 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PowerSkel: A Device-Free Framework Using CSI Signal for Human Skeleton Estimation in Power Station
Mar 04, 2024

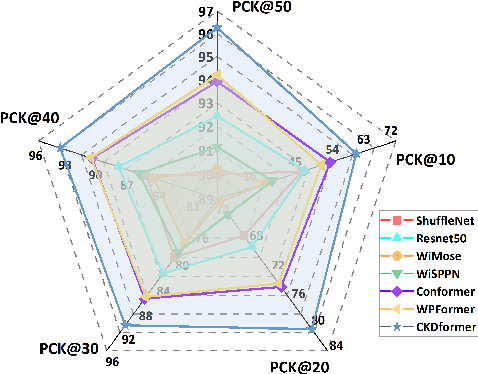
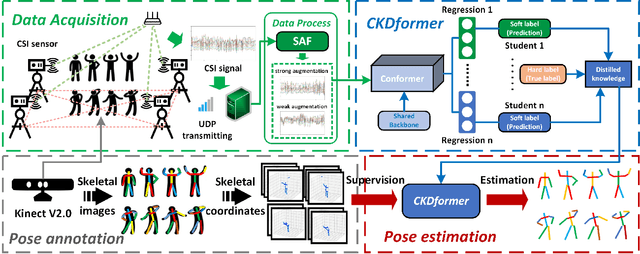
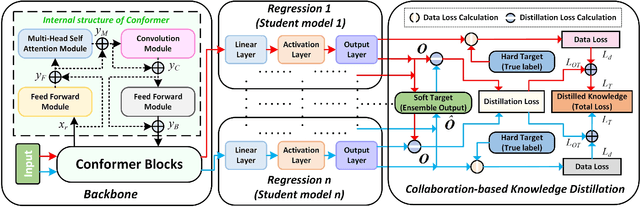
Safety monitoring of power operations in power stations is crucial for preventing accidents and ensuring stable power supply. However, conventional methods such as wearable devices and video surveillance have limitations such as high cost, dependence on light, and visual blind spots. WiFi-based human pose estimation is a suitable method for monitoring power operations due to its low cost, device-free, and robustness to various illumination conditions.In this paper, a novel Channel State Information (CSI)-based pose estimation framework, namely PowerSkel, is developed to address these challenges. PowerSkel utilizes self-developed CSI sensors to form a mutual sensing network and constructs a CSI acquisition scheme specialized for power scenarios. It significantly reduces the deployment cost and complexity compared to the existing solutions. To reduce interference with CSI in the electricity scenario, a sparse adaptive filtering algorithm is designed to preprocess the CSI. CKDformer, a knowledge distillation network based on collaborative learning and self-attention, is proposed to extract the features from CSI and establish the mapping relationship between CSI and keypoints. The experiments are conducted in a real-world power station, and the results show that the PowerSkel achieves high performance with a PCK@50 of 96.27%, and realizes a significant visualization on pose estimation, even in dark environments. Our work provides a novel low-cost and high-precision pose estimation solution for power operation.
