 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CHARM: A Hierarchical Deep Learning Model for Classification of Complex Human Activities Using Motion Sensors
Jul 16, 2022
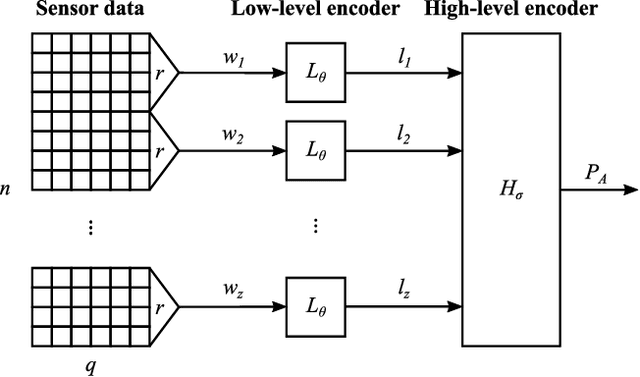
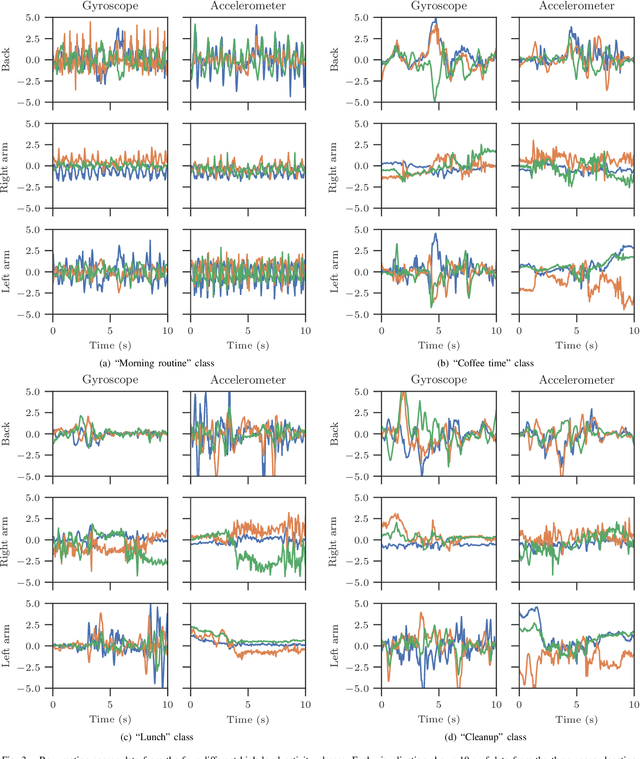
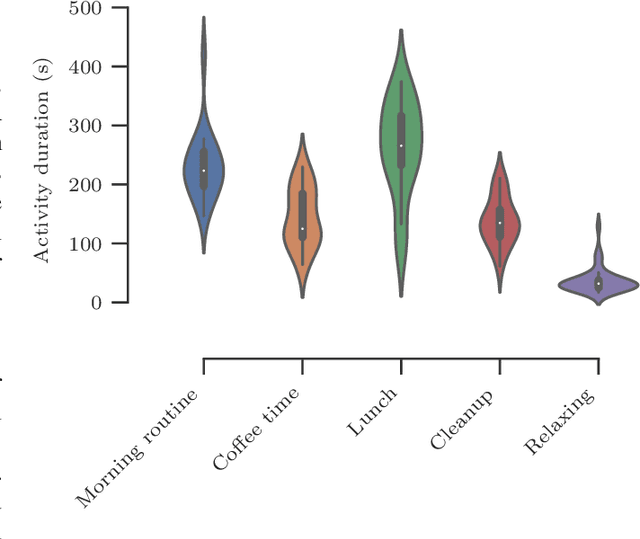
In this paper, we report a hierarchical deep learning model for classification of complex human activities using motion sensors. In contrast to traditional Human Activity Recognition (HAR) models used for event-based activity recognition, such as step counting, fall detection, and gesture identification, this new deep learning model, which we refer to as CHARM (Complex Human Activity Recognition Model), is aimed for recognition of high-level human activities that are composed of multiple different low-level activities in a non-deterministic sequence, such as meal preparation, house chores, and daily routines. CHARM not only quantitatively outperforms state-of-the-art supervised learning approaches for high-level activity recognition in terms of average accuracy and F1 scores, but also automatically learns to recognize low-level activities, such as manipulation gestures and locomotion modes, without any explicit labels for such activities. This opens new avenues for Human-Machine Interaction (HMI) modalities using wearable sensors, where the user can choose to associate an automated task with a high-level activity, such as controlling home automation (e.g., robotic vacuum cleaners, lights, and thermostats) or presenting contextually relevant information at the right time (e.g., reminders, status updates, and weather/news reports). In addition, the ability to learn low-level user activities when trained using only high-level activity labels may pave the way to semi-supervised learning of HAR tasks that are inherently difficult to label.
