 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generalization of generative model for neuronal ensemble inference method
Nov 07, 2022
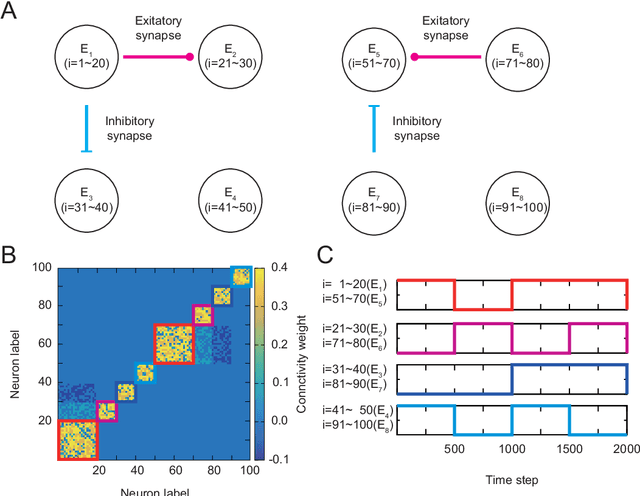

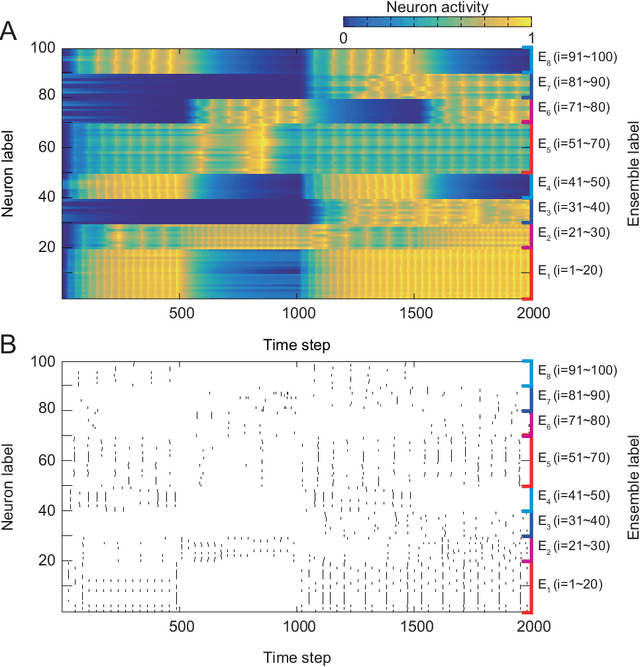
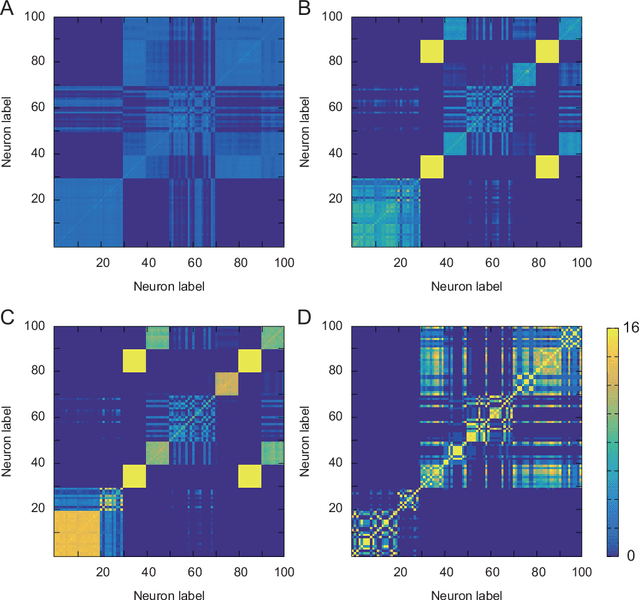
Various brain functions that are necessary to maintain life activities materialize through the interaction of countless neurons. Therefore, it is important to analyze the structure of functional neuronal network. To elucidate the mechanism of brain function, many studies are being actively conducted on the structure of functional neuronal ensemble and hub, including all areas of neuroscience. In addition, recent study suggests that the existence of functional neuronal ensembles and hubs contributes to the efficiency of information processing. For these reasons, there is a demand for methods to infer functional neuronal ensembles from neuronal activity data, and methods based on Bayesian inference have been proposed. However, there is a problem in modeling the activity in Bayesian inference. The features of each neuron's activity have non-stationarity depending on physiological experimental conditions. As a result, the assumption of stationarity in Bayesian inference model impedes inference, which leads to destabilization of inference results and degradation of inference accuracy. In this study, we extend the expressivity of the model in the previous study and improve it to a soft clustering method, which can be applied to activity data with non-stationarity. In addition, for the effectiveness of the method, we apply the developed method to synthetic data generated by the leaky-integrate-and-fire model, and discuss the result.
NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields
Oct 24, 2022
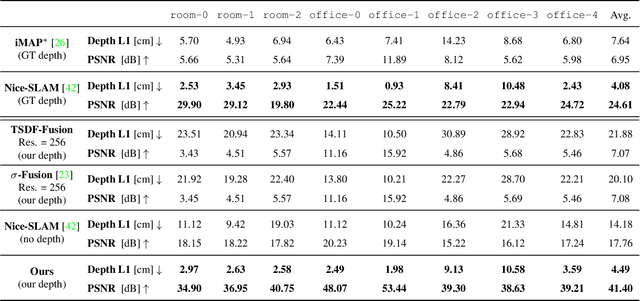
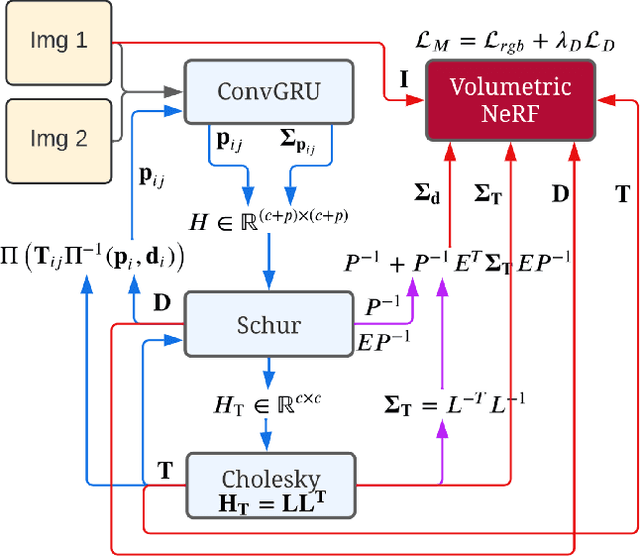

We propose a novel geometric and photometric 3D mapping pipeline for accurate and real-time scene reconstruction from monocular images. To achieve this, we leverage recent advances in dense monocular SLAM and real-time hierarchical volumetric neural radiance fields. Our insight is that dense monocular SLAM provides the right information to fit a neural radiance field of the scene in real-time, by providing accurate pose estimates and depth-maps with associated uncertainty. With our proposed uncertainty-based depth loss, we achieve not only good photometric accuracy, but also great geometric accuracy. In fact, our proposed pipeline achieves better geometric and photometric accuracy than competing approaches (up to 179% better PSNR and 86% better L1 depth), while working in real-time and using only monocular images.
