 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Regularized Graph Structure Learning with Semantic Knowledge for Multi-variates Time-Series Forecasting
Oct 12, 2022
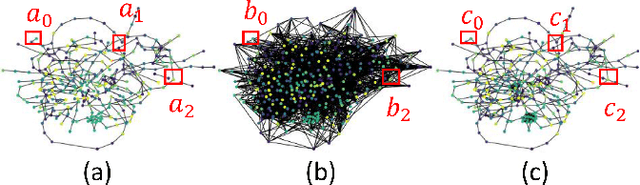
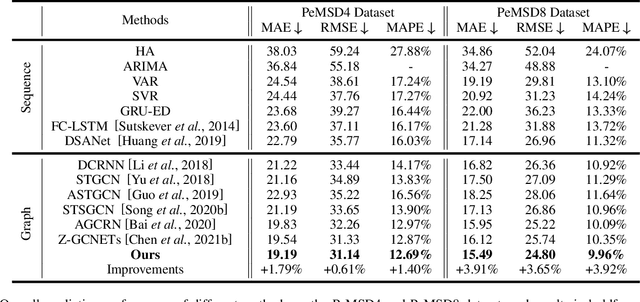
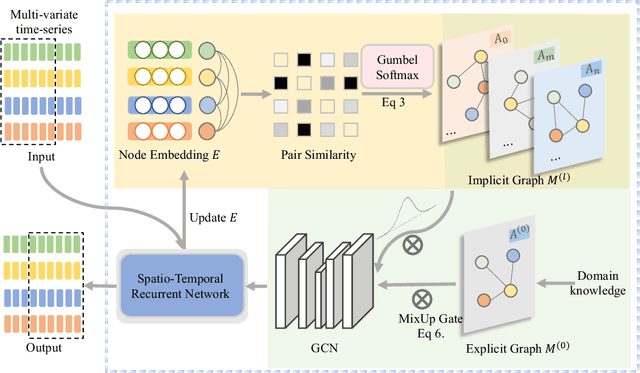
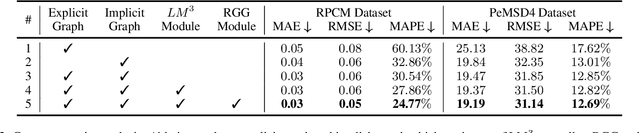
Multivariate time-series forecasting is a critical task for many applications, and graph time-series network is widely studied due to its capability to capture the spatial-temporal correlation simultaneously. However, most existing works focus more on learning with the explicit prior graph structure, while ignoring potential information from the implicit graph structure, yielding incomplete structure modeling. Some recent works attempt to learn the intrinsic or implicit graph structure directly while lacking a way to combine explicit prior structure with implicit structure together. In this paper, we propose Regularized Graph Structure Learning (RGSL) model to incorporate both explicit prior structure and implicit structure together, and learn the forecasting deep networks along with the graph structure. RGSL consists of two innovative modules. First, we derive an implicit dense similarity matrix through node embedding, and learn the sparse graph structure using the Regularized Graph Generation (RGG) based on the Gumbel Softmax trick. Second, we propose a Laplacian Matrix Mixed-up Module (LM3) to fuse the explicit graph and implicit graph together. We conduct experiments on three real-word datasets. Results show that the proposed RGSL model outperforms existing graph forecasting algorithms with a notable margin, while learning meaningful graph structure simultaneously. Our code and models are made publicly available at https://github.com/alipay/RGSL.git.