DTU-Net: Learning Topological Similarity for Curvilinear Structure Segmentation
May 23, 2022
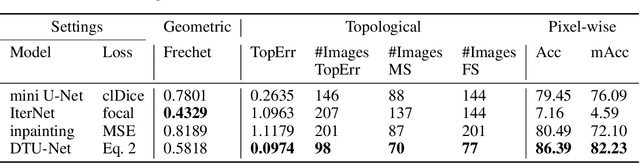
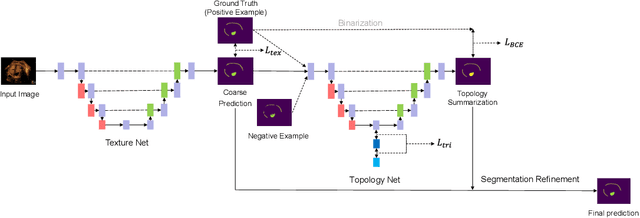
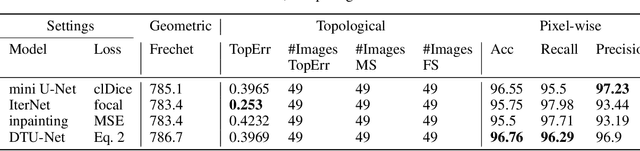
Curvilinear structure segmentation plays an important role in many applications. The standard formulation of segmentation as pixel-wise classification often fails to capture these structures due to the small size and low contrast. Some works introduce prior topological information to address this problem with the cost of expensive computations and the need for extra labels. Moreover, prior work primarily focuses on avoiding false splits by encouraging the connection of small gaps. Less attention has been given to avoiding missed splits, namely the incorrect inference of structures that are not visible in the image. In this paper, we present DTU-Net, a dual-decoder and topology-aware deep neural network consisting of two sequential light-weight U-Nets, namely a texture net, and a topology net. The texture net makes a coarse prediction using image texture information. The topology net learns topological information from the coarse prediction by employing a triplet loss trained to recognize false and missed splits, and provides a topology-aware separation of the foreground and background. The separation is further utilized to correct the coarse prediction. We conducted experiments on a challenging multi-class ultrasound scan segmentation dataset and an open dataset for road extraction. Results show that our model achieves state-of-the-art results in both segmentation accuracy and continuity. Compared to existing methods, our model corrects both false positive and false negative examples more effectively with no need for prior knowledge.
Dataset of Propaganda Techniques of the State-Sponsored Information Operation of the People's Republic of China
Jun 14, 2021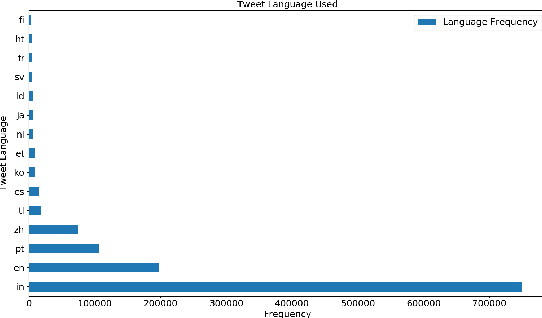

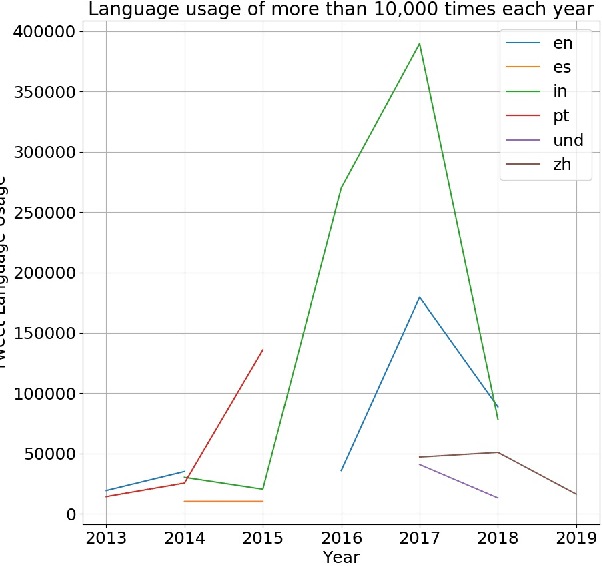

The digital media, identified as computational propaganda provides a pathway for propaganda to expand its reach without limit. State-backed propaganda aims to shape the audiences' cognition toward entities in favor of a certain political party or authority. Furthermore, it has become part of modern information warfare used in order to gain an advantage over opponents. Most of the current studies focus on using machine learning, quantitative, and qualitative methods to distinguish if a certain piece of information on social media is propaganda. Mainly conducted on English content, but very little research addresses Chinese Mandarin content. From propaganda detection, we want to go one step further to provide more fine-grained information on propaganda techniques that are applied. In this research, we aim to bridge the information gap by providing a multi-labeled propaganda techniques dataset in Mandarin based on a state-backed information operation dataset provided by Twitter. In addition to presenting the dataset, we apply a multi-label text classification using fine-tuned BERT. Potentially this could help future research in detecting state-backed propaganda online especially in a cross-lingual context and cross platforms identity consolidation.
