 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sensitivity Analysis On Loss Landscape
Mar 05, 2024
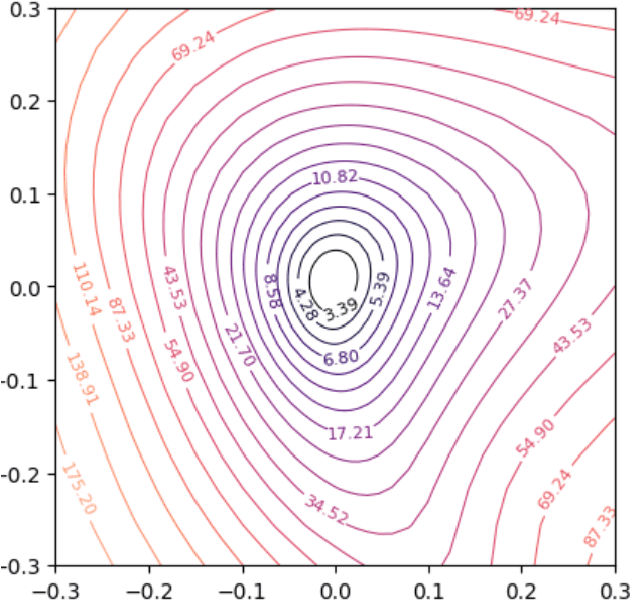
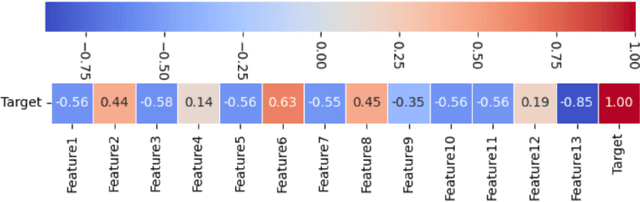
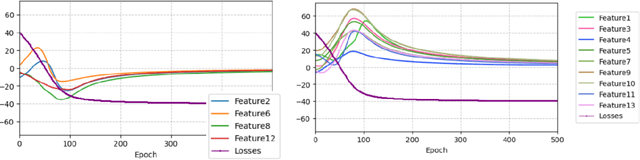
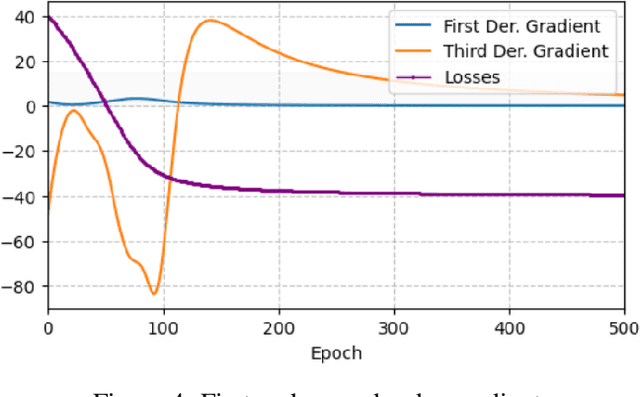
Gradients can be employed for sensitivity analysis. Here, we leverage the advantages of the Loss Landscape to comprehend which independent variables impact the dependent variable. We seek to grasp the loss landscape by utilizing first, second, and third derivatives through automatic differentiation. we know that Spearman's rank correlation coefficient can detect the monotonic relationship between two variables. However, I have found that second-order gradients, with certain configurations and parameters, provide information that can be visualized similarly to Spearman results, In this approach, we incorporate a loss function with an activation function, resulting in a non-linear pattern. Each exploration of the loss landscape through retraining yields new valuable information. Furthermore, the first and third derivatives are also beneficial, as they indicate the extent to which independent variables influence the dependent variable.
