 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBASE TTS: Lessons from building a billion-parameter Text-to-Speech model on 100K hours of data
Feb 15, 2024



We introduce a text-to-speech (TTS) model called BASE TTS, which stands for $\textbf{B}$ig $\textbf{A}$daptive $\textbf{S}$treamable TTS with $\textbf{E}$mergent abilities. BASE TTS is the largest TTS model to-date, trained on 100K hours of public domain speech data, achieving a new state-of-the-art in speech naturalness. It deploys a 1-billion-parameter autoregressive Transformer that converts raw texts into discrete codes ("speechcodes") followed by a convolution-based decoder which converts these speechcodes into waveforms in an incremental, streamable manner. Further, our speechcodes are built using a novel speech tokenization technique that features speaker ID disentanglement and compression with byte-pair encoding. Echoing the widely-reported "emergent abilities" of large language models when trained on increasing volume of data, we show that BASE TTS variants built with 10K+ hours and 500M+ parameters begin to demonstrate natural prosody on textually complex sentences. We design and share a specialized dataset to measure these emergent abilities for text-to-speech. We showcase state-of-the-art naturalness of BASE TTS by evaluating against baselines that include publicly available large-scale text-to-speech systems: YourTTS, Bark and TortoiseTTS. Audio samples generated by the model can be heard at https://amazon-ltts-paper.com/.
Energy-conserving equivariant GNN for elasticity of lattice architected metamaterials
Jan 30, 2024



Lattices are architected metamaterials whose properties strongly depend on their geometrical design. The analogy between lattices and graphs enables the use of graph neural networks (GNNs) as a faster surrogate model compared to traditional methods such as finite element modelling. In this work we present a higher-order GNN model trained to predict the fourth-order stiffness tensor of periodic strut-based lattices. The key features of the model are (i) SE(3) equivariance, and (ii) consistency with the thermodynamic law of conservation of energy. We compare the model to non-equivariant models based on a number of error metrics and demonstrate the benefits of the encoded equivariance and energy conservation in terms of predictive performance and reduced training requirements.
A Comparative Analysis of Pretrained Language Models for Text-to-Speech
Sep 04, 2023State-of-the-art text-to-speech (TTS) systems have utilized pretrained language models (PLMs) to enhance prosody and create more natural-sounding speech. However, while PLMs have been extensively researched for natural language understanding (NLU), their impact on TTS has been overlooked. In this study, we aim to address this gap by conducting a comparative analysis of different PLMs for two TTS tasks: prosody prediction and pause prediction. Firstly, we trained a prosody prediction model using 15 different PLMs. Our findings revealed a logarithmic relationship between model size and quality, as well as significant performance differences between neutral and expressive prosody. Secondly, we employed PLMs for pause prediction and found that the task was less sensitive to small models. We also identified a strong correlation between our empirical results and the GLUE scores obtained for these language models. To the best of our knowledge, this is the first study of its kind to investigate the impact of different PLMs on TTS.
eCat: An End-to-End Model for Multi-Speaker TTS & Many-to-Many Fine-Grained Prosody Transfer
Jun 20, 2023We present eCat, a novel end-to-end multispeaker model capable of: a) generating long-context speech with expressive and contextually appropriate prosody, and b) performing fine-grained prosody transfer between any pair of seen speakers. eCat is trained using a two-stage training approach. In Stage I, the model learns speaker-independent word-level prosody representations in an end-to-end fashion from speech. In Stage II, we learn to predict the prosody representations using the contextual information available in text. We compare eCat to CopyCat2, a model capable of both fine-grained prosody transfer (FPT) and multi-speaker TTS. We show that eCat statistically significantly reduces the gap in naturalness between CopyCat2 and human recordings by an average of 46.7% across 2 languages, 3 locales, and 7 speakers, along with better target-speaker similarity in FPT. We also compare eCat to VITS, and show a statistically significant preference.