BoundED: Neural Boundary and Edge Detection in 3D Point Clouds via Local Neighborhood Statistics
Oct 24, 2022
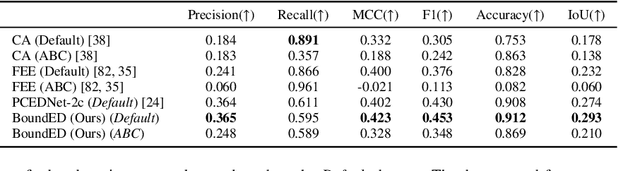
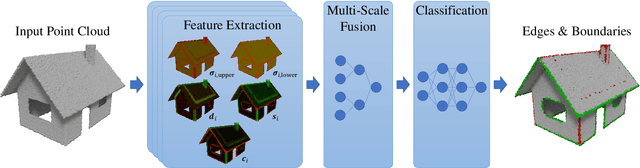
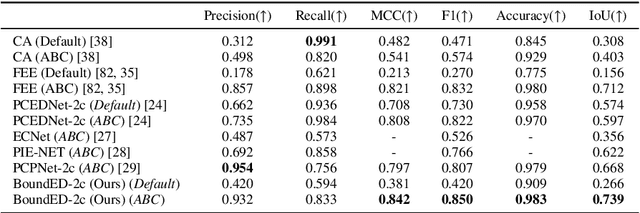
Extracting high-level structural information from 3D point clouds is challenging but essential for tasks like urban planning or autonomous driving requiring an advanced understanding of the scene at hand. Existing approaches are still not able to produce high-quality results consistently while being fast enough to be deployed in scenarios requiring interactivity. We propose to utilize a novel set of features describing the local neighborhood on a per-point basis via first and second order statistics as input for a simple and compact classification network to distinguish between non-edge, sharp-edge, and boundary points in the given data. Leveraging this feature embedding enables our algorithm to outperform the state-of-the-art techniques in terms of quality and processing time.
Implementation of Trained Factorization Machine Recommendation System on Quantum Annealer
Oct 24, 2022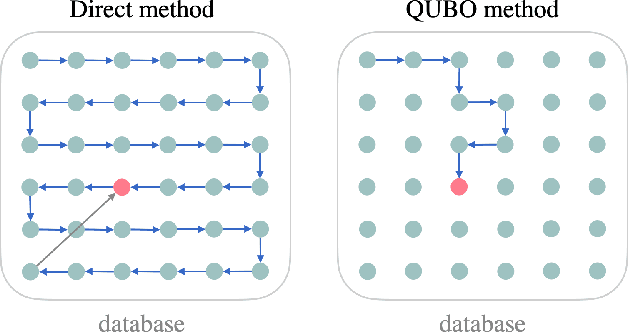
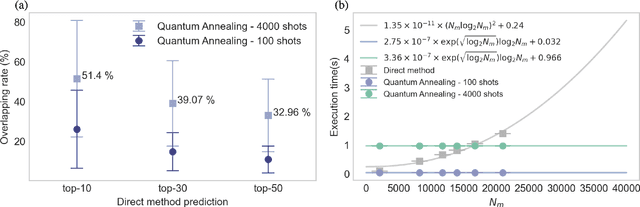
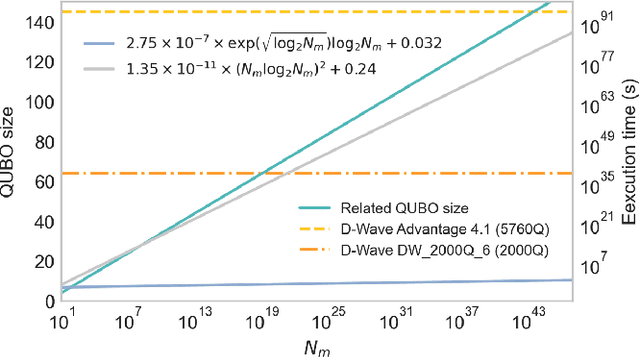
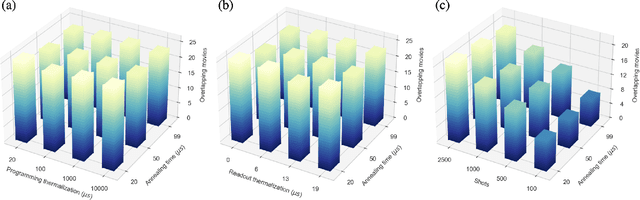
Factorization Machine (FM) is the most commonly used model to build a recommendation system since it can incorporate side information to improve performance. However, producing item suggestions for a given user with a trained FM is time-consuming. It requires a run-time of $O((N_m \log N_m)^2)$, where $N_m$ is the number of items in the dataset. To address this problem, we propose a quadratic unconstrained binary optimization (QUBO) scheme to combine with FM and apply quantum annealing (QA) computation. Compared to classical methods, this hybrid algorithm provides a faster than quadratic speedup in finding good user suggestions. We then demonstrate the aforementioned computational advantage on current NISQ hardware by experimenting with a real example on a D-Wave annealer.
