 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
"Explanation" is Not a Technical Term: The Problem of Ambiguity in XAI
Jun 27, 2022
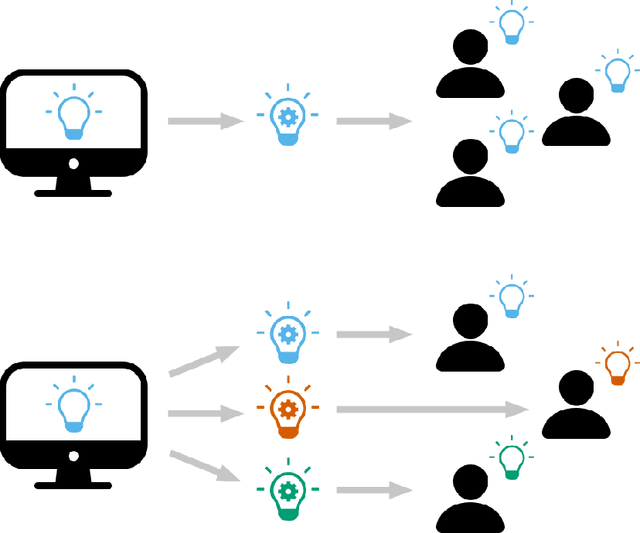
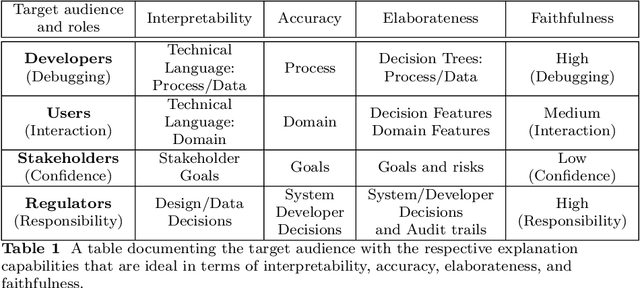
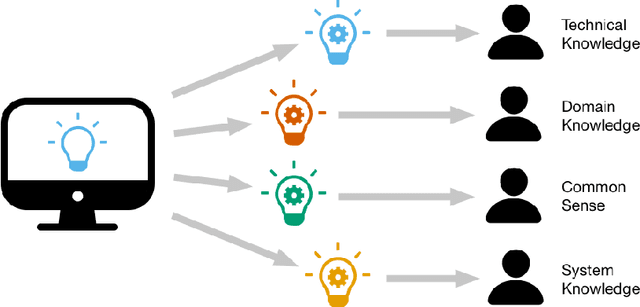

There is broad agreement that Artificial Intelligence (AI) systems, particularly those using Machine Learning (ML), should be able to "explain" their behavior. Unfortunately, there is little agreement as to what constitutes an "explanation." This has caused a disconnect between the explanations that systems produce in service of explainable Artificial Intelligence (XAI) and those explanations that users and other audiences actually need, which should be defined by the full spectrum of functional roles, audiences, and capabilities for explanation. In this paper, we explore the features of explanations and how to use those features in evaluating their utility. We focus on the requirements for explanations defined by their functional role, the knowledge states of users who are trying to understand them, and the availability of the information needed to generate them. Further, we discuss the risk of XAI enabling trust in systems without establishing their trustworthiness and define a critical next step for the field of XAI to establish metrics to guide and ground the utility of system-generated explanations.
