 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Deep Learning to Detecting Deepfakes
Jul 27, 2022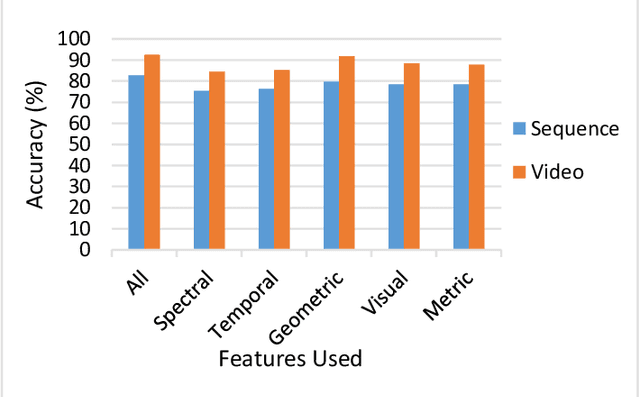
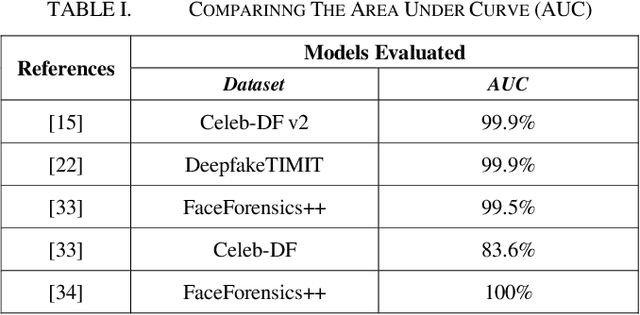
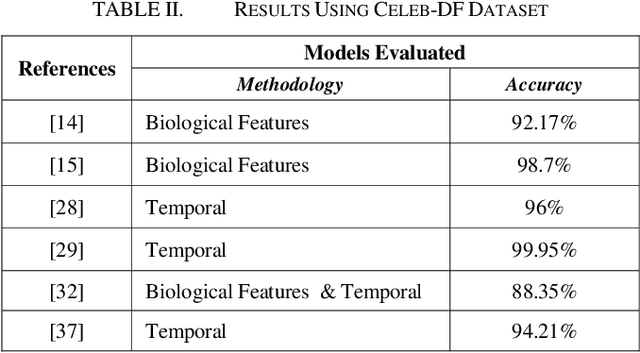
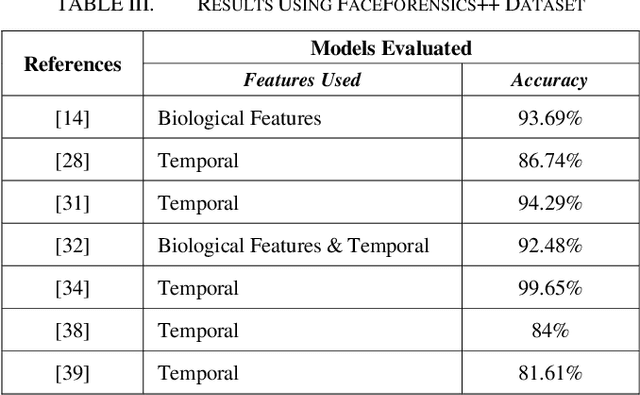
In the recent years, social media has grown to become a major source of information for many online users. This has given rise to the spread of misinformation through deepfakes. Deepfakes are videos or images that replace one persons face with another computer-generated face, often a more recognizable person in society. With the recent advances in technology, a person with little technological experience can generate these videos. This enables them to mimic a power figure in society, such as a president or celebrity, creating the potential danger of spreading misinformation and other nefarious uses of deepfakes. To combat this online threat, researchers have developed models that are designed to detect deepfakes. This study looks at various deepfake detection models that use deep learning algorithms to combat this looming threat. This survey focuses on providing a comprehensive overview of the current state of deepfake detection models and the unique approaches many researchers take to solving this problem. The benefits, limitations, and suggestions for future work will be thoroughly discussed throughout this paper.
