 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Fails: Unveiling Evasion Attacks in Weather Prediction Models
Dec 09, 2025With the increasing reliance on AI models for weather forecasting, it is imperative to evaluate their vulnerability to adversarial perturbations. This work introduces Weather Adaptive Adversarial Perturbation Optimization (WAAPO), a novel framework for generating targeted adversarial perturbations that are both effective in manipulating forecasts and stealthy to avoid detection. WAAPO achieves this by incorporating constraints for channel sparsity, spatial localization, and smoothness, ensuring that perturbations remain physically realistic and imperceptible. Using the ERA5 dataset and FourCastNet (Pathak et al. 2022), we demonstrate WAAPO's ability to generate adversarial trajectories that align closely with predefined targets, even under constrained conditions. Our experiments highlight critical vulnerabilities in AI-driven forecasting models, where small perturbations to initial conditions can result in significant deviations in predicted weather patterns. These findings underscore the need for robust safeguards to protect against adversarial exploitation in operational forecasting systems.
Patching LLM Like Software: A Lightweight Method for Improving Safety Policy in Large Language Models
Nov 11, 2025



We propose patching for large language models (LLMs) like software versions, a lightweight and modular approach for addressing safety vulnerabilities. While vendors release improved LLM versions, major releases are costly, infrequent, and difficult to tailor to customer needs, leaving released models with known safety gaps. Unlike full-model fine-tuning or major version updates, our method enables rapid remediation by prepending a compact, learnable prefix to an existing model. This "patch" introduces only 0.003% additional parameters, yet reliably steers model behavior toward that of a safer reference model. Across three critical domains (toxicity mitigation, bias reduction, and harmfulness refusal) policy patches achieve safety improvements comparable to next-generation safety-aligned models while preserving fluency. Our results demonstrate that LLMs can be "patched" much like software, offering vendors and practitioners a practical mechanism for distributing scalable, efficient, and composable safety updates between major model releases.
PEEL the Layers and Find Yourself: Revisiting Inference-time Data Leakage for Residual Neural Networks
Apr 08, 2025


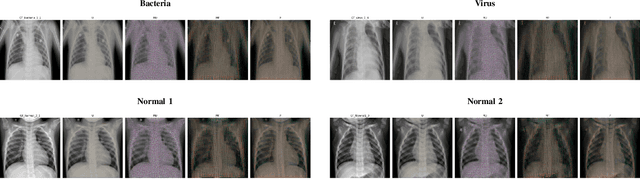
This paper explores inference-time data leakage risks of deep neural networks (NNs), where a curious and honest model service provider is interested in retrieving users' private data inputs solely based on the model inference results. Particularly, we revisit residual NNs due to their popularity in computer vision and our hypothesis that residual blocks are a primary cause of data leakage owing to the use of skip connections. By formulating inference-time data leakage as a constrained optimization problem, we propose a novel backward feature inversion method, \textbf{PEEL}, which can effectively recover block-wise input features from the intermediate output of residual NNs. The surprising results in high-quality input data recovery can be explained by the intuition that the output from these residual blocks can be considered as a noisy version of the input and thus the output retains sufficient information for input recovery. We demonstrate the effectiveness of our layer-by-layer feature inversion method on facial image datasets and pre-trained classifiers. Our results show that PEEL outperforms the state-of-the-art recovery methods by an order of magnitude when evaluated by mean squared error (MSE). The code is available at \href{https://github.com/Huzaifa-Arif/PEEL}{https://github.com/Huzaifa-Arif/PEEL}
Replacing Paths with Connection-Biased Attention for Knowledge Graph Completion
Oct 01, 2024



Knowledge graph (KG) completion aims to identify additional facts that can be inferred from the existing facts in the KG. Recent developments in this field have explored this task in the inductive setting, where at test time one sees entities that were not present during training; the most performant models in the inductive setting have employed path encoding modules in addition to standard subgraph encoding modules. This work similarly focuses on KG completion in the inductive setting, without the explicit use of path encodings, which can be time-consuming and introduces several hyperparameters that require costly hyperparameter optimization. Our approach uses a Transformer-based subgraph encoding module only; we introduce connection-biased attention and entity role embeddings into the subgraph encoding module to eliminate the need for an expensive and time-consuming path encoding module. Evaluations on standard inductive KG completion benchmark datasets demonstrate that our Connection-Biased Link Prediction (CBLiP) model has superior performance to models that do not use path information. Compared to models that utilize path information, CBLiP shows competitive or superior performance while being faster. Additionally, to show that the effectiveness of connection-biased attention and entity role embeddings also holds in the transductive setting, we compare CBLiP's performance on the relation prediction task in the transductive setting.
Exploiting the Data Gap: Utilizing Non-ignorable Missingness to Manipulate Model Learning
Sep 06, 2024



Missing data is commonly encountered in practice, and when the missingness is non-ignorable, effective remediation depends on knowledge of the missingness mechanism. Learning the underlying missingness mechanism from the data is not possible in general, so adversaries can exploit this fact by maliciously engineering non-ignorable missingness mechanisms. Such Adversarial Missingness (AM) attacks have only recently been motivated and introduced, and then successfully tailored to mislead causal structure learning algorithms into hiding specific cause-and-effect relationships. However, existing AM attacks assume the modeler (victim) uses full-information maximum likelihood methods to handle the missing data, and are of limited applicability when the modeler uses different remediation strategies. In this work we focus on associational learning in the context of AM attacks. We consider (i) complete case analysis, (ii) mean imputation, and (iii) regression-based imputation as alternative strategies used by the modeler. Instead of combinatorially searching for missing entries, we propose a novel probabilistic approximation by deriving the asymptotic forms of these methods used for handling the missing entries. We then formulate the learning of the adversarial missingness mechanism as a bi-level optimization problem. Experiments on generalized linear models show that AM attacks can be used to change the p-values of features from significant to insignificant in real datasets, such as the California-housing dataset, while using relatively moderate amounts of missingness (<20%). Additionally, we assess the robustness of our attacks against defense strategies based on data valuation.
Iterative thresholding for non-linear learning in the strong $\varepsilon$-contamination model
Sep 05, 2024