CrossCBR: Cross-view Contrastive Learning for Bundle Recommendation
Jun 01, 2022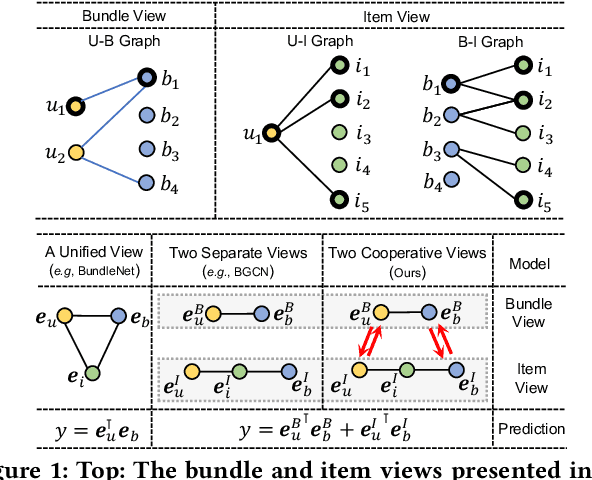
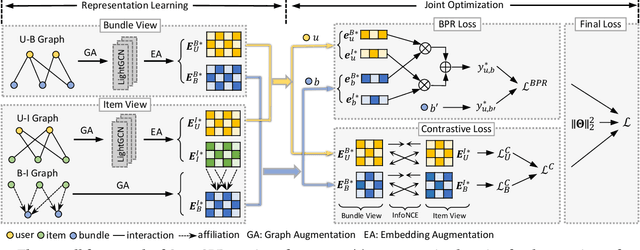
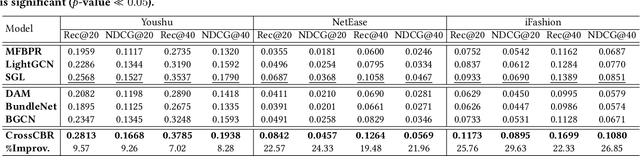
Bundle recommendation aims to recommend a bundle of related items to users, which can satisfy the users' various needs with one-stop convenience. Recent methods usually take advantage of both user-bundle and user-item interactions information to obtain informative representations for users and bundles, corresponding to bundle view and item view, respectively. However, they either use a unified view without differentiation or loosely combine the predictions of two separate views, while the crucial cooperative association between the two views' representations is overlooked. In this work, we propose to model the cooperative association between the two different views through cross-view contrastive learning. By encouraging the alignment of the two separately learned views, each view can distill complementary information from the other view, achieving mutual enhancement. Moreover, by enlarging the dispersion of different users/bundles, the self-discrimination of representations is enhanced. Extensive experiments on three public datasets demonstrate that our method outperforms SOTA baselines by a large margin. Meanwhile, our method requires minimal parameters of three set of embeddings (user, bundle, and item) and the computational costs are largely reduced due to more concise graph structure and graph learning module. In addition, various ablation and model studies demystify the working mechanism and justify our hypothesis. Codes and datasets are available at https://github.com/mysbupt/CrossCBR.