Detecting Disengagement in Virtual Learning as an Anomaly
Nov 13, 2022
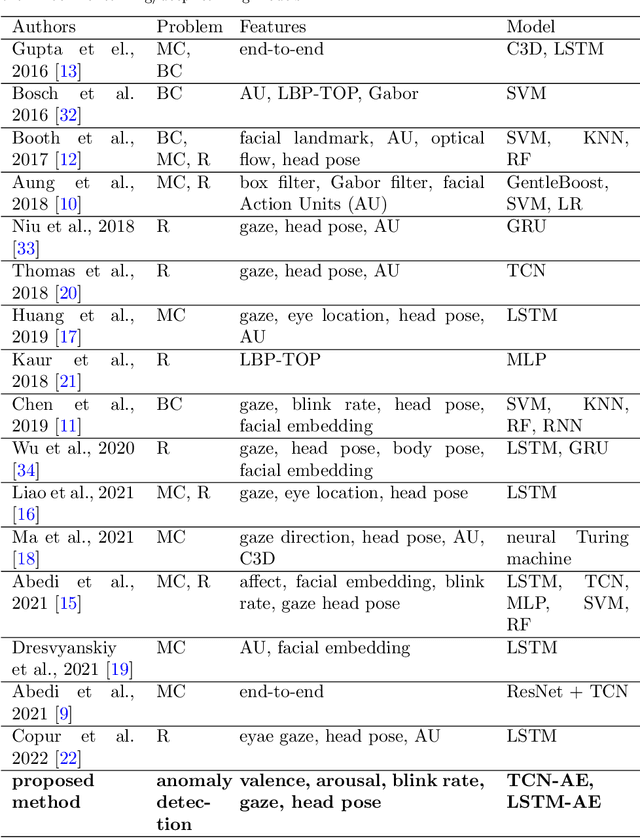
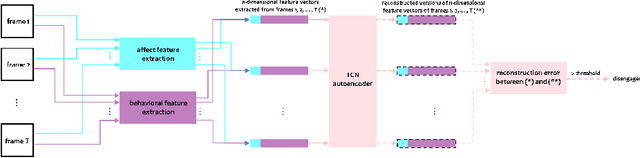

Student engagement is an important factor in meeting the goals of virtual learning programs. Automatic measurement of student engagement provides helpful information for instructors to meet learning program objectives and individualize program delivery. Many existing approaches solve video-based engagement measurement using the traditional frameworks of binary classification (classifying video snippets into engaged or disengaged classes), multi-class classification (classifying video snippets into multiple classes corresponding to different levels of engagement), or regression (estimating a continuous value corresponding to the level of engagement). However, we observe that while the engagement behaviour is mostly well-defined (e.g., focused, not distracted), disengagement can be expressed in various ways. In addition, in some cases, the data for disengaged classes may not be sufficient to train generalizable binary or multi-class classifiers. To handle this situation, in this paper, for the first time, we formulate detecting disengagement in virtual learning as an anomaly detection problem. We design various autoencoders, including temporal convolutional network autoencoder, long-short-term memory autoencoder, and feedforward autoencoder using different behavioral and affect features for video-based student disengagement detection. The result of our experiments on two publicly available student engagement datasets, DAiSEE and EmotiW, shows the superiority of the proposed approach for disengagement detection as an anomaly compared to binary classifiers for classifying videos into engaged versus disengaged classes (with an average improvement of 9% on the area under the curve of the receiver operating characteristic curve and 22% on the area under the curve of the precision-recall curve).