Simple and Effective Multi-sentence TTS with Expressive and Coherent Prosody
Jun 29, 2022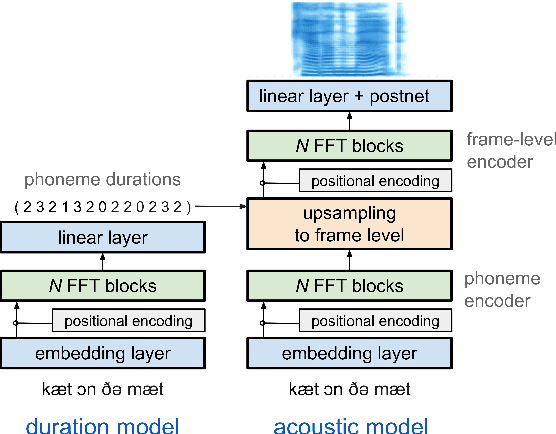

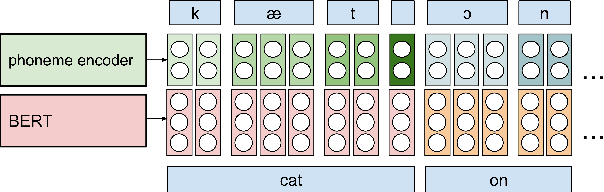
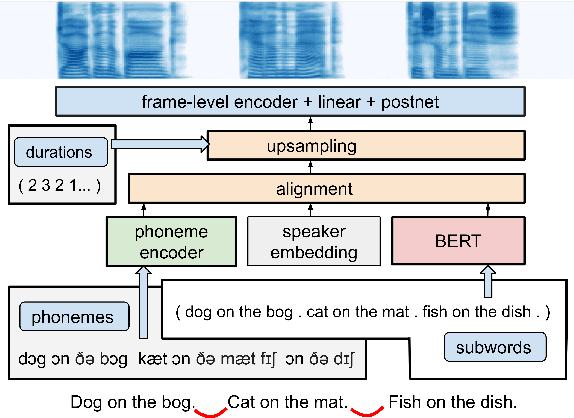
Generating expressive and contextually appropriate prosody remains a challenge for modern text-to-speech (TTS) systems. This is particularly evident for long, multi-sentence inputs. In this paper, we examine simple extensions to a Transformer-based FastSpeech-like system, with the goal of improving prosody for multi-sentence TTS. We find that long context, powerful text features, and training on multi-speaker data all improve prosody. More interestingly, they result in synergies. Long context disambiguates prosody, improves coherence, and plays to the strengths of Transformers. Fine-tuning word-level features from a powerful language model, such as BERT, appears to profit from more training data, readily available in a multi-speaker setting. We look into objective metrics on pausing and pacing and perform thorough subjective evaluations for speech naturalness. Our main system, which incorporates all the extensions, achieves consistently strong results, including statistically significant improvements in speech naturalness over all its competitors.
Expressive, Variable, and Controllable Duration Modelling in TTS
Jun 28, 2022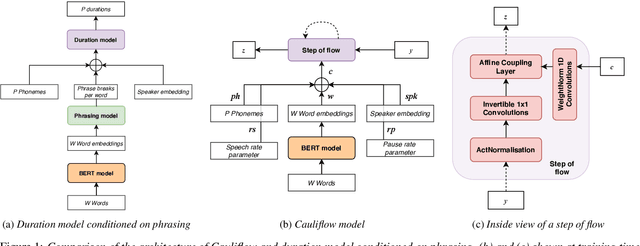
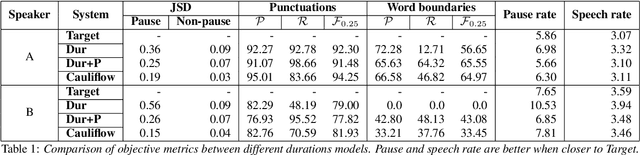
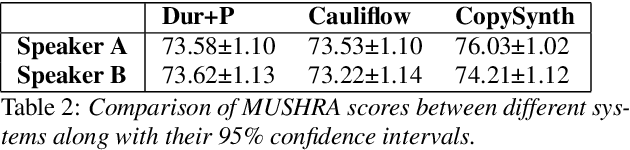
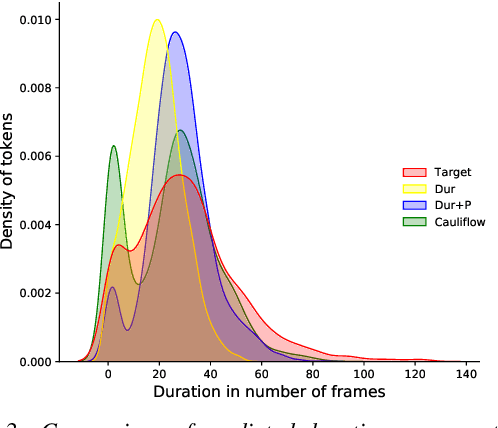
Duration modelling has become an important research problem once more with the rise of non-attention neural text-to-speech systems. The current approaches largely fall back to relying on previous statistical parametric speech synthesis technology for duration prediction, which poorly models the expressiveness and variability in speech. In this paper, we propose two alternate approaches to improve duration modelling. First, we propose a duration model conditioned on phrasing that improves the predicted durations and provides better modelling of pauses. We show that the duration model conditioned on phrasing improves the naturalness of speech over our baseline duration model. Second, we also propose a multi-speaker duration model called Cauliflow, that uses normalising flows to predict durations that better match the complex target duration distribution. Cauliflow performs on par with our other proposed duration model in terms of naturalness, whilst providing variable durations for the same prompt and variable levels of expressiveness. Lastly, we propose to condition Cauliflow on parameters that provide an intuitive control of the pacing and pausing in the synthesised speech in a novel way.
