 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CAME: Context-aware Mixture-of-Experts for Unbiased Scene Graph Generation
Aug 15, 2022
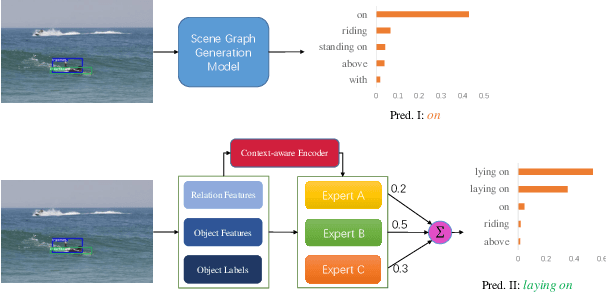
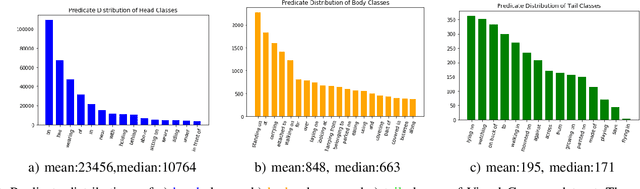
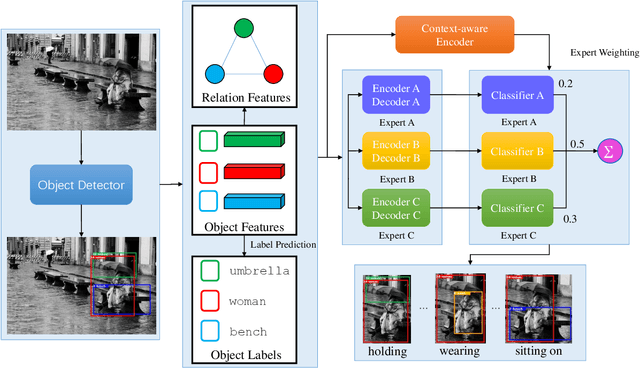
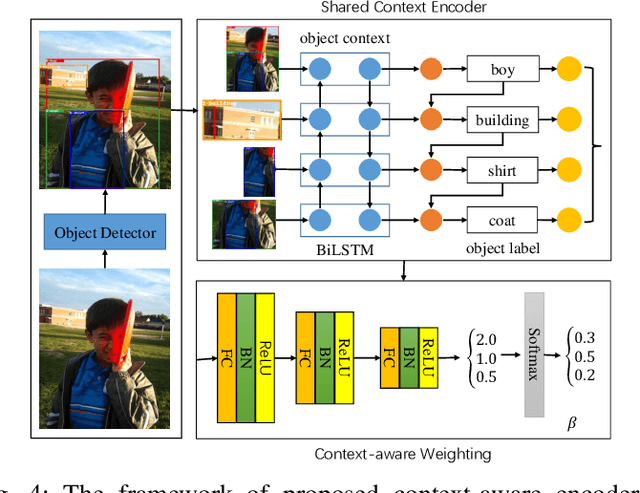
The scene graph generation has gained tremendous progress in recent years. However, its intrinsic long-tailed distribution of predicate classes is a challenging problem. Almost all existing scene graph generation (SGG) methods follow the same framework where they use a similar backbone network for object detection and a customized network for scene graph generation. These methods often design the sophisticated context-encoder to extract the inherent relevance of scene context w.r.t the intrinsic predicates and complicated networks to improve the learning capabilities of the network model for highly imbalanced data distributions. To address the unbiased SGG problem, we present a simple yet effective method called Context-Aware Mixture-of-Experts (CAME) to improve the model diversity and alleviate the biased SGG without a sophisticated design. Specifically, we propose to use the mixture of experts to remedy the heavily long-tailed distributions of predicate classes, which is suitable for most unbiased scene graph generators. With a mixture of relation experts, the long-tailed distribution of predicates is addressed in a divide and ensemble manner. As a result, the biased SGG is mitigated and the model tends to make more balanced predicates predictions. However, experts with the same weight are not sufficiently diverse to discriminate the different levels of predicates distributions. Hence, we simply use the build-in context-aware encoder, to help the network dynamically leverage the rich scene characteristics to further increase the diversity of the model. By utilizing the context information of the image, the importance of each expert w.r.t the scene context is dynamically assigned. We have conducted extensive experiments on three tasks on the Visual Genome dataset to show that came achieved superior performance over previous methods.