Machine and Deep Learning Applications to Mouse Dynamics for Continuous User Authentication
May 26, 2022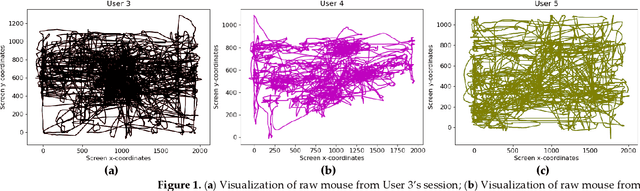
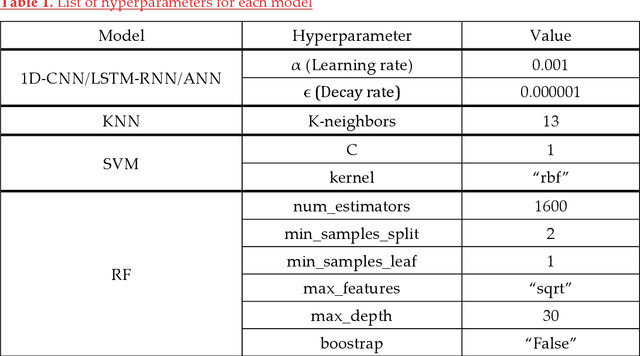
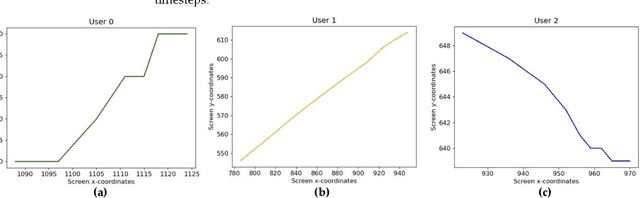
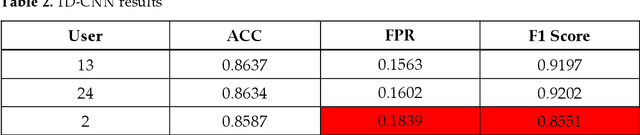
Static authentication methods, like passwords, grow increasingly weak with advancements in technology and attack strategies. Continuous authentication has been proposed as a solution, in which users who have gained access to an account are still monitored in order to continuously verify that the user is not an imposter who had access to the user credentials. Mouse dynamics is the behavior of a users mouse movements and is a biometric that has shown great promise for continuous authentication schemes. This article builds upon our previous published work by evaluating our dataset of 40 users using three machine learning and deep learning algorithms. Two evaluation scenarios are considered: binary classifiers are used for user authentication, with the top performer being a 1-dimensional convolutional neural network with a peak average test accuracy of 85.73% across the top 10 users. Multi class classification is also examined using an artificial neural network which reaches an astounding peak accuracy of 92.48% the highest accuracy we have seen for any classifier on this dataset.
Evaluation of a User Authentication Schema Using Behavioral Biometrics and Machine Learning
May 07, 2022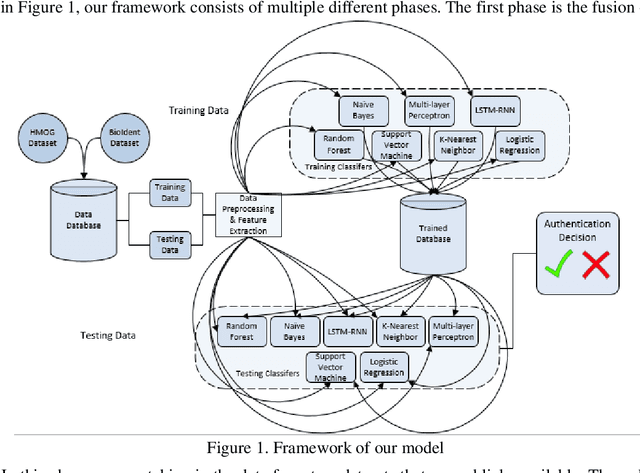
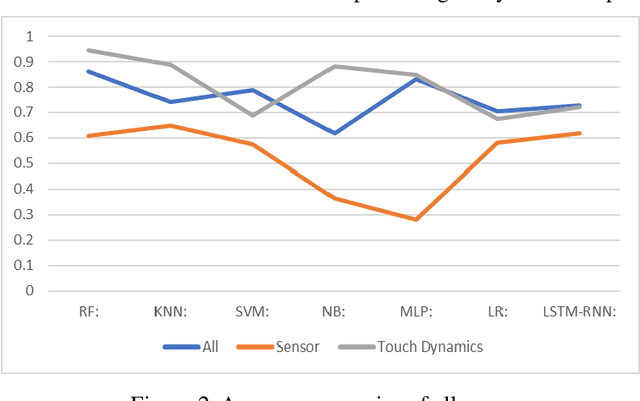
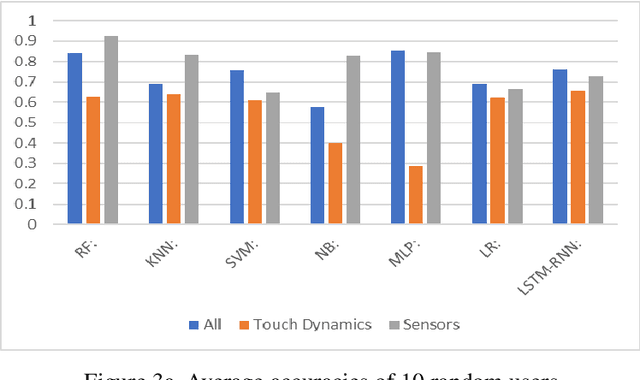
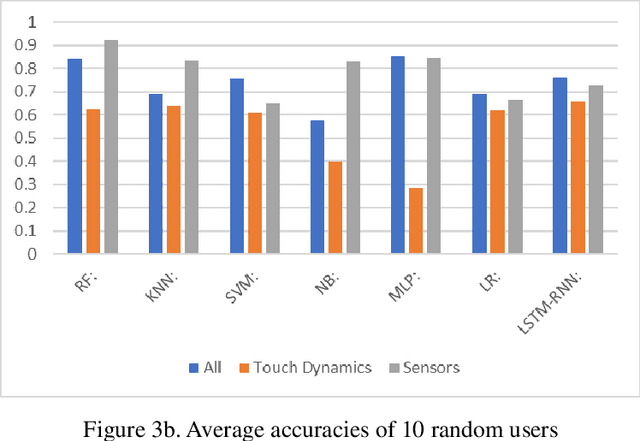