Semi-Supervised Offline Reinforcement Learning with Action-Free Trajectories
Oct 12, 2022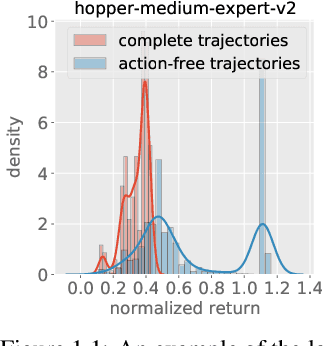
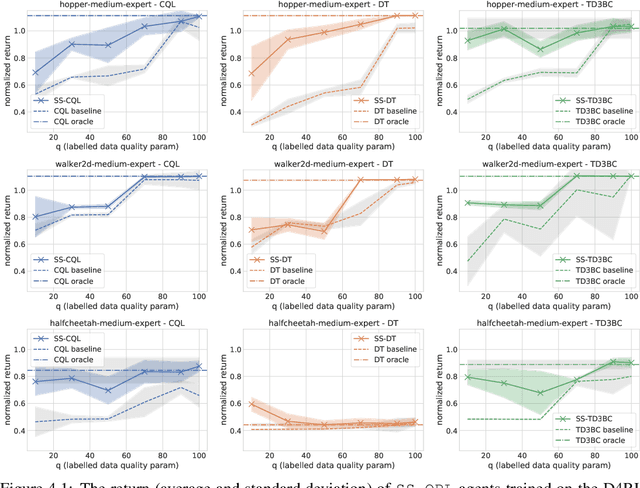
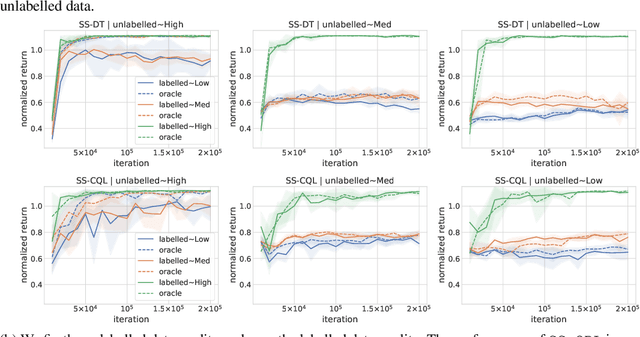
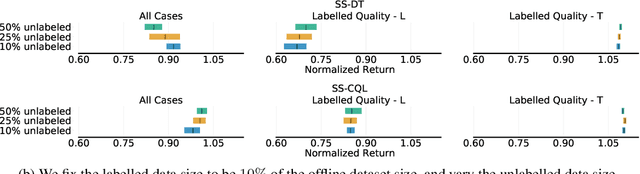
Natural agents can effectively learn from multiple data sources that differ in size, quality, and types of measurements. We study this heterogeneity in the context of offline reinforcement learning (RL) by introducing a new, practically motivated semi-supervised setting. Here, an agent has access to two sets of trajectories: labelled trajectories containing state, action, reward triplets at every timestep, along with unlabelled trajectories that contain only state and reward information. For this setting, we develop a simple meta-algorithmic pipeline that learns an inverse-dynamics model on the labelled data to obtain proxy-labels for the unlabelled data, followed by the use of any offline RL algorithm on the true and proxy-labelled trajectories. Empirically, we find this simple pipeline to be highly successful -- on several D4RL benchmarks \cite{fu2020d4rl}, certain offline RL algorithms can match the performance of variants trained on a fully labeled dataset even when we label only 10\% trajectories from the low return regime. Finally, we perform a large-scale controlled empirical study investigating the interplay of data-centric properties of the labelled and unlabelled datasets, with algorithmic design choices (e.g., inverse dynamics, offline RL algorithm) to identify general trends and best practices for training RL agents on semi-supervised offline datasets.