White Matter Tracts are Point Clouds: Neuropsychological Score Prediction and Critical Region Localization via Geometric Deep Learning
Jul 06, 2022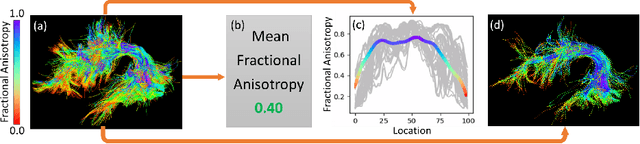
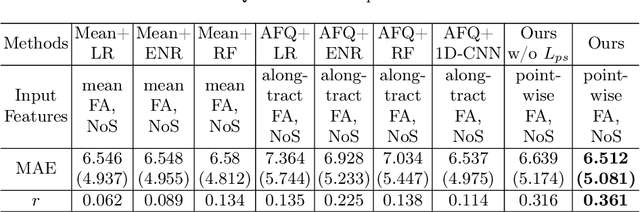
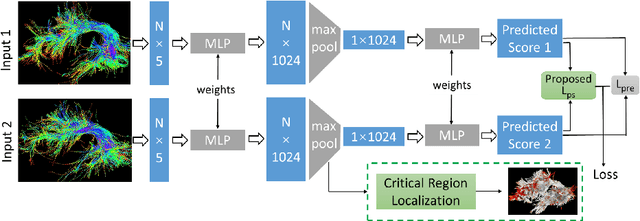
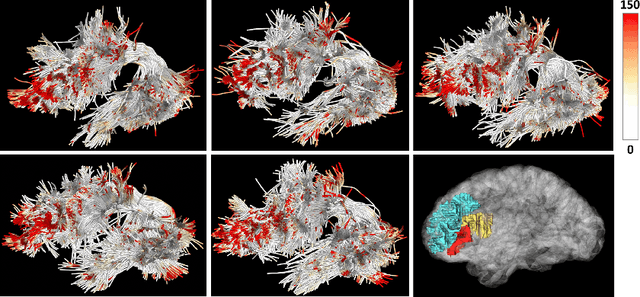
White matter tract microstructure has been shown to influence neuropsychological scores of cognitive performance. However, prediction of these scores from white matter tract data has not been attempted. In this paper, we propose a deep-learning-based framework for neuropsychological score prediction using microstructure measurements estimated from diffusion magnetic resonance imaging (dMRI) tractography, focusing on predicting performance on a receptive vocabulary assessment task based on a critical fiber tract for language, the arcuate fasciculus (AF). We directly utilize information from all points in a fiber tract, without the need to average data along the fiber as is traditionally required by diffusion MRI tractometry methods. Specifically, we represent the AF as a point cloud with microstructure measurements at each point, enabling adoption of point-based neural networks. We improve prediction performance with the proposed Paired-Siamese Loss that utilizes information about differences between continuous neuropsychological scores. Finally, we propose a Critical Region Localization (CRL) algorithm to localize informative anatomical regions containing points with strong contributions to the prediction results. Our method is evaluated on data from 806 subjects from the Human Connectome Project dataset. Results demonstrate superior neuropsychological score prediction performance compared to baseline methods. We discover that critical regions in the AF are strikingly consistent across subjects, with the highest number of strongly contributing points located in frontal cortical regions (i.e., the rostral middle frontal, pars opercularis, and pars triangularis), which are strongly implicated as critical areas for language processes.
A Cognitive Study on Semantic Similarity Analysis of Large Corpora: A Transformer-based Approach
Jul 24, 2022



Semantic similarity analysis and modeling is a fundamentally acclaimed task in many pioneering applications of natural language processing today. Owing to the sensation of sequential pattern recognition, many neural networks like RNNs and LSTMs have achieved satisfactory results in semantic similarity modeling. However, these solutions are considered inefficient due to their inability to process information in a non-sequential manner, thus leading to the improper extraction of context. Transformers function as the state-of-the-art architecture due to their advantages like non-sequential data processing and self-attention. In this paper, we perform semantic similarity analysis and modeling on the U.S Patent Phrase to Phrase Matching Dataset using both traditional and transformer-based techniques. We experiment upon four different variants of the Decoding Enhanced BERT - DeBERTa and enhance its performance by performing K-Fold Cross-Validation. The experimental results demonstrate our methodology's enhanced performance compared to traditional techniques, with an average Pearson correlation score of 0.79.
