 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustera: A Live Conversation Redaction System
Mar 16, 2023


Trustera, the first functional system that redacts personally identifiable information (PII) in real-time spoken conversations to remove agents' need to hear sensitive information while preserving the naturalness of live customer-agent conversations. As opposed to post-call redaction, audio masking starts as soon as the customer begins speaking to a PII entity. This significantly reduces the risk of PII being intercepted or stored in insecure data storage. Trustera's architecture consists of a pipeline of automatic speech recognition, natural language understanding, and a live audio redactor module. The system's goal is three-fold: redact entities that are PII, mask the audio that goes to the agent, and at the same time capture the entity, so that the captured PII can be used for a payment transaction or caller identification. Trustera is currently being used by thousands of agents to secure customers' sensitive information.
E2E Spoken Entity Extraction for Virtual Agents
Mar 01, 2023



This paper reimagines some aspects of speech processing using speech encoders, specifically about extracting entities directly from speech, with no intermediate textual representation. In human-computer conversations, extracting entities such as names, postal addresses and email addresses from speech is a challenging task. In this paper, we study the impact of fine-tuning pre-trained speech encoders on extracting spoken entities in human-readable form directly from speech without the need for text transcription. We illustrate that such a direct approach optimizes the encoder to transcribe only the entity relevant portions of speech, ignoring the superfluous portions such as carrier phrases and spellings of entities. In the context of dialogs from an enterprise virtual agent, we demonstrate that the 1-step approach outperforms the typical 2-step cascade of first generating lexical transcriptions followed by text-based entity extraction for identifying spoken entities.