CLOWER: A Pre-trained Language Model with Contrastive Learning over Word and Character Representations
Aug 23, 2022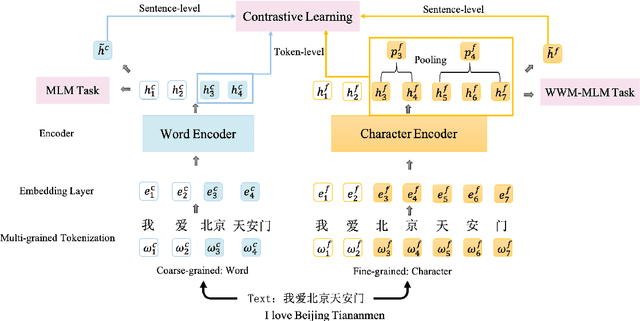
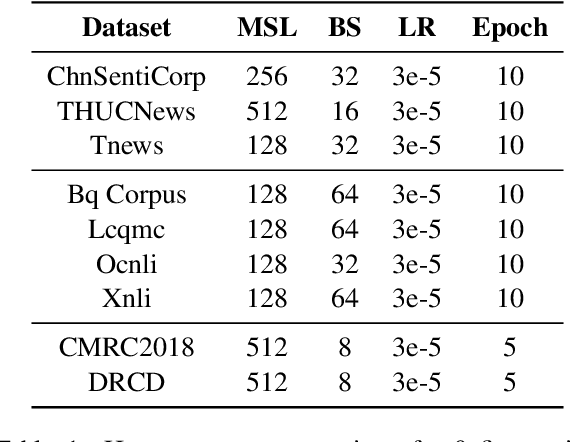
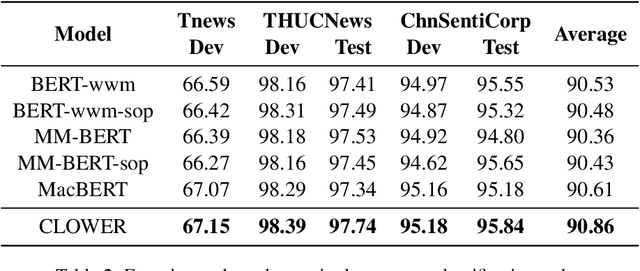
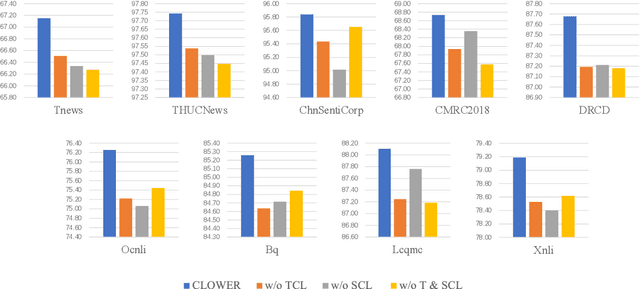
Pre-trained Language Models (PLMs) have achieved remarkable performance gains across numerous downstream tasks in natural language understanding. Various Chinese PLMs have been successively proposed for learning better Chinese language representation. However, most current models use Chinese characters as inputs and are not able to encode semantic information contained in Chinese words. While recent pre-trained models incorporate both words and characters simultaneously, they usually suffer from deficient semantic interactions and fail to capture the semantic relation between words and characters. To address the above issues, we propose a simple yet effective PLM CLOWER, which adopts the Contrastive Learning Over Word and charactER representations. In particular, CLOWER implicitly encodes the coarse-grained information (i.e., words) into the fine-grained representations (i.e., characters) through contrastive learning on multi-grained information. CLOWER is of great value in realistic scenarios since it can be easily incorporated into any existing fine-grained based PLMs without modifying the production pipelines.Extensive experiments conducted on a range of downstream tasks demonstrate the superior performance of CLOWER over several state-of-the-art baselines.
Augmented Deep Unfolding for Downlink Beamforming in Multi-cell Massive MIMO With Limited Feedback
Sep 03, 2022
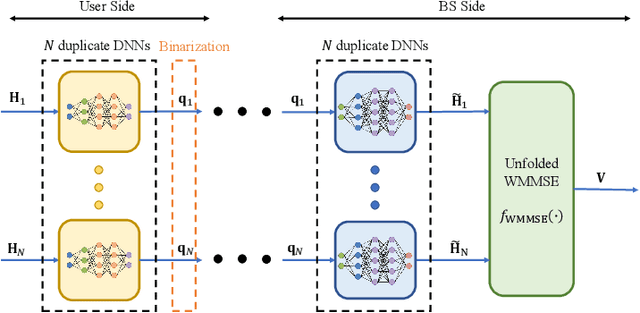
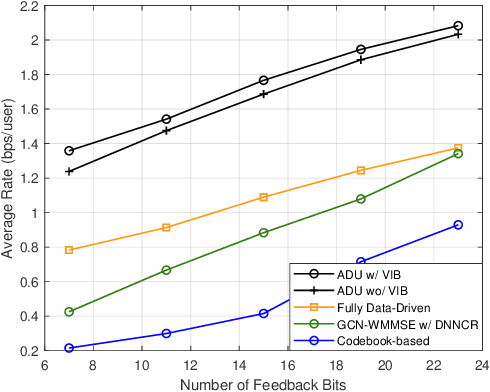
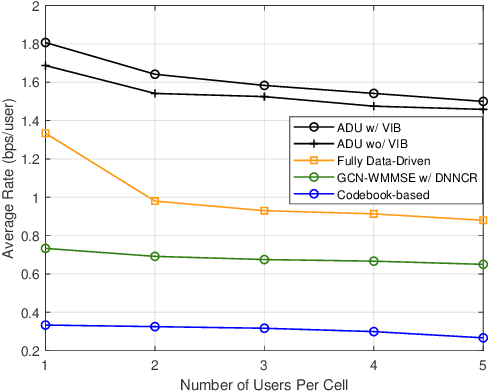
In limited feedback multi-user multiple-input multiple-output (MU-MIMO) cellular networks, users send quantized information about the channel conditions to the associated base station (BS) for downlink beamforming. However, channel quantization and beamforming have been treated as two separate tasks conventionally, which makes it difficult to achieve global system optimality. In this paper, we propose an augmented deep unfolding (ADU) approach that jointly optimizes the beamforming scheme at the BSs and the channel quantization scheme at the users. In particular, the classic WMMSE beamformer is unrolled and a deep neural network (DNN) is leveraged to pre-process its input to enhance the performance. The variational information bottleneck technique is adopted to further improve the performance when the feedback capacity is strictly restricted. Simulation results demonstrate that the proposed ADU method outperforms all the benchmark schemes in terms of the system average rate.
