 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Random forests for detecting weak signals and extracting physical information: a case study of magnetic navigation
Feb 21, 2024
It was recently demonstrated that two machine-learning architectures, reservoir computing and time-delayed feed-forward neural networks, can be exploited for detecting the Earth's anomaly magnetic field immersed in overwhelming complex signals for magnetic navigation in a GPS-denied environment. The accuracy of the detected anomaly field corresponds to a positioning accuracy in the range of 10 to 40 meters. To increase the accuracy and reduce the uncertainty of weak signal detection as well as to directly obtain the position information, we exploit the machine-learning model of random forests that combines the output of multiple decision trees to give optimal values of the physical quantities of interest. In particular, from time-series data gathered from the cockpit of a flying airplane during various maneuvering stages, where strong background complex signals are caused by other elements of the Earth's magnetic field and the fields produced by the electronic systems in the cockpit, we demonstrate that the random-forest algorithm performs remarkably well in detecting the weak anomaly field and in filtering the position of the aircraft. With the aid of the conventional inertial navigation system, the positioning error can be reduced to less than 10 meters. We also find that, contrary to the conventional wisdom, the classic Tolles-Lawson model for calibrating and removing the magnetic field generated by the body of the aircraft is not necessary and may even be detrimental for the success of the random-forest method.
CN-RMA: Combined Network with Ray Marching Aggregation for 3D Indoors Object Detection from Multi-view Images
Mar 07, 2024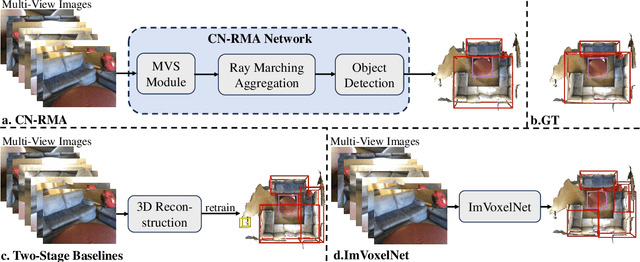
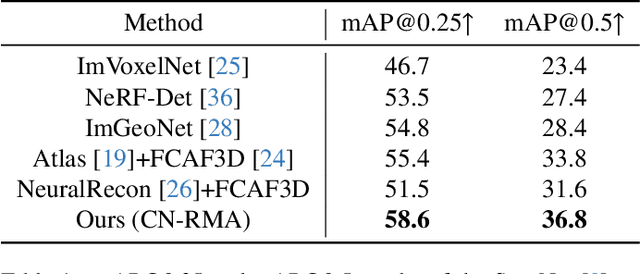
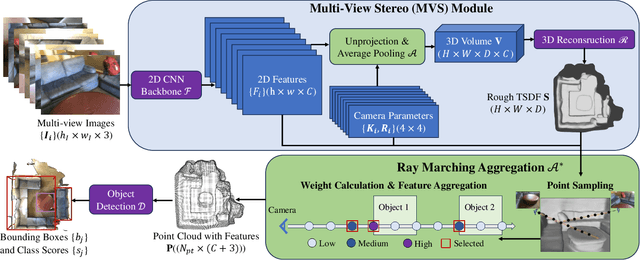
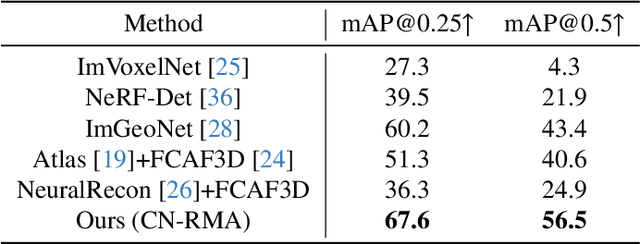
This paper introduces CN-RMA, a novel approach for 3D indoor object detection from multi-view images. We observe the key challenge as the ambiguity of image and 3D correspondence without explicit geometry to provide occlusion information. To address this issue, CN-RMA leverages the synergy of 3D reconstruction networks and 3D object detection networks, where the reconstruction network provides a rough Truncated Signed Distance Function (TSDF) and guides image features to vote to 3D space correctly in an end-to-end manner. Specifically, we associate weights to sampled points of each ray through ray marching, representing the contribution of a pixel in an image to corresponding 3D locations. Such weights are determined by the predicted signed distances so that image features vote only to regions near the reconstructed surface. Our method achieves state-of-the-art performance in 3D object detection from multi-view images, as measured by mAP@0.25 and mAP@0.5 on the ScanNet and ARKitScenes datasets. The code and models are released at https://github.com/SerCharles/CN-RMA.