Towards General Computer Control: A Multimodal Agent for Red Dead Redemption II as a Case Study
Mar 07, 2024


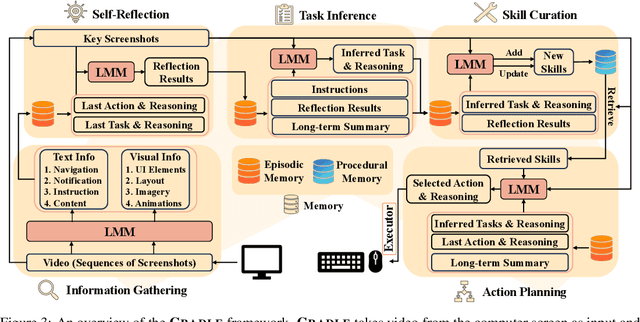
Despite the success in specific tasks and scenarios, existing foundation agents, empowered by large models (LMs) and advanced tools, still cannot generalize to different scenarios, mainly due to dramatic differences in the observations and actions across scenarios. In this work, we propose the General Computer Control (GCC) setting: building foundation agents that can master any computer task by taking only screen images (and possibly audio) of the computer as input, and producing keyboard and mouse operations as output, similar to human-computer interaction. The main challenges of achieving GCC are: 1) the multimodal observations for decision-making, 2) the requirements of accurate control of keyboard and mouse, 3) the need for long-term memory and reasoning, and 4) the abilities of efficient exploration and self-improvement. To target GCC, we introduce Cradle, an agent framework with six main modules, including: 1) information gathering to extract multi-modality information, 2) self-reflection to rethink past experiences, 3) task inference to choose the best next task, 4) skill curation for generating and updating relevant skills for given tasks, 5) action planning to generate specific operations for keyboard and mouse control, and 6) memory for storage and retrieval of past experiences and known skills. To demonstrate the capabilities of generalization and self-improvement of Cradle, we deploy it in the complex AAA game Red Dead Redemption II, serving as a preliminary attempt towards GCC with a challenging target. To our best knowledge, our work is the first to enable LMM-based agents to follow the main storyline and finish real missions in complex AAA games, with minimal reliance on prior knowledge or resources. The project website is at https://baai-agents.github.io/Cradle/.
A Modular End-to-End Multimodal Learning Method for Structured and Unstructured Data
Mar 07, 2024

