 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildOS: Open-Vocabulary Object Search in the Wild
Feb 22, 2026Autonomous navigation in complex, unstructured outdoor environments requires robots to operate over long ranges without prior maps and limited depth sensing. In such settings, relying solely on geometric frontiers for exploration is often insufficient. In such settings, the ability to reason semantically about where to go and what is safe to traverse is crucial for robust, efficient exploration. This work presents WildOS, a unified system for long-range, open-vocabulary object search that combines safe geometric exploration with semantic visual reasoning. WildOS builds a sparse navigation graph to maintain spatial memory, while utilizing a foundation-model-based vision module, ExploRFM, to score frontier nodes of the graph. ExploRFM simultaneously predicts traversability, visual frontiers, and object similarity in image space, enabling real-time, onboard semantic navigation tasks. The resulting vision-scored graph enables the robot to explore semantically meaningful directions while ensuring geometric safety. Furthermore, we introduce a particle-filter-based method for coarse localization of the open-vocabulary target query, that estimates candidate goal positions beyond the robot's immediate depth horizon, enabling effective planning toward distant goals. Extensive closed-loop field experiments across diverse off-road and urban terrains demonstrate that WildOS enables robust navigation, significantly outperforming purely geometric and purely vision-based baselines in both efficiency and autonomy. Our results highlight the potential of vision foundation models to drive open-world robotic behaviors that are both semantically informed and geometrically grounded. Project Page: https://leggedrobotics.github.io/wildos/
COARSE: Collaborative Pseudo-Labeling with Coarse Real Labels for Off-Road Semantic Segmentation
Mar 05, 2025



Autonomous off-road navigation faces challenges due to diverse, unstructured environments, requiring robust perception with both geometric and semantic understanding. However, scarce densely labeled semantic data limits generalization across domains. Simulated data helps, but introduces domain adaptation issues. We propose COARSE, a semi-supervised domain adaptation framework for off-road semantic segmentation, leveraging sparse, coarse in-domain labels and densely labeled out-of-domain data. Using pretrained vision transformers, we bridge domain gaps with complementary pixel-level and patch-level decoders, enhanced by a collaborative pseudo-labeling strategy on unlabeled data. Evaluations on RUGD and Rellis-3D datasets show significant improvements of 9.7\% and 8.4\% respectively, versus only using coarse data. Tests on real-world off-road vehicle data in a multi-biome setting further demonstrate COARSE's applicability.
Few-shot Semantic Learning for Robust Multi-Biome 3D Semantic Mapping in Off-Road Environments
Nov 10, 2024



Off-road environments pose significant perception challenges for high-speed autonomous navigation due to unstructured terrain, degraded sensing conditions, and domain-shifts among biomes. Learning semantic information across these conditions and biomes can be challenging when a large amount of ground truth data is required. In this work, we propose an approach that leverages a pre-trained Vision Transformer (ViT) with fine-tuning on a small (<500 images), sparse and coarsely labeled (<30% pixels) multi-biome dataset to predict 2D semantic segmentation classes. These classes are fused over time via a novel range-based metric and aggregated into a 3D semantic voxel map. We demonstrate zero-shot out-of-biome 2D semantic segmentation on the Yamaha (52.9 mIoU) and Rellis (55.5 mIoU) datasets along with few-shot coarse sparse labeling with existing data for improved segmentation performance on Yamaha (66.6 mIoU) and Rellis (67.2 mIoU). We further illustrate the feasibility of using a voxel map with a range-based semantic fusion approach to handle common off-road hazards like pop-up hazards, overhangs, and water features.
RoadRunner M&M -- Learning Multi-range Multi-resolution Traversability Maps for Autonomous Off-road Navigation
Sep 17, 2024Autonomous robot navigation in off-road environments requires a comprehensive understanding of the terrain geometry and traversability. The degraded perceptual conditions and sparse geometric information at longer ranges make the problem challenging especially when driving at high speeds. Furthermore, the sensing-to-mapping latency and the look-ahead map range can limit the maximum speed of the vehicle. Building on top of the recent work RoadRunner, in this work, we address the challenge of long-range (100 m) traversability estimation. Our RoadRunner (M&M) is an end-to-end learning-based framework that directly predicts the traversability and elevation maps at multiple ranges (50 m, 100 m) and resolutions (0.2 m, 0.8 m) taking as input multiple images and a LiDAR voxel map. Our method is trained in a self-supervised manner by leveraging the dense supervision signal generated by fusing predictions from an existing traversability estimation stack (X-Racer) in hindsight and satellite Digital Elevation Maps. RoadRunner M&M achieves a significant improvement of up to 50% for elevation mapping and 30% for traversability estimation over RoadRunner, and is able to predict in 30% more regions compared to X-Racer while achieving real-time performance. Experiments on various out-of-distribution datasets also demonstrate that our data-driven approach starts to generalize to novel unstructured environments. We integrate our proposed framework in closed-loop with the path planner to demonstrate autonomous high-speed off-road robotic navigation in challenging real-world environments. Project Page: https://leggedrobotics.github.io/roadrunner_mm/
ShadowNav: Autonomous Global Localization for Lunar Navigation in Darkness
May 06, 2024The ability to determine the pose of a rover in an inertial frame autonomously is a crucial capability necessary for the next generation of surface rover missions on other planetary bodies. Currently, most on-going rover missions utilize ground-in-the-loop interventions to manually correct for drift in the pose estimate and this human supervision bottlenecks the distance over which rovers can operate autonomously and carry out scientific measurements. In this paper, we present ShadowNav, an autonomous approach for global localization on the Moon with an emphasis on driving in darkness and at nighttime. Our approach uses the leading edge of Lunar craters as landmarks and a particle filtering approach is used to associate detected craters with known ones on an offboard map. We discuss the key design decisions in developing the ShadowNav framework for use with a Lunar rover concept equipped with a stereo camera and an external illumination source. Finally, we demonstrate the efficacy of our proposed approach in both a Lunar simulation environment and on data collected during a field test at Cinder Lakes, Arizona.
RoadRunner - Learning Traversability Estimation for Autonomous Off-road Driving
Mar 03, 2024



