreover, we also quantify the rate of convergence of the derived expressions to the central limit theorem (CLT) approximations using the \textit{Berry-Esseen} inequality. Further, we prove that the OP of EE is a strict pseudo-convex function of the transmit power and hence, has a unique global minimum. To obtain the optimal transmit power, we solve the OP of EE as a constrained optimization problem. To the best of our knowledge, the OP of EE as a performance metric, has never been previously studied in IRS-assisted wireless communication systems.