That's My Point: Compact Object-centric LiDAR Pose Estimation for Large-scale Outdoor Localisation
Mar 07, 2024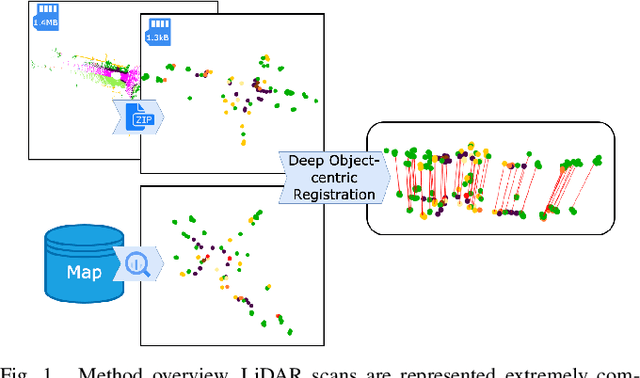
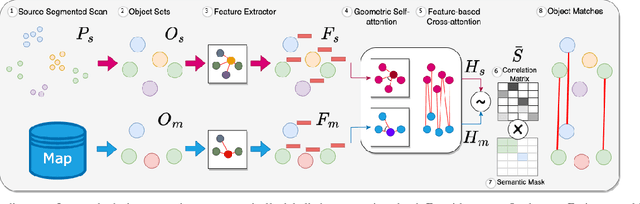
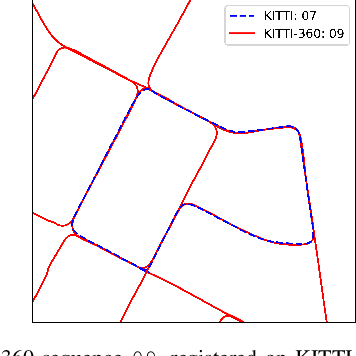
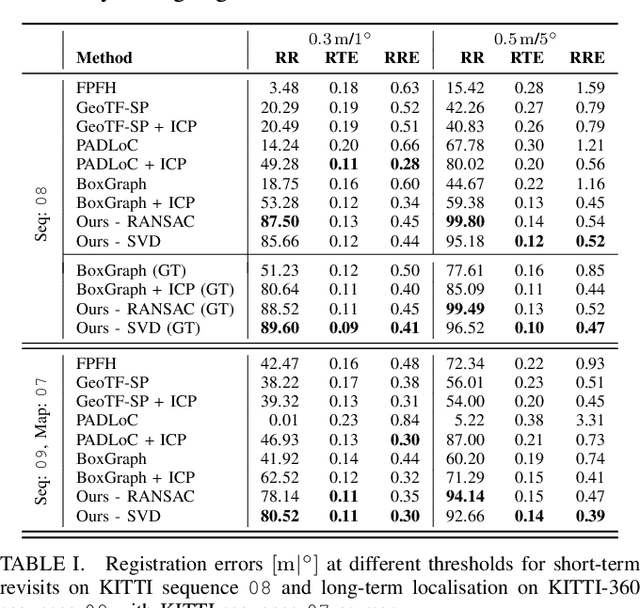
This paper is about 3D pose estimation on LiDAR scans with extremely minimal storage requirements to enable scalable mapping and localisation. We achieve this by clustering all points of segmented scans into semantic objects and representing them only with their respective centroid and semantic class. In this way, each LiDAR scan is reduced to a compact collection of four-number vectors. This abstracts away important structural information from the scenes, which is crucial for traditional registration approaches. To mitigate this, we introduce an object-matching network based on self- and cross-correlation that captures geometric and semantic relationships between entities. The respective matches allow us to recover the relative transformation between scans through weighted Singular Value Decomposition (SVD) and RANdom SAmple Consensus (RANSAC). We demonstrate that such representation is sufficient for metric localisation by registering point clouds taken under different viewpoints on the KITTI dataset, and at different periods of time localising between KITTI and KITTI-360. We achieve accurate metric estimates comparable with state-of-the-art methods with almost half the representation size, specifically 1.33 kB on average.
TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document
Mar 07, 2024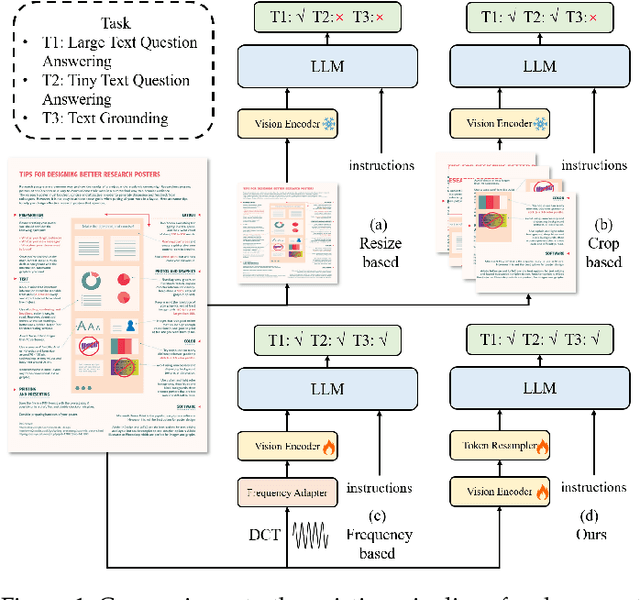
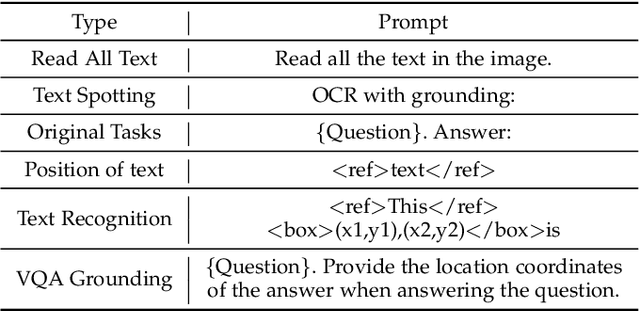
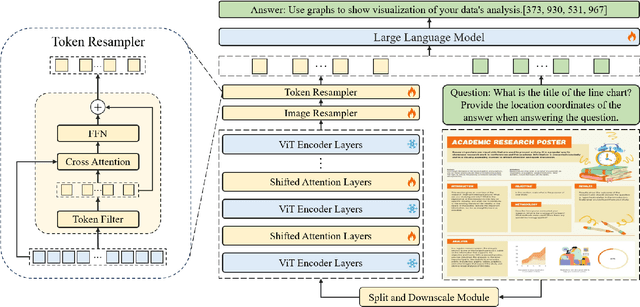
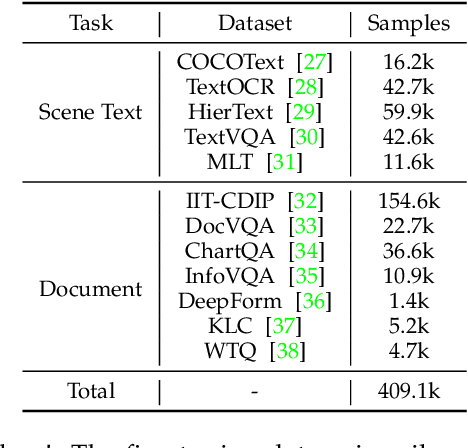
We present TextMonkey, a large multimodal model (LMM) tailored for text-centric tasks, including document question answering (DocVQA) and scene text analysis. Our approach introduces enhancement across several dimensions: by adopting Shifted Window Attention with zero-initialization, we achieve cross-window connectivity at higher input resolutions and stabilize early training; We hypothesize that images may contain redundant tokens, and by using similarity to filter out significant tokens, we can not only streamline the token length but also enhance the model's performance. Moreover, by expanding our model's capabilities to encompass text spotting and grounding, and incorporating positional information into responses, we enhance interpretability and minimize hallucinations. Additionally, TextMonkey can be finetuned to gain the ability to comprehend commands for clicking screenshots. Overall, our method notably boosts performance across various benchmark datasets, achieving increases of 5.2%, 6.9%, and 2.8% in Scene Text-Centric VQA, Document Oriented VQA, and KIE, respectively, especially with a score of 561 on OCRBench, surpassing prior open-sourced large multimodal models for document understanding. Code will be released at https://github.com/Yuliang-Liu/Monkey.
