 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Attacks of Social Engineering in Multi-turn Conversations -- LLM Agents for Simulation and Detection
Mar 18, 2025



The rapid advancement of conversational agents, particularly chatbots powered by Large Language Models (LLMs), poses a significant risk of social engineering (SE) attacks on social media platforms. SE detection in multi-turn, chat-based interactions is considerably more complex than single-instance detection due to the dynamic nature of these conversations. A critical factor in mitigating this threat is understanding the mechanisms through which SE attacks operate, specifically how attackers exploit vulnerabilities and how victims' personality traits contribute to their susceptibility. In this work, we propose an LLM-agentic framework, SE-VSim, to simulate SE attack mechanisms by generating multi-turn conversations. We model victim agents with varying personality traits to assess how psychological profiles influence susceptibility to manipulation. Using a dataset of over 1000 simulated conversations, we examine attack scenarios in which adversaries, posing as recruiters, funding agencies, and journalists, attempt to extract sensitive information. Based on this analysis, we present a proof of concept, SE-OmniGuard, to offer personalized protection to users by leveraging prior knowledge of the victims personality, evaluating attack strategies, and monitoring information exchanges in conversations to identify potential SE attempts.
Defending Against Social Engineering Attacks in the Age of LLMs
Jun 18, 2024



The proliferation of Large Language Models (LLMs) poses challenges in detecting and mitigating digital deception, as these models can emulate human conversational patterns and facilitate chat-based social engineering (CSE) attacks. This study investigates the dual capabilities of LLMs as both facilitators and defenders against CSE threats. We develop a novel dataset, SEConvo, simulating CSE scenarios in academic and recruitment contexts, and designed to examine how LLMs can be exploited in these situations. Our findings reveal that, while off-the-shelf LLMs generate high-quality CSE content, their detection capabilities are suboptimal, leading to increased operational costs for defense. In response, we propose ConvoSentinel, a modular defense pipeline that improves detection at both the message and the conversation levels, offering enhanced adaptability and cost-effectiveness. The retrieval-augmented module in ConvoSentinel identifies malicious intent by comparing messages to a database of similar conversations, enhancing CSE detection at all stages. Our study highlights the need for advanced strategies to leverage LLMs in cybersecurity.
Zero-shot LLM-guided Counterfactual Generation for Text
May 08, 2024



Counterfactual examples are frequently used for model development and evaluation in many natural language processing (NLP) tasks. Although methods for automated counterfactual generation have been explored, such methods depend on models such as pre-trained language models that are then fine-tuned on auxiliary, often task-specific datasets. Collecting and annotating such datasets for counterfactual generation is labor intensive and therefore, infeasible in practice. Therefore, in this work, we focus on a novel problem setting: \textit{zero-shot counterfactual generation}. To this end, we propose a structured way to utilize large language models (LLMs) as general purpose counterfactual example generators. We hypothesize that the instruction-following and textual understanding capabilities of recent LLMs can be effectively leveraged for generating high quality counterfactuals in a zero-shot manner, without requiring any training or fine-tuning. Through comprehensive experiments on various downstream tasks in natural language processing (NLP), we demonstrate the efficacy of LLMs as zero-shot counterfactual generators in evaluating and explaining black-box NLP models.
EAGLE: A Domain Generalization Framework for AI-generated Text Detection
Mar 23, 2024With the advancement in capabilities of Large Language Models (LLMs), one major step in the responsible and safe use of such LLMs is to be able to detect text generated by these models. While supervised AI-generated text detectors perform well on text generated by older LLMs, with the frequent release of new LLMs, building supervised detectors for identifying text from such new models would require new labeled training data, which is infeasible in practice. In this work, we tackle this problem and propose a domain generalization framework for the detection of AI-generated text from unseen target generators. Our proposed framework, EAGLE, leverages the labeled data that is available so far from older language models and learns features invariant across these generators, in order to detect text generated by an unknown target generator. EAGLE learns such domain-invariant features by combining the representational power of self-supervised contrastive learning with domain adversarial training. Through our experiments we demonstrate how EAGLE effectively achieves impressive performance in detecting text generated by unseen target generators, including recent state-of-the-art ones such as GPT-4 and Claude, reaching detection scores of within 4.7% of a fully supervised detector.
Harnessing Artificial Intelligence to Combat Online Hate: Exploring the Challenges and Opportunities of Large Language Models in Hate Speech Detection
Mar 12, 2024