Autonomous navigation at high speeds in off-road environments necessitates robots to comprehensively understand their surroundings using onboard sensing only. The extreme conditions posed by the off-road setting can cause degraded camera image quality due to poor lighting and motion blur, as well as limited sparse geometric information available from LiDAR sensing when driving at high speeds. In this work, we present RoadRunner, a novel framework capable of predicting terrain traversability and an elevation map directly from camera and LiDAR sensor inputs. RoadRunner enables reliable autonomous navigation, by fusing sensory information, handling of uncertainty, and generation of contextually informed predictions about the geometry and traversability of the terrain while operating at low latency. In contrast to existing methods relying on classifying handcrafted semantic classes and using heuristics to predict traversability costs, our method is trained end-to-end in a self-supervised fashion. The RoadRunner network architecture builds upon popular sensor fusion network architectures from the autonomous driving domain, which embed LiDAR and camera information into a common Bird's Eye View perspective. Training is enabled by utilizing an existing traversability estimation stack to generate training data in hindsight in a scalable manner from real-world off-road driving datasets. Furthermore, RoadRunner improves the system latency by a factor of roughly 4, from 500 ms to 140 ms, while improving the accuracy for traversability costs and elevation map predictions. We demonstrate the effectiveness of RoadRunner in enabling safe and reliable off-road navigation at high speeds in multiple real-world driving scenarios through unstructured desert environments.
ShadowNav: Crater-Based Localization for Nighttime and Permanently Shadowed Region Lunar Navigation
Jan 11, 2023



There has been an increase in interest in missions that drive significantly longer distances per day than what has currently been performed. Further, some of these proposed missions require autonomous driving and absolute localization in darkness. For example, the Endurance A mission proposes to drive 1200km of its total traverse at night. The lack of natural light available during such missions limits what can be used as visual landmarks and the range at which landmarks can be observed. In order for planetary rovers to traverse long ranges, onboard absolute localization is critical to the ability of the rover to maintain its planned trajectory and avoid known hazardous regions. Currently, to accomplish absolute localization, a ground in the loop (GITL) operation is performed wherein a human operator matches local maps or images from onboard with orbital images and maps. This GITL operation limits the distance that can be driven in a day to a few hundred meters, which is the distance that the rover can maintain acceptable localization error via relative methods. Previous work has shown that using craters as landmarks is a promising approach for performing absolute localization on the moon during the day. In this work we present a method of absolute localization that utilizes craters as landmarks and matches detected crater edges on the surface with known craters in orbital maps. We focus on a localization method based on a perception system which has an external illuminator and a stereo camera. We evaluate (1) both monocular and stereo based surface crater edge detection techniques, (2) methods of scoring the crater edge matches for optimal localization, and (3) localization performance on simulated Lunar surface imagery at night. We demonstrate that this technique shows promise for maintaining absolute localization error of less than 10m required for most planetary rover missions.
Self-Supervised Traversability Prediction by Learning to Reconstruct Safe Terrain
Aug 02, 2022
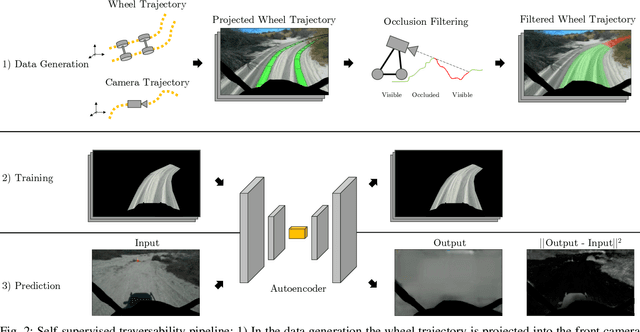