Robust Wake Word Spotting With Frame-Level Cross-Modal Attention Based Audio-Visual Conformer
Mar 04, 2024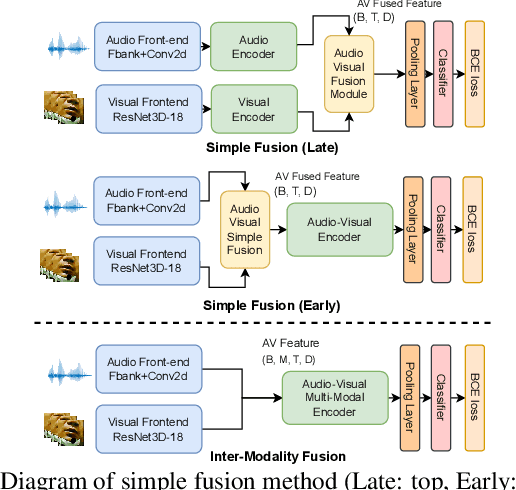
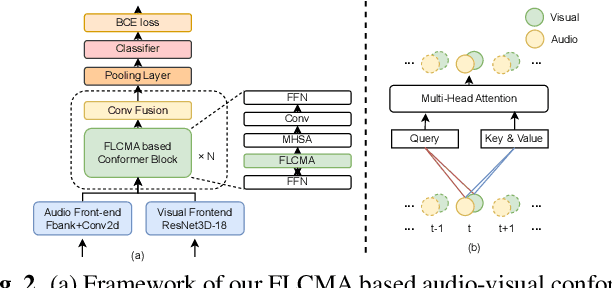
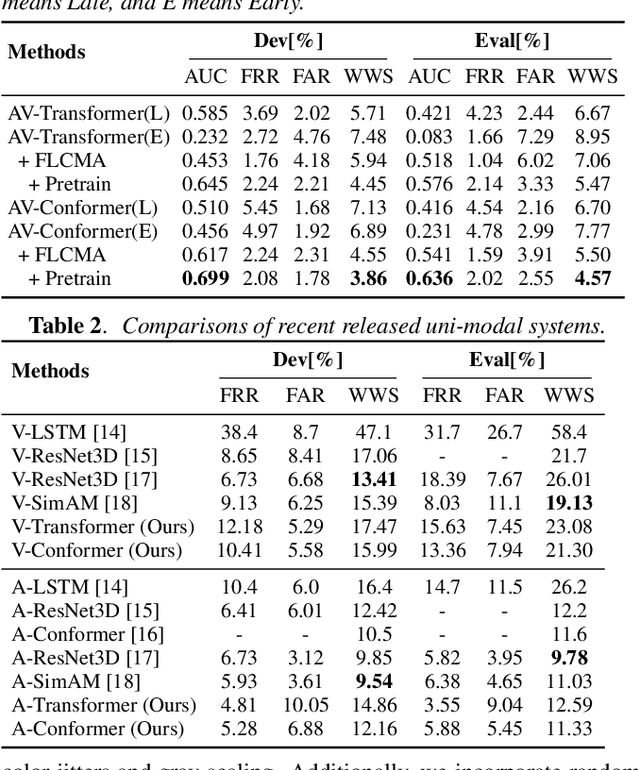
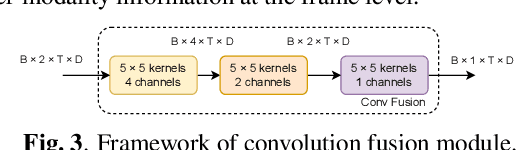
In recent years, neural network-based Wake Word Spotting achieves good performance on clean audio samples but struggles in noisy environments. Audio-Visual Wake Word Spotting (AVWWS) receives lots of attention because visual lip movement information is not affected by complex acoustic scenes. Previous works usually use simple addition or concatenation for multi-modal fusion. The inter-modal correlation remains relatively under-explored. In this paper, we propose a novel module called Frame-Level Cross-Modal Attention (FLCMA) to improve the performance of AVWWS systems. This module can help model multi-modal information at the frame-level through synchronous lip movements and speech signals. We train the end-to-end FLCMA based Audio-Visual Conformer and further improve the performance by fine-tuning pre-trained uni-modal models for the AVWWS task. The proposed system achieves a new state-of-the-art result (4.57% WWS score) on the far-field MISP dataset.