The amount of secure data being stored on mobile devices has grown immensely in recent years. However, the security measures protecting this data have stayed static, with few improvements being done to the vulnerabilities of current authentication methods such as physiological biometrics or passwords. Instead of these methods, behavioral biometrics has recently been researched as a solution to these vulnerable authentication methods. In this study, we aim to contribute to the research being done on behavioral biometrics by creating and evaluating a user authentication scheme using behavioral biometrics. The behavioral biometrics used in this study include touch dynamics and phone movement, and we evaluate the performance of different single-modal and multi-modal combinations of the two biometrics. Using two publicly available datasets - BioIdent and Hand Movement Orientation and Grasp (H-MOG), this study uses seven common machine learning algorithms to evaluate performance. The algorithms used in the evaluation include Random Forest, Support Vector Machine, K-Nearest Neighbor, Naive Bayes, Logistic Regression, Multilayer Perceptron, and Long Short-Term Memory Recurrent Neural Networks, with accuracy rates reaching as high as 86%.
A Close Look into Human Activity Recognition Models using Deep Learning
Apr 26, 2022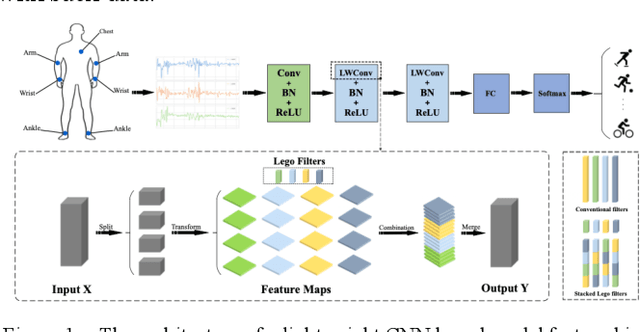
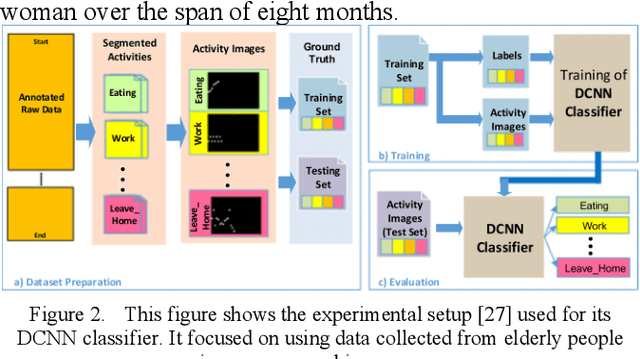
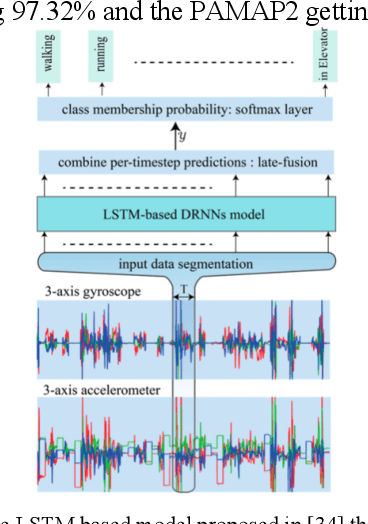
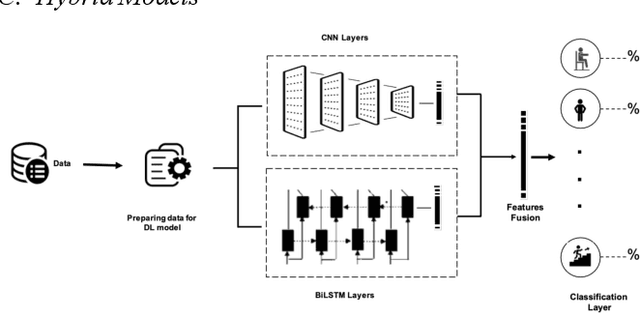
Human activity recognition using deep learning techniques has become increasing popular because of its high effectivity with recognizing complex tasks, as well as being relatively low in costs compared to more traditional machine learning techniques. This paper surveys some state-of-the-art human activity recognition models that are based on deep learning architecture and has layers containing Convolution Neural Networks (CNN), Long Short-Term Memory (LSTM), or a mix of more than one type for a hybrid system. The analysis outlines how the models are implemented to maximize its effectivity and some of the potential limitations it faces.