CopyCat2: A Single Model for Multi-Speaker TTS and Many-to-Many Fine-Grained Prosody Transfer
Jun 27, 2022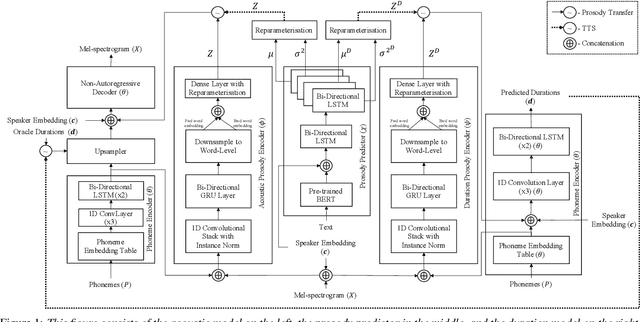
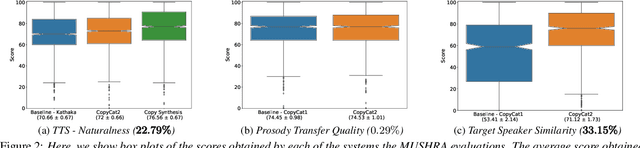
In this paper, we present CopyCat2 (CC2), a novel model capable of: a) synthesizing speech with different speaker identities, b) generating speech with expressive and contextually appropriate prosody, and c) transferring prosody at fine-grained level between any pair of seen speakers. We do this by activating distinct parts of the network for different tasks. We train our model using a novel approach to two-stage training. In Stage I, the model learns speaker-independent word-level prosody representations from speech which it uses for many-to-many fine-grained prosody transfer. In Stage II, we learn to predict these prosody representations using the contextual information available in text, thereby, enabling multi-speaker TTS with contextually appropriate prosody. We compare CC2 to two strong baselines, one in TTS with contextually appropriate prosody, and one in fine-grained prosody transfer. CC2 reduces the gap in naturalness between our baseline and copy-synthesised speech by $22.79\%$. In fine-grained prosody transfer evaluations, it obtains a relative improvement of $33.15\%$ in target speaker similarity.
