 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mixer is more than just a model
Feb 28, 2024
Recently, MLP structures have regained popularity, with MLP-Mixer standing out as a prominent example. In the field of computer vision, MLP-Mixer is noted for its ability to extract data information from both channel and token perspectives, effectively acting as a fusion of channel and token information. Indeed, Mixer represents a paradigm for information extraction that amalgamates channel and token information. The essence of Mixer lies in its ability to blend information from diverse perspectives, epitomizing the true concept of "mixing" in the realm of neural network architectures. Beyond channel and token considerations, it is possible to create more tailored mixers from various perspectives to better suit specific task requirements. This study focuses on the domain of audio recognition, introducing a novel model named Audio Spectrogram Mixer with Roll-Time and Hermit FFT (ASM-RH) that incorporates insights from both time and frequency domains. Experimental results demonstrate that ASM-RH is particularly well-suited for audio data and yields promising outcomes across multiple classification tasks.
Understanding Biology in the Age of Artificial Intelligence
Mar 06, 2024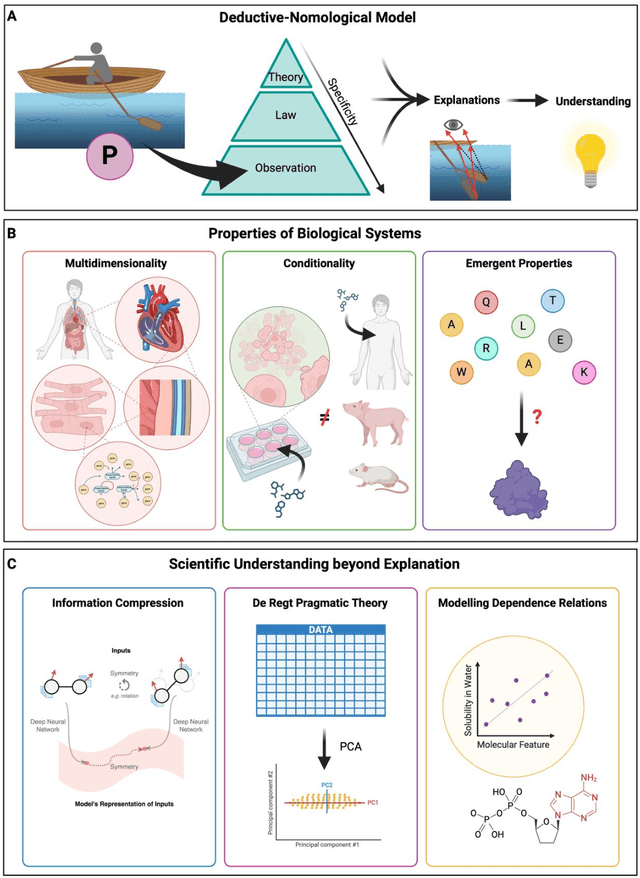
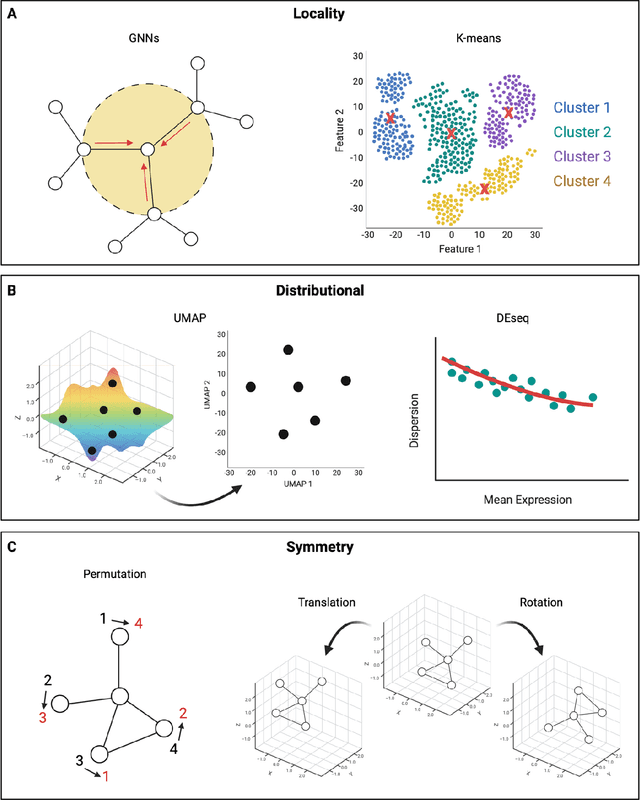
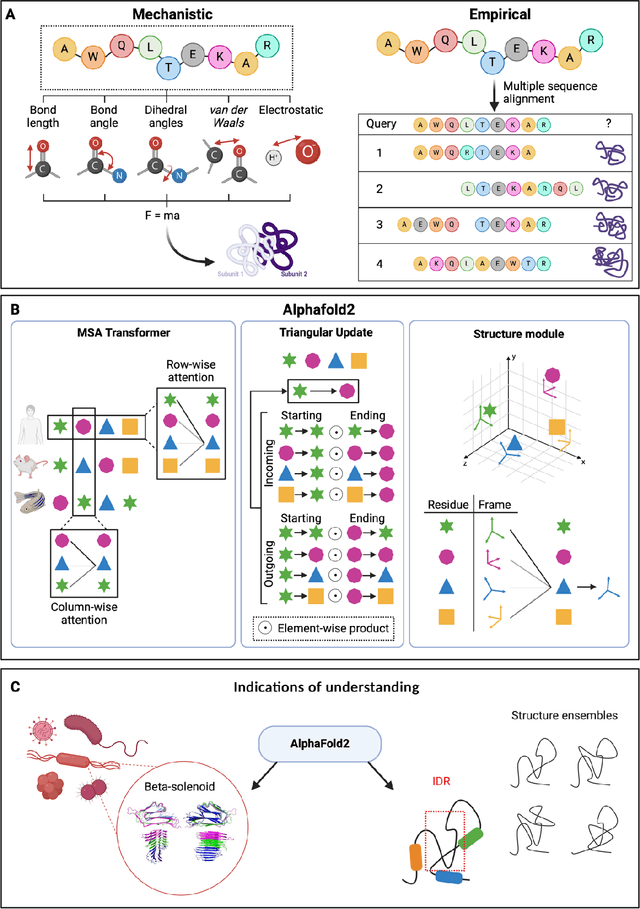
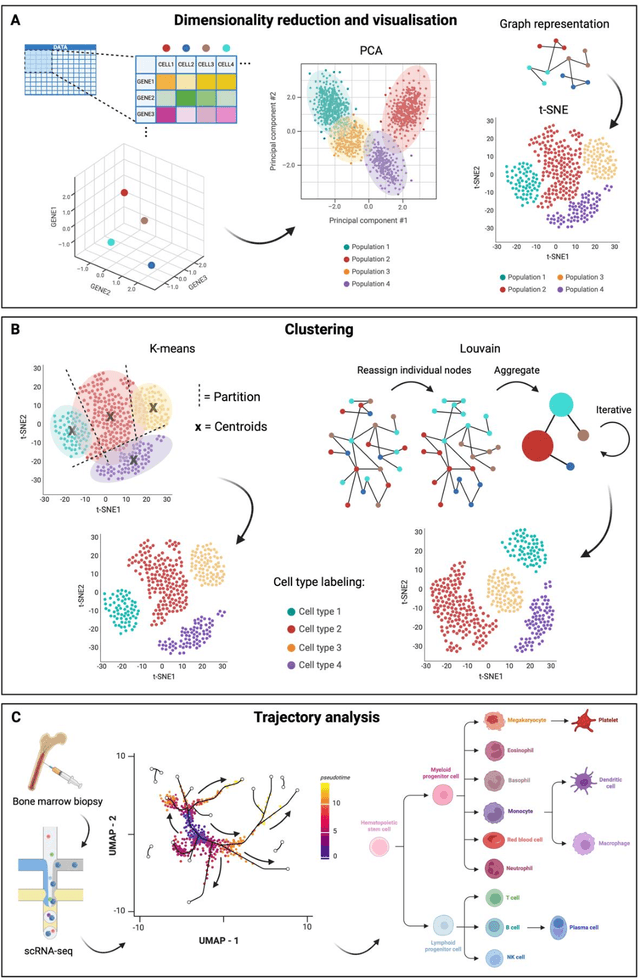
Modern life sciences research is increasingly relying on artificial intelligence approaches to model biological systems, primarily centered around the use of machine learning (ML) models. Although ML is undeniably useful for identifying patterns in large, complex data sets, its widespread application in biological sciences represents a significant deviation from traditional methods of scientific inquiry. As such, the interplay between these models and scientific understanding in biology is a topic with important implications for the future of scientific research, yet it is a subject that has received little attention. Here, we draw from an epistemological toolkit to contextualize recent applications of ML in biological sciences under modern philosophical theories of understanding, identifying general principles that can guide the design and application of ML systems to model biological phenomena and advance scientific knowledge. We propose that conceptions of scientific understanding as information compression, qualitative intelligibility, and dependency relation modelling provide a useful framework for interpreting ML-mediated understanding of biological systems. Through a detailed analysis of two key application areas of ML in modern biological research - protein structure prediction and single cell RNA-sequencing - we explore how these features have thus far enabled ML systems to advance scientific understanding of their target phenomena, how they may guide the development of future ML models, and the key obstacles that remain in preventing ML from achieving its potential as a tool for biological discovery. Consideration of the epistemological features of ML applications in biology will improve the prospects of these methods to solve important problems and advance scientific understanding of living systems.