Human Activity Recognition models using Limited Consumer Device Sensors and Machine Learning
Jan 21, 2022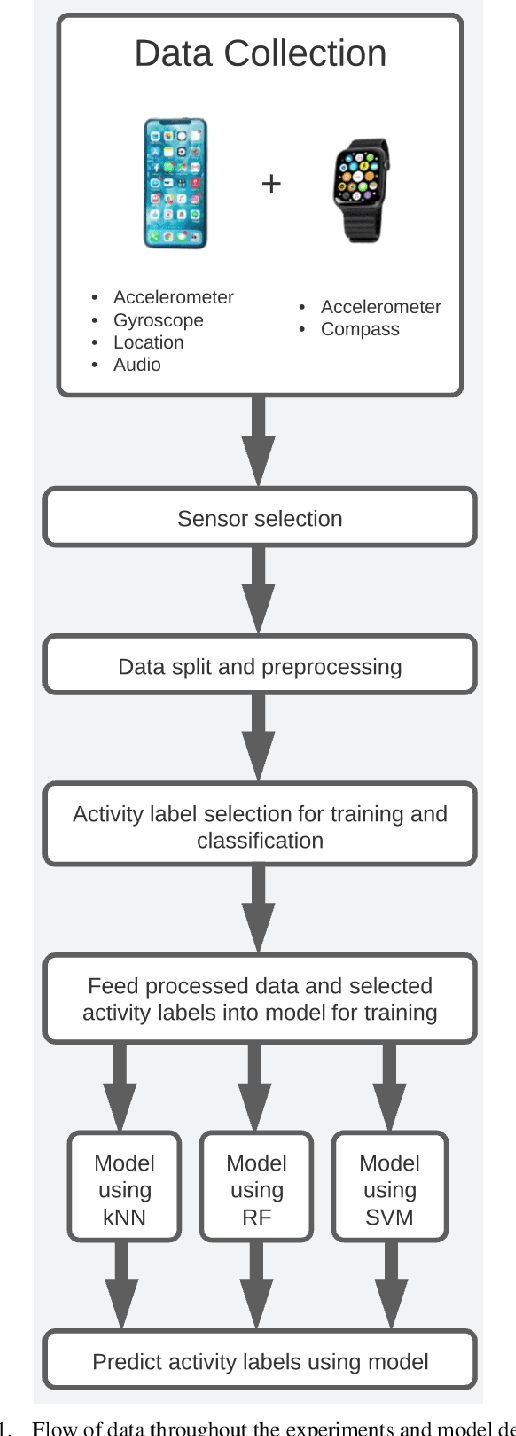
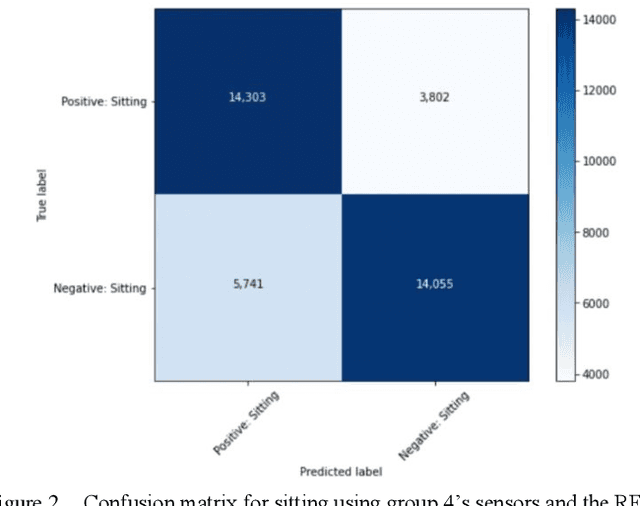
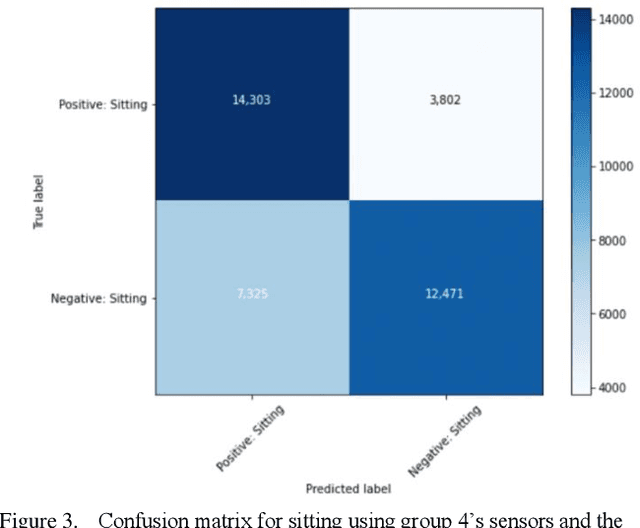
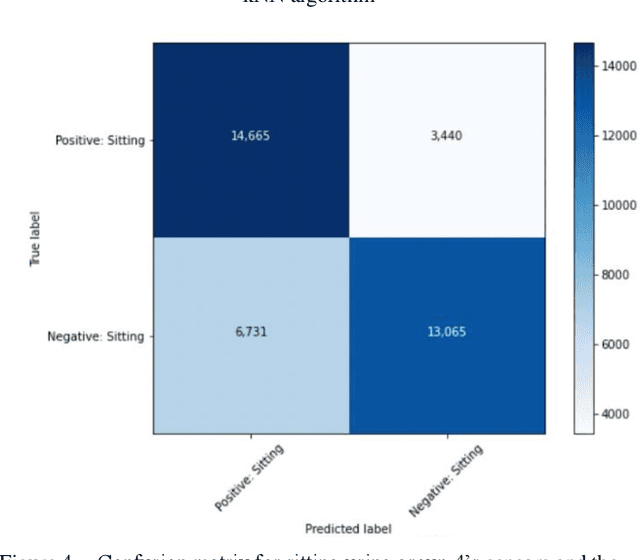
Human activity recognition has grown in popularity with its increase of applications within daily lifestyles and medical environments. The goal of having efficient and reliable human activity recognition brings benefits such as accessible use and better allocation of resources; especially in the medical industry. Activity recognition and classification can be obtained using many sophisticated data recording setups, but there is also a need in observing how performance varies among models that are strictly limited to using sensor data from easily accessible devices: smartphones and smartwatches. This paper presents the findings of different models that are limited to train using such sensors. The models are trained using either the k-Nearest Neighbor, Support Vector Machine, or Random Forest classifier algorithms. Performance and evaluations are done by comparing various model performances using different combinations of mobile sensors and how they affect recognitive performances of models. Results show promise for models trained strictly using limited sensor data collected from only smartphones and smartwatches coupled with traditional machine learning concepts and algorithms.