'Labelling the Gaps': A Weakly Supervised Automatic Eye Gaze Estimation
Aug 03, 2022
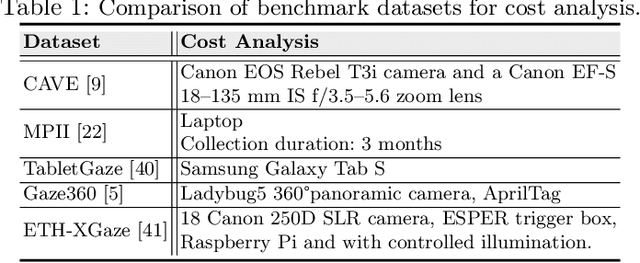
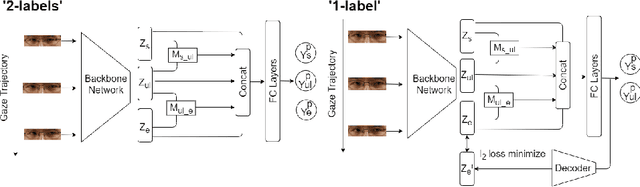
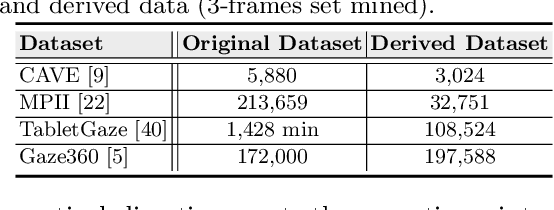
Over the past few years, there has been an increasing interest to interpret gaze direction in an unconstrained environment with limited supervision. Owing to data curation and annotation issues, replicating gaze estimation method to other platforms, such as unconstrained outdoor or AR/VR, might lead to significant drop in performance due to insufficient availability of accurately annotated data for model training. In this paper, we explore an interesting yet challenging problem of gaze estimation method with a limited amount of labelled data. The proposed method distills knowledge from the labelled subset with visual features; including identity-specific appearance, gaze trajectory consistency and motion features. Given a gaze trajectory, the method utilizes label information of only the start and the end frames of a gaze sequence. An extension of the proposed method further reduces the requirement of labelled frames to only the start frame with a minor drop in the generated label's quality. We evaluate the proposed method on four benchmark datasets (CAVE, TabletGaze, MPII and Gaze360) as well as web-crawled YouTube videos. Our proposed method reduces the annotation effort to as low as 2.67%, with minimal impact on performance; indicating the potential of our model enabling gaze estimation 'in-the-wild' setup.
Learning Prior Feature and Attention Enhanced Image Inpainting
Aug 03, 2022

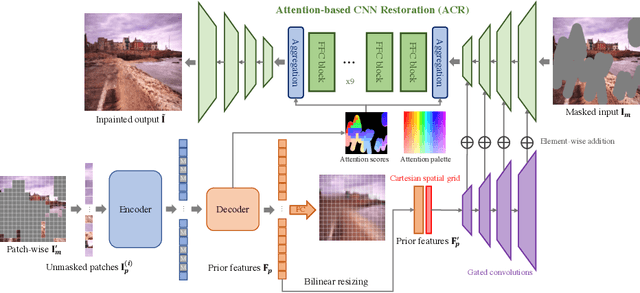

Many recent inpainting works have achieved impressive results by leveraging Deep Neural Networks (DNNs) to model various prior information for image restoration. Unfortunately, the performance of these methods is largely limited by the representation ability of vanilla Convolutional Neural Networks (CNNs) backbones.On the other hand, Vision Transformers (ViT) with self-supervised pre-training have shown great potential for many visual recognition and object detection tasks. A natural question is whether the inpainting task can be greatly benefited from the ViT backbone? However, it is nontrivial to directly replace the new backbones in inpainting networks, as the inpainting is an inverse problem fundamentally different from the recognition tasks. To this end, this paper incorporates the pre-training based Masked AutoEncoder (MAE) into the inpainting model, which enjoys richer informative priors to enhance the inpainting process. Moreover, we propose to use attention priors from MAE to make the inpainting model learn more long-distance dependencies between masked and unmasked regions. Sufficient ablations have been discussed about the inpainting and the self-supervised pre-training models in this paper. Besides, experiments on both Places2 and FFHQ demonstrate the effectiveness of our proposed model. Codes and pre-trained models are released in https://github.com/ewrfcas/MAE-FAR.