Loss-Free Machine Unlearning
Feb 29, 2024We present a machine unlearning approach that is both retraining- and label-free. Most existing machine unlearning approaches require a model to be fine-tuned to remove information while preserving performance. This is computationally expensive and necessitates the storage of the whole dataset for the lifetime of the model. Retraining-free approaches often utilise Fisher information, which is derived from the loss and requires labelled data which may not be available. Thus, we present an extension to the Selective Synaptic Dampening algorithm, substituting the diagonal of the Fisher information matrix for the gradient of the l2 norm of the model output to approximate sensitivity. We evaluate our method in a range of experiments using ResNet18 and Vision Transformer. Results show our label-free method is competitive with existing state-of-the-art approaches.
Ice-Tide: Implicit Cryo-ET Imaging and Deformation Estimation
Mar 04, 2024
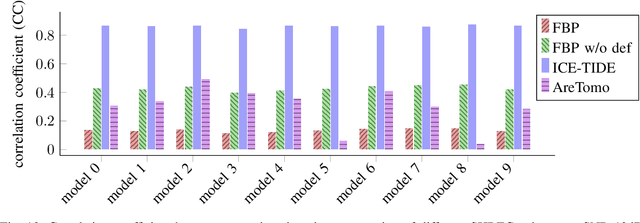


We introduce ICE-TIDE, a method for cryogenic electron tomography (cryo-ET) that simultaneously aligns observations and reconstructs a high-resolution volume. The alignment of tilt series in cryo-ET is a major problem limiting the resolution of reconstructions. ICE-TIDE relies on an efficient coordinate-based implicit neural representation of the volume which enables it to directly parameterize deformations and align the projections. Furthermore, the implicit network acts as an effective regularizer, allowing for high-quality reconstruction at low signal-to-noise ratios as well as partially restoring the missing wedge information. We compare the performance of ICE-TIDE to existing approaches on realistic simulated volumes where the significant gains in resolution and accuracy of recovering deformations can be precisely evaluated. Finally, we demonstrate ICE-TIDE's ability to perform on experimental data sets.