Multi-Scale Spectrogram Modelling for Neural Text-to-Speech
Jun 29, 2021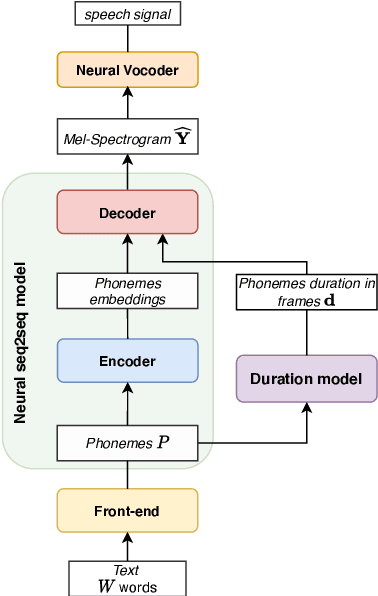
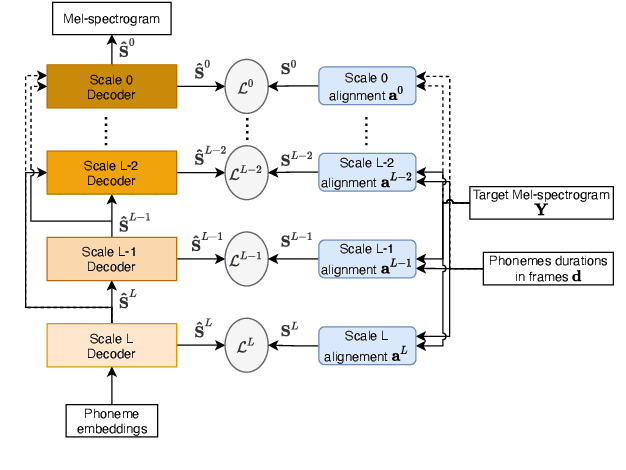
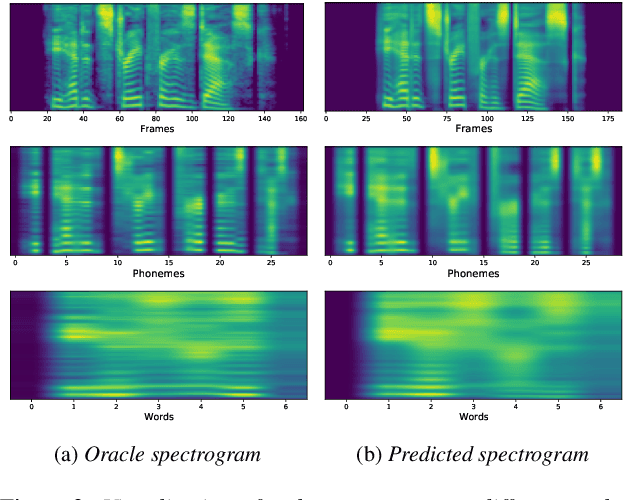
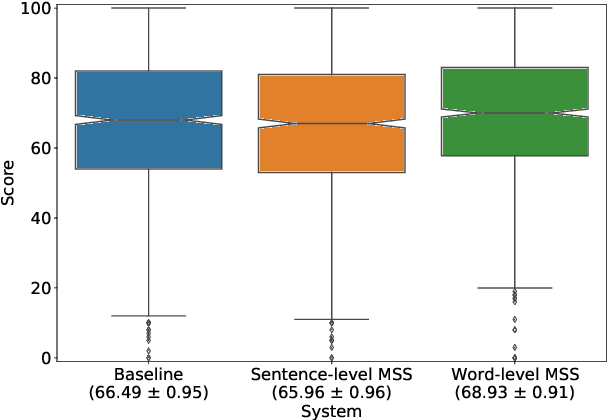
We propose a novel Multi-Scale Spectrogram (MSS) modelling approach to synthesise speech with an improved coarse and fine-grained prosody. We present a generic multi-scale spectrogram prediction mechanism where the system first predicts coarser scale mel-spectrograms that capture the suprasegmental information in speech, and later uses these coarser scale mel-spectrograms to predict finer scale mel-spectrograms capturing fine-grained prosody. We present details for two specific versions of MSS called Word-level MSS and Sentence-level MSS where the scales in our system are motivated by the linguistic units. The Word-level MSS models word, phoneme, and frame-level spectrograms while Sentence-level MSS models sentence-level spectrogram in addition. Subjective evaluations show that Word-level MSS performs statistically significantly better compared to the baseline on two voices.
