 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Demonstrating and Reducing Shortcuts in Vision-Language Representation Learning
Feb 27, 2024
Vision-language models (VLMs) mainly rely on contrastive training to learn general-purpose representations of images and captions. We focus on the situation when one image is associated with several captions, each caption containing both information shared among all captions and unique information per caption about the scene depicted in the image. In such cases, it is unclear whether contrastive losses are sufficient for learning task-optimal representations that contain all the information provided by the captions or whether the contrastive learning setup encourages the learning of a simple shortcut that minimizes contrastive loss. We introduce synthetic shortcuts for vision-language: a training and evaluation framework where we inject synthetic shortcuts into image-text data. We show that contrastive VLMs trained from scratch or fine-tuned with data containing these synthetic shortcuts mainly learn features that represent the shortcut. Hence, contrastive losses are not sufficient to learn task-optimal representations, i.e., representations that contain all task-relevant information shared between the image and associated captions. We examine two methods to reduce shortcut learning in our training and evaluation framework: (i) latent target decoding and (ii) implicit feature modification. We show empirically that both methods improve performance on the evaluation task, but only partly reduce shortcut learning when training and evaluating with our shortcut learning framework. Hence, we show the difficulty and challenge of our shortcut learning framework for contrastive vision-language representation learning.
Multi-FAct: Assessing Multilingual LLMs' Multi-Regional Knowledge using FActScore
Mar 01, 2024Large Language Models (LLMs) are prone to factuality hallucination, generating text that contradicts established knowledge. While extensive research has addressed this in English, little is known about multilingual LLMs. This paper systematically evaluates multilingual LLMs' factual accuracy across languages and geographic regions. We introduce a novel pipeline for multilingual factuality evaluation, adapting FActScore(Min et al., 2023) for diverse languages. Our analysis across nine languages reveals that English consistently outperforms others in factual accuracy and quantity of generated facts. Furthermore, multilingual models demonstrate a bias towards factual information from Western continents. These findings highlight the need for improved multilingual factuality assessment and underscore geographical biases in LLMs' fact generation.
Federated Learning via Lattice Joint Source-Channel Coding
Mar 01, 2024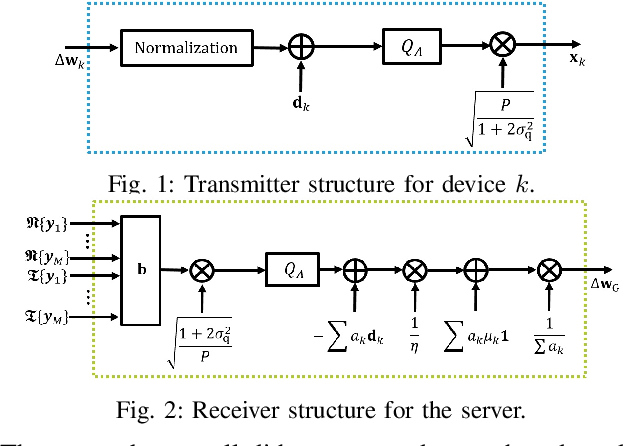
This paper introduces a universal federated learning framework that enables over-the-air computation via digital communications, using a new joint source-channel coding scheme. Without relying on channel state information at devices, this scheme employs lattice codes to both quantize model parameters and exploit interference from the devices. A novel two-layer receiver structure at the server is designed to reliably decode an integer combination of the quantized model parameters as a lattice point for the purpose of aggregation. Numerical experiments validate the effectiveness of the proposed scheme. Even with the challenges posed by channel conditions and device heterogeneity, the proposed scheme markedly surpasses other over-the-air FL strategies.