Temporal Lift Pooling for Continuous Sign Language Recognition
Jul 18, 2022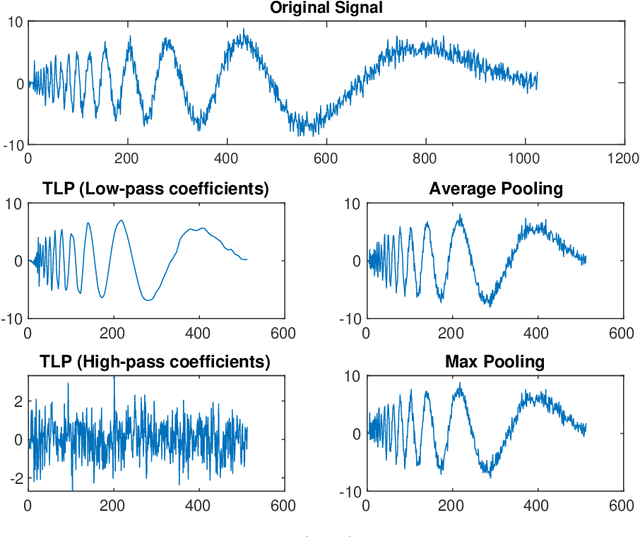
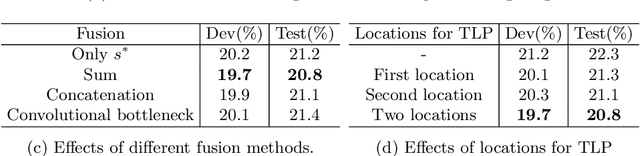

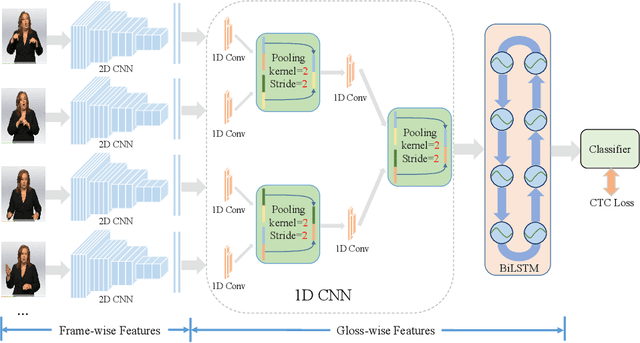
Pooling methods are necessities for modern neural networks for increasing receptive fields and lowering down computational costs. However, commonly used hand-crafted pooling approaches, e.g., max pooling and average pooling, may not well preserve discriminative features. While many researchers have elaborately designed various pooling variants in spatial domain to handle these limitations with much progress, the temporal aspect is rarely visited where directly applying hand-crafted methods or these specialized spatial variants may not be optimal. In this paper, we derive temporal lift pooling (TLP) from the Lifting Scheme in signal processing to intelligently downsample features of different temporal hierarchies. The Lifting Scheme factorizes input signals into various sub-bands with different frequency, which can be viewed as different temporal movement patterns. Our TLP is a three-stage procedure, which performs signal decomposition, component weighting and information fusion to generate a refined downsized feature map. We select a typical temporal task with long sequences, i.e. continuous sign language recognition (CSLR), as our testbed to verify the effectiveness of TLP. Experiments on two large-scale datasets show TLP outperforms hand-crafted methods and specialized spatial variants by a large margin (1.5%) with similar computational overhead. As a robust feature extractor, TLP exhibits great generalizability upon multiple backbones on various datasets and achieves new state-of-the-art results on two large-scale CSLR datasets. Visualizations further demonstrate the mechanism of TLP in correcting gloss borders. Code is released.