SGD with Partial Hessian for Deep Neural Networks Optimization
Mar 05, 2024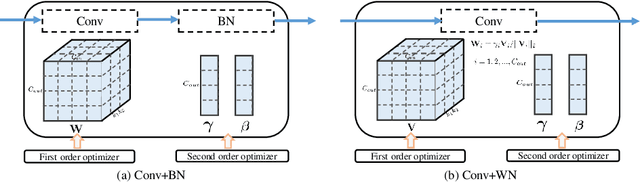
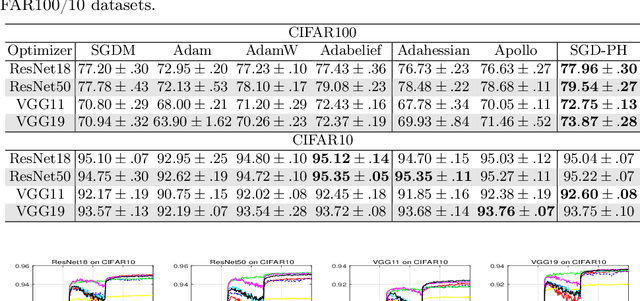
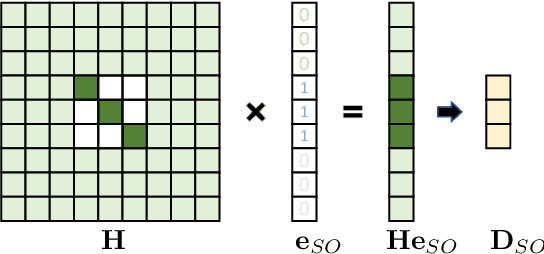

Due to the effectiveness of second-order algorithms in solving classical optimization problems, designing second-order optimizers to train deep neural networks (DNNs) has attracted much research interest in recent years. However, because of the very high dimension of intermediate features in DNNs, it is difficult to directly compute and store the Hessian matrix for network optimization. Most of the previous second-order methods approximate the Hessian information imprecisely, resulting in unstable performance. In this work, we propose a compound optimizer, which is a combination of a second-order optimizer with a precise partial Hessian matrix for updating channel-wise parameters and the first-order stochastic gradient descent (SGD) optimizer for updating the other parameters. We show that the associated Hessian matrices of channel-wise parameters are diagonal and can be extracted directly and precisely from Hessian-free methods. The proposed method, namely SGD with Partial Hessian (SGD-PH), inherits the advantages of both first-order and second-order optimizers. Compared with first-order optimizers, it adopts a certain amount of information from the Hessian matrix to assist optimization, while compared with the existing second-order optimizers, it keeps the good generalization performance of first-order optimizers. Experiments on image classification tasks demonstrate the effectiveness of our proposed optimizer SGD-PH. The code is publicly available at \url{https://github.com/myingysun/SGDPH}.