Large language models (LLMs) excel in many diverse applications beyond language generation, e.g., translation, summarization, and sentiment analysis. One intriguing application is in text classification. This becomes pertinent in the realm of identifying hateful or toxic speech -- a domain fraught with challenges and ethical dilemmas. In our study, we have two objectives: firstly, to offer a literature review revolving around LLMs as classifiers, emphasizing their role in detecting and classifying hateful or toxic content. Subsequently, we explore the efficacy of several LLMs in classifying hate speech: identifying which LLMs excel in this task as well as their underlying attributes and training. Providing insight into the factors that contribute to an LLM proficiency (or lack thereof) in discerning hateful content. By combining a comprehensive literature review with an empirical analysis, our paper strives to shed light on the capabilities and constraints of LLMs in the crucial domain of hate speech detection.
A Survey of AI-generated Text Forensic Systems: Detection, Attribution, and Characterization
Mar 02, 2024



We have witnessed lately a rapid proliferation of advanced Large Language Models (LLMs) capable of generating high-quality text. While these LLMs have revolutionized text generation across various domains, they also pose significant risks to the information ecosystem, such as the potential for generating convincing propaganda, misinformation, and disinformation at scale. This paper offers a review of AI-generated text forensic systems, an emerging field addressing the challenges of LLM misuses. We present an overview of the existing efforts in AI-generated text forensics by introducing a detailed taxonomy, focusing on three primary pillars: detection, attribution, and characterization. These pillars enable a practical understanding of AI-generated text, from identifying AI-generated content (detection), determining the specific AI model involved (attribution), and grouping the underlying intents of the text (characterization). Furthermore, we explore available resources for AI-generated text forensics research and discuss the evolving challenges and future directions of forensic systems in an AI era.
How Reliable Are AI-Generated-Text Detectors? An Assessment Framework Using Evasive Soft Prompts
Oct 08, 2023



In recent years, there has been a rapid proliferation of AI-generated text, primarily driven by the release of powerful pre-trained language models (PLMs). To address the issue of misuse associated with AI-generated text, various high-performing detectors have been developed, including the OpenAI detector and the Stanford DetectGPT. In our study, we ask how reliable these detectors are. We answer the question by designing a novel approach that can prompt any PLM to generate text that evades these high-performing detectors. The proposed approach suggests a universal evasive prompt, a novel type of soft prompt, which guides PLMs in producing "human-like" text that can mislead the detectors. The novel universal evasive prompt is achieved in two steps: First, we create an evasive soft prompt tailored to a specific PLM through prompt tuning; and then, we leverage the transferability of soft prompts to transfer the learned evasive soft prompt from one PLM to another. Employing multiple PLMs in various writing tasks, we conduct extensive experiments to evaluate the efficacy of the evasive soft prompts in their evasion of state-of-the-art detectors.
LLMs as Counterfactual Explanation Modules: Can ChatGPT Explain Black-box Text Classifiers?
Sep 23, 2023Large language models (LLMs) are increasingly being used for tasks beyond text generation, including complex tasks such as data labeling, information extraction, etc. With the recent surge in research efforts to comprehend the full extent of LLM capabilities, in this work, we investigate the role of LLMs as counterfactual explanation modules, to explain decisions of black-box text classifiers. Inspired by causal thinking, we propose a pipeline for using LLMs to generate post-hoc, model-agnostic counterfactual explanations in a principled way via (i) leveraging the textual understanding capabilities of the LLM to identify and extract latent features, and (ii) leveraging the perturbation and generation capabilities of the same LLM to generate a counterfactual explanation by perturbing input features derived from the extracted latent features. We evaluate three variants of our framework, with varying degrees of specificity, on a suite of state-of-the-art LLMs, including ChatGPT and LLaMA 2. We evaluate the effectiveness and quality of the generated counterfactual explanations, over a variety of text classification benchmarks. Our results show varied performance of these models in different settings, with a full two-step feature extraction based variant outperforming others in most cases. Our pipeline can be used in automated explanation systems, potentially reducing human effort.
J-Guard: Journalism Guided Adversarially Robust Detection of AI-generated News
Sep 06, 2023
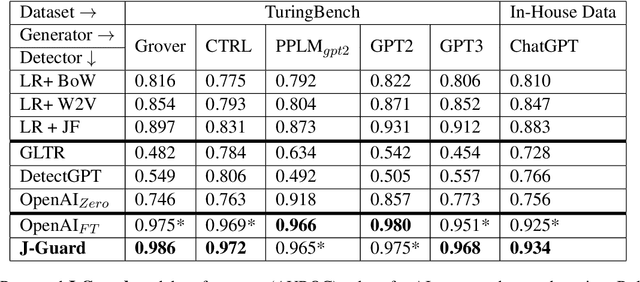