* 9 pages, 5 figures, 5 tables
Classification at the Accuracy Limit -- Facing the Problem of Data Ambiguity
Jun 04, 2022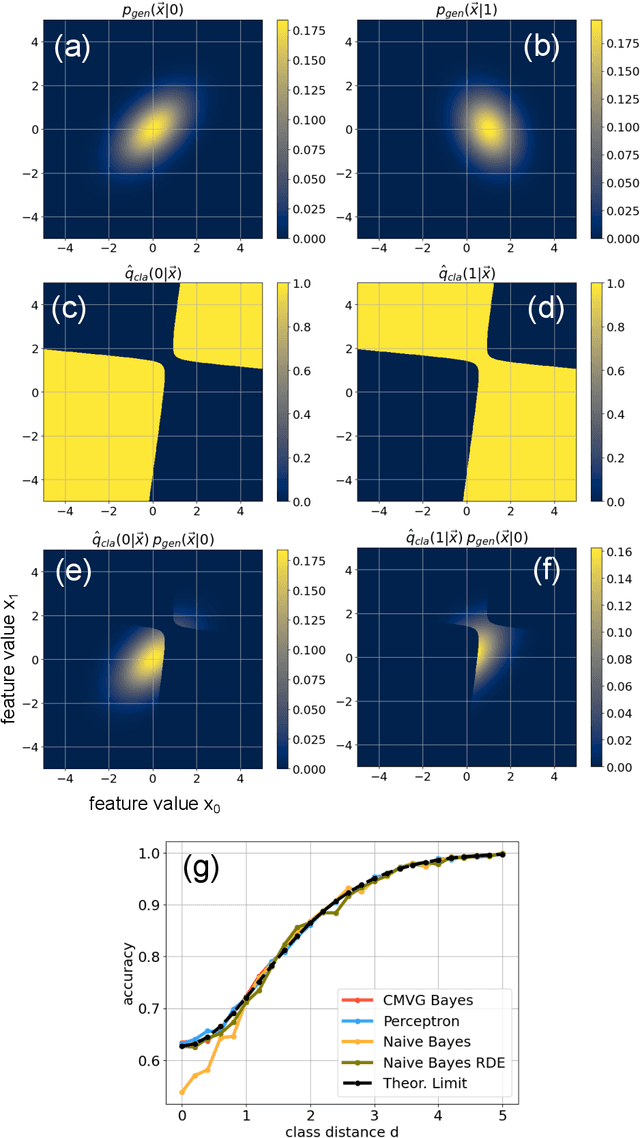
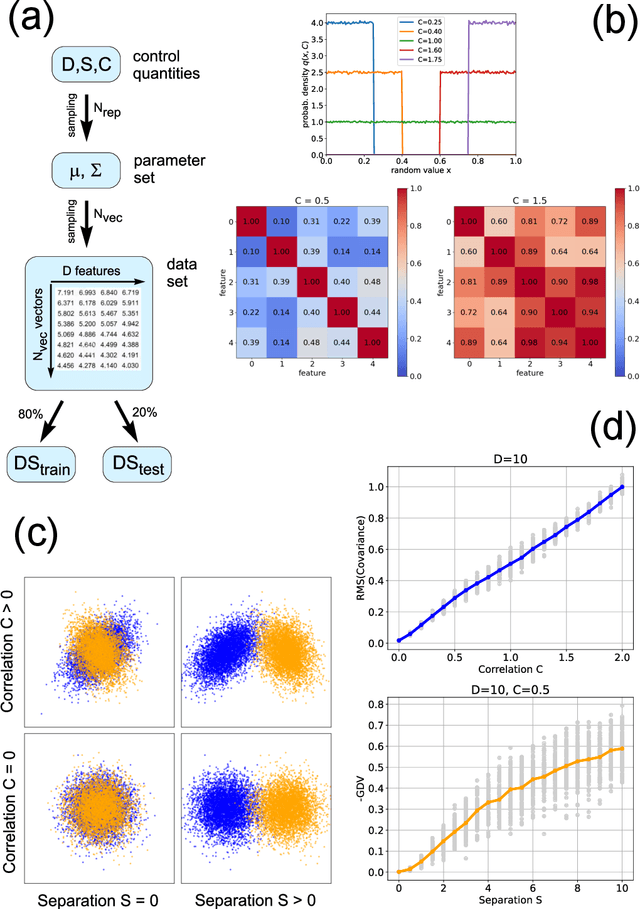
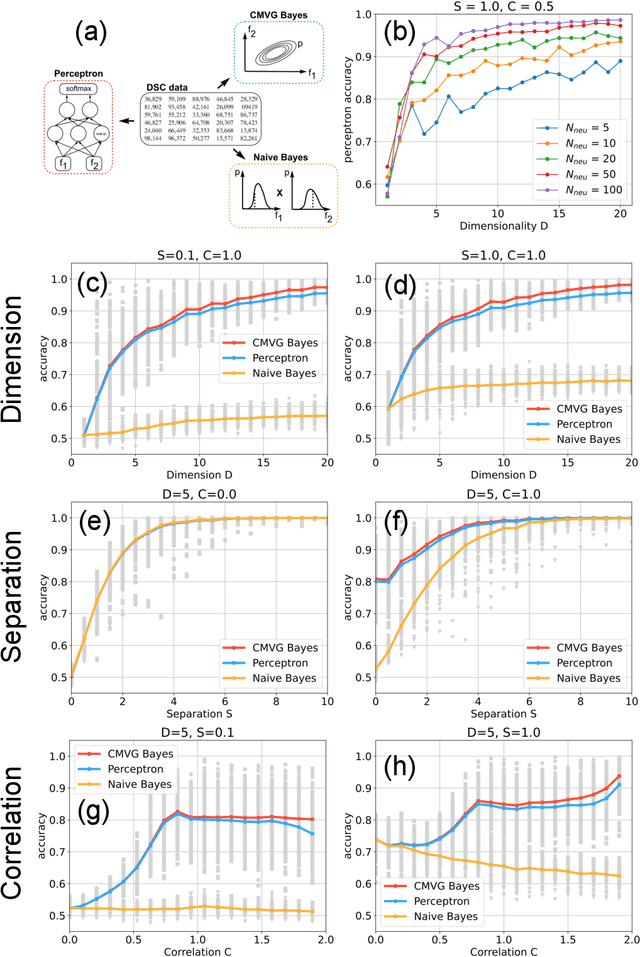
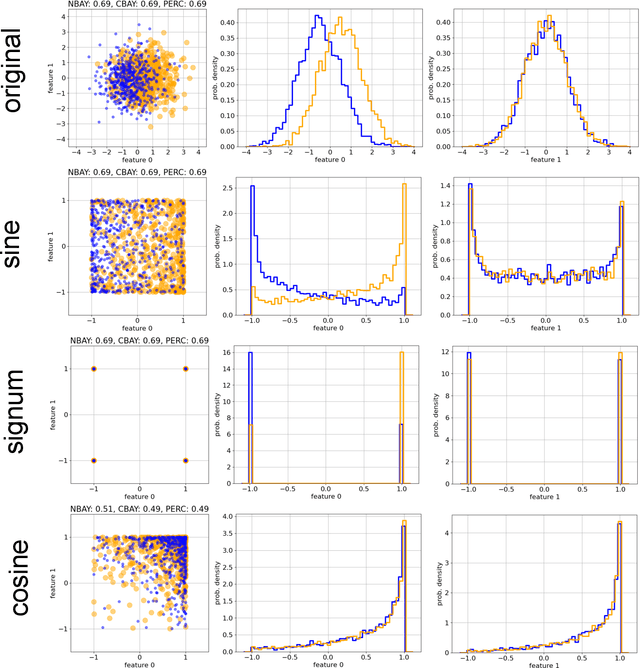
Data classification, the process of analyzing data and organizing it into categories, is a fundamental computing problem of natural and artificial information processing systems. Ideally, the performance of classifier models would be evaluated using unambiguous data sets, where the 'correct' assignment of category labels to the input data vectors is unequivocal. In real-world problems, however, a significant fraction of actually occurring data vectors will be located in a boundary zone between or outside of all categories, so that perfect classification cannot even in principle be achieved. We derive the theoretical limit for classification accuracy that arises from the overlap of data categories. By using a surrogate data generation model with adjustable statistical properties, we show that sufficiently powerful classifiers based on completely different principles, such as perceptrons and Bayesian models, all perform at this universal accuracy limit. Remarkably, the accuracy limit is not affected by applying non-linear transformations to the data, even if these transformations are non-reversible and drastically reduce the information content of the input data. We compare emerging data embeddings produced by supervised and unsupervised training, using MNIST and human EEG recordings during sleep. We find that categories are not only well separated in the final layers of classifiers trained with back-propagation, but to a smaller degree also after unsupervised dimensionality reduction. This suggests that human-defined categories, such as hand-written digits or sleep stages, can indeed be considered as 'natural kinds'.