Towards Code Summarization of APIs Using NLP Techniques
Aug 26, 2022
Each programming language comes with official documentation to guide developers with APIs, methods and classes. However, in some cases, official documentation is not an efficient way to get the needed information. As a result, developers may consult other sources (e.g., Stack Overflow, GitHub) to learn more about an API, its implementation, usage, and other information that official documentation may not provide. In this research, we propose an automatic approach to generate summaries for APIs and methods by leveraging unofficial documentation using NLP techniques. Our findings demonstrate that the generated summaries are competitive, and can be used as a complementary source for guiding developers in software development and maintenance tasks.
ViT-DD: Multi-Task Vision Transformer for Semi-Supervised Driver Distraction Detection
Sep 28, 2022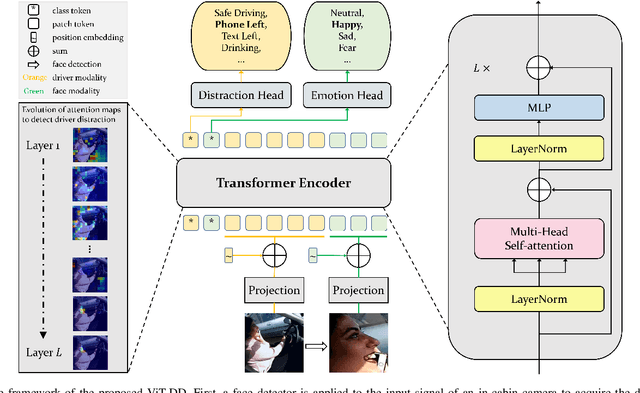


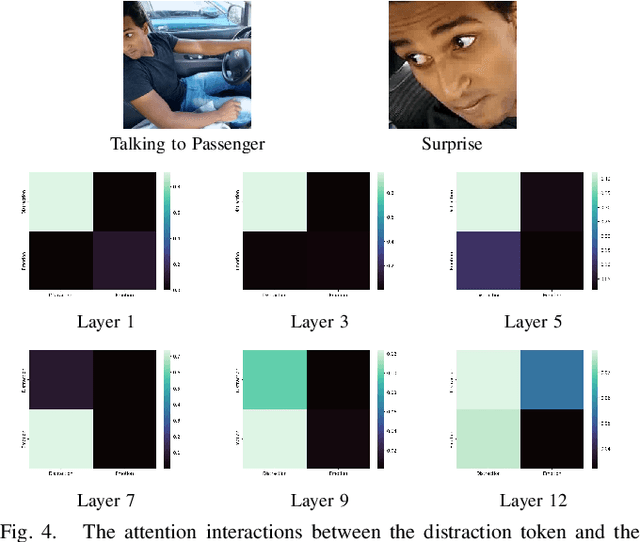
Driver distraction detection is an important computer vision problem that can play a crucial role in enhancing traffic safety and reducing traffic accidents. This paper proposes a novel semi-supervised method for detecting driver distractions based on Vision Transformer (ViT). Specifically, a multi-modal Vision Transformer (ViT-DD) is developed that makes use of inductive information contained in training signals of distraction detection as well as driver emotion recognition. Further, a self-learning algorithm is designed to include driver data without emotion labels into the multi-task training of ViT-DD. Extensive experiments conducted on the SFDDD and AUCDD datasets demonstrate that the proposed ViT-DD outperforms the best state-of-the-art approaches for driver distraction detection by 6.5% and 0.9%, respectively. Our source code is released at https://github.com/PurdueDigitalTwin/ViT-DD.