Hold On and Swipe: A Touch-Movement Based Continuous Authentication Schema based on Machine Learning
Jan 21, 2022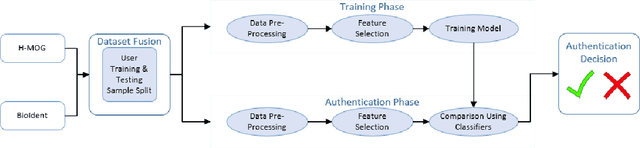
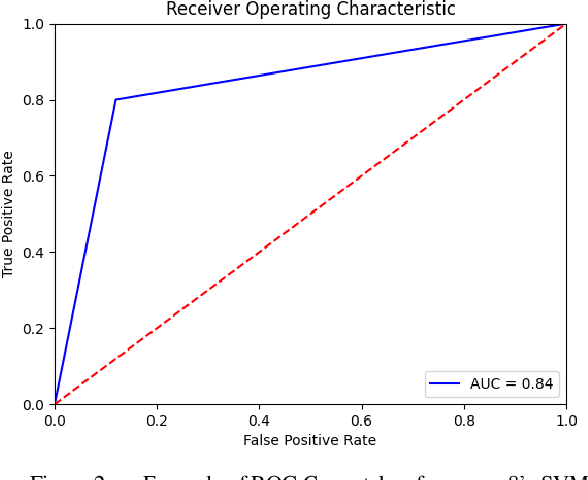
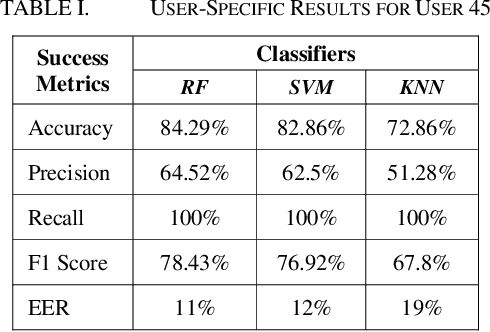
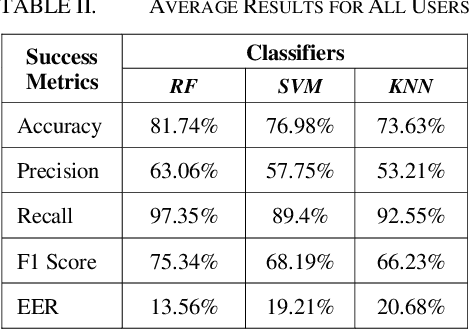
In recent years the amount of secure information being stored on mobile devices has grown exponentially. However, current security schemas for mobile devices such as physiological biometrics and passwords are not secure enough to protect this information. Behavioral biometrics have been heavily researched as a possible solution to this security deficiency for mobile devices. This study aims to contribute to this innovative research by evaluating the performance of a multimodal behavioral biometric based user authentication scheme using touch dynamics and phone movement. This study uses a fusion of two popular publicly available datasets the Hand Movement Orientation and Grasp dataset and the BioIdent dataset. This study evaluates our model performance using three common machine learning algorithms which are Random Forest Support Vector Machine and K-Nearest Neighbor reaching accuracy rates as high as 82% with each algorithm performing respectively for all success metrics reported.