Large language models surpass human experts in predicting neuroscience results
Mar 04, 2024
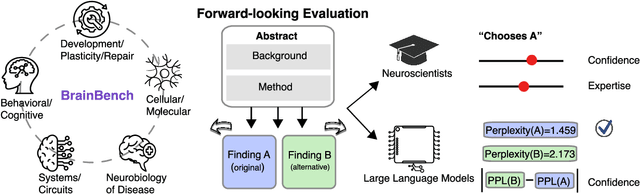
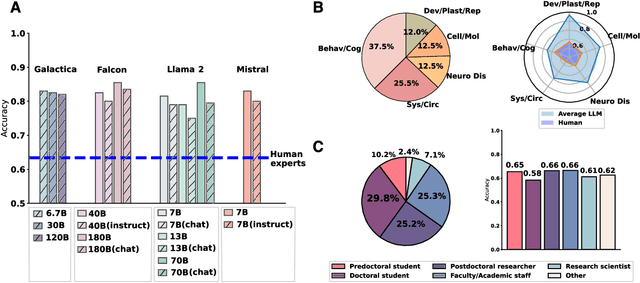
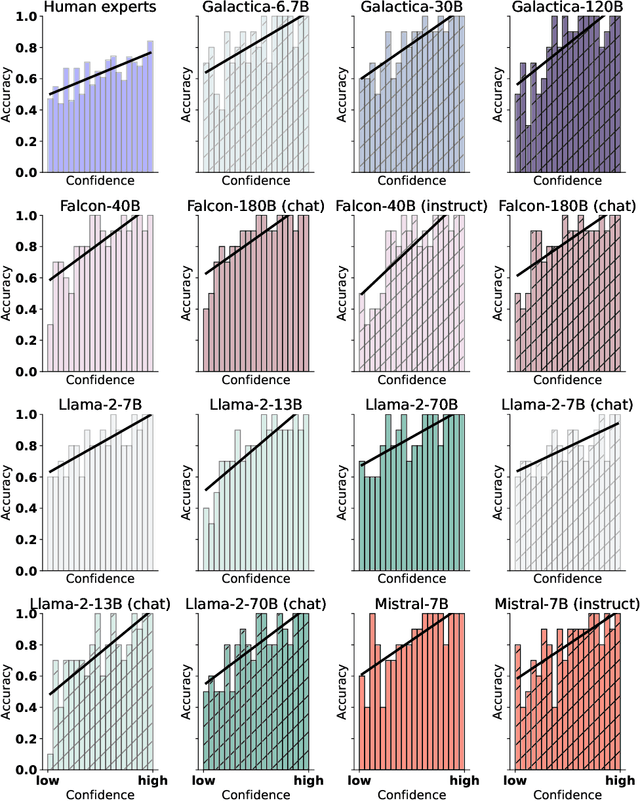
Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
A robust audio deepfake detection system via multi-view feature
Mar 04, 2024
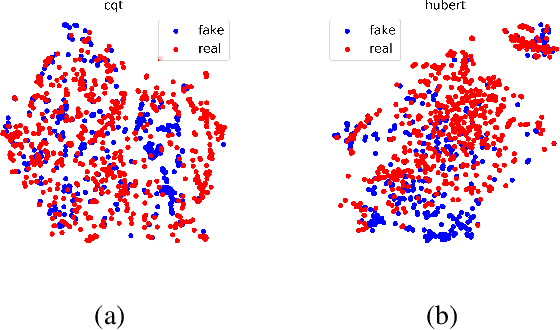
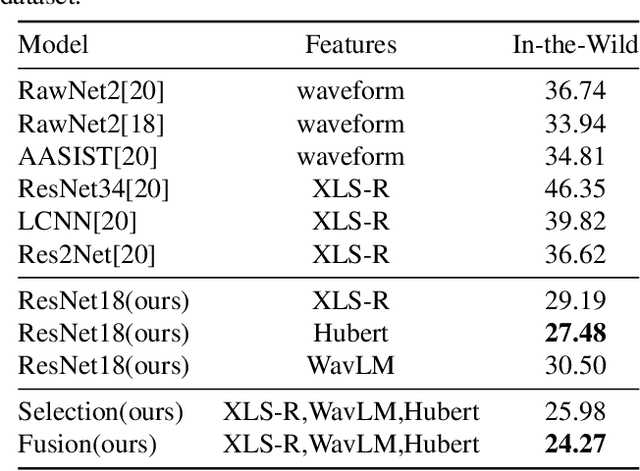
With the advancement of generative modeling techniques, synthetic human speech becomes increasingly indistinguishable from real, and tricky challenges are elicited for the audio deepfake detection (ADD) system. In this paper, we exploit audio features to improve the generalizability of ADD systems. Investigation of the ADD task performance is conducted over a broad range of audio features, including various handcrafted features and learning-based features. Experiments show that learning-based audio features pretrained on a large amount of data generalize better than hand-crafted features on out-of-domain scenarios. Subsequently, we further improve the generalizability of the ADD system using proposed multi-feature approaches to incorporate complimentary information from features of different views. The model trained on ASV2019 data achieves an equal error rate of 24.27\% on the In-the-Wild dataset.