Wrapping Haptic Displays Around Robot Arms to Communicate Learning
Jul 07, 2022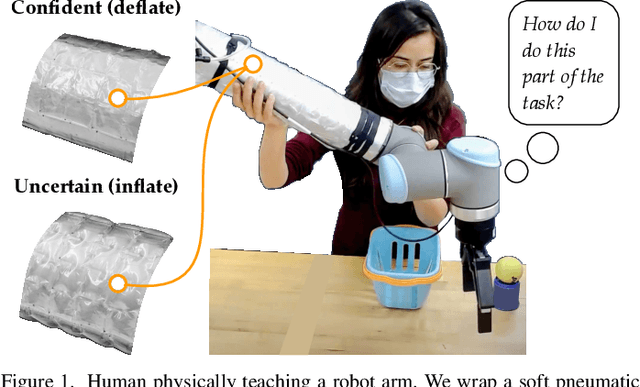
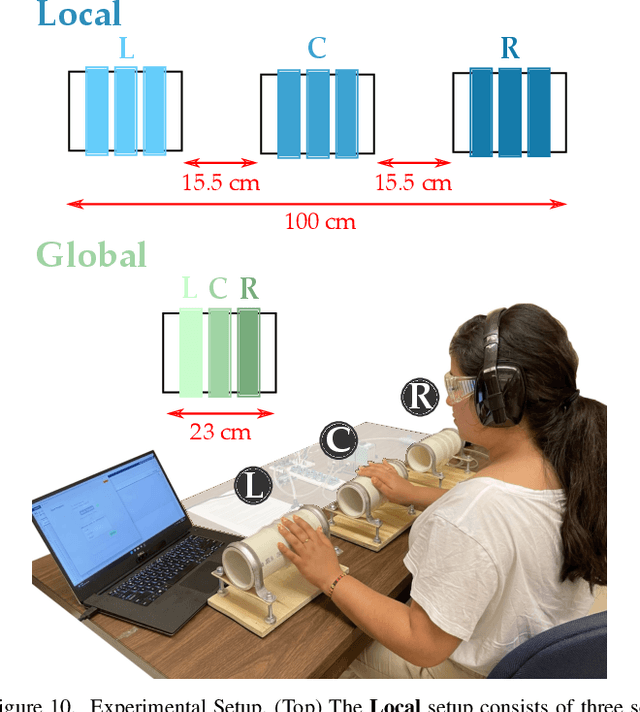
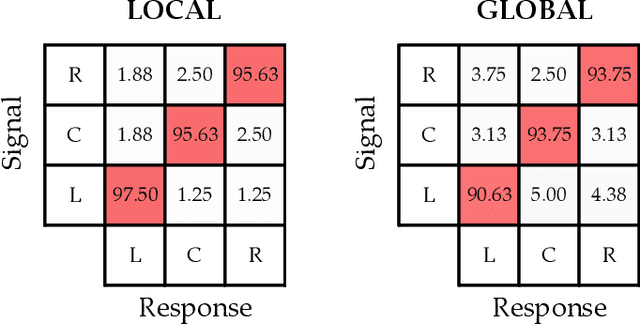
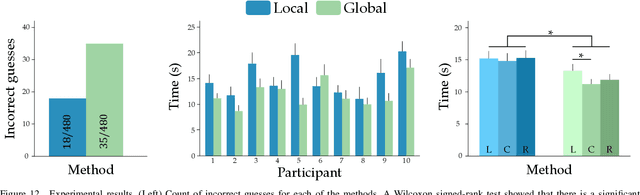
Humans can leverage physical interaction to teach robot arms. As the human kinesthetically guides the robot through demonstrations, the robot learns the desired task. While prior works focus on how the robot learns, it is equally important for the human teacher to understand what their robot is learning. Visual displays can communicate this information; however, we hypothesize that visual feedback alone misses out on the physical connection between the human and robot. In this paper we introduce a novel class of soft haptic displays that wrap around the robot arm, adding signals without affecting interaction. We first design a pneumatic actuation array that remains flexible in mounting. We then develop single and multi-dimensional versions of this wrapped haptic display, and explore human perception of the rendered signals during psychophysic tests and robot learning. We ultimately find that people accurately distinguish single-dimensional feedback with a Weber fraction of 11.4%, and identify multi-dimensional feedback with 94.5% accuracy. When physically teaching robot arms, humans leverage the single- and multi-dimensional feedback to provide better demonstrations than with visual feedback: our wrapped haptic display decreases teaching time while increasing demonstration quality. This improvement depends on the location and distribution of the wrapped haptic display. You can see videos of our device and experiments here: https://youtu.be/yPcMGeqsjdM
