 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInside the LLM Word Factory
Jun 07, 2026Transformer language models process input provided as subword fragments, but natural language semantics usually rely on word-level concepts. Detokenization is the process where models reconcile these two facts, aggregating subwords into word-level representations through their computation. Prior work has found that this takes place mostly in early-to-middle layers, but so far the exact mechanics of the process have not been pinned down. We venture deep into detokenization using activation patching in controlled paired experiments that isolate the contribution of different model components, localizing English detokenization in Llama2-7B to a two-stage process at Layer 1. Attention transmits a token-specific signal from nonfinal subwords, using sequential relays if necessary, while the MLP composes it with the local embedding. This two-stage structure generalizes to twelve models from eight families, but the depth over which it takes place depends on the flavor of positional encoding: RoPE-based models detokenize over 1 to 5 layers, while learned-absolute models take 5 to 10. Finally, we provide a probe for determining the success of the detokenization process based on early-layer activations alone, performing at 0.94-0.97 AUROC depending on the amount of context.
Tokenization with Split Trees
May 21, 2026We introduce Tokenization with Split Trees (ToaST), a subword tokenization method that directly optimizes compression under a new recursive inference procedure. ToaST greedily splits each pretoken into a full binary tree using precomputed byte n-gram counts, independent of any vocabulary. Given a vocabulary, inference recursively descends each split tree and emits the first in-vocabulary node reached on each path. Vocabulary selection is formulated as an Integer Program (IP) that minimizes the total token count over all split trees under this inference procedure. The Linear Programming (LP) relaxation is near-integral in practice, yielding provably near-optimal vocabularies, with training time empirically scaling quadratically in the number of split trees. On English text, ToaST reduces token counts by more than 11% compared to BPE, WordPiece, and UnigramLM at vocabulary sizes of 40,960 and above, reducing the number of inference tokens for models using this tokenizer, thus extending the effective context length. ToaST also uses common single-byte tokens less frequently than these baselines, leading to a substantial improvement in Renyi efficiency. In experiments training 1.5B parameter language models, ToaST achieves the highest CORE score, outperforming baselines by 2.6%--7.6%, with significance for two of three, and scoring best on 13 of 22 individual tasks.
Universal NER v2: Towards a Massively Multilingual Named Entity Recognition Benchmark
Apr 14, 2026While multilingual language models promise to bring the benefits of LLMs to speakers of many languages, gold-standard evaluation benchmarks in most languages to interrogate these assumptions remain scarce. The Universal NER project, now entering its fourth year, is dedicated to building gold-standard multilingual Named Entity Recognition (NER) benchmark datasets. Inspired by existing massively multilingual efforts for other core NLP tasks (e.g., Universal Dependencies), the project uses a general tagset and thorough annotation guidelines to collect standardized, cross-lingual annotations of named entity spans. The first installment (UNER v1) was released in 2024, and the project has continued and expanded since then, with various organizers, annotators, and collaborators in an active community.
Faster Superword Tokenization
Apr 06, 2026Byte Pair Encoding (BPE) is a widely used tokenization algorithm, whose tokens cannot extend across pre-tokenization boundaries, functionally limiting it to representing at most full words. The BoundlessBPE and SuperBPE algorithms extend and improve BPE by relaxing this limitation and allowing the formation of superwords, which are combinations of pretokens that form phrases. However, previous implementations were impractical to train: for example, BoundlessBPE took 4.7 CPU days to train on 1GB of data. We show that supermerge candidates, two or more consecutive pretokens eligible to form a supermerge, can be aggregated by frequency much like regular pretokens. This avoids keeping full documents in memory, as the original implementations of BoundlessBPE and SuperBPE required, leading to a significant training speedup. We present a two-phase formulation of BoundlessBPE that separates first-phase learning of regular merges from second-phase learning of supermerges, producing identical results to the original implementation. We also show a near-equivalence between two-phase BoundlessBPE and SuperBPE, with the difference being that a manually selected hyperparameter used in SuperBPE can be automatically determined in the second phase of BoundlessBPE. These changes enable a much faster implementation, allowing training on that same 1GB of data in 603 and 593 seconds for BoundlessBPE and SuperBPE, respectively, a more than 600x increase in speed. For each of BoundlessBPE, SuperBPE, and BPE, we open-source both a reference Python implementation and a fast Rust implementation.