Macroscopic auxiliary asymptotic preserving neural networks for the linear radiative transfer equations
Mar 04, 2024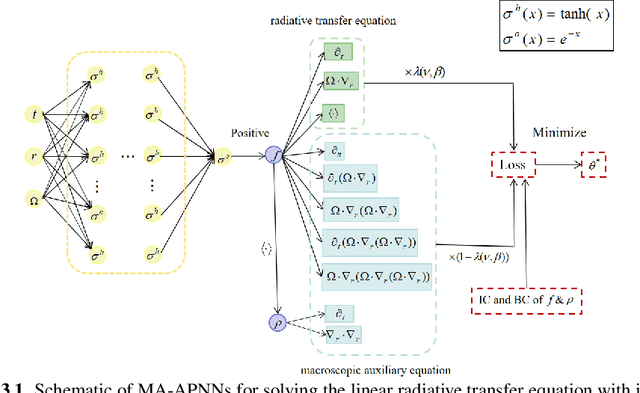
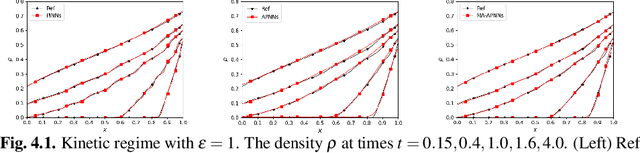

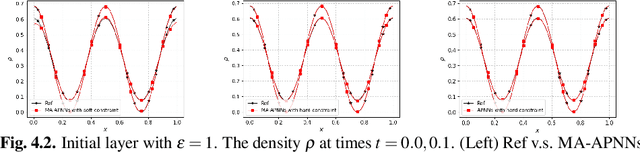
We develop a Macroscopic Auxiliary Asymptotic-Preserving Neural Network (MA-APNN) method to solve the time-dependent linear radiative transfer equations (LRTEs), which have a multi-scale nature and high dimensionality. To achieve this, we utilize the Physics-Informed Neural Networks (PINNs) framework and design a new adaptive exponentially weighted Asymptotic-Preserving (AP) loss function, which incorporates the macroscopic auxiliary equation that is derived from the original transfer equation directly and explicitly contains the information of the diffusion limit equation. Thus, as the scale parameter tends to zero, the loss function gradually transitions from the transport state to the diffusion limit state. In addition, the initial data, boundary conditions, and conservation laws serve as the regularization terms for the loss. We present several numerical examples to demonstrate the effectiveness of MA-APNNs.
Lemur: Log Parsing with Entropy Sampling and Chain-of-Thought Merging
Mar 02, 2024Logs produced by extensive software systems are integral to monitoring system behaviors. Advanced log analysis facilitates the detection, alerting, and diagnosis of system faults. Log parsing, which entails transforming raw log messages into structured templates, constitutes a critical phase in the automation of log analytics. Existing log parsers fail to identify the correct templates due to reliance on human-made rules. Besides, These methods focus on statistical features while ignoring semantic information in log messages. To address these challenges, we introduce a cutting-edge \textbf{L}og parsing framework with \textbf{E}ntropy sampling and Chain-of-Thought \textbf{M}erging (Lemur). Specifically, to discard the tedious manual rules. We propose a novel sampling method inspired by information entropy, which efficiently clusters typical logs. Furthermore, to enhance the merging of log templates, we design a chain-of-thought method for large language models (LLMs). LLMs exhibit exceptional semantic comprehension, deftly distinguishing between parameters and invariant tokens. We have conducted experiments on large-scale public datasets. Extensive evaluation demonstrates that Lemur achieves the state-of-the-art performance and impressive efficiency.