SMAUG: A Sliding Multidimensional Task Window-Based MARL Framework for Adaptive Real-Time Subtask Recognition
Mar 04, 2024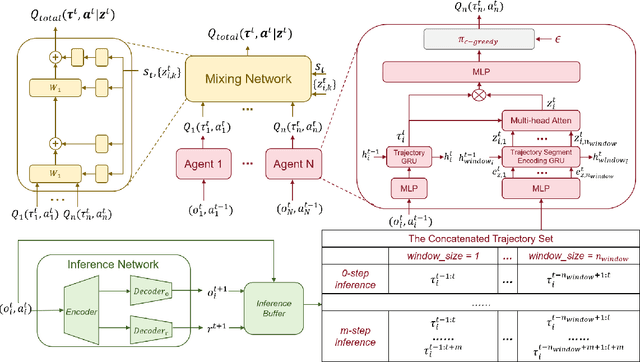
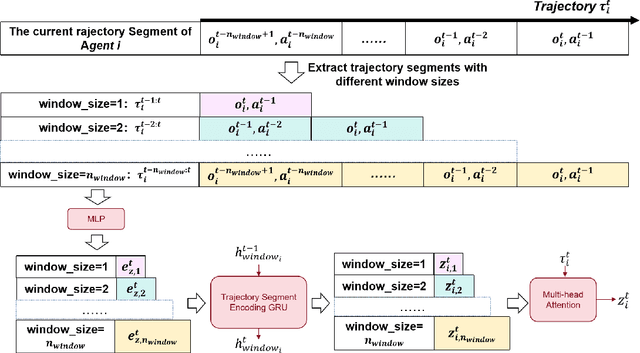
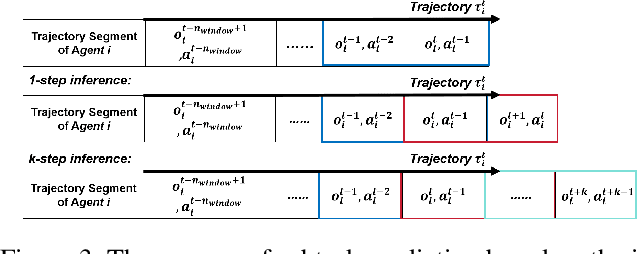
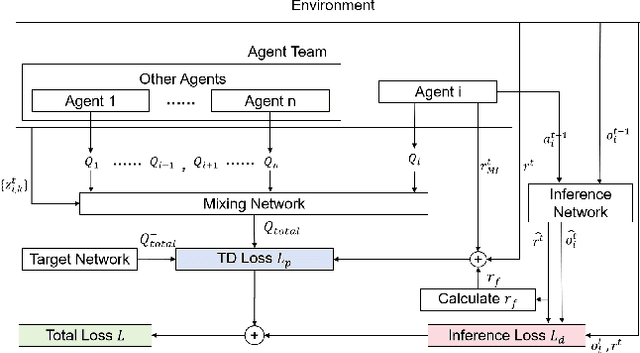
Instead of making behavioral decisions directly from the exponentially expanding joint observational-action space, subtask-based multi-agent reinforcement learning (MARL) methods enable agents to learn how to tackle different subtasks. Most existing subtask-based MARL methods are based on hierarchical reinforcement learning (HRL). However, these approaches often limit the number of subtasks, perform subtask recognition periodically, and can only identify and execute a specific subtask within the predefined fixed time period, which makes them inflexible and not suitable for diverse and dynamic scenarios with constantly changing subtasks. To break through above restrictions, a \textbf{S}liding \textbf{M}ultidimensional t\textbf{A}sk window based m\textbf{U}ti-agent reinforcement learnin\textbf{G} framework (SMAUG) is proposed for adaptive real-time subtask recognition. It leverages a sliding multidimensional task window to extract essential information of subtasks from trajectory segments concatenated based on observed and predicted trajectories in varying lengths. An inference network is designed to iteratively predict future trajectories with the subtask-oriented policy network. Furthermore, intrinsic motivation rewards are defined to promote subtask exploration and behavior diversity. SMAUG can be integrated with any Q-learning-based approach. Experiments on StarCraft II show that SMAUG not only demonstrates performance superiority in comparison with all baselines but also presents a more prominent and swift rise in rewards during the initial training stage.