What Do Deep Neural Networks Find in Disordered Structures of Glasses?
Jul 31, 2022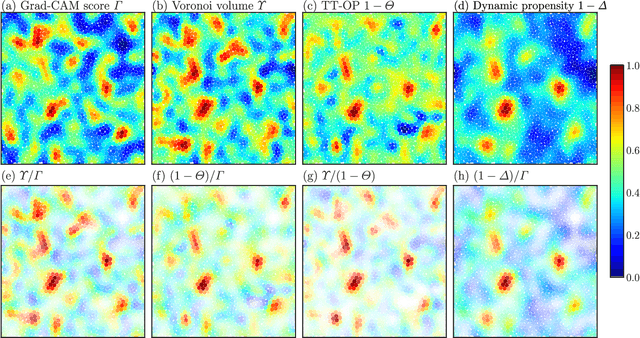
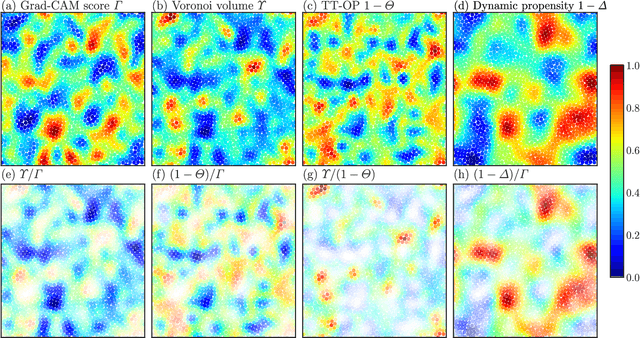
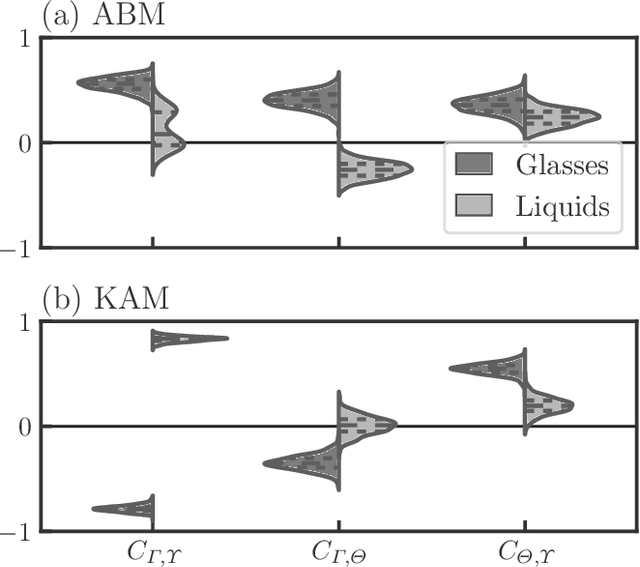
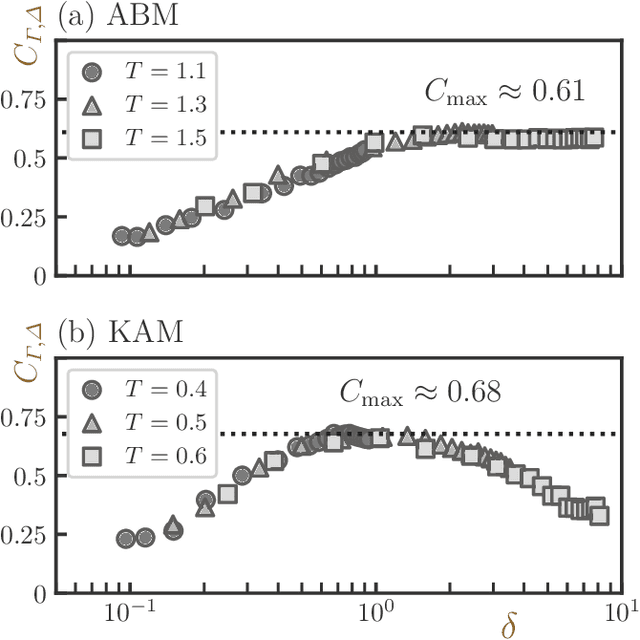
Glass transitions are widely observed in a range of types of soft matter systems. However, the physical mechanism of these transitions remains unknown, despite years of ambitious research. In particular, an important unanswered question is whether the glass transition is accompanied by a divergence of the correlation lengths of the characteristic static structures. Recently, a method that can predict long-time dynamics from purely static information with high accuracy was proposed; however, even this method is not universal and does not work well for the Kob--Andersen system, which is a typical model of glass-forming liquids. In this study, we developed a method to extract the characteristic structures of glasses using machine learning or, specifically, a convolutional neural network. In particular, we extracted the characteristic structures by quantifying the grounds for the decisions made by the network. We considered two qualitatively different glass-forming binary systems and, through comparisons with several established structural indicators, we demonstrate that our system can identify characteristic structures that depend on the details of the systems. Surprisingly, the extracted structures were strongly correlated with the nonequilibrium aging dynamics on thermal fluctuation.