Navigating off-road with a fast autonomous vehicle depends on a robust perception system that differentiates traversable from non-traversable terrain. Typically, this depends on a semantic understanding which is based on supervised learning from images annotated by a human expert. This requires a significant investment in human time, assumes correct expert classification, and small details can lead to misclassification. To address these challenges, we propose a method for predicting high- and low-risk terrains from only past vehicle experience in a self-supervised fashion. First, we develop a tool that projects the vehicle trajectory into the front camera image. Second, occlusions in the 3D representation of the terrain are filtered out. Third, an autoencoder trained on masked vehicle trajectory regions identifies low- and high-risk terrains based on the reconstruction error. We evaluated our approach with two models and different bottleneck sizes with two different training and testing sites with a fourwheeled off-road vehicle. Comparison with two independent test sets of semantic labels from similar terrain as training sites demonstrates the ability to separate the ground as low-risk and the vegetation as high-risk with 81.1% and 85.1% accuracy.
Lunar Rover Localization Using Craters as Landmarks
Mar 18, 2022

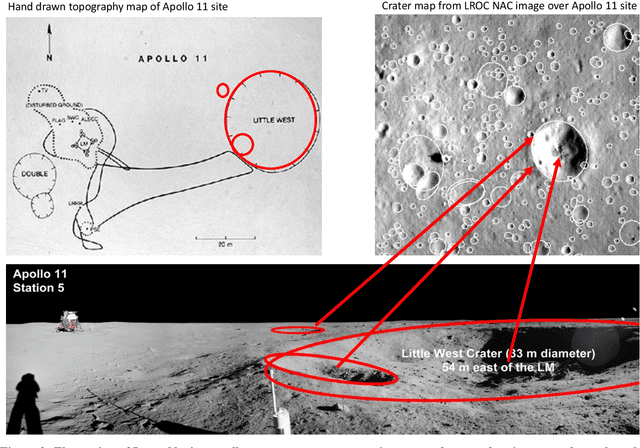
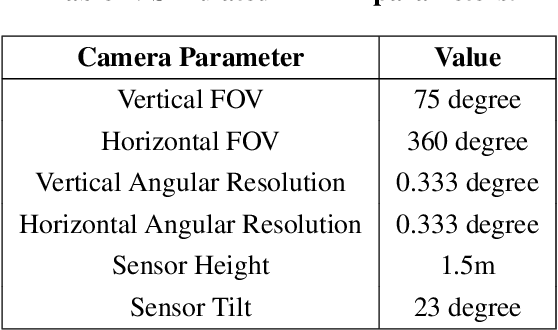
Onboard localization capabilities for planetary rovers to date have used relative navigation, by integrating combinations of wheel odometry, visual odometry, and inertial measurements during each drive to track position relative to the start of each drive. At the end of each drive, a ground-in-the-loop (GITL) interaction is used to get a position update from human operators in a more global reference frame, by matching images or local maps from onboard the rover to orbital reconnaissance images or maps of a large region around the rover's current position. Autonomous rover drives are limited in distance so that accumulated relative navigation error does not risk the possibility of the rover driving into hazards known from orbital images. However, several rover mission concepts have recently been studied that require much longer drives between GITL cycles, particularly for the Moon. These concepts require greater autonomy to minimize GITL cycles to enable such large range; onboard global localization is a key element of such autonomy. Multiple techniques have been studied in the past for onboard rover global localization, but a satisfactory solution has not yet emerged. For the Moon, the ubiquitous craters offer a new possibility, which involves mapping craters from orbit, then recognizing crater landmarks with cameras and-or a lidar onboard the rover. This approach is applicable everywhere on the Moon, does not require high resolution stereo imaging from orbit as some other approaches do, and has potential to enable position knowledge with order of 5 to 10 m accuracy at all times. This paper describes our technical approach to crater-based lunar rover localization and presents initial results on crater detection using 3D point cloud data from onboard lidar or stereo cameras, as well as using shading cues in monocular onboard imagery.