Multimodal learning is a rapidly growing research field that has revolutionized multitasking and generative modeling in AI. While much of the research has focused on dealing with unstructured data (e.g., language, images, audio, or video), structured data (e.g., tabular data, time series, or signals) has received less attention. However, many industry-relevant use cases involve or can be benefited from both types of data. In this work, we propose a modular, end-to-end multimodal learning method called MAGNUM, which can natively handle both structured and unstructured data. MAGNUM is flexible enough to employ any specialized unimodal module to extract, compress, and fuse information from all available modalities.
ERASOR++: Height Coding Plus Egocentric Ratio Based Dynamic Object Removal for Static Point Cloud Mapping
Mar 08, 2024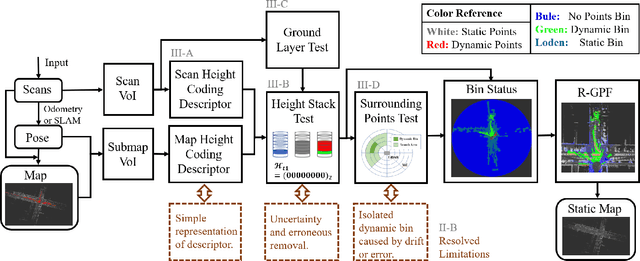
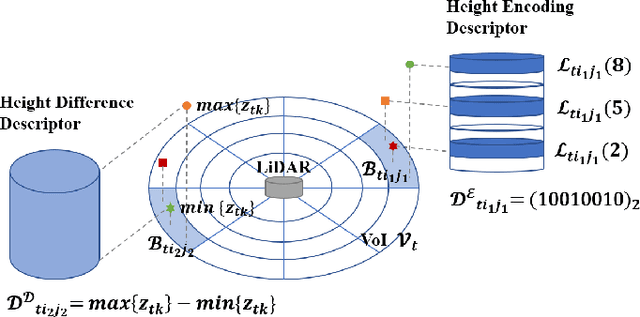
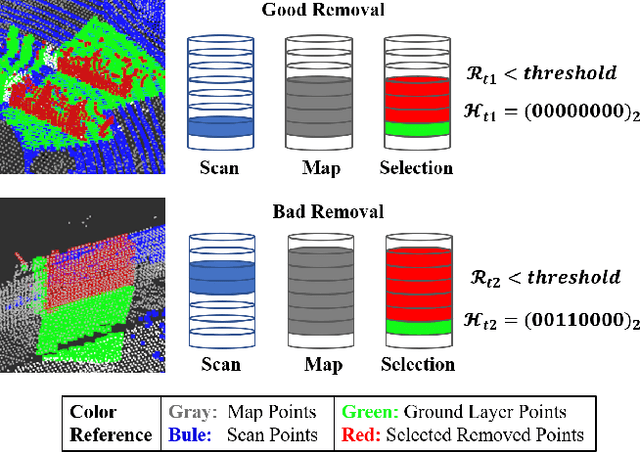
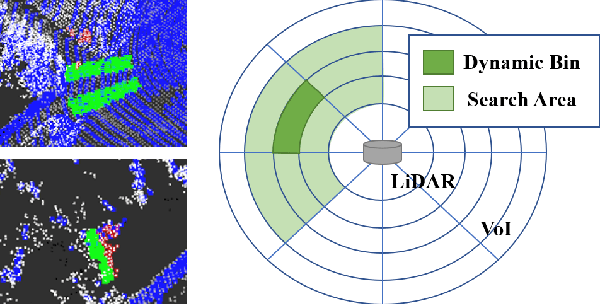
Mapping plays a crucial role in location and navigation within automatic systems. However, the presence of dynamic objects in 3D point cloud maps generated from scan sensors can introduce map distortion and long traces, thereby posing challenges for accurate mapping and navigation. To address this issue, we propose ERASOR++, an enhanced approach based on the Egocentric Ratio of Pseudo Occupancy for effective dynamic object removal. To begin, we introduce the Height Coding Descriptor, which combines height difference and height layer information to encode the point cloud. Subsequently, we propose the Height Stack Test, Ground Layer Test, and Surrounding Point Test methods to precisely and efficiently identify the dynamic bins within point cloud bins, thus overcoming the limitations of prior approaches. Through extensive evaluation on open-source datasets, our approach demonstrates superior performance in terms of precision and efficiency compared to existing methods. Furthermore, the techniques described in our work hold promise for addressing various challenging tasks or aspects through subsequent migration.
DiffuLT: How to Make Diffusion Model Useful for Long-tail Recognition
Mar 08, 2024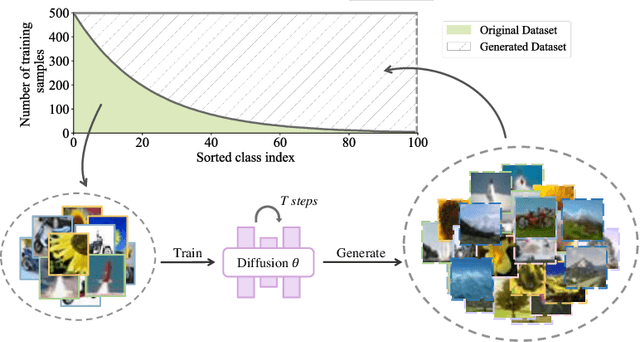
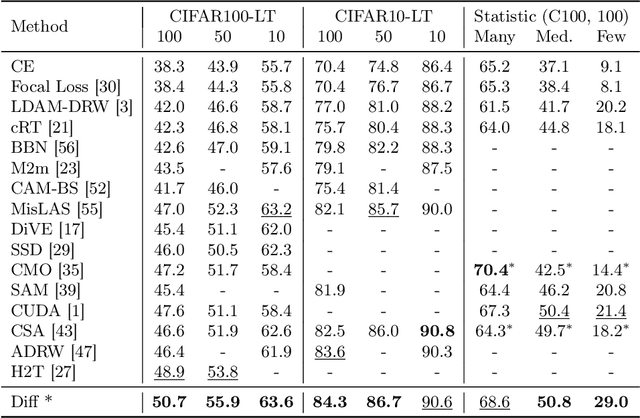
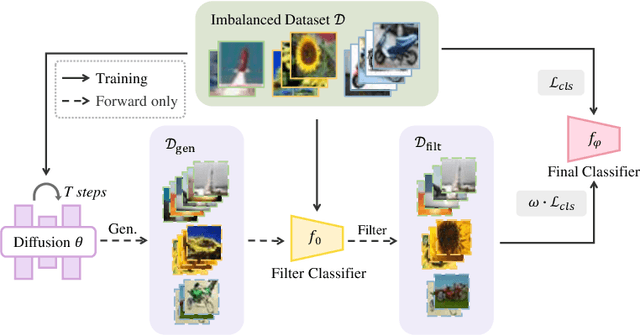
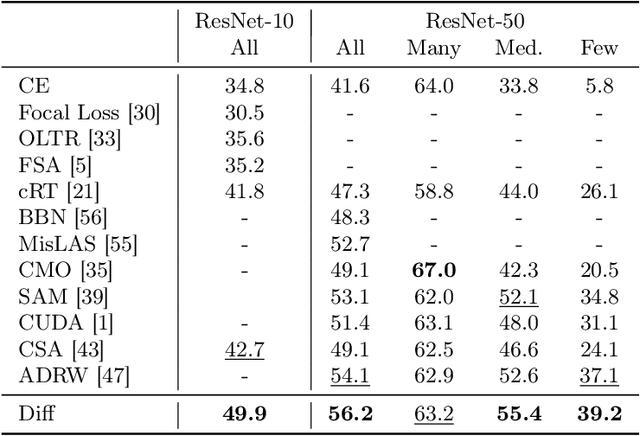