Towards Zero-Shot Code-Switched Speech Recognition
Nov 02, 2022
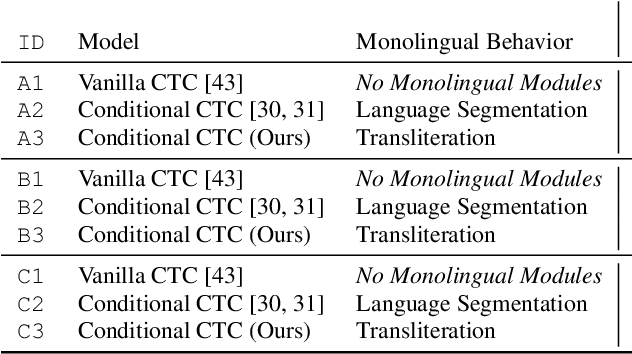
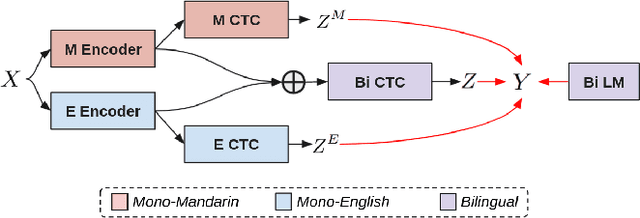

In this work, we seek to build effective code-switched (CS) automatic speech recognition systems (ASR) under the zero-shot setting where no transcribed CS speech data is available for training. Previously proposed frameworks which conditionally factorize the bilingual task into its constituent monolingual parts are a promising starting point for leveraging monolingual data efficiently. However, these methods require the monolingual modules to perform language segmentation. That is, each monolingual module has to simultaneously detect CS points and transcribe speech segments of one language while ignoring those of other languages -- not a trivial task. We propose to simplify each monolingual module by allowing them to transcribe all speech segments indiscriminately with a monolingual script (i.e. transliteration). This simple modification passes the responsibility of CS point detection to subsequent bilingual modules which determine the final output by considering multiple monolingual transliterations along with external language model information. We apply this transliteration-based approach in an end-to-end differentiable neural network and demonstrate its efficacy for zero-shot CS ASR on Mandarin-English SEAME test sets.
Deep Virtual-to-Real Distillation for Pedestrian Crossing Prediction
Nov 02, 2022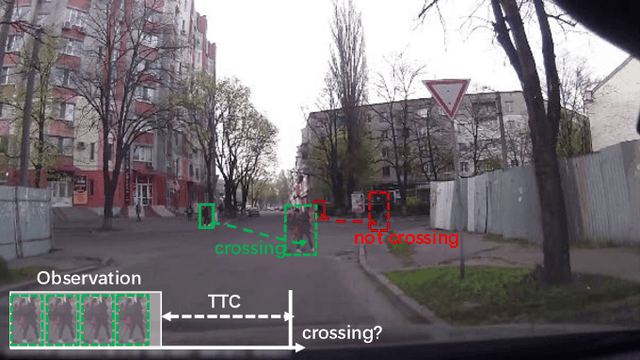
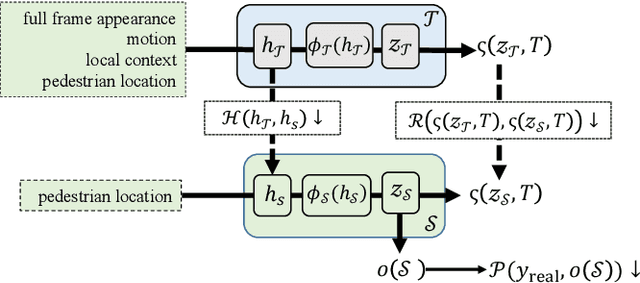
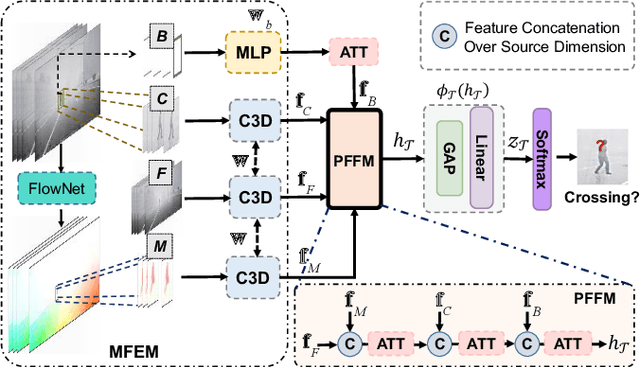

Pedestrian crossing is one of the most typical behavior which conflicts with natural driving behavior of vehicles. Consequently, pedestrian crossing prediction is one of the primary task that influences the vehicle planning for safe driving. However, current methods that rely on the practically collected data in real driving scenes cannot depict and cover all kinds of scene condition in real traffic world. To this end, we formulate a deep virtual to real distillation framework by introducing the synthetic data that can be generated conveniently, and borrow the abundant information of pedestrian movement in synthetic videos for the pedestrian crossing prediction in real data with a simple and lightweight implementation. In order to verify this framework, we construct a benchmark with 4667 virtual videos owning about 745k frames (called Virtual-PedCross-4667), and evaluate the proposed method on two challenging datasets collected in real driving situations, i.e., JAAD and PIE datasets. State-of-the-art performance of this framework is demonstrated by exhaustive experiment analysis. The dataset and code can be downloaded from the website \url{http://www.lotvs.net/code_data/}.