A Modern Analysis of Aging Machine Learning Based IoT Cybersecurity Methods
Oct 15, 2021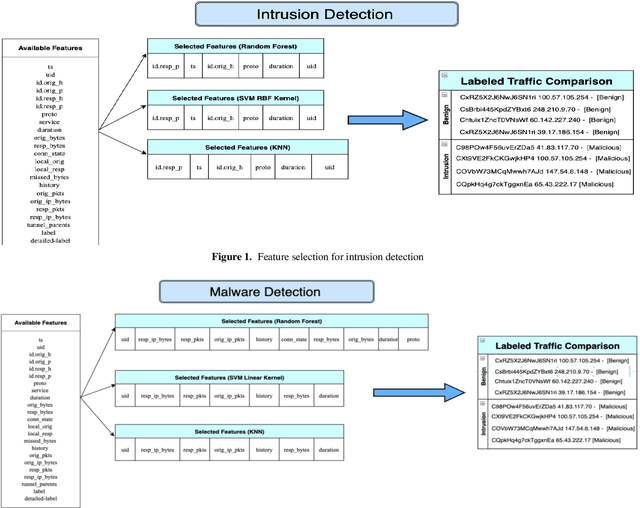
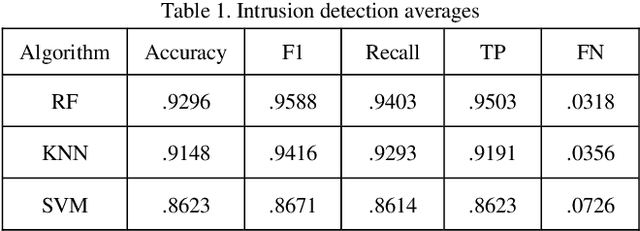
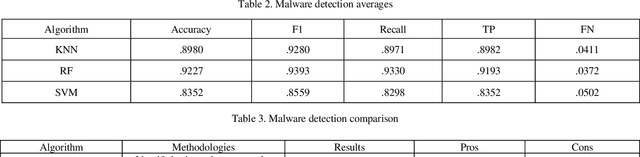
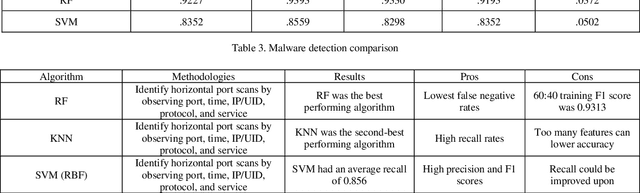
Modern scientific advancements often contribute to the introduction and refinement of never-before-seen technologies. This can be quite the task for humans to maintain and monitor and as a result, our society has become reliant on machine learning to assist in this task. With new technology comes new methods and thus new ways to circumvent existing cyber security measures. This study examines the effectiveness of three distinct Internet of Things cyber security algorithms currently used in industry today for malware and intrusion detection: Random Forest (RF), Support-Vector Machine (SVM), and K-Nearest Neighbor (KNN). Each algorithm was trained and tested on the Aposemat IoT-23 dataset which was published in January 2020 with the earliest of captures from 2018 and latest from 2019. The RF, SVM, and KNN reached peak accuracies of 92.96%, 86.23%, and 91.48%, respectively, in intrusion detection and 92.27%, 83.52%, and 89.80% in malware detection. It was found all three algorithms are capable of being effectively utilized for the current landscape of IoT cyber security in 2021.
Named Entity Recognition in Unstructured Medical Text Documents
Oct 15, 2021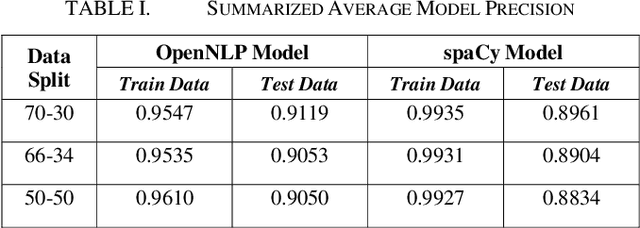
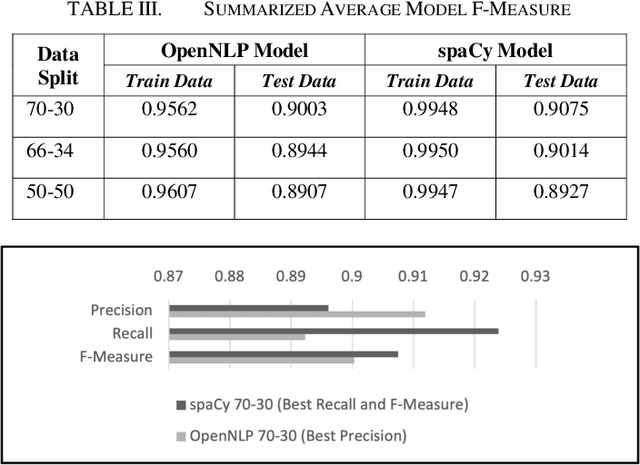
Physicians provide expert opinion to legal courts on the medical state of patients, including determining if a patient is likely to have permanent or non-permanent injuries or ailments. An independent medical examination (IME) report summarizes a physicians medical opinion about a patients health status based on the physicians expertise. IME reports contain private and sensitive information (Personally Identifiable Information or PII) that needs to be removed or randomly encoded before further research work can be conducted. In our study the IME is an orthopedic surgeon from a private practice in the United States. The goal of this research is to perform named entity recognition (NER) to identify and subsequently remove/encode PII information from IME reports prepared by the physician. We apply the NER toolkits of OpenNLP and spaCy, two freely available natural language processing platforms, and compare their precision, recall, and f-measure performance at identifying five categories of PII across trials of randomly selected IME reports using each models common default parameters. We find that both platforms achieve high performance (f-measure > 0.9) at de-identification and that a spaCy model trained with a 70-30 train-test data split is most performant.