Deep Learning to See: Towards New Foundations of Computer Vision
Jun 30, 2022The remarkable progress in computer vision over the last few years is, by and large, attributed to deep learning, fueled by the availability of huge sets of labeled data, and paired with the explosive growth of the GPU paradigm. While subscribing to this view, this book criticizes the supposed scientific progress in the field and proposes the investigation of vision within the framework of information-based laws of nature. Specifically, the present work poses fundamental questions about vision that remain far from understood, leading the reader on a journey populated by novel challenges resonating with the foundations of machine learning. The central thesis is that for a deeper understanding of visual computational processes, it is necessary to look beyond the applications of general purpose machine learning algorithms and focus instead on appropriate learning theories that take into account the spatiotemporal nature of the visual signal.
Tree-constrained Pointer Generator with Graph Neural Network Encodings for Contextual Speech Recognition
Jul 02, 2022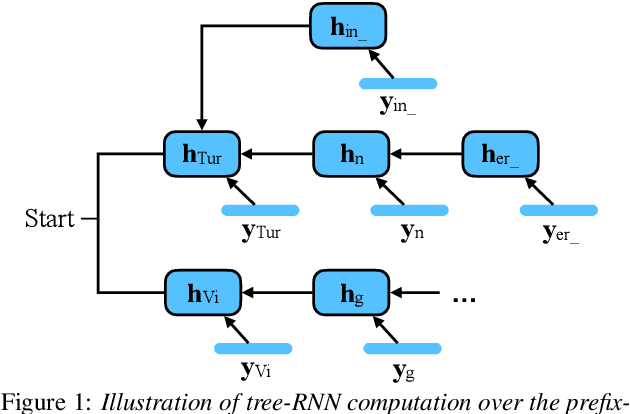
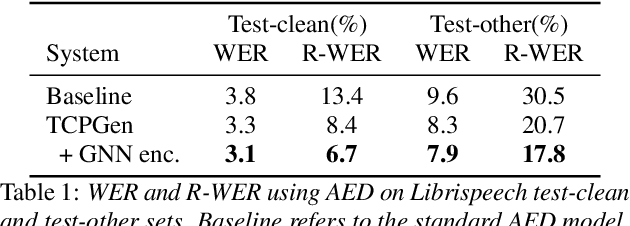
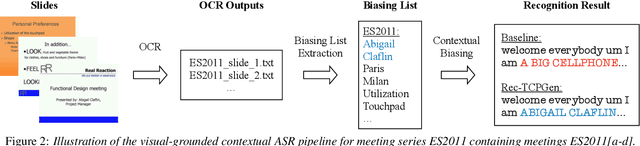
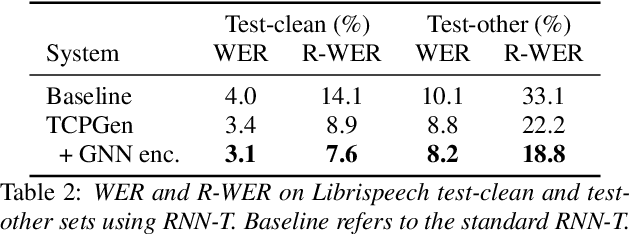
Incorporating biasing words obtained as contextual knowledge is critical for many automatic speech recognition (ASR) applications. This paper proposes the use of graph neural network (GNN) encodings in a tree-constrained pointer generator (TCPGen) component for end-to-end contextual ASR. By encoding the biasing words in the prefix-tree with a tree-based GNN, lookahead for future wordpieces in end-to-end ASR decoding is achieved at each tree node by incorporating information about all wordpieces on the tree branches rooted from it, which allows a more accurate prediction of the generation probability of the biasing words. Systems were evaluated on the Librispeech corpus using simulated biasing tasks, and on the AMI corpus by proposing a novel visual-grounded contextual ASR pipeline that extracts biasing words from slides alongside each meeting. Results showed that TCPGen with GNN encodings achieved about a further 15% relative WER reduction on the biasing words compared to the original TCPGen, with a negligible increase in the computation cost for decoding.