BioIE: Biomedical Information Extraction with Multi-head Attention Enhanced Graph Convolutional Network
Oct 26, 2021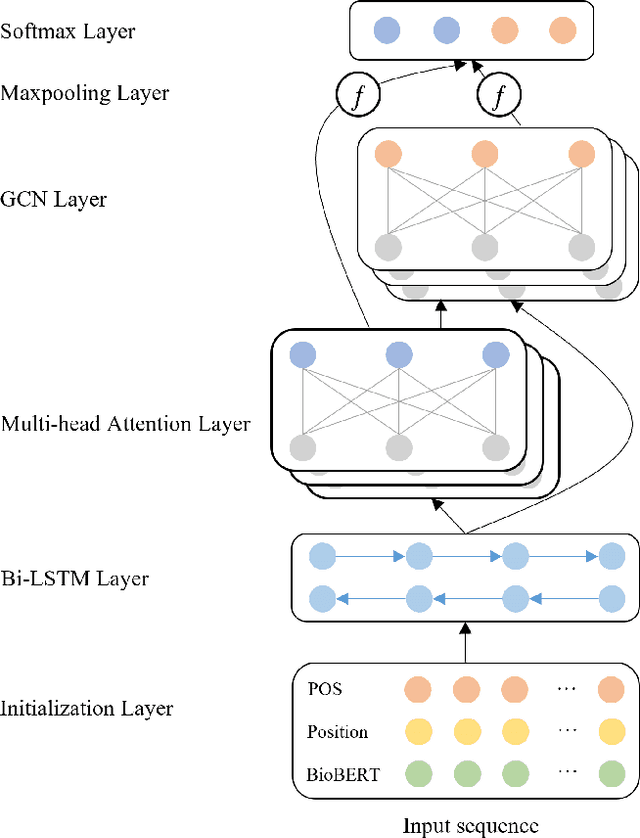

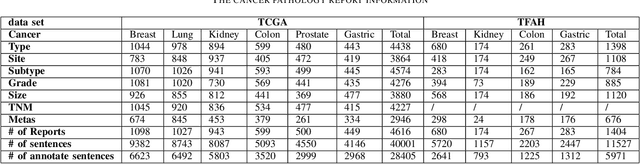

Constructing large-scaled medical knowledge graphs can significantly boost healthcare applications for medical surveillance, bring much attention from recent research. An essential step in constructing large-scale MKG is extracting information from medical reports. Recently, information extraction techniques have been proposed and show promising performance in biomedical information extraction. However, these methods only consider limited types of entity and relation due to the noisy biomedical text data with complex entity correlations. Thus, they fail to provide enough information for constructing MKGs and restrict the downstream applications. To address this issue, we propose Biomedical Information Extraction, a hybrid neural network to extract relations from biomedical text and unstructured medical reports. Our model utilizes a multi-head attention enhanced graph convolutional network to capture the complex relations and context information while resisting the noise from the data. We evaluate our model on two major biomedical relationship extraction tasks, chemical-disease relation and chemical-protein interaction, and a cross-hospital pan-cancer pathology report corpus. The results show that our method achieves superior performance than baselines. Furthermore, we evaluate the applicability of our method under a transfer learning setting and show that BioIE achieves promising performance in processing medical text from different formats and writing styles.