A learned conditional prior for the VAE acoustic space of a TTS system
Jun 14, 2021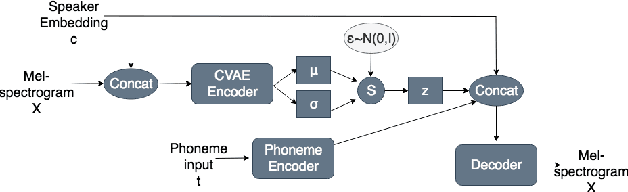
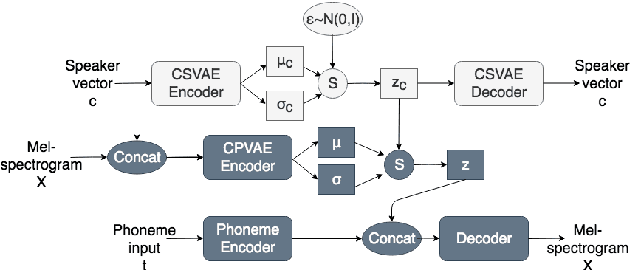
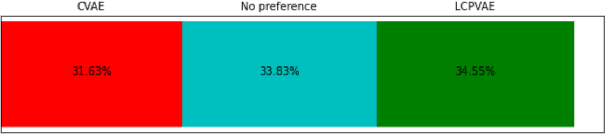
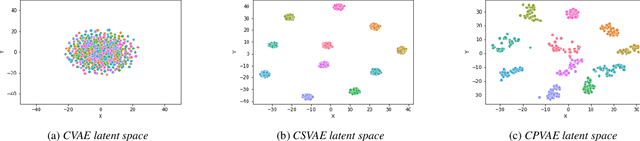
Many factors influence speech yielding different renditions of a given sentence. Generative models, such as variational autoencoders (VAEs), capture this variability and allow multiple renditions of the same sentence via sampling. The degree of prosodic variability depends heavily on the prior that is used when sampling. In this paper, we propose a novel method to compute an informative prior for the VAE latent space of a neural text-to-speech (TTS) system. By doing so, we aim to sample with more prosodic variability, while gaining controllability over the latent space's structure. By using as prior the posterior distribution of a secondary VAE, which we condition on a speaker vector, we can sample from the primary VAE taking explicitly the conditioning into account and resulting in samples from a specific region of the latent space for each condition (i.e. speaker). A formal preference test demonstrates significant preference of the proposed approach over standard Conditional VAE. We also provide visualisations of the latent space where well-separated condition-specific clusters appear, as well as ablation studies to better understand the behaviour of the system.
Prosodic Representation Learning and Contextual Sampling for Neural Text-to-Speech
Nov 04, 2020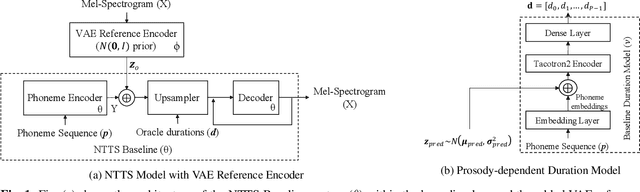
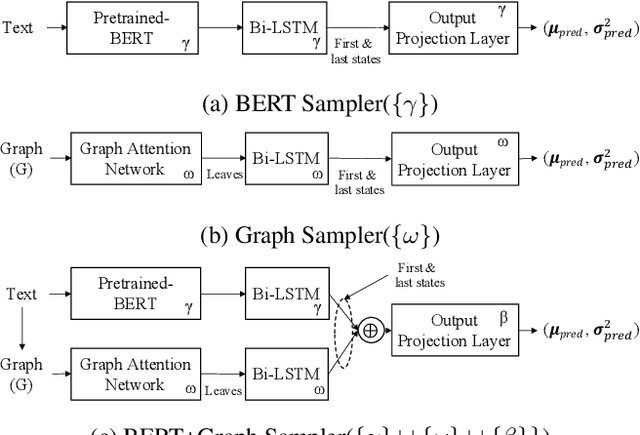
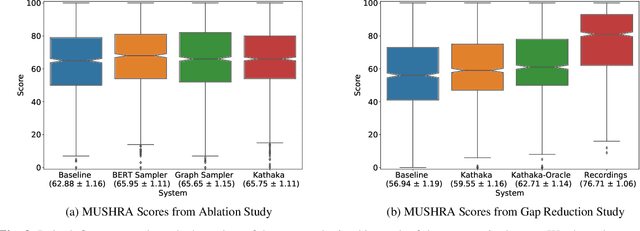
In this paper, we introduce Kathaka, a model trained with a novel two-stage training process for neural speech synthesis with contextually appropriate prosody. In Stage I, we learn a prosodic distribution at the sentence level from mel-spectrograms available during training. In Stage II, we propose a novel method to sample from this learnt prosodic distribution using the contextual information available in text. To do this, we use BERT on text, and graph-attention networks on parse trees extracted from text. We show a statistically significant relative improvement of $13.2\%$ in naturalness over a strong baseline when compared to recordings. We also conduct an ablation study on variations of our sampling technique, and show a statistically significant improvement over the baseline in each case.