A Hybrid Model for Traffic Incident Detection based on Generative Adversarial Networks and Transformer Model
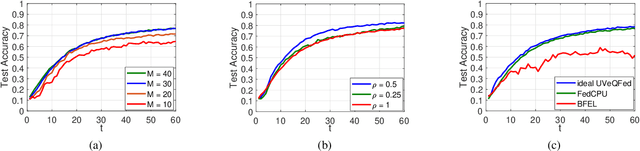
Mar 02, 2024

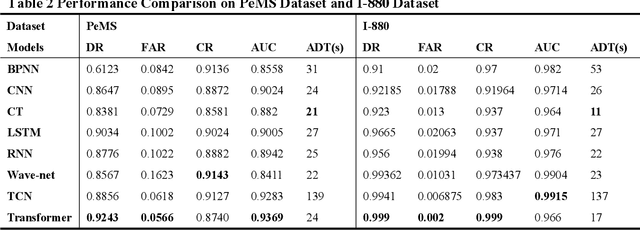
In addition to enhancing traffic safety and facilitating prompt emergency response, traffic incident detection plays an indispensable role in intelligent transportation systems by providing real-time traffic status information. This enables the realization of intelligent traffic control and management. Previous research has identified that apart from employing advanced algorithmic models, the effectiveness of detection is also significantly influenced by challenges related to acquiring large datasets and addressing dataset imbalances. A hybrid model combining transformer and generative adversarial networks (GANs) is proposed to address these challenges. Experiments are conducted on four real datasets to validate the superiority of the transformer in traffic incident detection. Additionally, GANs are utilized to expand the dataset and achieve a balanced ratio of 1:4, 2:3, and 1:1. The proposed model is evaluated against the baseline model. The results demonstrate that the proposed model enhances the dataset size, balances the dataset, and improves the performance of traffic incident detection in various aspects.
A Survey of AI-generated Text Forensic Systems: Detection, Attribution, and Characterization
Mar 02, 2024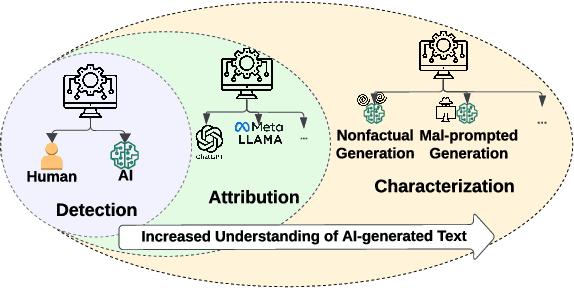
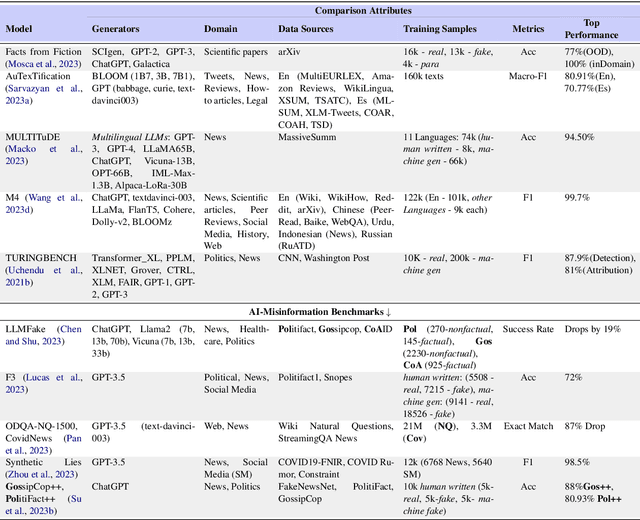
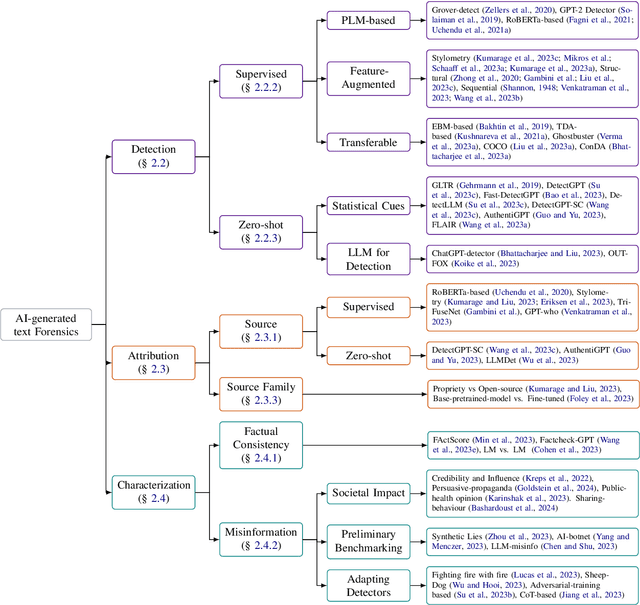
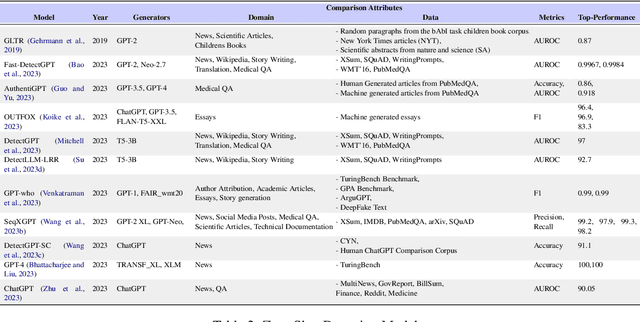
We have witnessed lately a rapid proliferation of advanced Large Language Models (LLMs) capable of generating high-quality text. While these LLMs have revolutionized text generation across various domains, they also pose significant risks to the information ecosystem, such as the potential for generating convincing propaganda, misinformation, and disinformation at scale. This paper offers a review of AI-generated text forensic systems, an emerging field addressing the challenges of LLM misuses. We