Pseudo-Label Calibration Semi-supervised Multi-Modal Entity Alignment
Mar 02, 2024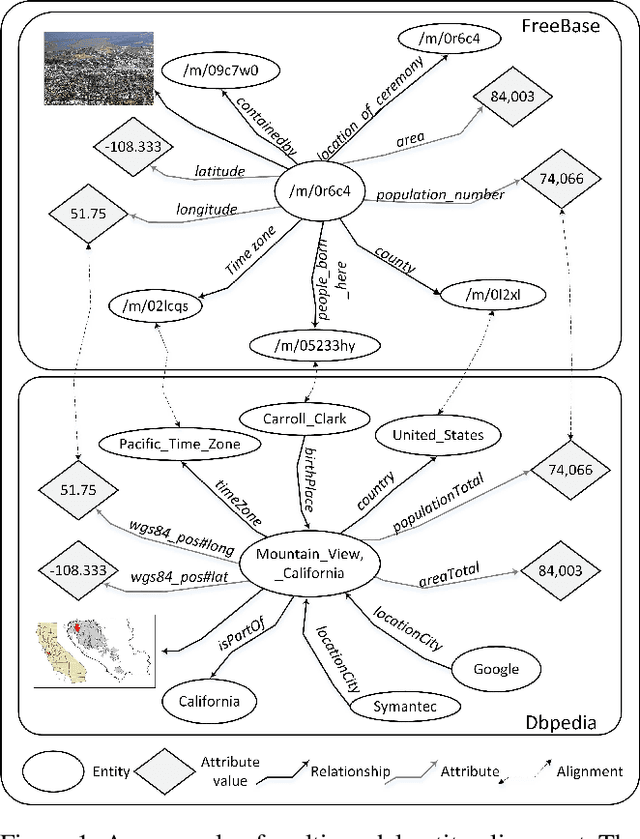
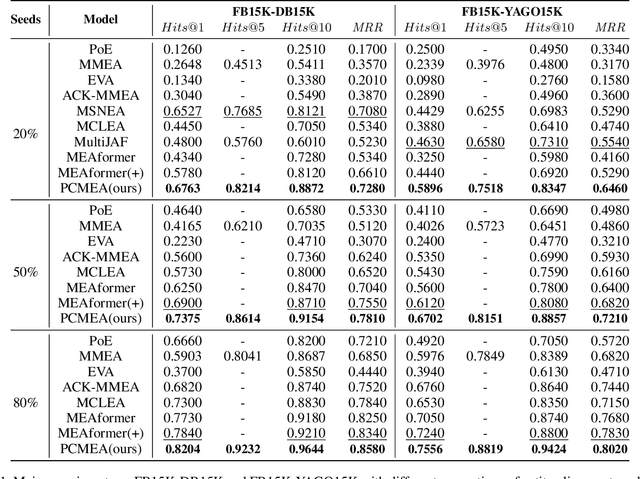
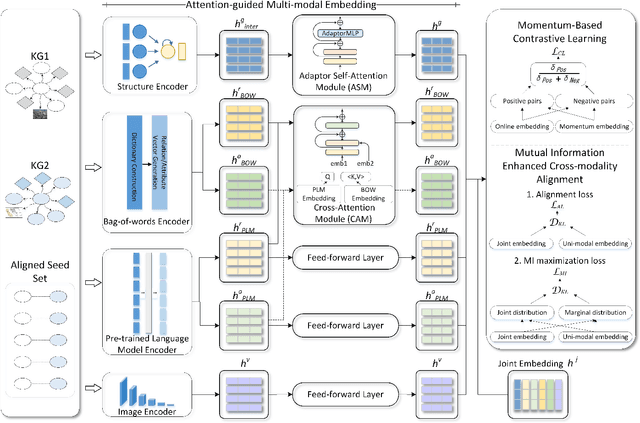
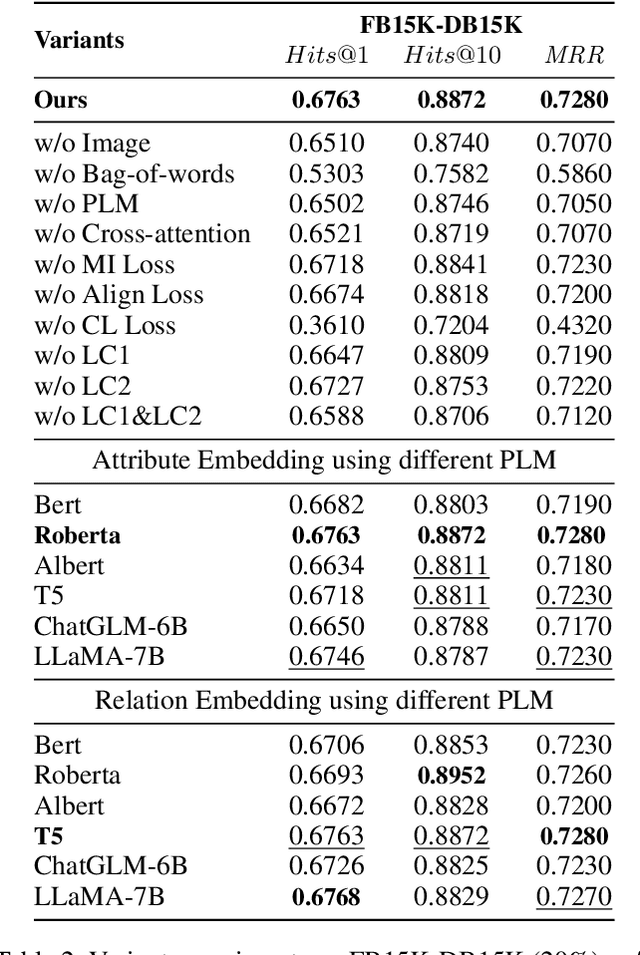
Multi-modal entity alignment (MMEA) aims to identify equivalent entities between two multi-modal knowledge graphs for integration. Unfortunately, prior arts have attempted to improve the interaction and fusion of multi-modal information, which have overlooked the influence of modal-specific noise and the usage of labeled and unlabeled data in semi-supervised settings. In this work, we introduce a Pseudo-label Calibration Multi-modal Entity Alignment (PCMEA) in a semi-supervised way. Specifically, in order to generate holistic entity representations, we first devise various embedding modules and attention mechanisms to extract visual, structural, relational, and attribute features. Different from the prior direct fusion methods, we next propose to exploit mutual information maximization to filter the modal-specific noise and to augment modal-invariant commonality. Then, we combine pseudo-label calibration with momentum-based contrastive learning to make full use of the labeled and unlabeled data, which improves the quality of pseudo-label and pulls aligned entities closer. Finally, extensive experiments on two MMEA datasets demonstrate the effectiveness of our PCMEA, which yields state-of-the-art performance.