We derive approximation bounds for learning single neuron models using thresholded gradient descent when both the labels and the covariates are possibly corrupted adversarially. We assume the data follows the model $y = \sigma(\mathbf{w}^{*} \cdot \mathbf{x}) + \xi,$ where $\sigma$ is a nonlinear activation function, the noise $\xi$ is Gaussian, and the covariate vector $\mathbf{x}$ is sampled from a sub-Gaussian distribution. We study sigmoidal, leaky-ReLU, and ReLU activation functions and derive a $O(\nu\sqrt{\epsilon\log(1/\epsilon)})$ approximation bound in $\ell_{2}$-norm, with sample complexity $O(d/\epsilon)$ and failure probability $e^{-\Omega(d)}$. We also study the linear regression problem, where $\sigma(\mathbf{x}) = \mathbf{x}$. We derive a $O(\nu\epsilon\log(1/\epsilon))$ approximation bound, improving upon the previous $O(\nu)$ approximation bounds for the gradient-descent based iterative thresholding algorithms of Bhatia et al. (NeurIPS 2015) and Shen and Sanghavi (ICML 2019). Our algorithm has a $O(\textrm{polylog}(N,d)\log(R/\epsilon))$ runtime complexity when $\|\mathbf{w}^{*}\|_2 \leq R$, improving upon the $O(\text{polylog}(N,d)/\epsilon^2)$ runtime complexity of Awasthi et al. (NeurIPS 2022).
Aligners: Decoupling LLMs and Alignment
Mar 11, 2024

Large Language Models (LLMs) need to be aligned with human expectations to ensure their safety and utility in most applications. Alignment is challenging, costly, and needs to be repeated for every LLM and alignment criterion. We propose to decouple LLMs and alignment by training aligner models that can be used to align any LLM for a given criteria on an as-needed basis, thus also reducing the potential negative impacts of alignment on performance. Our recipe for training the aligner models solely relies on synthetic data generated with a (prompted) LLM and can be easily adjusted for a variety of alignment criteria. We illustrate our method by training an "ethical" aligner and verify its efficacy empirically.
Improving Neural Ranking Models with Traditional IR Methods
Aug 29, 2023
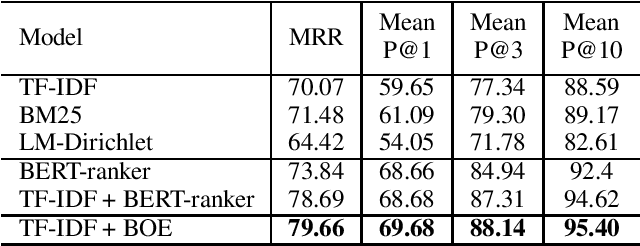


Neural ranking methods based on large transformer models have recently gained significant attention in the information retrieval community, and have been adopted by major commercial solutions. Nevertheless, they are computationally expensive to create, and require a great deal of labeled data for specialized corpora. In this paper, we explore a low resource alternative which is a bag-of-embedding model for document retrieval and find that it is competitive with large transformer models fine tuned on information retrieval tasks. Our results show that a simple combination of TF-IDF, a traditional keyword matching method, with a shallow embedding model provides a low cost path to compete well with the performance of complex neural ranking models on 3 datasets. Furthermore, adding TF-IDF measures improves the performance of large-scale fine tuned models on these tasks.
A Cross-Domain Evaluation of Approaches for Causal Knowledge Extraction
Aug 07, 2023



Causal knowledge extraction is the task of extracting relevant causes and effects from text by detecting the causal relation. Although this task is important for language understanding and knowledge discovery, recent works in this domain have largely focused on binary classification of a text segment as causal or non-causal. In this regard, we perform a thorough analysis of three sequence tagging models for causal knowledge extraction and compare it with a span based approach to causality extraction. Our experiments show that embeddings from pre-trained language models (e.g. BERT) provide a significant performance boost on this task compared to previous state-of-the-art models with complex architectures. We observe that span based models perform better than simple sequence tagging models based on BERT across all 4 data sets from diverse domains with different types of cause-effect phrases.
Deception by Omission: Using Adversarial Missingness to Poison Causal Structure Learning
May 31, 2023



Inference of causal structures from observational data is a key component of causal machine learning; in practice, this data may be incompletely observed. Prior work has demonstrated that adversarial perturbations of completely observed training data may be used to force the learning of inaccurate causal structural models (SCMs). However, when the data can be audited for correctness (e.g., it is crytographically signed by its source), this adversarial mechanism is invalidated. This work introduces a novel attack methodology wherein the adversary deceptively omits a portion of the true training data to bias the learned causal structures in a desired manner. Theoretically sound attack mechanisms are derived for the case of arbitrary SCMs, and a sample-efficient learning-based heuristic is given for Gaussian SCMs. Experimental validation of these approaches on real and synthetic data sets demonstrates the effectiveness of adversarial missingness attacks at deceiving popular causal structure learning algorithms.