Cross-stitched Multi-modal Encoders
Apr 20, 2022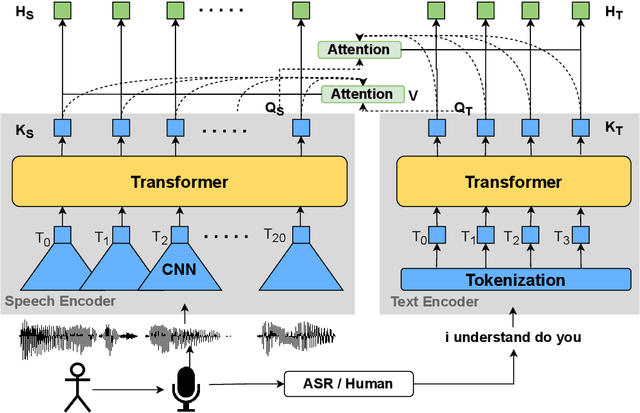
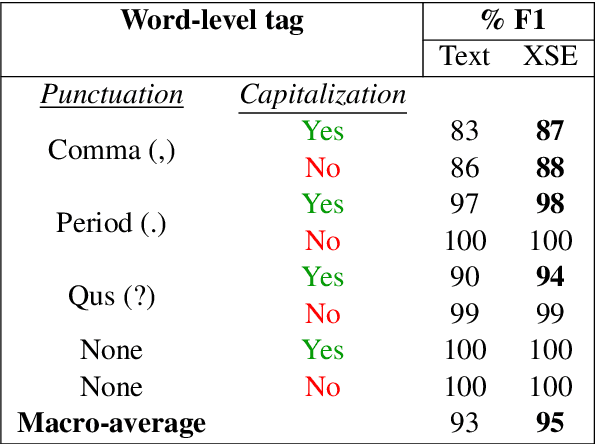
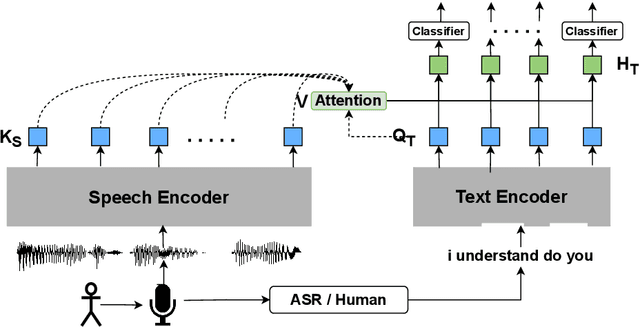
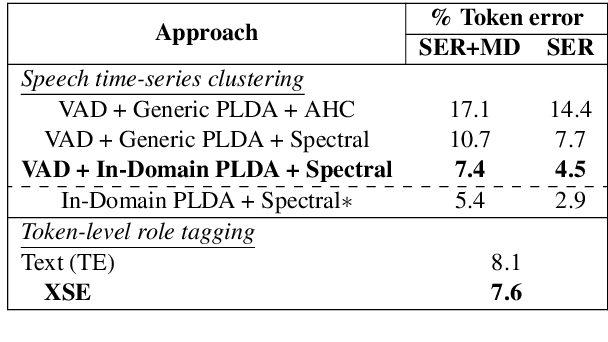
In this paper, we propose a novel architecture for multi-modal speech and text input. We combine pretrained speech and text encoders using multi-headed cross-modal attention and jointly fine-tune on the target problem. The resultant architecture can be used for continuous token-level classification or utterance-level prediction acting on simultaneous text and speech. The resultant encoder efficiently captures both acoustic-prosodic and lexical information. We compare the benefits of multi-headed attention-based fusion for multi-modal utterance-level classification against a simple concatenation of pre-pooled, modality-specific representations. Our model architecture is compact, resource efficient, and can be trained on a single consumer GPU card.
Seq-2-Seq based Refinement of ASR Output for Spoken Name Capture
Mar 29, 2022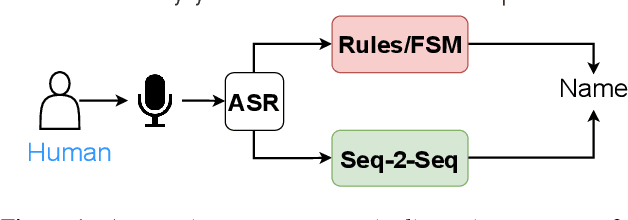
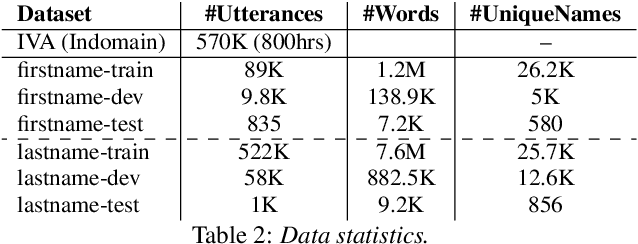
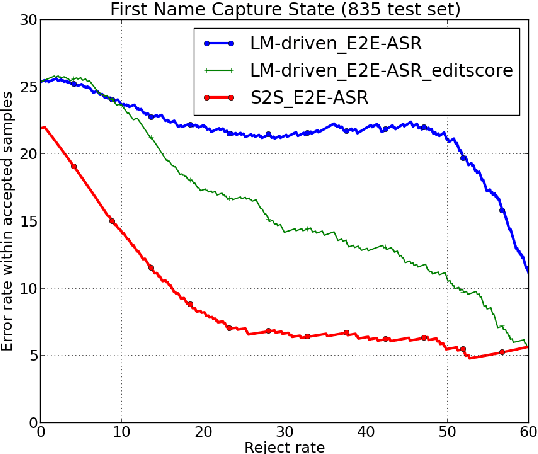
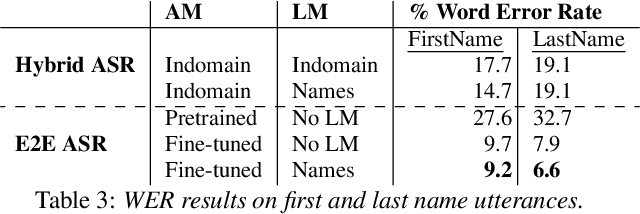
Person name capture from human speech is a difficult task in human-machine conversations. In this paper, we propose a novel approach to capture the person names from the caller utterances in response to the prompt "say and spell your first/last name". Inspired from work on spell correction, disfluency removal and text normalization, we propose a lightweight Seq-2-Seq system which generates a name spell from a varying user input. Our proposed method outperforms the strong baseline which is based on LM-driven rule-based approach.