Information Discrepancy in Strategic Learning
Mar 03, 2021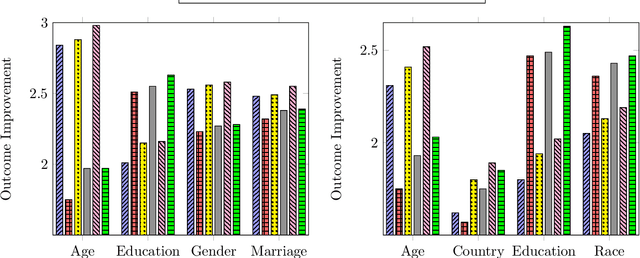


We study a decision-making model where a principal deploys a scoring rule and the agents strategically invest effort to improve their scores. Unlike existing work in the strategic learning literature, we do not assume that the principal's scoring rule is fully known to the agents, and agents may form different estimates of the scoring rule based on their own sources of information. We focus on disparities in outcomes that stem from information discrepancies in our model. To do so, we consider a population of agents who belong to different subgroups, which determine their knowledge about the deployed scoring rule. Agents within each subgroup observe the past scores received by their peers, which allow them to construct an estimate of the deployed scoring rule and to invest their efforts accordingly. The principal, taking into account the agents' behaviors, deploys a scoring rule that maximizes the social welfare of the whole population. We provide a collection of theoretical results that characterize the impact of the welfare-maximizing scoring rules on the strategic effort investments across different subgroups. In particular, we identify sufficient and necessary conditions for when the deployed scoring rule incentivizes optimal strategic investment across all groups for different notions of optimality. Finally, we complement and validate our theoretical analysis with experimental results on the real-world datasets Taiwan-Credit and Adult.