On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving
Mar 02, 2024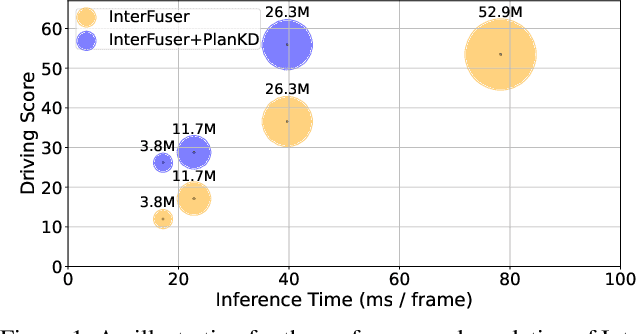
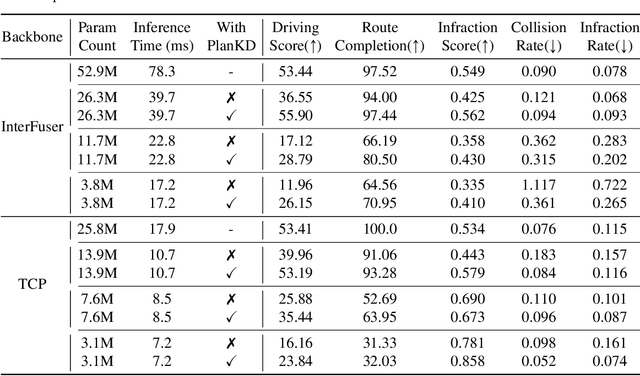
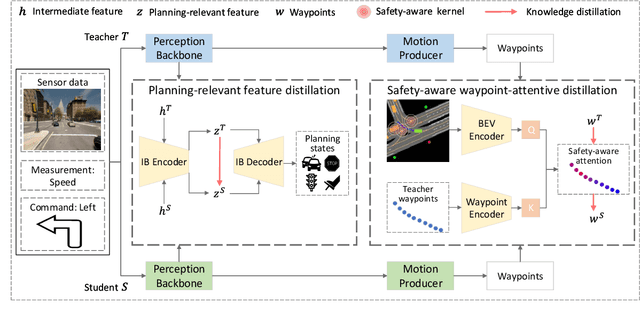
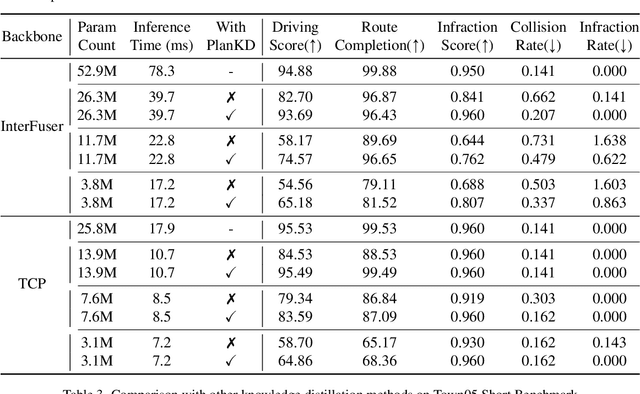
End-to-end motion planning models equipped with deep neural networks have shown great potential for enabling full autonomous driving. However, the oversized neural networks render them impractical for deployment on resource-constrained systems, which unavoidably requires more computational time and resources during reference.To handle this, knowledge distillation offers a promising approach that compresses models by enabling a smaller student model to learn from a larger teacher model. Nevertheless, how to apply knowledge distillation to compress motion planners has not been explored so far. In this paper, we propose PlanKD, the first knowledge distillation framework tailored for compressing end-to-end motion planners. First, considering that driving scenes are inherently complex, often containing planning-irrelevant or even noisy information, transferring such information is not beneficial for the student planner. Thus, we design an information bottleneck based strategy to only distill planning-relevant information, rather than transfer all information indiscriminately. Second, different waypoints in an output planned trajectory may hold varying degrees of importance for motion planning, where a slight deviation in certain crucial waypoints might lead to a collision. Therefore, we devise a safety-aware waypoint-attentive distillation module that assigns adaptive weights to different waypoints based on the importance, to encourage the student to accurately mimic more crucial waypoints, thereby improving overall safety. Experiments demonstrate that our PlanKD can boost the performance of smaller planners by a large margin, and significantly reduce their reference time.