The Degree of Language Diacriticity and Its Effect on Tasks
Mar 29, 2026Diacritics are orthographic marks that clarify pronunciation, distinguish similar words, or alter meaning. They play a central role in many writing systems, yet their impact on language technology has not been systematically quantified across scripts. While prior work has examined diacritics in individual languages, there's no cross-linguistic, data-driven framework for measuring the degree to which writing systems rely on them and how this affects downstream tasks. We propose a data-driven framework for quantifying diacritic complexity using corpus-level, information-theoretic metrics that capture the frequency, ambiguity, and structural diversity of character-diacritic combinations. We compute these metrics over 24 corpora in 15 languages, spanning both single- and multi-diacritic scripts. We then examine how diacritic complexity correlates with performance on the task of diacritics restoration, evaluating BERT- and RNN-based models. We find that across languages, higher diacritic complexity is strongly associated with lower restoration accuracy. In single-diacritic scripts, where character-diacritic combinations are more predictable, frequency-based and structural measures largely align. In multi-diacritic scripts, however, structural complexity exhibits the strongest association with performance, surpassing frequency-based measures. These findings show that measurable properties of diacritic usage influence the performance of diacritic restoration models, demonstrating that orthographic complexity is not only descriptive but functionally relevant for modeling.
The Effect of Scripts and Formats on LLM Numeracy
Jan 21, 2026Large language models (LLMs) have achieved impressive proficiency in basic arithmetic, rivaling human-level performance on standard numerical tasks. However, little attention has been given to how these models perform when numerical expressions deviate from the prevailing conventions present in their training corpora. In this work, we investigate numerical reasoning across a wide range of numeral scripts and formats. We show that LLM accuracy drops substantially when numerical inputs are rendered in underrepresented scripts or formats, despite the underlying mathematical reasoning being identical. We further demonstrate that targeted prompting strategies, such as few-shot prompting and explicit numeral mapping, can greatly narrow this gap. Our findings highlight an overlooked challenge in multilingual numerical reasoning and provide actionable insights for working with LLMs to reliably interpret, manipulate, and generate numbers across diverse numeral scripts and formatting styles.
Which Pieces Does Unigram Tokenization Really Need?
Dec 14, 2025
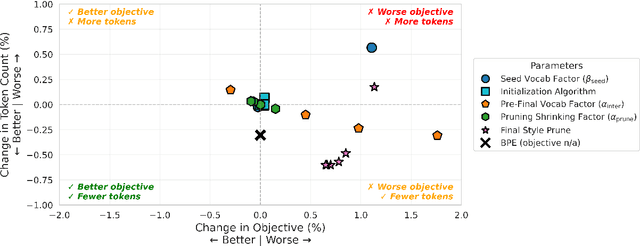
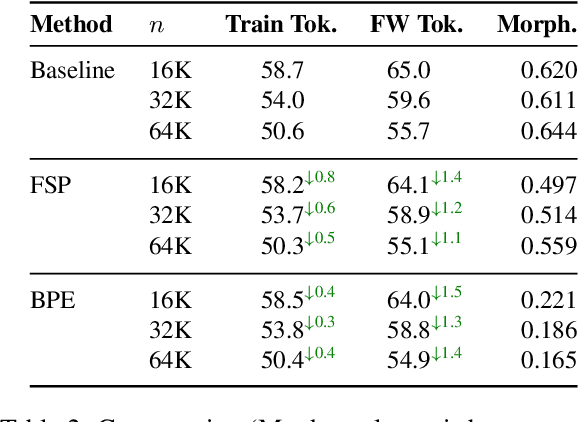
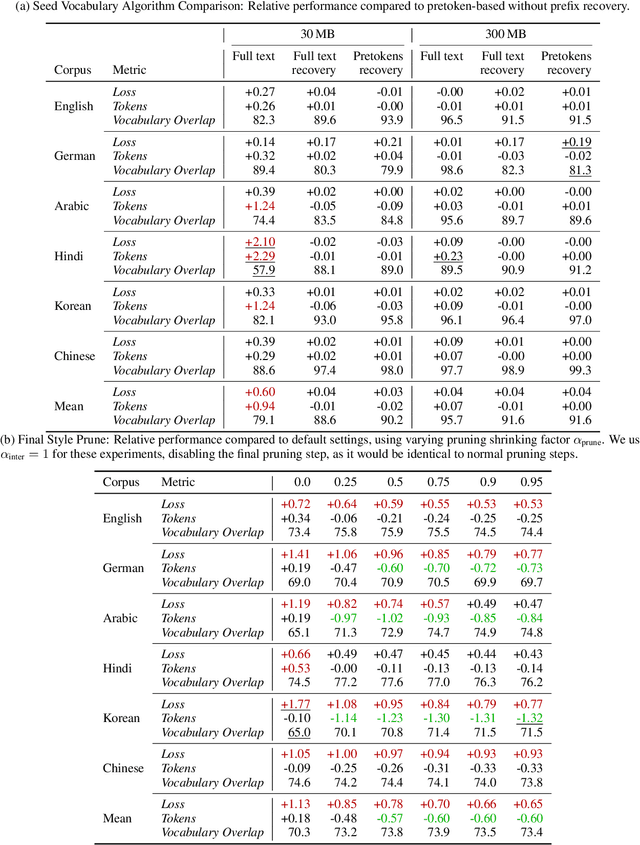
The Unigram tokenization algorithm offers a probabilistic alternative to the greedy heuristics of Byte-Pair Encoding. Despite its theoretical elegance, its implementation in practice is complex, limiting its adoption to the SentencePiece package and adapters thereof. We bridge this gap between theory and practice by providing a clear guide to implementation and parameter choices. We also identify a simpler algorithm that accepts slightly higher training loss in exchange for improved compression.
Hebrew Diacritics Restoration using Visual Representation