Disentangling representations in Restricted Boltzmann Machines without adversaries
Jun 23, 2022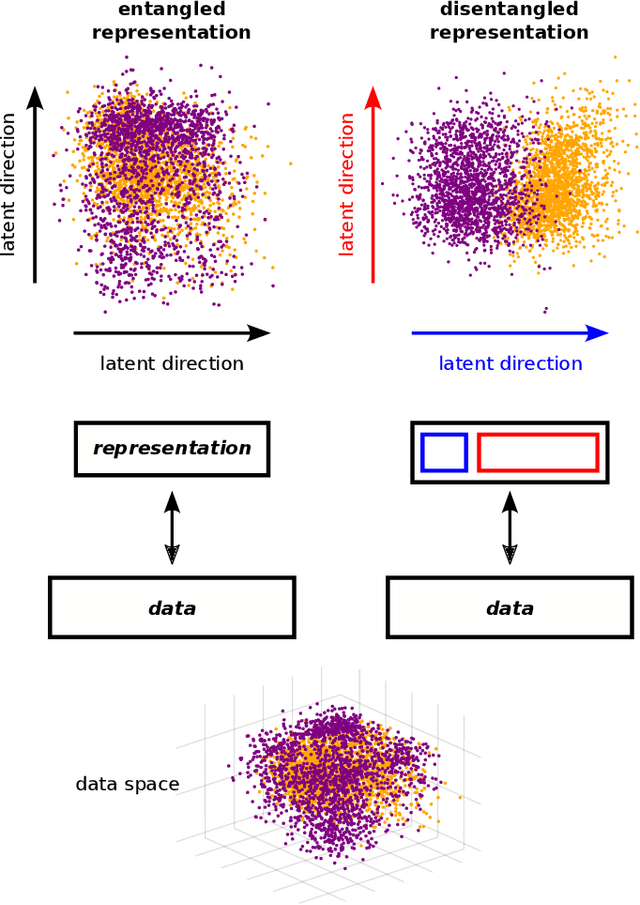
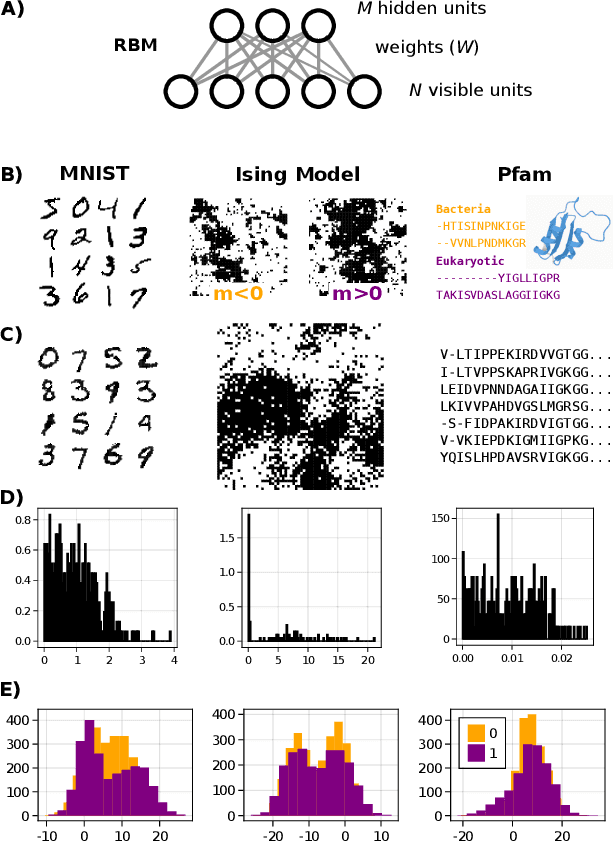
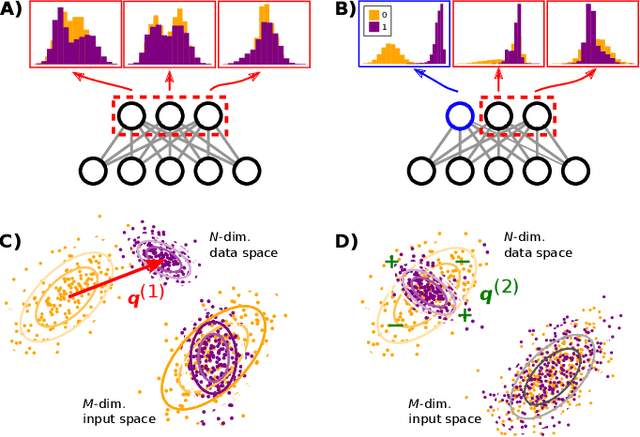
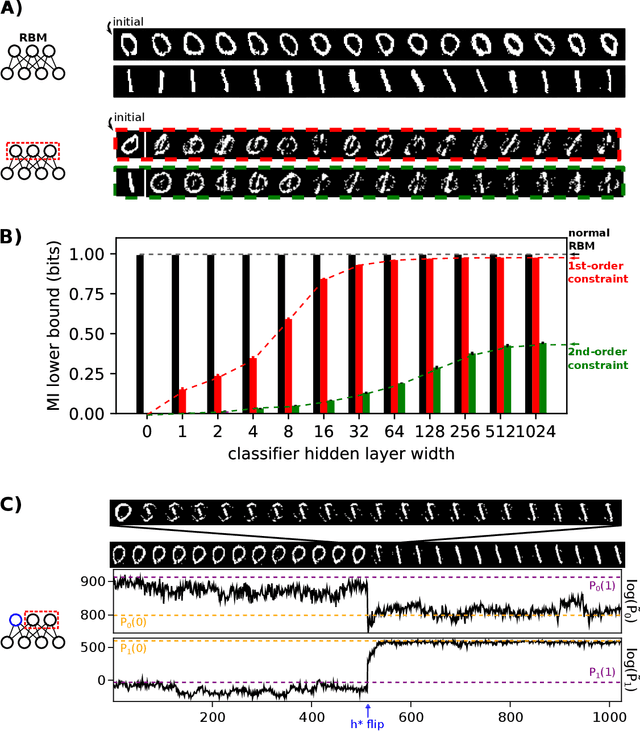
A goal of unsupervised machine learning is to disentangle representations of complex high-dimensional data, allowing for interpreting the significant latent factors of variation in the data as well as for manipulating them to generate new data with desirable features. These methods often rely on an adversarial scheme, in which representations are tuned to avoid discriminators from being able to reconstruct specific data information (labels). We propose a simple, effective way of disentangling representations without any need to train adversarial discriminators, and apply our approach to Restricted Boltzmann Machines (RBM), one of the simplest representation-based generative models. Our approach relies on the introduction of adequate constraints on the weights during training, which allows us to concentrate information about labels on a small subset of latent variables. The effectiveness of the approach is illustrated on the MNIST dataset, the two-dimensional Ising model, and taxonomy of protein families. In addition, we show how our framework allows for computing the cost, in terms of log-likelihood of the data, associated to the disentanglement of their representations.