Personalised Drug Identifier for Cancer Treatment with Transformers using Auxiliary Information
Feb 16, 2024Cancer remains a global challenge due to its growing clinical and economic burden. Its uniquely personal manifestation, which makes treatment difficult, has fuelled the quest for personalized treatment strategies. Thus, genomic profiling is increasingly becoming part of clinical diagnostic panels. Effective use of such panels requires accurate drug response prediction (DRP) models, which are challenging to build due to limited labelled patient data. Previous methods to address this problem have used various forms of transfer learning. However, they do not explicitly model the variable length sequential structure of the list of mutations in such diagnostic panels. Further, they do not utilize auxiliary information (like patient survival) for model training. We address these limitations through a novel transformer based method, which surpasses the performance of state-of-the-art DRP models on benchmark data. We also present the design of a treatment recommendation system (TRS), which is currently deployed at the National University Hospital, Singapore and is being evaluated in a clinical trial.
Debiasing Large Visual Language Models
Mar 08, 2024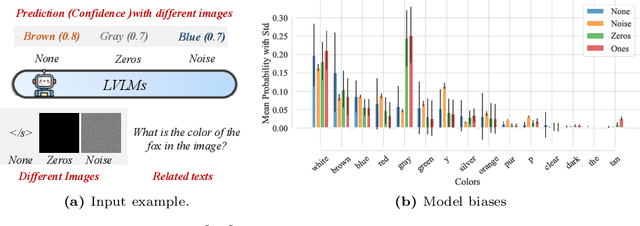
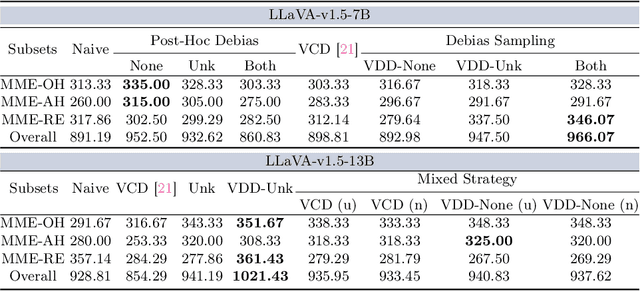
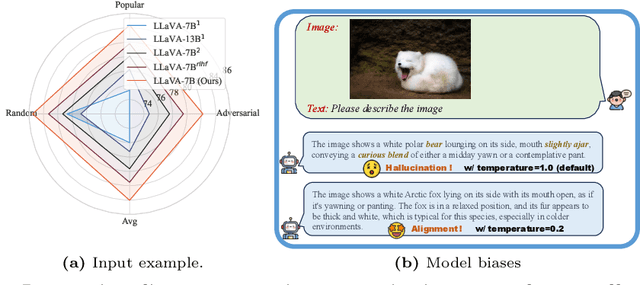
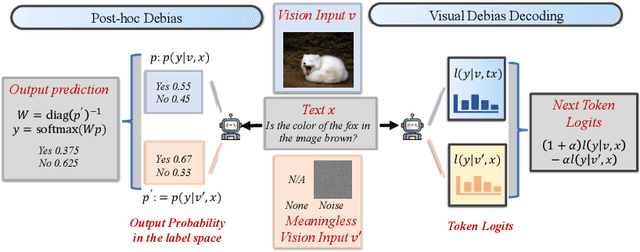
In the realms of computer vision and natural language processing, Large Vision-Language Models (LVLMs) have become indispensable tools, proficient in generating textual descriptions based on visual inputs. Despite their advancements, our investigation reveals a noteworthy bias in the generated content, where the output is primarily influenced by the underlying Large Language Models (LLMs) prior rather than the input image. Our empirical experiments underscore the persistence of this bias, as LVLMs often provide confident answers even in the absence of relevant images or given incongruent visual input. To rectify these biases and redirect the model's focus toward vision information, we introduce two simple, training-free strategies. Firstly, for tasks such as classification or multi-choice question-answering (QA), we propose a ``calibration'' step through affine transformation to adjust the output distribution. This ``Post-Hoc debias'' approach ensures uniform scores for each answer when the image is absent, serving as an effective regularization technique to alleviate the influence of LLM priors. For more intricate open-ended generation tasks, we extend this method to ``Debias sampling'', drawing inspirations from contrastive decoding methods. Furthermore, our investigation sheds light on the instability of LVLMs across various decoding configurations. Through systematic exploration of different settings, we significantly enhance performance, surpassing reported results and raising concerns about the fairness of existing evaluations. Comprehensive experiments substantiate the effectiveness of our proposed strategies in mitigating biases. These strategies not only prove beneficial in minimizing hallucinations but also contribute to the generation of more helpful and precise illustrations.