Pile of Law: Learning Responsible Data Filtering from the Law and a 256GB Open-Source Legal Dataset
Jul 01, 2022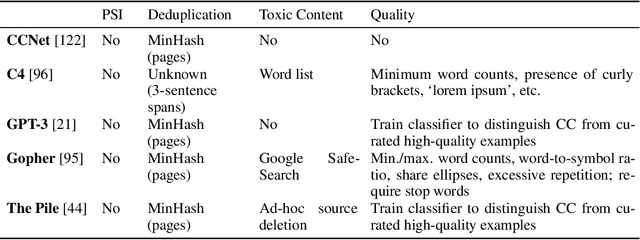
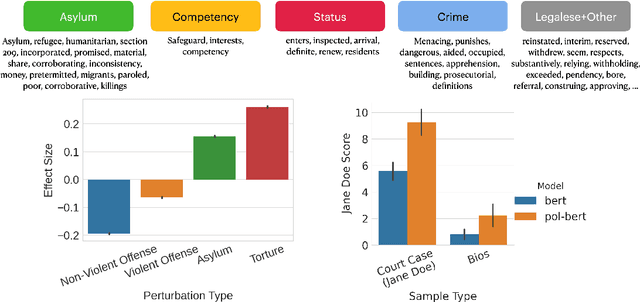
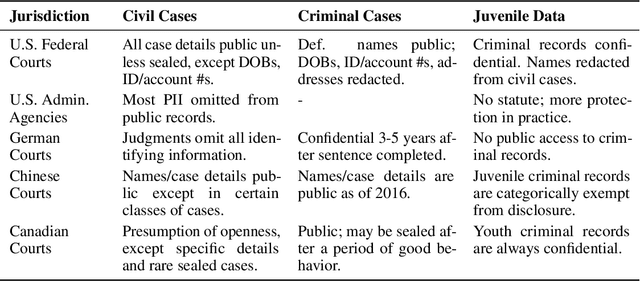
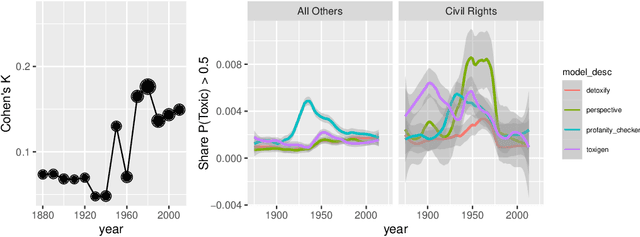
One concern with the rise of large language models lies with their potential for significant harm, particularly from pretraining on biased, obscene, copyrighted, and private information. Emerging ethical approaches have attempted to filter pretraining material, but such approaches have been ad hoc and failed to take into account context. We offer an approach to filtering grounded in law, which has directly addressed the tradeoffs in filtering material. First, we gather and make available the Pile of Law, a 256GB (and growing) dataset of open-source English-language legal and administrative data, covering court opinions, contracts, administrative rules, and legislative records. Pretraining on the Pile of Law may potentially help with legal tasks that have the promise to improve access to justice. Second, we distill the legal norms that governments have developed to constrain the inclusion of toxic or private content into actionable lessons for researchers and discuss how our dataset reflects these norms. Third, we show how the Pile of Law offers researchers the opportunity to learn such filtering rules directly from the data, providing an exciting new research direction in model-based processing.