present an overview of the existing efforts in AI-generated text forensics by introducing a detailed taxonomy, focusing on three primary pillars: detection, attribution, and characterization. These pillars enable a practical understanding of AI-generated text, from identifying AI-generated content (detection), determining the specific AI model involved (attribution), and grouping the underlying intents of the text (characterization). Furthermore, we explore available resources for AI-generated text forensics research and discuss the evolving challenges and future directions of forensic systems in an AI era.
OpticalDR: A Deep Optical Imaging Model for Privacy-Protective Depression Recognition
Feb 29, 2024Depression Recognition (DR) poses a considerable challenge, especially in the context of the growing concerns surrounding privacy. Traditional automatic diagnosis of DR technology necessitates the use of facial images, undoubtedly expose the patient identity features and poses privacy risks. In order to mitigate the potential risks associated with the inappropriate disclosure of patient facial images, we design a new imaging system to erase the identity information of captured facial images while retain disease-relevant features. It is irreversible for identity information recovery while preserving essential disease-related characteristics necessary for accurate DR. More specifically, we try to record a de-identified facial image (erasing the identifiable features as much as possible) by a learnable lens, which is optimized in conjunction with the following DR task as well as a range of face analysis related auxiliary tasks in an end-to-end manner. These aforementioned strategies form our final Optical deep Depression Recognition network (OpticalDR). Experiments on CelebA, AVEC 2013, and AVEC 2014 datasets demonstrate that our OpticalDR has achieved state-of-the-art privacy protection performance with an average AUC of 0.51 on popular facial recognition models, and competitive results for DR with MAE/RMSE of 7.53/8.48 on AVEC 2013 and 7.89/8.82 on AVEC 2014, respectively.