Learning a Condensed Frame for Memory-Efficient Video Class-Incremental Learning
Nov 02, 2022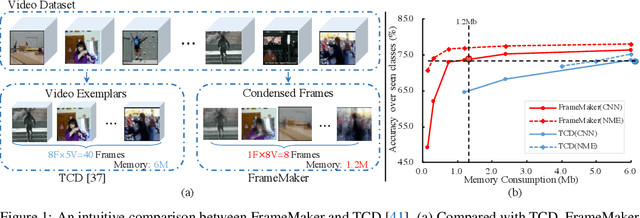
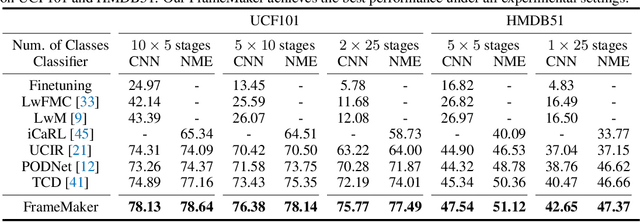
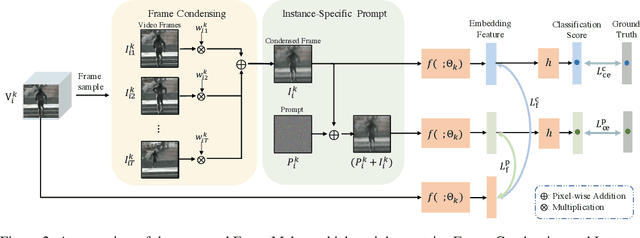
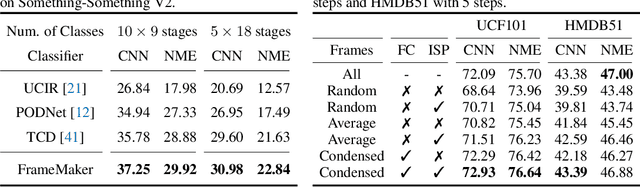
Recent incremental learning for action recognition usually stores representative videos to mitigate catastrophic forgetting. However, only a few bulky videos can be stored due to the limited memory. To address this problem, we propose FrameMaker, a memory-efficient video class-incremental learning approach that learns to produce a condensed frame for each selected video. Specifically, FrameMaker is mainly composed of two crucial components: Frame Condensing and Instance-Specific Prompt. The former is to reduce the memory cost by preserving only one condensed frame instead of the whole video, while the latter aims to compensate the lost spatio-temporal details in the Frame Condensing stage. By this means, FrameMaker enables a remarkable reduction in memory but keep enough information that can be applied to following incremental tasks. Experimental results on multiple challenging benchmarks, i.e., HMDB51, UCF101 and Something-Something V2, demonstrate that FrameMaker can achieve better performance to recent advanced methods while consuming only 20% memory. Additionally, under the same memory consumption conditions, FrameMaker significantly outperforms existing state-of-the-arts by a convincing margin.