On the robustness of self-supervised representations for multi-view object classification
Jul 27, 2022
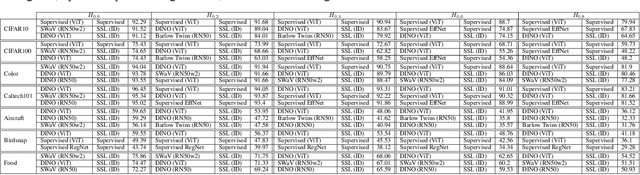
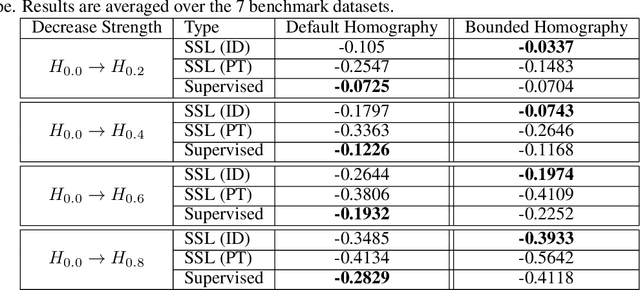
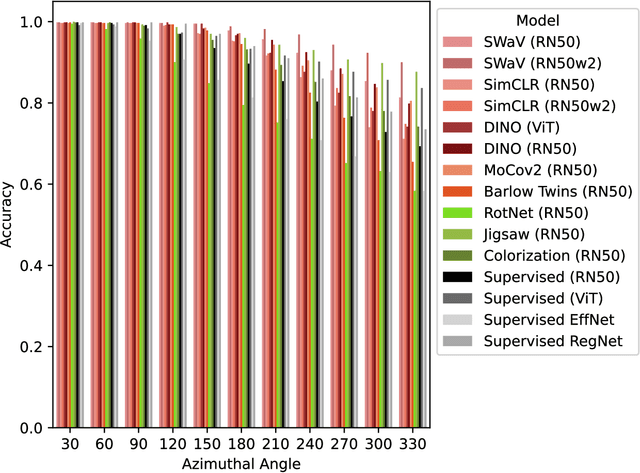
It is known that representations from self-supervised pre-training can perform on par, and often better, on various downstream tasks than representations from fully-supervised pre-training. This has been shown in a host of settings such as generic object classification and detection, semantic segmentation, and image retrieval. However, some issues have recently come to the fore that demonstrate some of the failure modes of self-supervised representations, such as performance on non-ImageNet-like data, or complex scenes. In this paper, we show that self-supervised representations based on the instance discrimination objective lead to better representations of objects that are more robust to changes in the viewpoint and perspective of the object. We perform experiments of modern self-supervised methods against multiple supervised baselines to demonstrate this, including approximating object viewpoint variation through homographies, and real-world tests based on several multi-view datasets. We find that self-supervised representations are more robust to object viewpoint and appear to encode more pertinent information about objects that facilitate the recognition of objects from novel views.