The Road to Next-Generation Multiple Access: A 50-Year Tutorial Review
Feb 29, 2024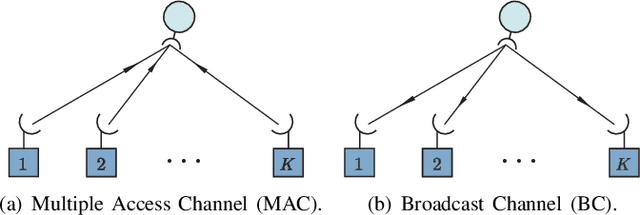
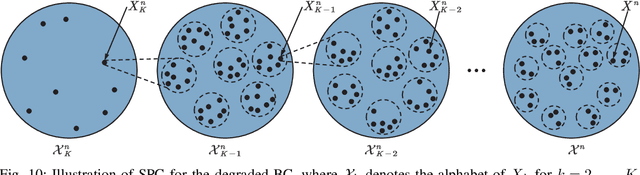

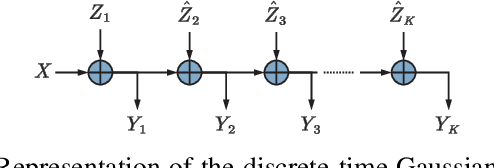
The evolution of wireless communications has been significantly influenced by remarkable advancements in multiple access (MA) technologies over the past five decades, shaping the landscape of modern connectivity. Within this context, a comprehensive tutorial review is presented, focusing on representative MA techniques developed over the past 50 years. The following areas are explored: i) The foundational principles and information-theoretic capacity limits of power-domain non-orthogonal multiple access (NOMA) are characterized, along with its extension to multiple-input multiple-output (MIMO)-NOMA. ii) Several MA transmission schemes exploiting the spatial domain are investigated, encompassing both conventional space-division multiple access (SDMA)/MIMO-NOMA systems and near-field MA systems utilizing spherical-wave propagation models. iii) The application of NOMA to integrated sensing and communications (ISAC) systems is studied. This includes an introduction to typical NOMA-based downlink/uplink ISAC frameworks, followed by an evaluation of their performance limits using a mutual information (MI)-based analytical framework. iv) Major issues and research opportunities associated with the integration of MA with other emerging technologies are identified to facilitate MA in next-generation networks, i.e., next-generation multiple access (NGMA). Throughout the paper, promising directions are highlighted to inspire future research endeavors in the realm of MA and NGMA.
Artwork Explanation in Large-scale Vision Language Models
Feb 29, 2024

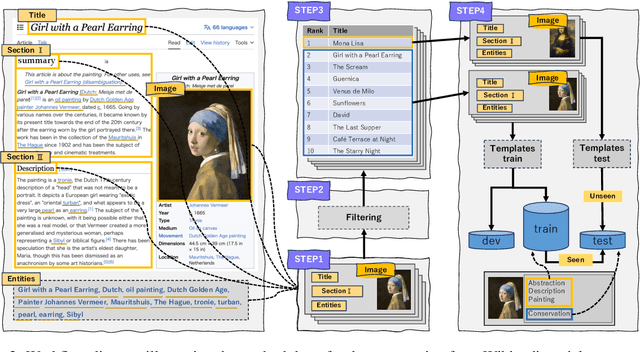
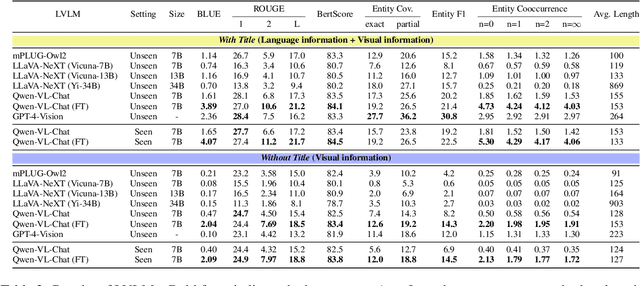
Large-scale vision-language models (LVLMs) output text from images and instructions, demonstrating advanced capabilities in text generation and comprehension. However, it has not been clarified to what extent LVLMs understand the knowledge necessary for explaining images, the complex relationships between various pieces of knowledge, and how they integrate these understandings into their explanations. To address this issue, we propose a new task: the artwork explanation generation task, along with its evaluation dataset and metric for quantitatively assessing the understanding and utilization of knowledge about artworks. This task is apt for image description based on the premise that LVLMs are expected to have pre-existing knowledge of artworks, which are often subjects of wide recognition and documented information. It consists of two parts: generating explanations from both images and titles of artworks, and generating explanations using only images, thus evaluating the LVLMs' language-based and vision-based knowledge. Alongside, we release a training dataset for LVLMs to learn explanations that incorporate knowledge about artworks. Our findings indicate that LVLMs not only struggle with integrating language and visual information but also exhibit a more pronounced limitation in acquiring knowledge from images alone. The datasets (ExpArt=Explain Artworks) are available at https://huggingface.co/datasets/naist-nlp/ExpArt.