Continuous Authentication Using Mouse Movements, Machine Learning, and Minecraft
Oct 15, 2021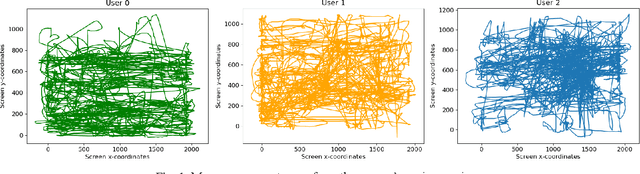
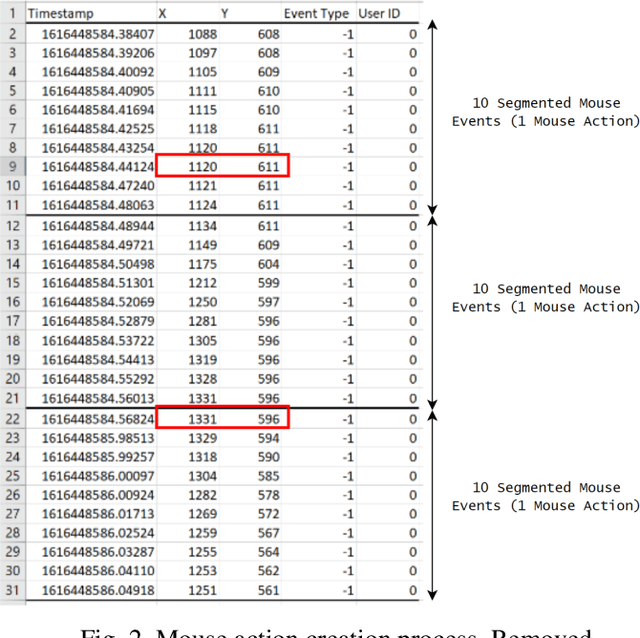
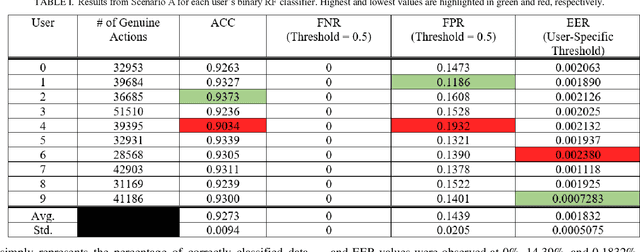
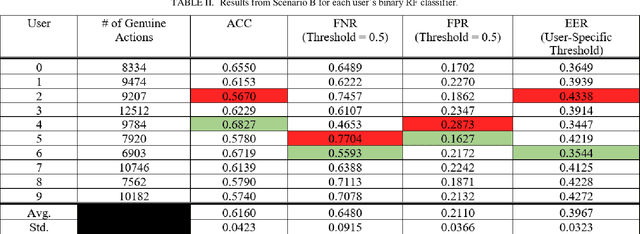
Mouse dynamics has grown in popularity as a novel irreproducible behavioral biometric. Datasets which contain general unrestricted mouse movements from users are sparse in the current literature. The Balabit mouse dynamics dataset produced in 2016 was made for a data science competition and despite some of its shortcomings, is considered to be the first publicly available mouse dynamics dataset. Collecting mouse movements in a dull administrative manner as Balabit does may unintentionally homogenize data and is also not representative of realworld application scenarios. This paper presents a novel mouse dynamics dataset that has been collected while 10 users play the video game Minecraft on a desktop computer. Binary Random Forest (RF) classifiers are created for each user to detect differences between a specific users movements and an imposters movements. Two evaluation scenarios are proposed to evaluate the performance of these classifiers; one scenario outperformed previous works in all evaluation metrics, reaching average accuracy rates of 92%, while the other scenario successfully reported reduced instances of false authentications of imposters.