Subgraph Matching via Query-Conditioned Subgraph Matching Neural Networks and Bi-Level Tree Search
Jul 21, 2022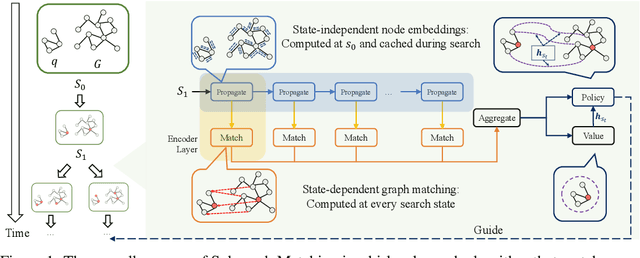
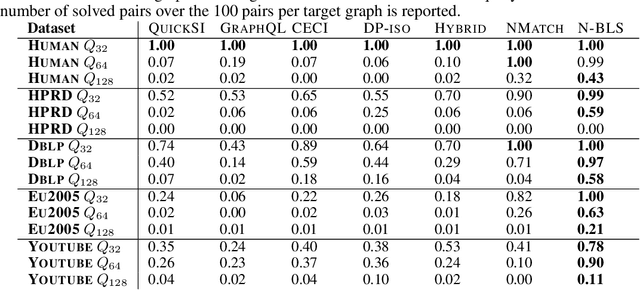
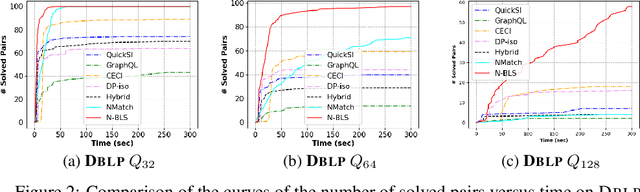
Recent advances have shown the success of using reinforcement learning and search to solve NP-hard graph-related tasks, such as Traveling Salesman Optimization, Graph Edit Distance computation, etc. However, it remains unclear how one can efficiently and accurately detect the occurrences of a small query graph in a large target graph, which is a core operation in graph database search, biomedical analysis, social group finding, etc. This task is called Subgraph Matching which essentially performs subgraph isomorphism check between a query graph and a large target graph. One promising approach to this classical problem is the "learning-to-search" paradigm, where a reinforcement learning (RL) agent is designed with a learned policy to guide a search algorithm to quickly find the solution without any solved instances for supervision. However, for the specific task of Subgraph Matching, though the query graph is usually small given by the user as input, the target graph is often orders-of-magnitude larger. It poses challenges to the neural network design and can lead to solution and reward sparsity. In this paper, we propose N-BLS with two innovations to tackle the challenges: (1) A novel encoder-decoder neural network architecture to dynamically compute the matching information between the query and the target graphs at each search state; (2) A Monte Carlo Tree Search enhanced bi-level search framework for training the policy and value networks. Experiments on five large real-world target graphs show that N-BLS can significantly improve the subgraph matching performance.