This paper proposes a new pipeline for long-tail (LT) recognition. Instead of re-weighting or re-sampling, we utilize the long-tailed dataset itself to generate a balanced proxy that can be optimized through cross-entropy (CE). Specifically, a randomly initialized diffusion model, trained exclusively on the long-tailed dataset, is employed to synthesize new samples for underrepresented classes. Then, we utilize the inherent information in the original dataset to filter out harmful samples and keep the useful ones. Our strategy, Diffusion model for Long-Tail recognition (DiffuLT), represents a pioneering utilization of generative models in long-tail recognition. DiffuLT achieves state-of-the-art results on CIFAR10-LT, CIFAR100-LT, and ImageNet-LT, surpassing the best competitors with non-trivial margins. Abundant ablations make our pipeline interpretable, too. The whole generation pipeline is done without any external data or pre-trained model weights, making it highly generalizable to real-world long-tailed settings.
Learning Expressive And Generalizable Motion Features For Face Forgery Detection
Mar 08, 2024
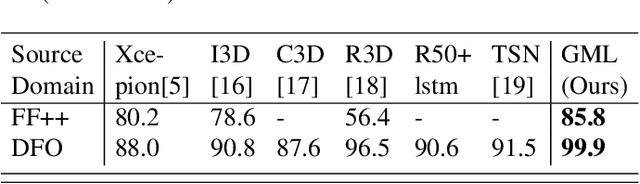
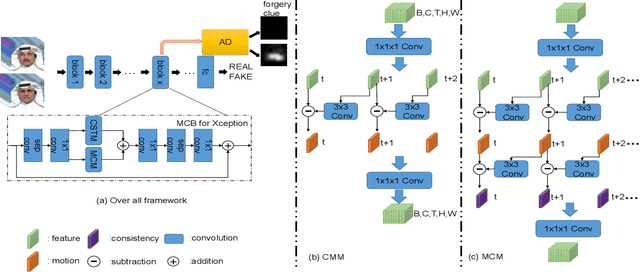

Previous face forgery detection methods mainly focus on appearance features, which may be easily attacked by sophisticated manipulation. Considering the majority of current face manipulation methods generate fake faces based on a single frame, which do not take frame consistency and coordination into consideration, artifacts on frame sequences are more effective for face forgery detection. However, current sequence-based face forgery detection methods use general video classification networks directly, which discard the special and discriminative motion information for face manipulation detection. To this end, we propose an effective sequence-based forgery detection framework based on an existing video classification method. To make the motion features more expressive for manipulation detection, we propose an alternative motion consistency block instead of the original motion features module. To make the learned features more generalizable, we propose an auxiliary anomaly detection block. With these two specially designed improvements, we make a general video classification network achieve promising results on three popular face forgery datasets.