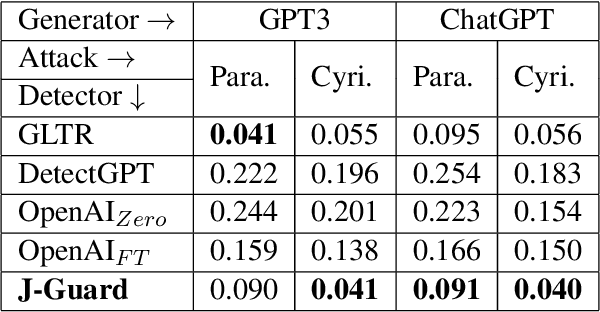
The rapid proliferation of AI-generated text online is profoundly reshaping the information landscape. Among various types of AI-generated text, AI-generated news presents a significant threat as it can be a prominent source of misinformation online. While several recent efforts have focused on detecting AI-generated text in general, these methods require enhanced reliability, given concerns about their vulnerability to simple adversarial attacks. Furthermore, due to the eccentricities of news writing, applying these detection methods for AI-generated news can produce false positives, potentially damaging the reputation of news organizations. To address these challenges, we leverage the expertise of an interdisciplinary team to develop a framework, J-Guard, capable of steering existing supervised AI text detectors for detecting AI-generated news while boosting adversarial robustness. By incorporating stylistic cues inspired by the unique journalistic attributes, J-Guard effectively distinguishes between real-world journalism and AI-generated news articles. Our experiments on news articles generated by a vast array of AI models, including ChatGPT (GPT3.5), demonstrate the effectiveness of J-Guard in enhancing detection capabilities while maintaining an average performance decrease of as low as 7% when faced with adversarial attacks.
Stylometric Detection of AI-Generated Text in Twitter Timelines
Mar 07, 2023



Recent advancements in pre-trained language models have enabled convenient methods for generating human-like text at a large scale. Though these generation capabilities hold great potential for breakthrough applications, it can also be a tool for an adversary to generate misinformation. In particular, social media platforms like Twitter are highly susceptible to AI-generated misinformation. A potential threat scenario is when an adversary hijacks a credible user account and incorporates a natural language generator to generate misinformation. Such threats necessitate automated detectors for AI-generated tweets in a given user's Twitter timeline. However, tweets are inherently short, thus making it difficult for current state-of-the-art pre-trained language model-based detectors to accurately detect at what point the AI starts to generate tweets in a given Twitter timeline. In this paper, we present a novel algorithm using stylometric signals to aid detecting AI-generated tweets. We propose models corresponding to quantifying stylistic changes in human and AI tweets in two related tasks: Task 1 - discriminate between human and AI-generated tweets, and Task 2 - detect if and when an AI starts to generate tweets in a given Twitter timeline. Our extensive experiments demonstrate that the stylometric features are effective in augmenting the state-of-the-art AI-generated text detectors.