Towards a Psychology of Machines: Large Language Models Predict Human Memory
Mar 08, 2024
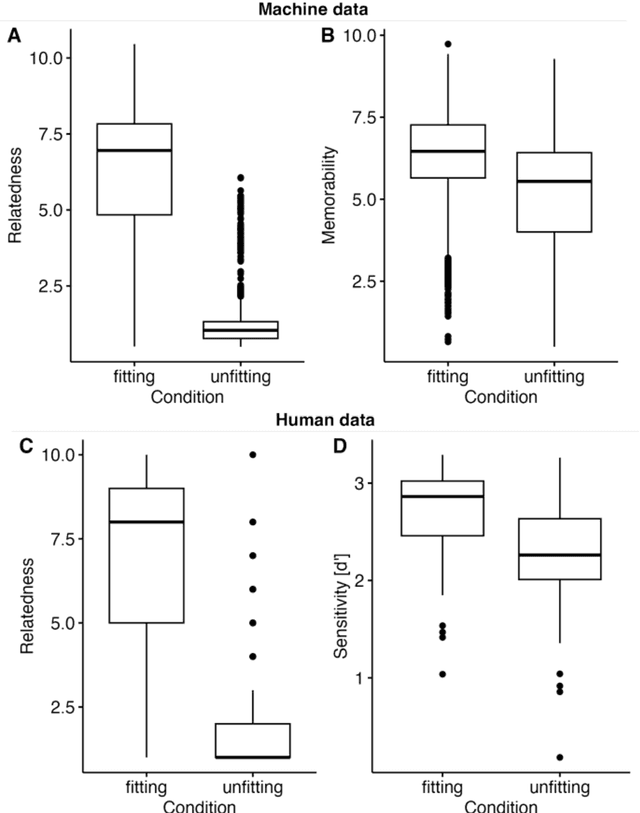
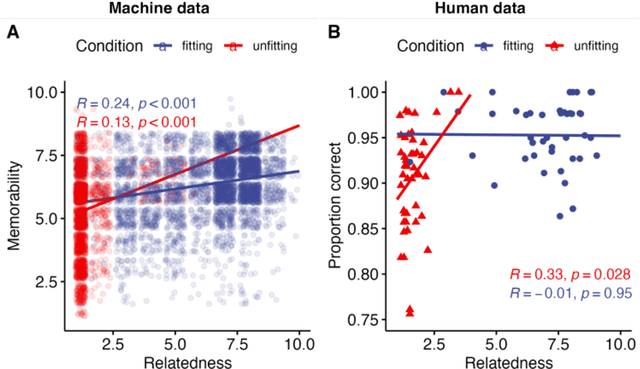
Large language models (LLMs) are demonstrating remarkable capabilities across various tasks despite lacking a foundation in human cognition. This raises the question: can these models, beyond simply mimicking human language patterns, offer insights into the mechanisms underlying human cognition? This study explores the ability of ChatGPT to predict human performance in a language-based memory task. Building upon theories of text comprehension, we hypothesize that recognizing ambiguous sentences (e.g., "Because Bill drinks wine is never kept in the house") is facilitated by preceding them with contextually relevant information. Participants, both human and ChatGPT, were presented with pairs of sentences. The second sentence was always a garden-path sentence designed to be inherently ambiguous, while the first sentence either provided a fitting (e.g., "Bill has chronic alcoholism") or an unfitting context (e.g., "Bill likes to play golf"). We measured both human's and ChatGPT's ratings of sentence relatedness, ChatGPT's memorability ratings for the garden-path sentences, and humans' spontaneous memory for the garden-path sentences. The results revealed a striking alignment between ChatGPT's assessments and human performance. Sentences deemed more related and assessed as being more memorable by ChatGPT were indeed better remembered by humans, even though ChatGPT's internal mechanisms likely differ significantly from human cognition. This finding, which was confirmed with a robustness check employing synonyms, underscores the potential of generative AI models to predict human performance accurately. We discuss the broader implications of these findings for leveraging LLMs in the development of psychological theories and for gaining a deeper understanding of human cognition.