Approach of variable clustering and compression for learning large Bayesian networks
Aug 29, 2022
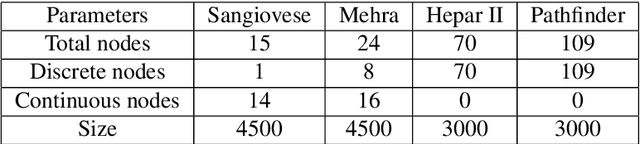
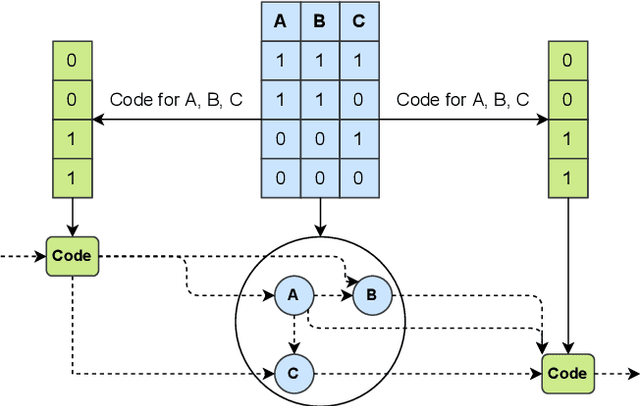
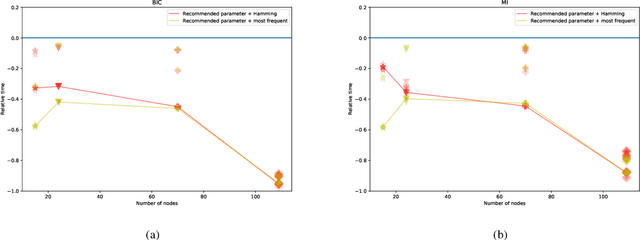
This paper describes a new approach for learning structures of large Bayesian networks based on blocks resulting from feature space clustering. This clustering is obtained using normalized mutual information. And the subsequent aggregation of blocks is done using classical learning methods except that they are input with compressed information about combinations of feature values for each block. Validation of this approach is done for Hill-Climbing as a graph enumeration algorithm for two score functions: BIC and MI. In this way, potentially parallelizable block learning can be implemented even for those score functions that are considered unsuitable for parallelizable learning. The advantage of the approach is evaluated in terms of speed of work as well as the accuracy of the found structures.
MonoNHR: Monocular Neural Human Renderer
Oct 02, 2022
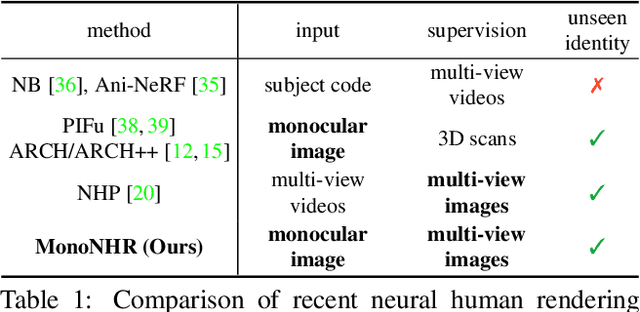
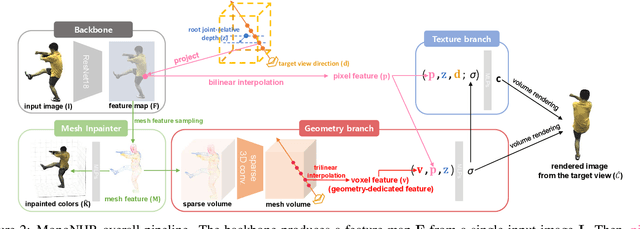
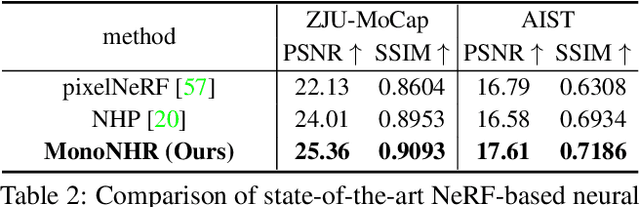
Existing neural human rendering methods struggle with a single image input due to the lack of information in invisible areas and the depth ambiguity of pixels in visible areas. In this regard, we propose Monocular Neural Human Renderer (MonoNHR), a novel approach that renders robust free-viewpoint images of an arbitrary human given only a single image. MonoNHR is the first method that (i) renders human subjects never seen during training in a monocular setup, and (ii) is trained in a weakly-supervised manner without geometry supervision. First, we propose to disentangle 3D geometry and texture features and to condition the texture inference on the 3D geometry features. Second, we introduce a Mesh Inpainter module that inpaints the occluded parts exploiting human structural priors such as symmetry. Experiments on ZJU-MoCap, AIST, and HUMBI datasets show that our approach significantly outperforms the recent methods adapted to the monocular case.