Using Deep Learning to Detecting Deepfakes
Jul 27, 2022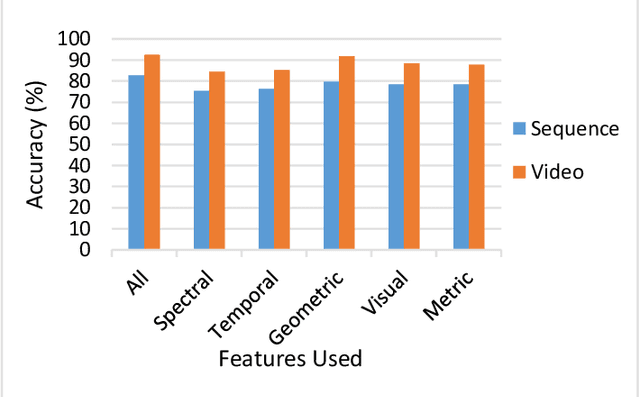
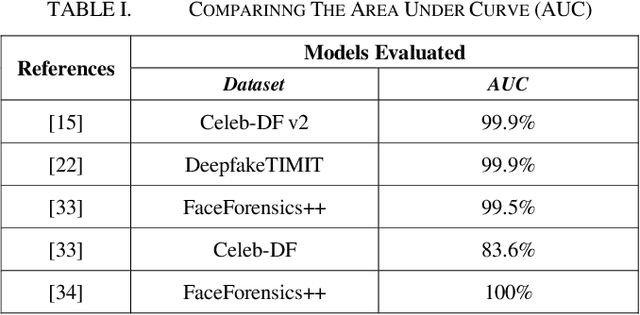
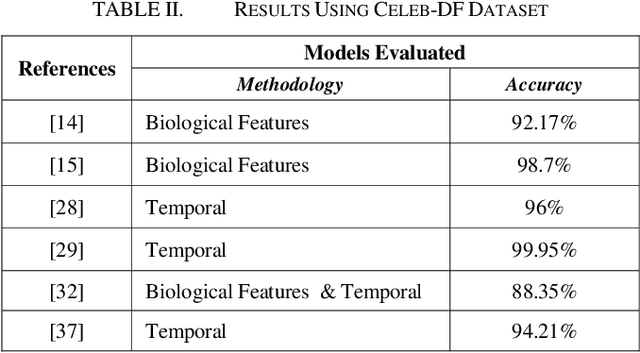
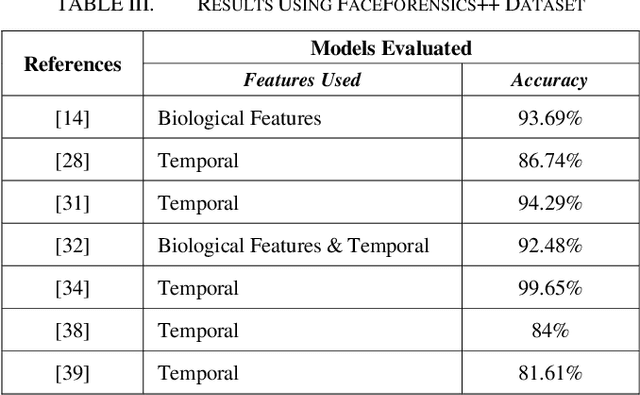
In the recent years, social media has grown to become a major source of information for many online users. This has given rise to the spread of misinformation through deepfakes. Deepfakes are videos or images that replace one persons face with another computer-generated face, often a more recognizable person in society. With the recent advances in technology, a person with little technological experience can generate these videos. This enables them to mimic a power figure in society, such as a president or celebrity, creating the potential danger of spreading misinformation and other nefarious uses of deepfakes. To combat this online threat, researchers have developed models that are designed to detect deepfakes. This study looks at various deepfake detection models that use deep learning algorithms to combat this looming threat. This survey focuses on providing a comprehensive overview of the current state of deepfake detection models and the unique approaches many researchers take to solving this problem. The benefits, limitations, and suggestions for future work will be thoroughly discussed throughout this paper.