Improving Long Tailed Document-Level Relation Extraction via Easy Relation Augmentation and Contrastive Learning
May 21, 2022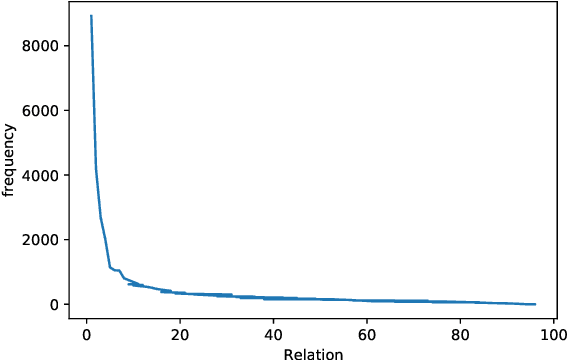
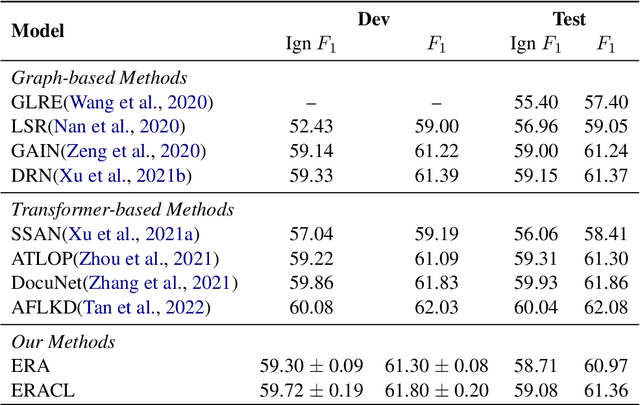
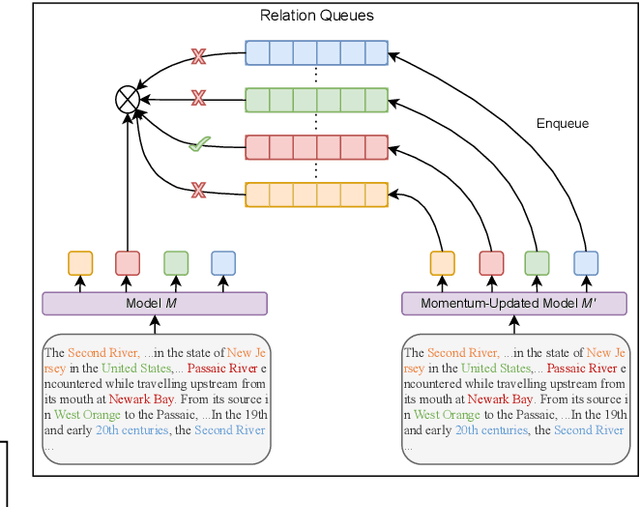
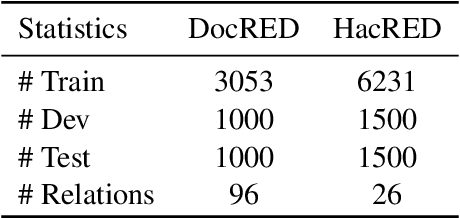
Towards real-world information extraction scenario, research of relation extraction is advancing to document-level relation extraction(DocRE). Existing approaches for DocRE aim to extract relation by encoding various information sources in the long context by novel model architectures. However, the inherent long-tailed distribution problem of DocRE is overlooked by prior work. We argue that mitigating the long-tailed distribution problem is crucial for DocRE in the real-world scenario. Motivated by the long-tailed distribution problem, we propose an Easy Relation Augmentation(ERA) method for improving DocRE by enhancing the performance of tailed relations. In addition, we further propose a novel contrastive learning framework based on our ERA, i.e., ERACL, which can further improve the model performance on tailed relations and achieve competitive overall DocRE performance compared to the state-of-arts.
How to talk so your robot will learn: Instructions, descriptions, and pragmatics
Jun 16, 2022
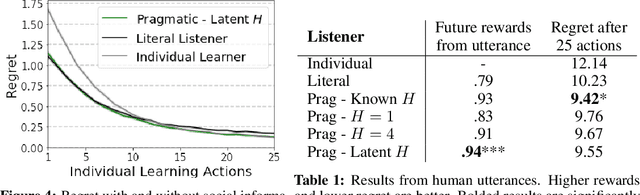
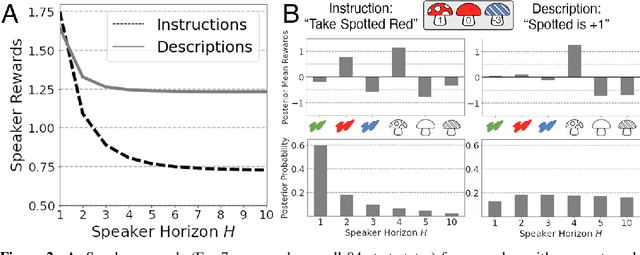
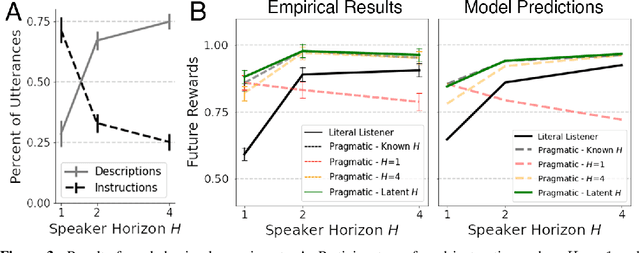
From the earliest years of our lives, humans use language to express our beliefs and desires. Being able to talk to artificial agents about our preferences would thus fulfill a central goal of value alignment. Yet today, we lack computational models explaining such flexible and abstract language use. To address this challenge, we consider social learning in a linear bandit setting and ask how a human might communicate preferences over behaviors (i.e. the reward function). We study two distinct types of language: instructions, which provide information about the desired policy, and descriptions, which provide information about the reward function. To explain how humans use these forms of language, we suggest they reason about both known present and unknown future states: instructions optimize for the present, while descriptions generalize to the future. We formalize this choice by extending reward design to consider a distribution over states. We then define a pragmatic listener agent that infers the speaker's reward function by reasoning about how the speaker expresses themselves. We validate our models with a behavioral experiment, demonstrating that (1) our speaker model predicts spontaneous human behavior, and (2) our pragmatic listener is able to recover their reward functions. Finally, we show that in traditional reinforcement learning settings, pragmatic social learning can integrate with and accelerate individual learning. Our findings suggest that social learning from a wider range of language -- in particular, expanding the field's present focus on instructions to include learning from descriptions -- is a promising approach for value alignment and reinforcement learning more broadly.