Considering Nonstationary within Multivariate Time Series with Variational Hierarchical Transformer for Forecasting
Mar 08, 2024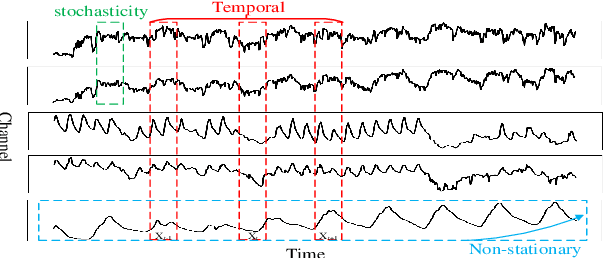
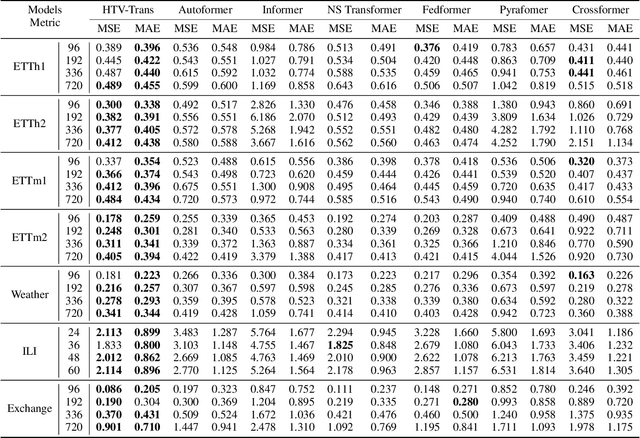
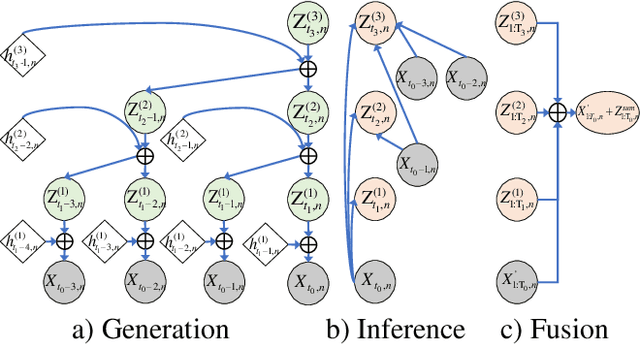
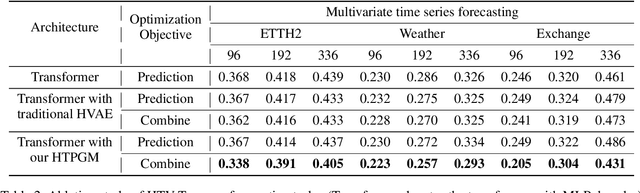
The forecasting of Multivariate Time Series (MTS) has long been an important but challenging task. Due to the non-stationary problem across long-distance time steps, previous studies primarily adopt stationarization method to attenuate the non-stationary problem of the original series for better predictability. However, existing methods always adopt the stationarized series, which ignores the inherent non-stationarity, and has difficulty in modeling MTS with complex distributions due to the lack of stochasticity. To tackle these problems, we first develop a powerful hierarchical probabilistic generative module to consider the non-stationarity and stochastic characteristics within MTS, and then combine it with transformer for a well-defined variational generative dynamic model named Hierarchical Time series Variational Transformer (HTV-Trans), which recovers the intrinsic non-stationary information into temporal dependencies. Being a powerful probabilistic model, HTV-Trans is utilized to learn expressive representations of MTS and applied to forecasting tasks. Extensive experiments on diverse datasets show the efficiency of HTV-Trans on MTS forecasting tasks
Spatial-aware Transformer-GRU Framework for Enhanced Glaucoma Diagnosis from 3D OCT Imaging
Mar 08, 2024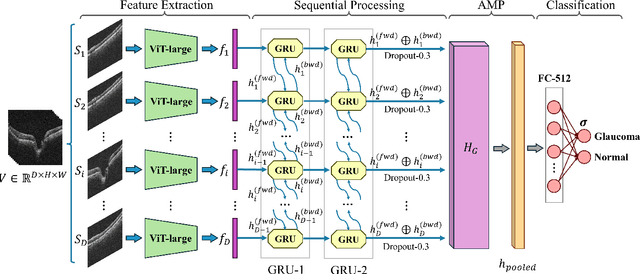
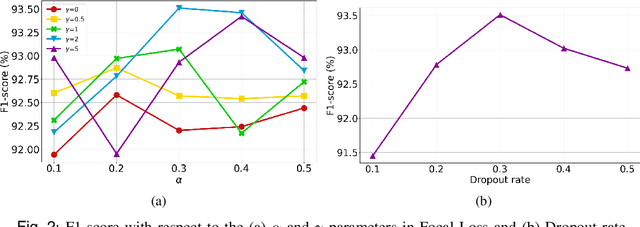
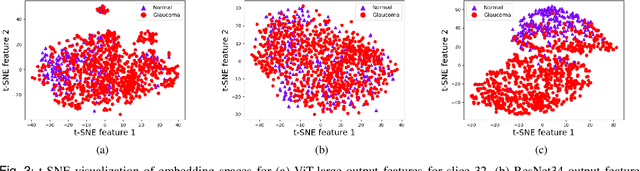
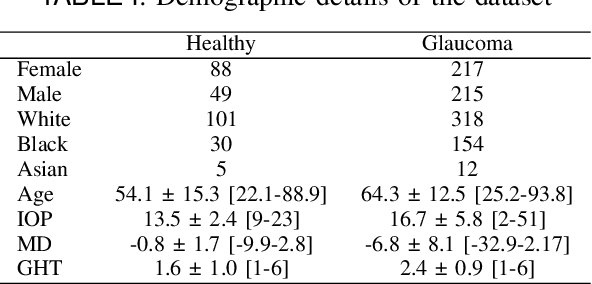
Glaucoma, a leading cause of irreversible blindness, necessitates early detection for accurate and timely intervention to prevent irreversible vision loss. In this study, we present a novel deep learning framework that leverages the diagnostic value of 3D Optical Coherence Tomography (OCT) imaging for automated glaucoma