Machine Learning: Challenges, Limitations, and Compatibility for Audio Restoration Processes
Sep 06, 2021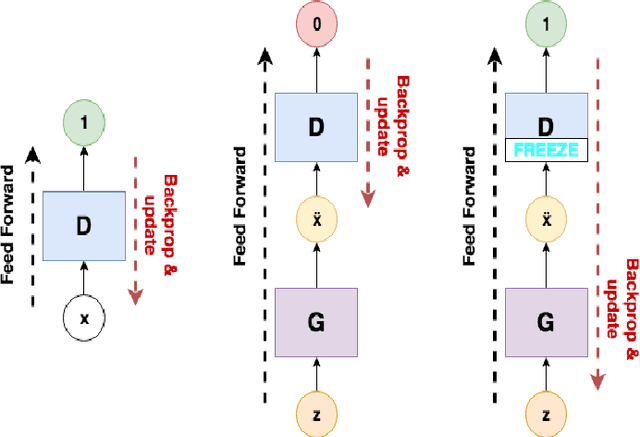
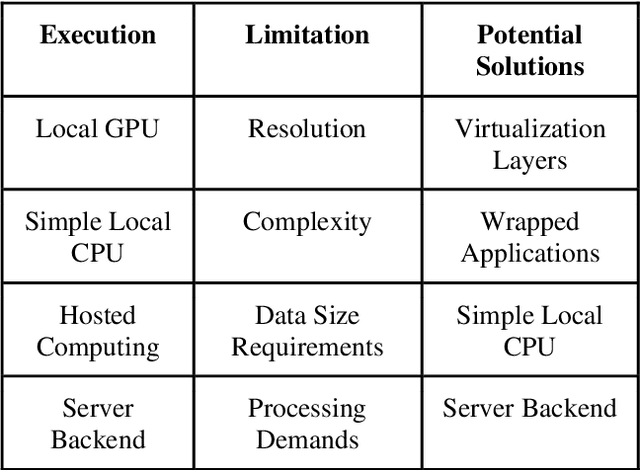
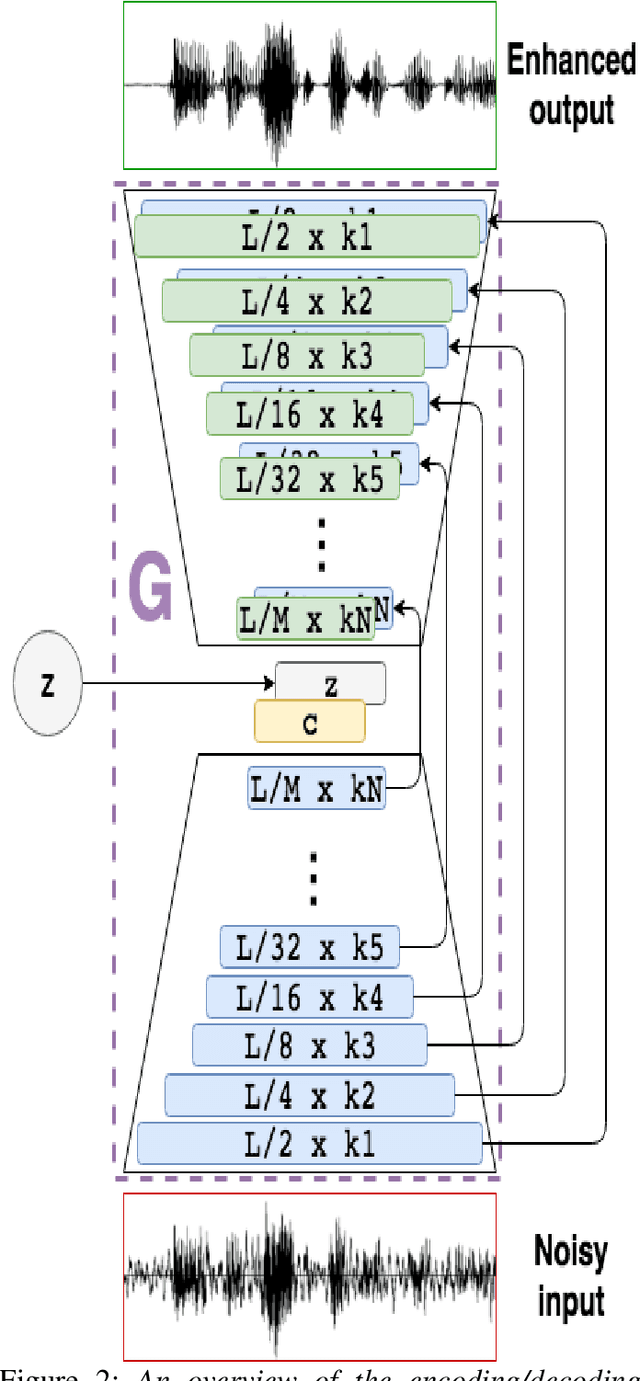
In this paper machine learning networks are explored for their use in restoring degraded and compressed speech audio. The project intent is to build a new trained model from voice data to learn features of compression artifacting distortion introduced by data loss from lossy compression and resolution loss with an existing algorithm presented in SEGAN: Speech Enhancement Generative Adversarial Network. The resulting generator from the model was then to be used to restore degraded speech audio. This paper details an examination of the subsequent compatibility and operational issues presented by working with deprecated code, which obstructed the trained model from successfully being developed. This paper further serves as an examination of the challenges, limitations, and compatibility in the current state of machine learning.