Feature Alignment: Rethinking Efficient Active Learning via Proxy in the Context of Pre-trained Models
Mar 02, 2024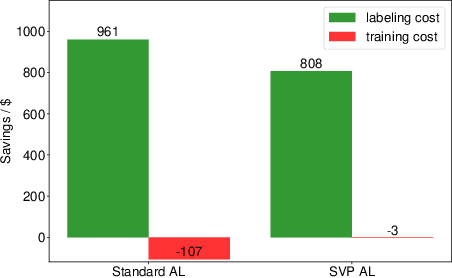
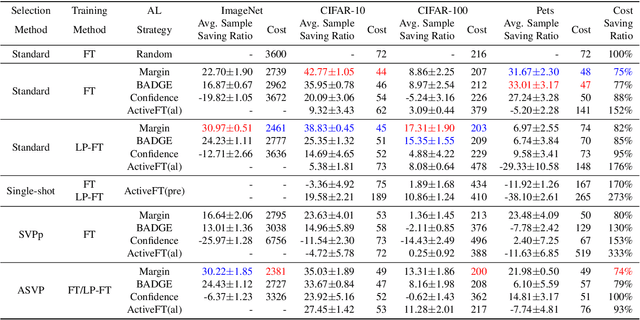
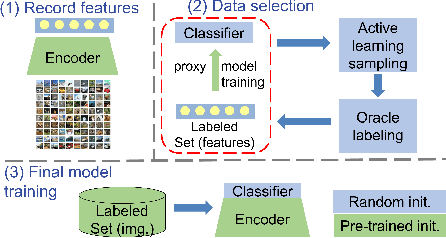
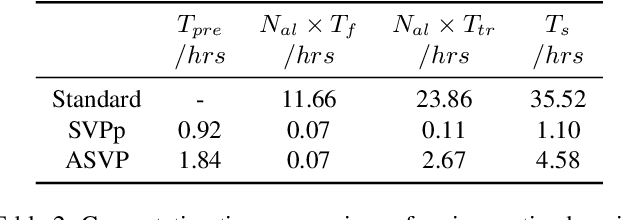
Fine-tuning the pre-trained model with active learning holds promise for reducing annotation costs. However, this combination introduces significant computational costs, particularly with the growing scale of pre-trained models. Recent research has proposed proxy-based active learning, which pre-computes features to reduce computational costs. Yet, this approach often incurs a significant loss in active learning performance, which may even outweigh the computational cost savings. In this paper, we argue the performance drop stems not only from pre-computed features' inability to distinguish between categories of labeled samples, resulting in the selection of redundant samples but also from the tendency to compromise valuable pre-trained information when fine-tuning with samples selected through the proxy model. To address this issue, we propose a novel method called aligned selection via proxy to update pre-computed features while selecting a proper training method to inherit valuable pre-training information. Extensive experiments validate that our method significantly improves the total cost of efficient active learning while maintaining computational efficiency.