Using cognitive psychology to understand GPT-3
Jun 21, 2022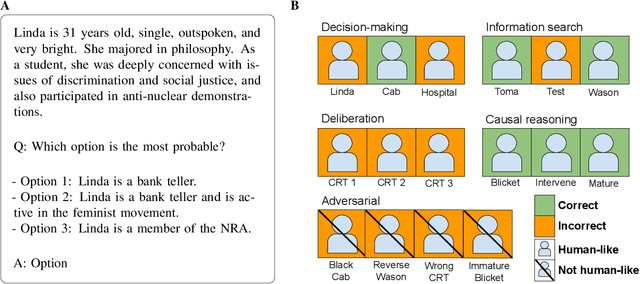
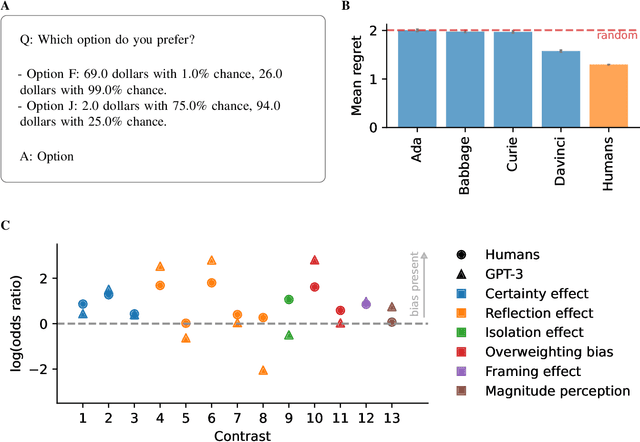

We study GPT-3, a recent large language model, using tools from cognitive psychology. More specifically, we assess GPT-3's decision-making, information search, deliberation, and causal reasoning abilities on a battery of canonical experiments from the literature. We find that much of GPT-3's behavior is impressive: it solves vignette-based tasks similarly or better than human subjects, is able to make decent decisions from descriptions, outperforms humans in a multi-armed bandit task, and shows signatures of model-based reinforcement learning. Yet we also find that small perturbations to vignette-based tasks can lead GPT-3 vastly astray, that it shows no signatures of directed exploration, and that it fails miserably in a causal reasoning task. These results enrich our understanding of current large language models and pave the way for future investigations using tools from cognitive psychology to study increasingly capable and opaque artificial agents.
CopyCat2: A Single Model for Multi-Speaker TTS and Many-to-Many Fine-Grained Prosody Transfer
Jun 27, 2022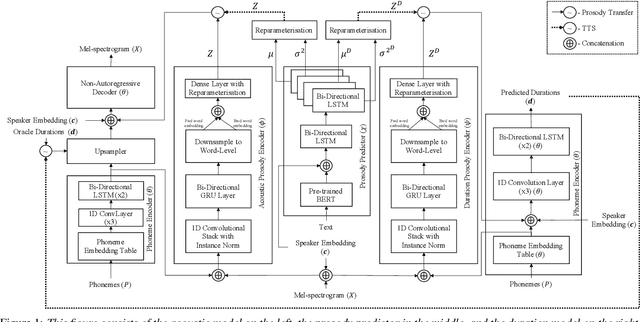
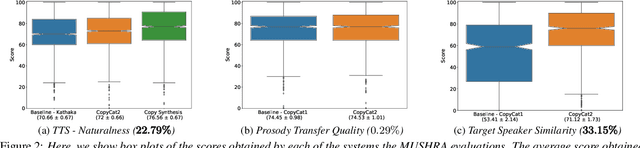
In this paper, we present CopyCat2 (CC2), a novel model capable of: a) synthesizing speech with different speaker identities, b) generating speech with expressive and contextually appropriate prosody, and c) transferring prosody at fine-grained level between any pair of seen speakers. We do this by activating distinct parts of the network for different tasks. We train our model using a novel approach to two-stage training. In Stage I, the model learns speaker-independent word-level prosody representations from speech which it uses for many-to-many fine-grained prosody transfer. In Stage II, we learn to predict these prosody representations using the contextual information available in text, thereby, enabling multi-speaker TTS with contextually appropriate prosody. We compare CC2 to two strong baselines, one in TTS with contextually appropriate prosody, and one in fine-grained prosody transfer. CC2 reduces the gap in naturalness between our baseline and copy-synthesised speech by $22.79\%$. In fine-grained prosody transfer evaluations, it obtains a relative improvement of $33.15\%$ in target speaker similarity.