detection. In this framework, we integrate a pre-trained Vision Transformer on retinal data for rich slice-wise feature extraction and a bidirectional Gated Recurrent Unit for capturing inter-slice spatial dependencies. This dual-component approach enables comprehensive analysis of local nuances and global structural integrity, crucial for accurate glaucoma diagnosis. Experimental results on a large dataset demonstrate the superior performance of the proposed method over state-of-the-art ones, achieving an F1-score of 93.58%, Matthews Correlation Coefficient (MCC) of 73.54%, and AUC of 95.24%. The framework's ability to leverage the valuable information in 3D OCT data holds significant potential for enhancing clinical decision support systems and improving patient outcomes in glaucoma management.
Bayesian Hierarchical Probabilistic Forecasting of Intraday Electricity Prices
Mar 08, 2024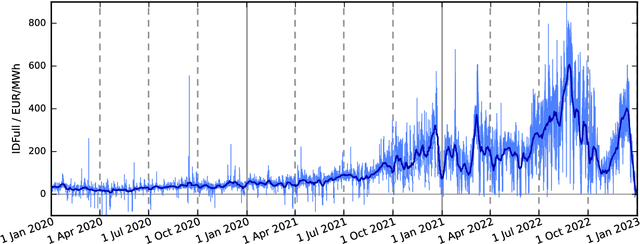

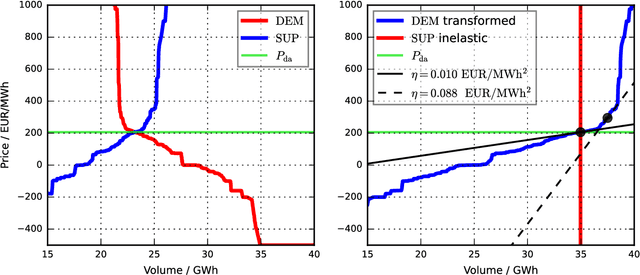
We present a first study of Bayesian forecasting of electricity prices traded on the German continuous intraday market which fully incorporates parameter uncertainty. Our target variable is the IDFull price index, forecasts are given in terms of posterior predictive distributions. For validation we use the exceedingly volatile electricity prices of 2022, which have hardly been the subject of forecasting studies before. As a benchmark model, we use all available intraday transactions at the time of forecast creation to compute a current value for the IDFull. According to the weak-form efficiency hypothesis, it would not be possible to significantly improve this benchmark built from last price information. We do, however, observe statistically significant improvement in terms of both point measures and probability scores. Finally, we challenge the declared gold standard of using LASSO for feature selection in electricity price forecasting by presenting strong statistical evidence that Orthogonal Matching Pursuit (OMP) leads to better forecasting performance.