Corpus-Steered Query Expansion with Large Language Models
Feb 28, 2024Recent studies demonstrate that query expansions generated by large language models (LLMs) can considerably enhance information retrieval systems by generating hypothetical documents that answer the queries as expansions. However, challenges arise from misalignments between the expansions and the retrieval corpus, resulting in issues like hallucinations and outdated information due to the limited intrinsic knowledge of LLMs. Inspired by Pseudo Relevance Feedback (PRF), we introduce Corpus-Steered Query Expansion (CSQE) to promote the incorporation of knowledge embedded within the corpus. CSQE utilizes the relevance assessing capability of LLMs to systematically identify pivotal sentences in the initially-retrieved documents. These corpus-originated texts are subsequently used to expand the query together with LLM-knowledge empowered expansions, improving the relevance prediction between the query and the target documents. Extensive experiments reveal that CSQE exhibits strong performance without necessitating any training, especially with queries for which LLMs lack knowledge.
Region-Transformer: Self-Attention Region Based Class-Agnostic Point Cloud Segmentation
Mar 03, 2024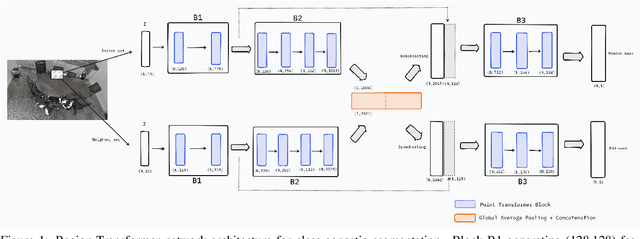
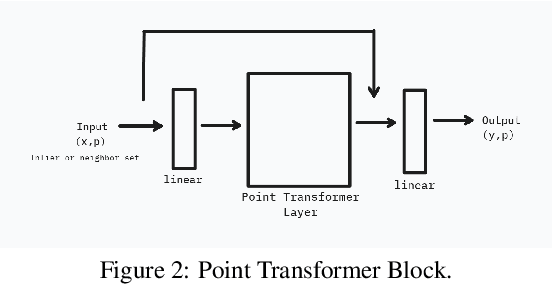
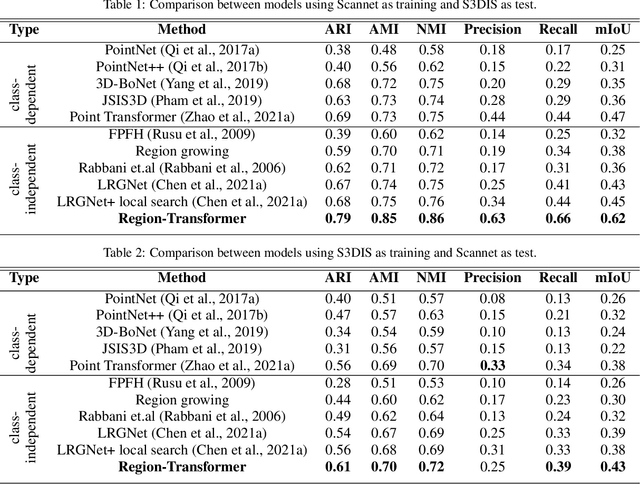

Point cloud segmentation, which helps us understand the environment of specific structures and objects, can be performed in class-specific and class-agnostic ways. We propose a novel region-based transformer model called Region-Transformer for performing class-agnostic point cloud segmentation. The model utilizes a region-growth approach and self-attention mechanism to iteratively expand or contract a region by adding or removing points. It is trained on simulated point clouds with instance labels only, avoiding semantic labels. Attention-based networks have succeeded in many previous methods of performing point cloud segmentation. However, a region-growth approach with attention-based networks has yet to be used to explore its performance gain. To our knowledge, we are the first to use a self-attention mechanism in a region-growth approach. With the introduction of self-attention to region-growth that can utilize local contextual information of neighborhood points, our experiments demonstrate that the Region-Transformer model outperforms previous class-agnostic and class-specific methods on indoor datasets regarding clustering metrics. The model generalizes well to large-scale scenes. Key advantages include capturing long-range dependencies through self-attention, avoiding the need for semantic labels during training, and applicability to a variable number of objects. The Region-Transformer model represents a promising approach for flexible point cloud segmentation with applications in robotics, digital twinning, and autonomous vehicles.
* 8 pages, 5 figures, 3 tables