Oct 30, 2025Diacritics restoration in Hebrew is a fundamental task for ensuring accurate word pronunciation and disambiguating textual meaning. Despite the language's high degree of ambiguity when unvocalized, recent machine learning approaches have significantly advanced performance on this task. In this work, we present DIVRIT, a novel system for Hebrew diacritization that frames the task as a zero-shot classification problem. Our approach operates at the word level, selecting the most appropriate diacritization pattern for each undiacritized word from a dynamically generated candidate set, conditioned on the surrounding textual context. A key innovation of DIVRIT is its use of a Hebrew Visual Language Model, which processes undiacritized text as an image, allowing diacritic information to be embedded directly within the input's vector representation. Through a comprehensive evaluation across various configurations, we demonstrate that the system effectively performs diacritization without relying on complex, explicit linguistic analysis. Notably, in an ``oracle'' setting where the correct diacritized form is guaranteed to be among the provided candidates, DIVRIT achieves a high level of accuracy. Furthermore, strategic architectural enhancements and optimized training methodologies yield significant improvements in the system's overall generalization capabilities. These findings highlight the promising potential of visual representations for accurate and automated Hebrew diacritization.
Probing Subphonemes in Morphology Models
May 16, 2025Transformers have achieved state-of-the-art performance in morphological inflection tasks, yet their ability to generalize across languages and morphological rules remains limited. One possible explanation for this behavior can be the degree to which these models are able to capture implicit phenomena at the phonological and subphonemic levels. We introduce a language-agnostic probing method to investigate phonological feature encoding in transformers trained directly on phonemes, and perform it across seven morphologically diverse languages. We show that phonological features which are local, such as final-obstruent devoicing in Turkish, are captured well in phoneme embeddings, whereas long-distance dependencies like vowel harmony are better represented in the transformer's encoder. Finally, we discuss how these findings inform empirical strategies for training morphological models, particularly regarding the role of subphonemic feature acquisition.
Boundless Byte Pair Encoding: Breaking the Pre-tokenization Barrier
Mar 31, 2025Pre-tokenization, the initial step in many modern tokenization pipelines, segments text into smaller units called pretokens, typically splitting on whitespace and punctuation. While this process encourages having full, individual words as tokens, it introduces a fundamental limitation in most tokenization algorithms such as Byte Pair Encoding (BPE). Specifically, pre-tokenization causes the distribution of tokens in a corpus to heavily skew towards common, full-length words. This skewed distribution limits the benefits of expanding to larger vocabularies, since the additional tokens appear with progressively lower counts. To overcome this barrier, we propose BoundlessBPE, a modified BPE algorithm that relaxes the pretoken boundary constraint. Our approach selectively merges two complete pretokens into a larger unit we term a superword. Superwords are not necessarily semantically cohesive. For example, the pretokens " of" and " the" might be combined to form the superword " of the". This merging strategy results in a substantially more uniform distribution of tokens across a corpus than standard BPE, and compresses text more effectively, with an approximate 20% increase in bytes per token.