Leveraging Log Instructions in Log-based Anomaly Detection
Jul 07, 2022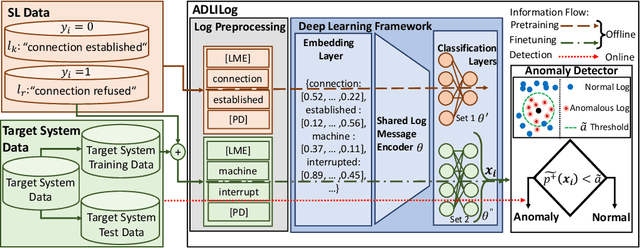
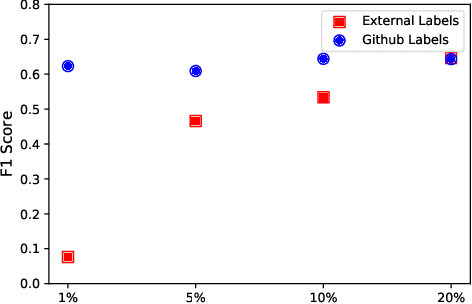
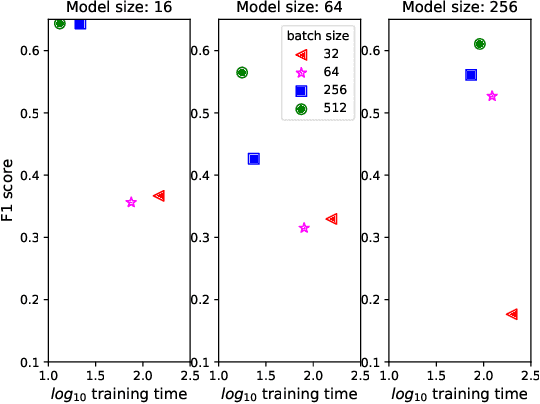

Artificial Intelligence for IT Operations (AIOps) describes the process of maintaining and operating large IT systems using diverse AI-enabled methods and tools for, e.g., anomaly detection and root cause analysis, to support the remediation, optimization, and automatic initiation of self-stabilizing IT activities. The core step of any AIOps workflow is anomaly detection, typically performed on high-volume heterogeneous data such as log messages (logs), metrics (e.g., CPU utilization), and distributed traces. In this paper, we propose a method for reliable and practical anomaly detection from system logs. It overcomes the common disadvantage of related works, i.e., the need for a large amount of manually labeled training data, by building an anomaly detection model with log instructions from the source code of 1000+ GitHub projects. The instructions from diverse systems contain rich and heterogenous information about many different normal and abnormal IT events and serve as a foundation for anomaly detection. The proposed method, named ADLILog, combines the log instructions and the data from the system of interest (target system) to learn a deep neural network model through a two-phase learning procedure. The experimental results show that ADLILog outperforms the related approaches by up to 60% on the F1 score while satisfying core non-functional requirements for industrial deployments such as unsupervised design, efficient model updates, and small model sizes.