A Knowledge-Enhanced Adversarial Model for Cross-lingual Structured Sentiment Analysis
May 31, 2022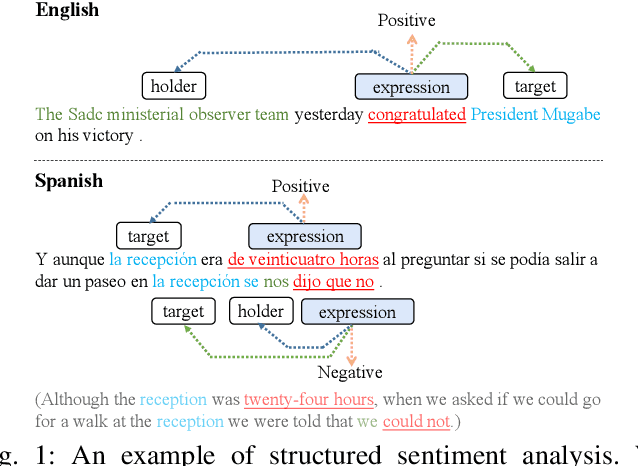
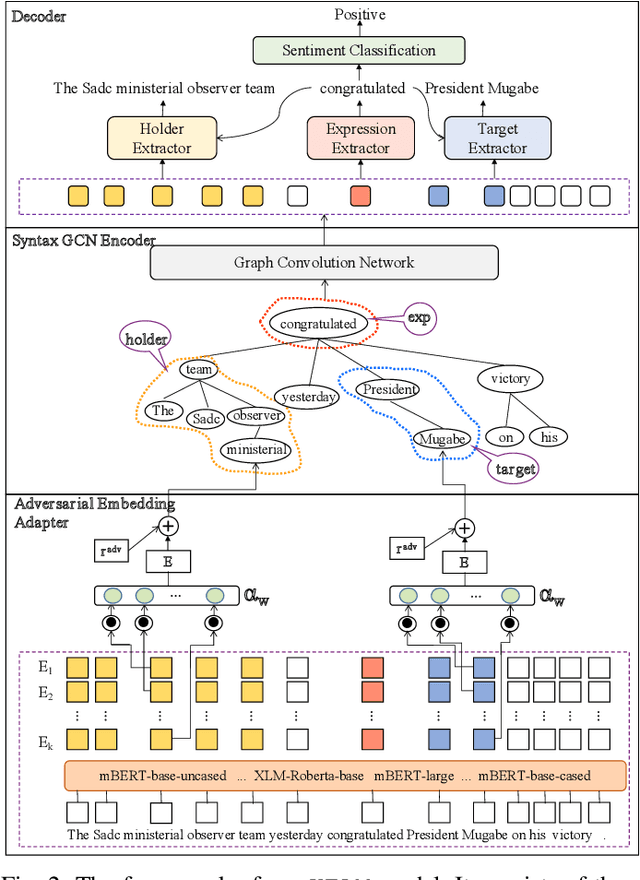
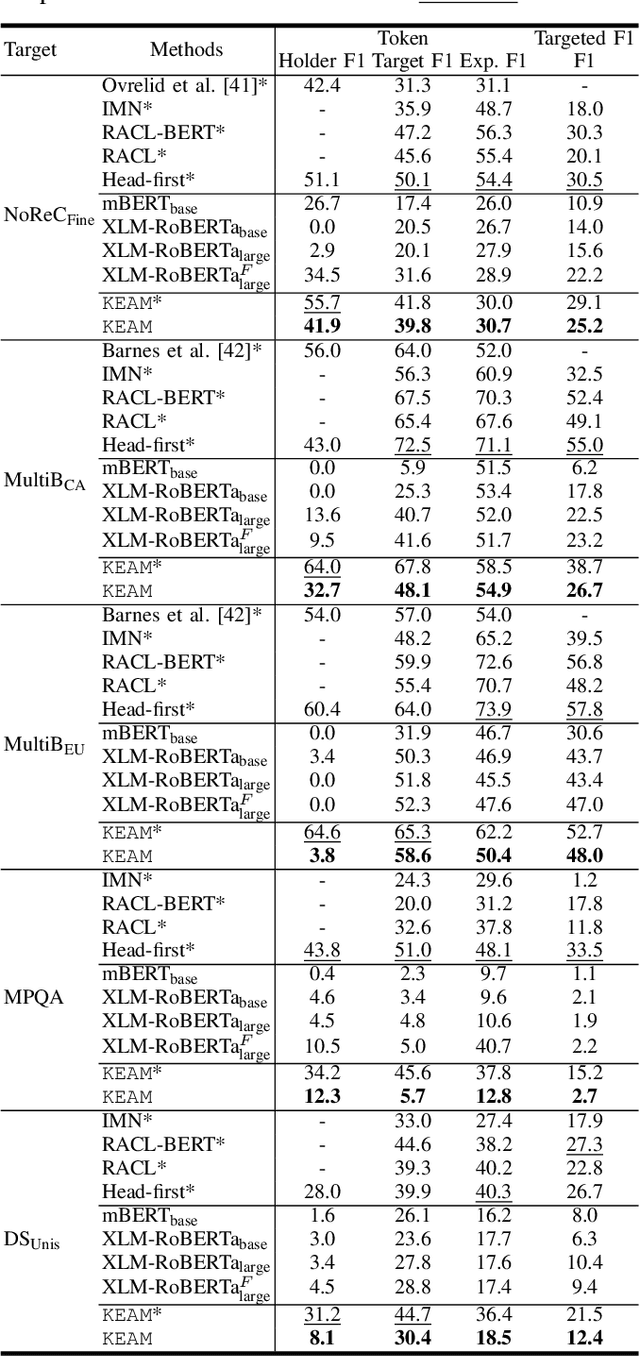
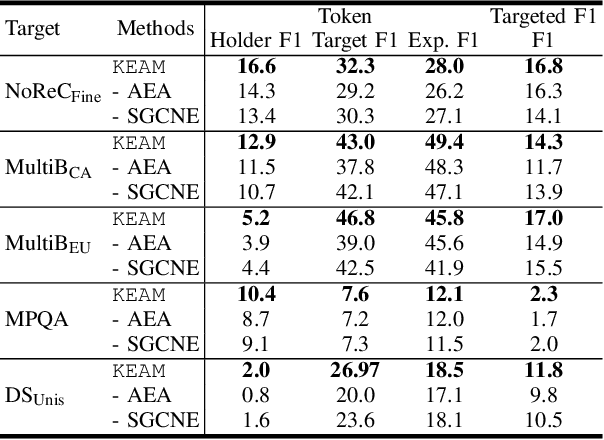
Structured sentiment analysis, which aims to extract the complex semantic structures such as holders, expressions, targets, and polarities, has obtained widespread attention from both industry and academia. Unfortunately, the existing structured sentiment analysis datasets refer to a few languages and are relatively small, limiting neural network models' performance. In this paper, we focus on the cross-lingual structured sentiment analysis task, which aims to transfer the knowledge from the source language to the target one. Notably, we propose a Knowledge-Enhanced Adversarial Model (\texttt{KEAM}) with both implicit distributed and explicit structural knowledge to enhance the cross-lingual transfer. First, we design an adversarial embedding adapter for learning an informative and robust representation by capturing implicit semantic information from diverse multi-lingual embeddings adaptively. Then, we propose a syntax GCN encoder to transfer the explicit semantic information (e.g., universal dependency tree) among multiple languages. We conduct experiments on five datasets and compare \texttt{KEAM} with both the supervised and unsupervised methods. The extensive experimental results show that our \texttt{KEAM} model outperforms all the unsupervised baselines in various metrics.