 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Skill Discovery for Quadruped Robots via Unsupervised Learning
Feb 10, 2026Reinforcement learning necessitates meticulous reward shaping by specialists to elicit target behaviors, while imitation learning relies on costly task-specific data. In contrast, unsupervised skill discovery can potentially reduce these burdens by learning a diverse repertoire of useful skills driven by intrinsic motivation. However, existing methods exhibit two key limitations: they typically rely on a single policy to master a versatile repertoire of behaviors without modeling the shared structure or distinctions among them, which results in low learning efficiency; moreover, they are susceptible to reward hacking, where the reward signal increases and converges rapidly while the learned skills display insufficient actual diversity. In this work, we introduce an Orthogonal Mixture-of-Experts (OMoE) architecture that prevents diverse behaviors from collapsing into overlapping representations, enabling a single policy to master a wide spectrum of locomotion skills. In addition, we design a multi-discriminator framework in which different discriminators operate on distinct observation spaces, effectively mitigating reward hacking. We evaluated our method on the 12-DOF Unitree A1 quadruped robot, demonstrating a diverse set of locomotion skills. Our experiments demonstrate that the proposed framework boosts training efficiency and yields an 18.3\% expansion in state-space coverage compared to the baseline.
Training-free LLM-generated Text Detection by Mining Token Probability Sequences
Oct 08, 2024



Large language models (LLMs) have demonstrated remarkable capabilities in generating high-quality texts across diverse domains. However, the potential misuse of LLMs has raised significant concerns, underscoring the urgent need for reliable detection of LLM-generated texts. Conventional training-based detectors often struggle with generalization, particularly in cross-domain and cross-model scenarios. In contrast, training-free methods, which focus on inherent discrepancies through carefully designed statistical features, offer improved generalization and interpretability. Despite this, existing training-free detection methods typically rely on global text sequence statistics, neglecting the modeling of local discriminative features, thereby limiting their detection efficacy. In this work, we introduce a novel training-free detector, termed \textbf{Lastde} that synergizes local and global statistics for enhanced detection. For the first time, we introduce time series analysis to LLM-generated text detection, capturing the temporal dynamics of token probability sequences. By integrating these local statistics with global ones, our detector reveals significant disparities between human and LLM-generated texts. We also propose an efficient alternative, \textbf{Lastde++} to enable real-time detection. Extensive experiments on six datasets involving cross-domain, cross-model, and cross-lingual detection scenarios, under both white-box and black-box settings, demonstrated that our method consistently achieves state-of-the-art performance. Furthermore, our approach exhibits greater robustness against paraphrasing attacks compared to existing baseline methods.
Towards General Computer Control: A Multimodal Agent for Red Dead Redemption II as a Case Study
Mar 07, 2024Despite the success in specific tasks and scenarios, existing foundation agents, empowered by large models (LMs) and advanced tools, still cannot generalize to different scenarios, mainly due to dramatic differences in the observations and actions across scenarios. In this work, we propose the General Computer Control (GCC) setting: building foundation agents that can master any computer task by taking only screen images (and possibly audio) of the computer as input, and producing keyboard and mouse operations as output, similar to human-computer interaction. The main challenges of achieving GCC are: 1) the multimodal observations for decision-making, 2) the requirements of accurate control of keyboard and mouse, 3) the need for long-term memory and reasoning, and 4) the abilities of efficient exploration and self-improvement. To target GCC, we introduce Cradle, an agent framework with six main modules, including: 1) information gathering to extract multi-modality information, 2) self-reflection to rethink past experiences, 3) task inference to choose the best next task, 4) skill curation for generating and updating relevant skills for given tasks, 5) action planning to generate specific operations for keyboard and mouse control, and 6) memory for storage and retrieval of past experiences and known skills. To demonstrate the capabilities of generalization and self-improvement of Cradle, we deploy it in the complex AAA game Red Dead Redemption II, serving as a preliminary attempt towards GCC with a challenging target. To our best knowledge, our work is the first to enable LMM-based agents to follow the main storyline and finish real missions in complex AAA games, with minimal reliance on prior knowledge or resources. The project website is at https://baai-agents.github.io/Cradle/.
A Deep Reinforcement Learning Approach towards Pendulum Swing-up Problem based on TF-Agents
Jun 17, 2021
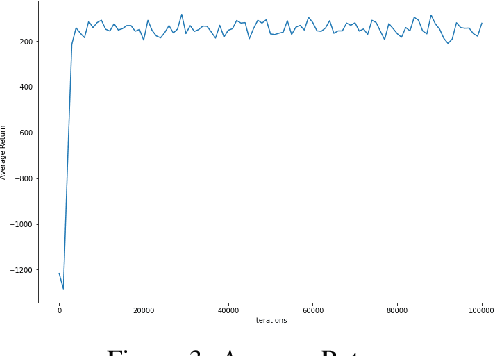
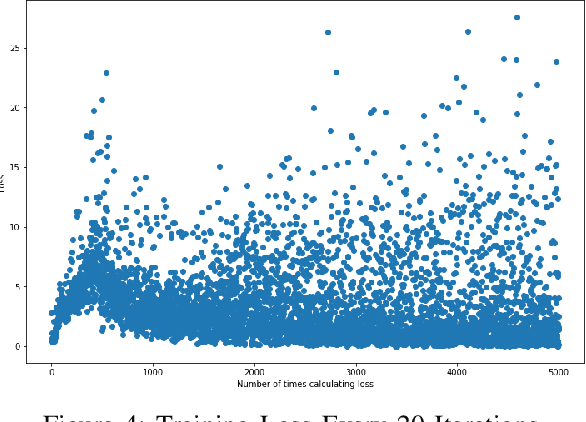
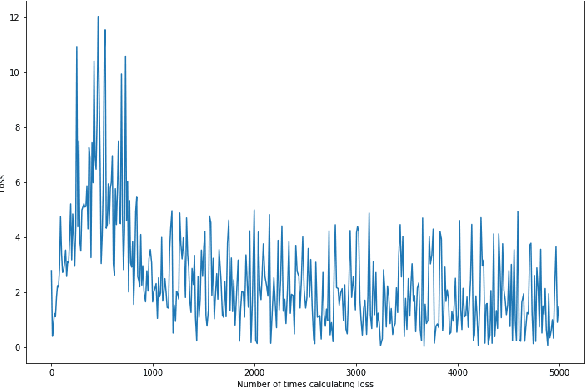
Adapting the idea of training CartPole with Deep Q-learning agent, we are able to find a promising result that prevent the pole from falling down. The capacity of reinforcement learning (RL) to learn from the interaction between the environment and agent provides an optimal control strategy. In this paper, we aim to solve the classic pendulum swing-up problem that making the learned pendulum to be in upright position and balanced. Deep Deterministic Policy Gradient algorithm is introduced to operate over continuous action domain in this problem. Salient results of optimal pendulum are proved with increasing average return, decreasing loss, and live video in the code part.