Neural Network Assisted Lifting Steps For Improved Fully Scalable Lossy Image Compression in JPEG 2000
Mar 04, 2024
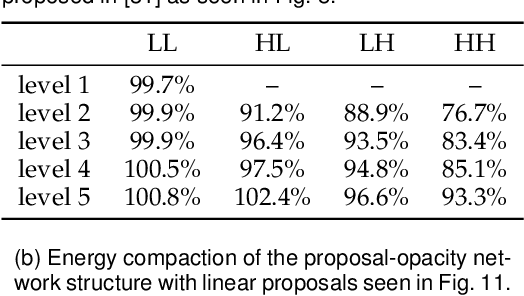
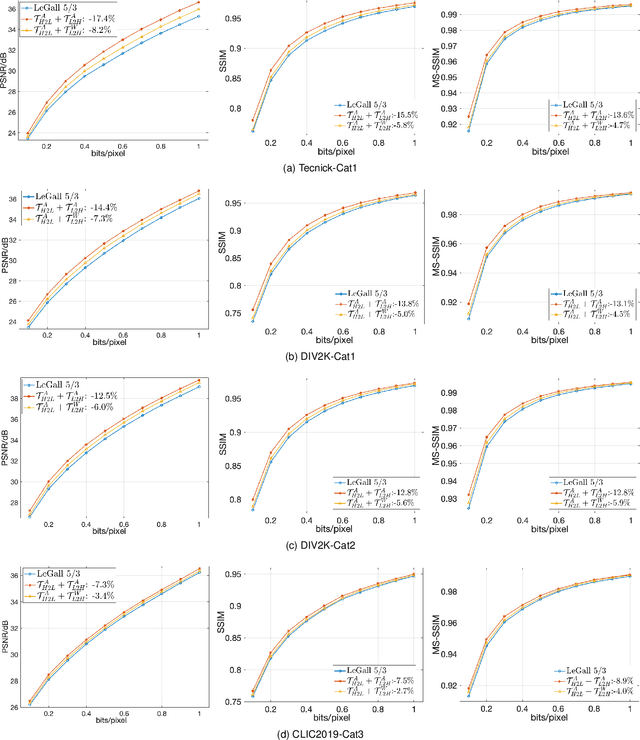
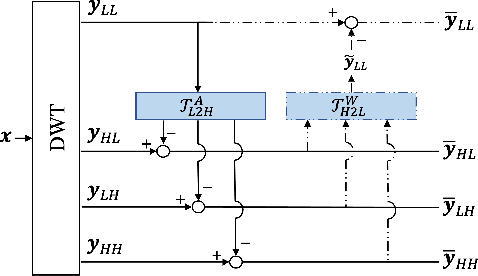
This work proposes to augment the lifting steps of the conventional wavelet transform with additional neural network assisted lifting steps. These additional steps reduce residual redundancy (notably aliasing information) amongst the wavelet subbands, and also improve the visual quality of reconstructed images at reduced resolutions. The proposed approach involves two steps, a high-to-low step followed by a low-to-high step. The high-to-low step suppresses aliasing in the low-pass band by using the detail bands at the same resolution, while the low-to-high step aims to further remove redundancy from detail bands, so as to achieve higher energy compaction. The proposed two lifting steps are trained in an end-to-end fashion; we employ a backward annealing approach to overcome the non-differentiability of the quantization and cost functions during back-propagation. Importantly, the networks employed in this paper are compact and with limited non-linearities, allowing a fully scalable system; one pair of trained network parameters are applied for all levels of decomposition and for all bit-rates of interest. By employing the proposed approach within the JPEG 2000 image coding standard, our method can achieve up to 17.4% average BD bit-rate saving over a wide range of bit-rates, while retaining quality and resolution scalability features of JPEG 2000.
Entity-Aware Multimodal Alignment Framework for News Image Captioning
Feb 29, 2024News image captioning task is a variant of image captioning task which requires model to generate a more informative caption with news image and the associated news article. Multimodal Large Language models have developed rapidly in recent years and is promising in news image captioning task. However, according to our experiments, common MLLMs are not good at generating the entities in zero-shot setting. Their abilities to deal with the entities information are still limited after simply fine-tuned on news image captioning dataset. To obtain a more powerful model to handle the multimodal entity information, we design two multimodal entity-aware alignment tasks and an alignment framework to align the model and generate the news image captions. Our method achieves better results than previous state-of-the-art models in CIDEr score (72.33 -> 86.29) on GoodNews dataset and (70.83 -> 85.61) on NYTimes800k dataset.