Performance Evaluation of 3D Keypoint Detectors and Descriptors on Coloured Point Clouds in Subsea Environments
Sep 26, 2022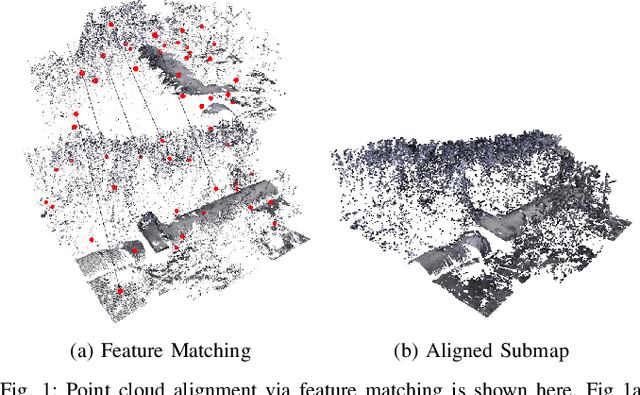
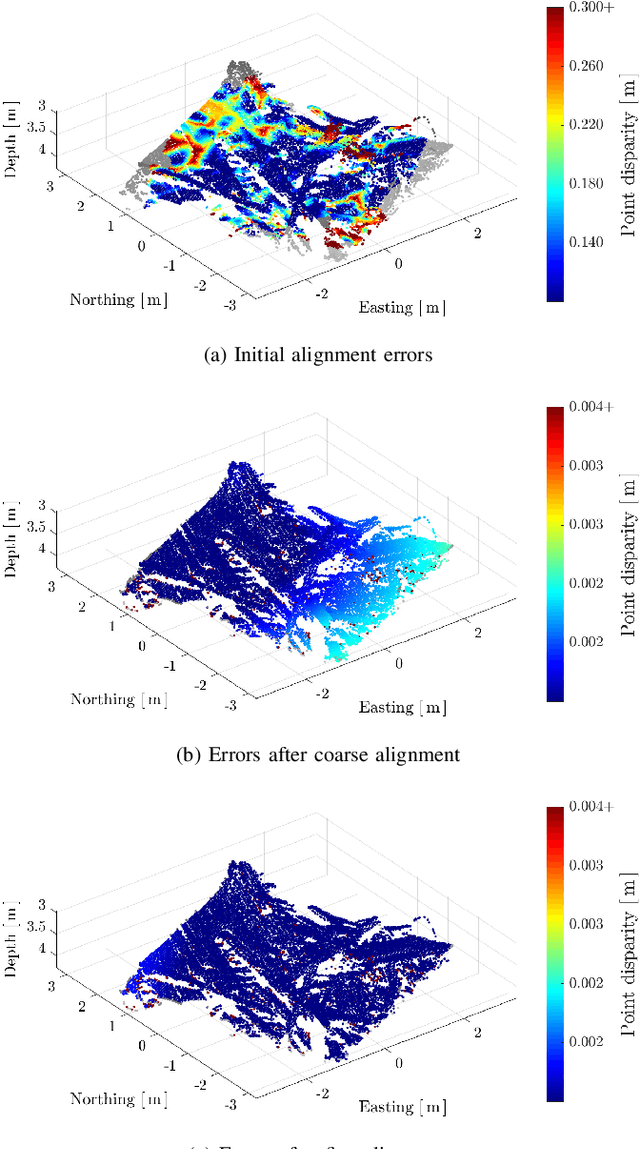

The recent development of high-precision subsea optical scanners allows for 3D keypoint detectors and feature descriptors to be leveraged on point cloud scans from subsea environments. However, the literature lacks a comprehensive survey to identify the best combination of detectors and descriptors to be used in these challenging and novel environments. This paper aims to identify the best detector/descriptor pair using a challenging field dataset collected using a commercial underwater laser scanner. Furthermore, studies have shown that incorporating texture information to extend geometric features adds robustness to feature matching on synthetic datasets. This paper also proposes a novel method of fusing images with underwater laser scans to produce coloured point clouds, which are used to study the effectiveness of 6D point cloud descriptors.