Spatial Reasoning for Few-Shot Object Detection
Nov 02, 2022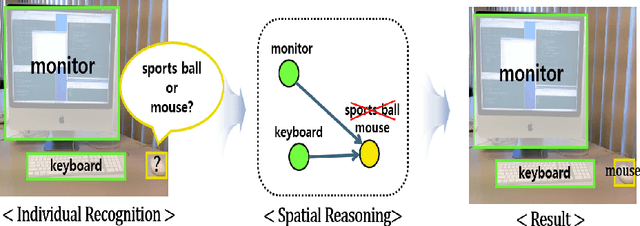
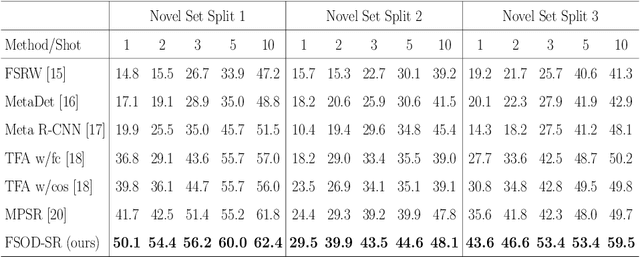
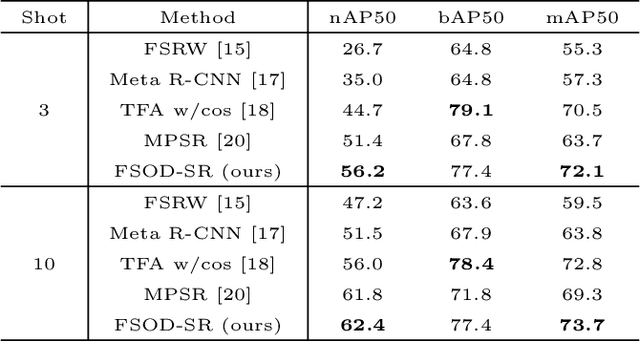
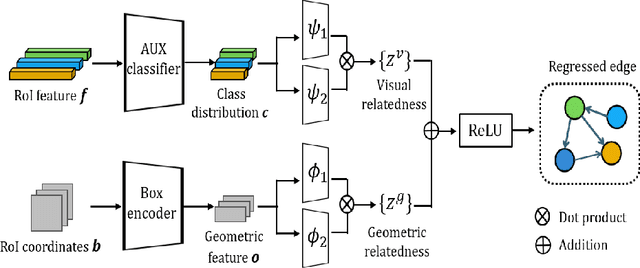
Although modern object detectors rely heavily on a significant amount of training data, humans can easily detect novel objects using a few training examples. The mechanism of the human visual system is to interpret spatial relationships among various objects and this process enables us to exploit contextual information by considering the co-occurrence of objects. Thus, we propose a spatial reasoning framework that detects novel objects with only a few training examples in a context. We infer geometric relatedness between novel and base RoIs (Region-of-Interests) to enhance the feature representation of novel categories using an object detector well trained on base categories. We employ a graph convolutional network as the RoIs and their relatedness are defined as nodes and edges, respectively. Furthermore, we present spatial data augmentation to overcome the few-shot environment where all objects and bounding boxes in an image are resized randomly. Using the PASCAL VOC and MS COCO datasets, we demonstrate that the proposed method significantly outperforms the state-of-the-art methods and verify its efficacy through extensive ablation studies.
Dialect-robust Evaluation of Generated Text
Nov 02, 2022
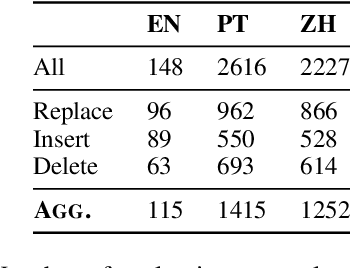


Evaluation metrics that are not robust to dialect variation make it impossible to tell how well systems perform for many groups of users, and can even penalize systems for producing text in lower-resource dialects. However, currently, there exists no way to quantify how metrics respond to change in the dialect of a generated utterance. We thus formalize dialect robustness and dialect awareness as goals for NLG evaluation metrics. We introduce a suite of methods and corresponding statistical tests one can use to assess metrics in light of the two goals. Applying the suite to current state-of-the-art metrics, we demonstrate that they are not dialect-robust and that semantic perturbations frequently lead to smaller decreases in a metric than the introduction of dialect features. As a first step to overcome this limitation, we propose a training schema, NANO, which introduces regional and language information to the pretraining process of a metric. We demonstrate that NANO provides a size-efficient way for models to improve the dialect robustness while simultaneously improving their performance on the standard metric benchmark.