NiteDR: Nighttime Image De-Raining with Cross-View Sensor Cooperative Learning for Dynamic Driving Scenes
Feb 28, 2024In real-world environments, outdoor imaging systems are often affected by disturbances such as rain degradation. Especially, in nighttime driving scenes, insufficient and uneven lighting shrouds the scenes in darkness, resulting degradation of both the image quality and visibility. Particularly, in the field of autonomous driving, the visual perception ability of RGB sensors experiences a sharp decline in such harsh scenarios. Additionally, driving assistance systems suffer from reduced capabilities in capturing and discerning the surrounding environment, posing a threat to driving safety. Single-view information captured by single-modal sensors cannot comprehensively depict the entire scene. To address these challenges, we developed an image de-raining framework tailored for rainy nighttime driving scenes. It aims to remove rain artifacts, enrich scene representation, and restore useful information. Specifically, we introduce cooperative learning between visible and infrared images captured by different sensors. By cross-view fusion of these multi-source data, the scene within the images gains richer texture details and enhanced contrast. We constructed an information cleaning module called CleanNet as the first stage of our framework. Moreover, we designed an information fusion module called FusionNet as the second stage to fuse the clean visible images with infrared images. Using this stage-by-stage learning strategy, we obtain de-rained fusion images with higher quality and better visual perception. Extensive experiments demonstrate the effectiveness of our proposed Cross-View Cooperative Learning (CVCL) in adverse driving scenarios in low-light rainy environments. The proposed approach addresses the gap in the utilization of existing rain removal algorithms in specific low-light conditions.
RoadRunner -- Learning Traversability Estimation for Autonomous Off-road Driving
Feb 29, 2024Autonomous navigation at high speeds in off-road environments necessitates robots to comprehensively understand their surroundings using onboard sensing only. The extreme conditions posed by the off-road setting can cause degraded camera image quality due to poor lighting and motion blur, as well as limited sparse geometric information available from LiDAR sensing when driving at high speeds. In this work, we present RoadRunner, a novel framework capable of predicting terrain traversability and an elevation map directly from camera and LiDAR sensor inputs. RoadRunner enables reliable autonomous navigation, by fusing sensory information, handling of uncertainty, and generation of contextually informed predictions about the geometry and traversability of the terrain while operating at low latency. In contrast to existing methods relying on classifying handcrafted semantic classes and using heuristics to predict traversability costs, our method is trained end-to-end in a self-supervised fashion. The RoadRunner network architecture builds upon popular sensor fusion network architectures from the autonomous driving domain, which embed LiDAR and camera information into a common Bird's Eye View perspective. Training is enabled by utilizing an existing traversability estimation stack to generate training data in hindsight in a scalable manner from real-world off-road driving datasets. Furthermore, RoadRunner improves the system latency by a factor of roughly 4, from 500 ms to 140 ms, while improving the accuracy for traversability costs and elevation map predictions. We demonstrate the effectiveness of RoadRunner in enabling safe and reliable off-road navigation at high speeds in multiple real-world driving scenarios through unstructured desert environments.
Greed is All You Need: An Evaluation of Tokenizer Inference Methods
Mar 02, 2024
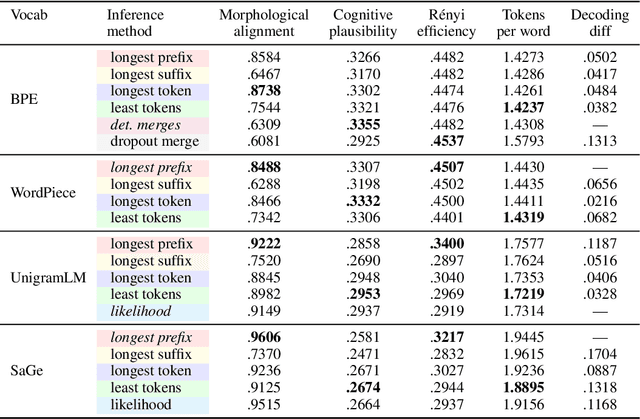
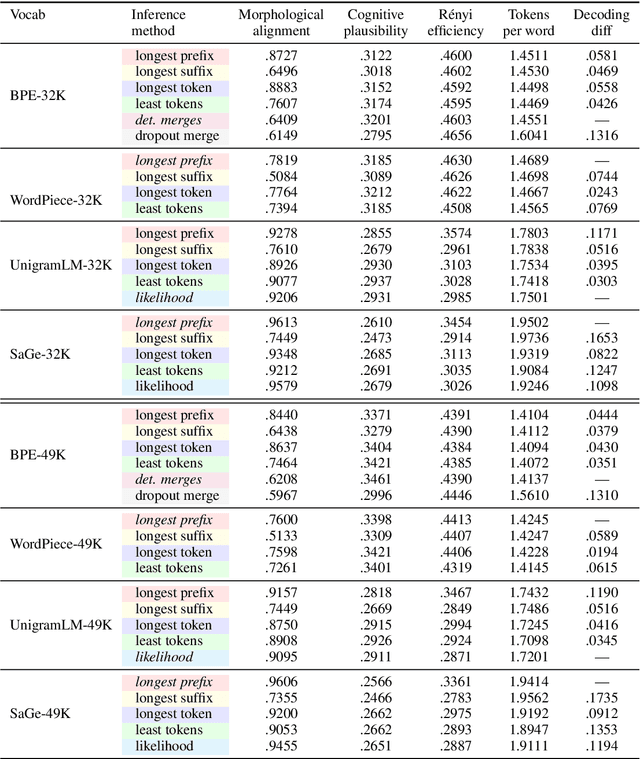