Aligning Speech to Languages to Enhance Code-switching Speech Recognition
Mar 09, 2024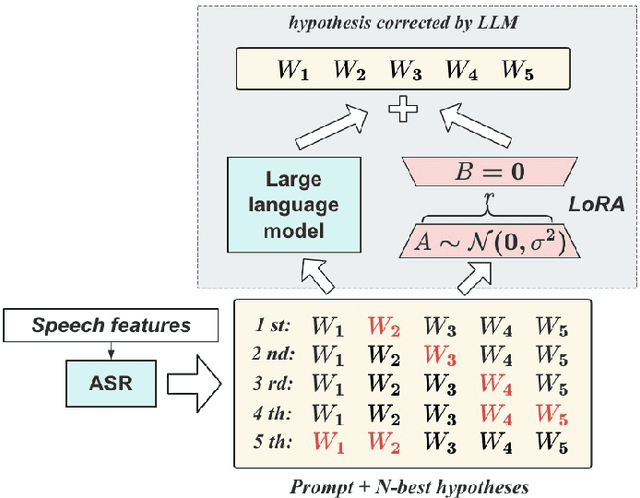
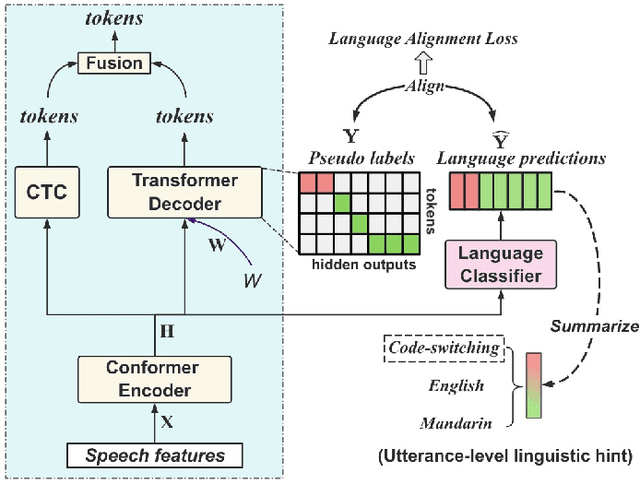
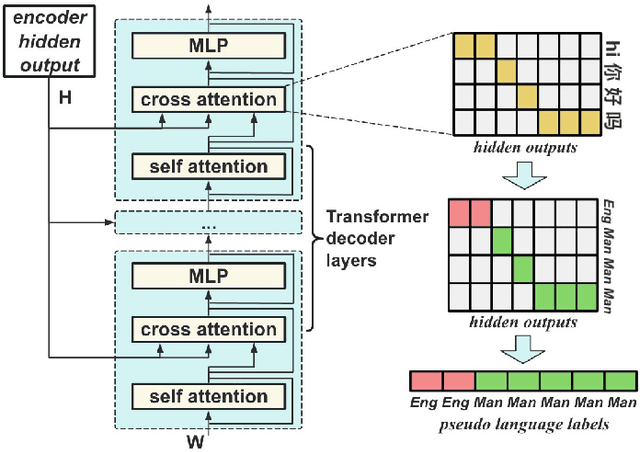
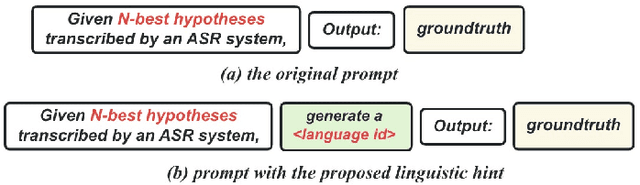
Code-switching (CS) refers to the switching of languages within a speech signal and results in language confusion for automatic speech recognition (ASR). To address language confusion, we propose the language alignment loss that performs frame-level language identification using pseudo language labels learned from the ASR decoder. This eliminates the need for frame-level language annotations. To further tackle the complex token alternatives for language modeling in bilingual scenarios, we propose to employ large language models via a generative error correction method. A linguistic hint that incorporates language information (derived from the proposed language alignment loss and decoded hypotheses) is introduced to guide the prompting of large language models. The proposed methods are evaluated on the SEAME dataset and data from the ASRU 2019 Mandarin-English code-switching speech recognition challenge. The incorporation of the proposed language alignment loss demonstrates a higher CS-ASR performance with only a negligible increase in the number of parameters on both datasets compared to the baseline model. This work also highlights the efficacy of language alignment loss in balancing primary-language-dominant bilingual data during training, with an 8.6% relative improvement on the ASRU dataset compared to the baseline model. Performance evaluation using large language models reveals the advantage of the linguistic hint by achieving 14.1% and 5.5% relative improvement on test sets of the ASRU and SEAME datasets, respectively.