Aspect-Based Sentiment Analysis using Local Context Focus Mechanism with DeBERTa
Jul 07, 2022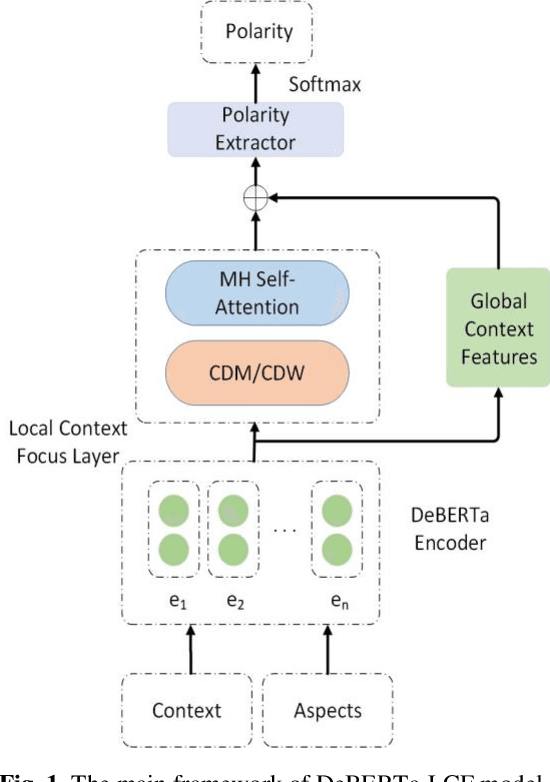

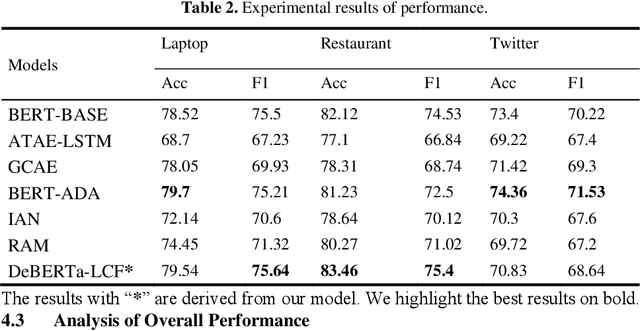
Text sentiment analysis, also known as opinion mining, is research on the calculation of people's views, evaluations, attitude and emotions expressed by entities. Text sentiment analysis can be divided into text-level sentiment analysis, sen-tence-level sentiment analysis and aspect-level sentiment analysis. Aspect-Based Sentiment Analysis (ABSA) is a fine-grained task in the field of sentiment analysis, which aims to predict the polarity of aspects. The research of pre-training neural model has significantly improved the performance of many natural language processing tasks. In recent years, pre training model (PTM) has been applied in ABSA. Therefore, there has been a question, which is whether PTMs contain sufficient syntactic information for ABSA. In this paper, we explored the recent DeBERTa model (Decoding-enhanced BERT with disentangled attention) to solve Aspect-Based Sentiment Analysis problem. DeBERTa is a kind of neural language model based on transformer, which uses self-supervised learning to pre-train on a large number of original text corpora. Based on the Local Context Focus (LCF) mechanism, by integrating DeBERTa model, we purpose a multi-task learning model for aspect-based sentiment analysis. The experiments result on the most commonly used the laptop and restaurant datasets of SemEval-2014 and the ACL twitter dataset show that LCF mechanism with DeBERTa has significant improvement.
Information Prediction using Knowledge Graphs for Contextual Malware Threat Intelligence
Feb 18, 2021
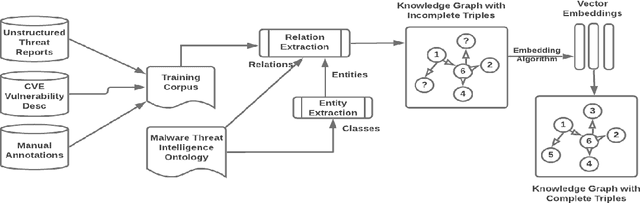
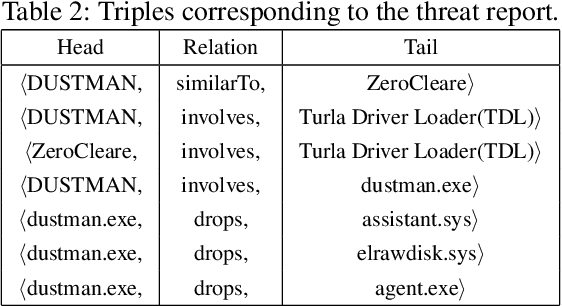

Large amounts of threat intelligence information about mal-ware attacks are available in disparate, typically unstructured, formats. Knowledge graphs can capture this information and its context using RDF triples represented by entities and relations. Sparse or inaccurate threat information, however, leads to challenges such as incomplete or erroneous triples. Named entity recognition (NER) and relation extraction (RE) models used to populate the knowledge graph cannot fully guaran-tee accurate information retrieval, further exacerbating this problem. This paper proposes an end-to-end approach to generate a Malware Knowledge Graph called MalKG, the first open-source automated knowledge graph for malware threat intelligence. MalKG dataset called MT40K1 contains approximately 40,000 triples generated from 27,354 unique entities and 34 relations. We demonstrate the application of MalKGin predicting missing malware threat intelligence information in the knowledge graph. For ground truth, we manually curate a knowledge graph called MT3K, with 3,027 triples generated from 5,741 unique entities and 22 relations. For entity prediction via a state-of-the-art entity prediction model(TuckER), our approach achieves 80.4 for the hits@10 metric (predicts the top 10 options for missing entities in the knowledge graph), and 0.75 for the MRR (mean reciprocal rank). We also propose a framework to automate the extraction of thousands of entities and relations into RDF triples, both manually and automatically, at the sentence level from1,100 malware threat intelligence reports and from the com-mon vulnerabilities and exposures (CVE) database.