While subword tokenizers such as BPE and WordPiece are typically used to build vocabularies for NLP models, the method of decoding text into a sequence of tokens from these vocabularies is often left unspecified, or ill-suited to the method in which they were constructed. We provide a controlled analysis of seven tokenizer inference methods across four different algorithms and three vocabulary sizes, performed on a novel intrinsic evaluation suite we curated for English, combining measures rooted in morphology, cognition, and information theory. We show that for the most commonly used tokenizers, greedy inference performs surprisingly well; and that SaGe, a recently-introduced contextually-informed tokenizer, outperforms all others on morphological alignment.
The Information of Large Language Model Geometry
Feb 01, 2024This paper investigates the information encoded in the embeddings of large language models (LLMs). We conduct simulations to analyze the representation entropy and discover a power law relationship with model sizes. Building upon this observation, we propose a theory based on (conditional) entropy to elucidate the scaling law phenomenon. Furthermore, we delve into the auto-regressive structure of LLMs and examine the relationship between the last token and previous context tokens using information theory and regression techniques. Specifically, we establish a theoretical connection between the information gain of new tokens and ridge regression. Additionally, we explore the effectiveness of Lasso regression in selecting meaningful tokens, which sometimes outperforms the closely related attention weights. Finally, we conduct controlled experiments, and find that information is distributed across tokens, rather than being concentrated in specific "meaningful" tokens alone.
Multi-Fidelity Residual Neural Processes for Scalable Surrogate Modeling
Feb 29, 2024Multi-fidelity surrogate modeling aims to learn an accurate surrogate at the highest fidelity level by combining data from multiple sources. Traditional methods relying on Gaussian processes can hardly scale to high-dimensional data. Deep learning approaches utilize neural network based encoders and decoders to improve scalability. These approaches share encoded representations across fidelities without including corresponding decoder parameters. At the highest fidelity, the representations are decoded with different parameters, making the shared information inherently inaccurate. This hinders inference performance, especially in out-of-distribution scenarios when the highest fidelity data has limited domain coverage. To address these limitations, we propose Multi-fidelity Residual Neural Processes (MFRNP), a novel multi-fidelity surrogate modeling framework. MFRNP optimizes lower fidelity decoders for accurate information sharing by aggregating lower fidelity surrogate outputs and models residual between the aggregation and ground truth on the highest fidelity. We show that MFRNP significantly outperforms current state-of-the-art in learning partial differential equations and a real-world climate modeling task.
Evaluating Webcam-based Gaze Data as an Alternative for Human Rationale Annotations
Feb 29, 2024Rationales in the form of manually annotated input spans usually serve as ground truth when evaluating explainability methods in NLP. They are, however, time-consuming and often biased by the annotation process. In this paper, we debate whether human gaze, in the form of webcam-based eye-tracking recordings, poses a valid alternative when evaluating importance scores. We evaluate the additional information provided by gaze data, such as total reading times, gaze entropy, and decoding accuracy with respect to human rationale annotations. We compare WebQAmGaze, a multilingual dataset for information-seeking QA, with attention and explainability-based importance scores for 4 different multilingual Transformer-based language models (mBERT, distil-mBERT, XLMR, and XLMR-L) and 3 languages (English, Spanish, and German). Our pipeline can easily be applied to other tasks and languages. Our findings suggest that gaze data offers valuable linguistic insights that could be leveraged to infer task difficulty and further show a comparable ranking of explainability methods to that of human rationales.