 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Data Generation and Differential Privacy using Tensor Networks' Matrix Product States (MPS)
Aug 08, 2025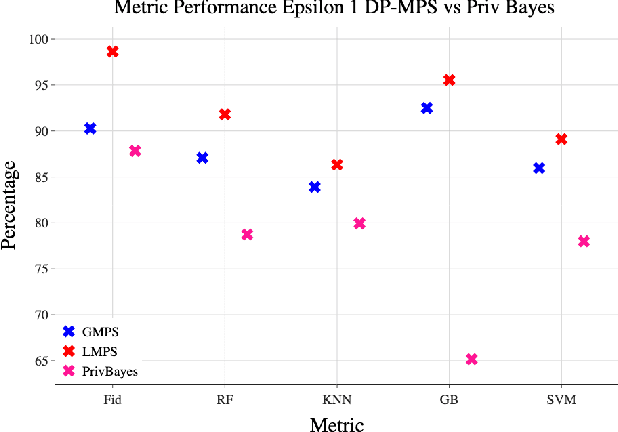
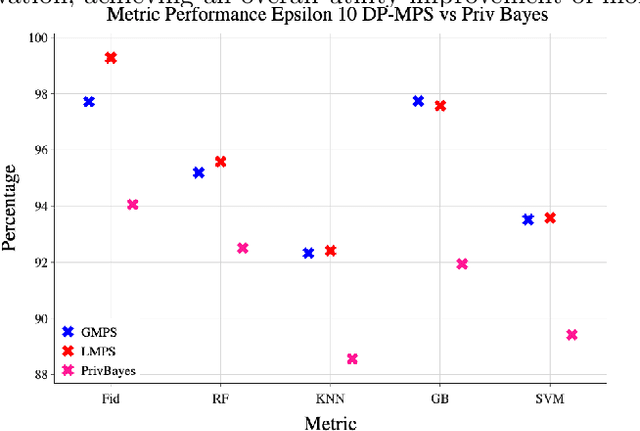
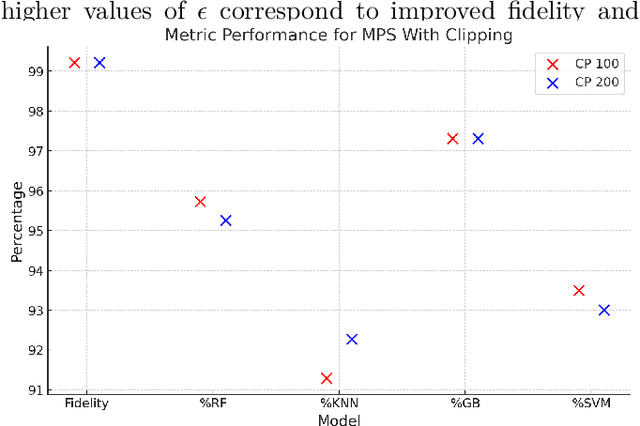
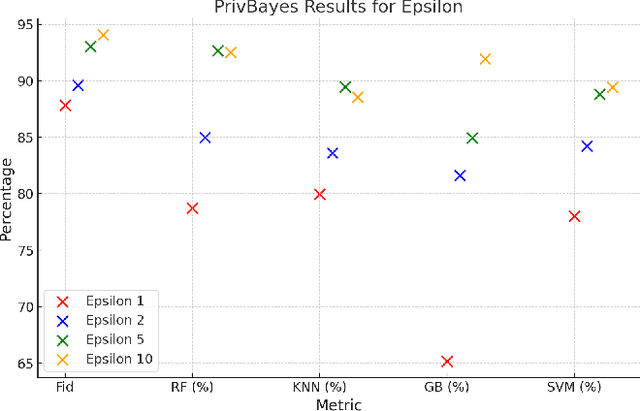
Synthetic data generation is a key technique in modern artificial intelligence, addressing data scarcity, privacy constraints, and the need for diverse datasets in training robust models. In this work, we propose a method for generating privacy-preserving high-quality synthetic tabular data using Tensor Networks, specifically Matrix Product States (MPS). We benchmark the MPS-based generative model against state-of-the-art models such as CTGAN, VAE, and PrivBayes, focusing on both fidelity and privacy-preserving capabilities. To ensure differential privacy (DP), we integrate noise injection and gradient clipping during training, enabling privacy guarantees via R\'enyi Differential Privacy accounting. Across multiple metrics analyzing data fidelity and downstream machine learning task performance, our results show that MPS outperforms classical models, particularly under strict privacy constraints. This work highlights MPS as a promising tool for privacy-aware synthetic data generation. By combining the expressive power of tensor network representations with formal privacy mechanisms, the proposed approach offers an interpretable and scalable alternative for secure data sharing. Its structured design facilitates integration into sensitive domains where both data quality and confidentiality are critical.
OPEN: A Benchmark Dataset and Baseline for Older Adult Patient Engagement Recognition in Virtual Rehabilitation Learning Environments
Jul 23, 2025Engagement in virtual learning is essential for participant satisfaction, performance, and adherence, particularly in online education and virtual rehabilitation, where interactive communication plays a key role. Yet, accurately measuring engagement in virtual group settings remains a challenge. There is increasing interest in using artificial intelligence (AI) for large-scale, real-world, automated engagement recognition. While engagement has been widely studied in younger academic populations, research and datasets focused on older adults in virtual and telehealth learning settings remain limited. Existing methods often neglect contextual relevance and the longitudinal nature of engagement across sessions. This paper introduces OPEN (Older adult Patient ENgagement), a novel dataset supporting AI-driven engagement recognition. It was collected from eleven older adults participating in weekly virtual group learning sessions over six weeks as part of cardiac rehabilitation, producing over 35 hours of data, making it the largest dataset of its kind. To protect privacy, raw video is withheld; instead, the released data include facial, hand, and body joint landmarks, along with affective and behavioral features extracted from video. Annotations include binary engagement states, affective and behavioral labels, and context-type indicators, such as whether the instructor addressed the group or an individual. The dataset offers versions with 5-, 10-, 30-second, and variable-length samples. To demonstrate utility, multiple machine learning and deep learning models were trained, achieving engagement recognition accuracy of up to 81 percent. OPEN provides a scalable foundation for personalized engagement modeling in aging populations and contributes to broader engagement recognition research.
Explaining Recovery Trajectories of Older Adults Post Lower-Limb Fracture Using Modality-wise Multiview Clustering and Large Language Models
Jun 13, 2025Interpreting large volumes of high-dimensional, unlabeled data in a manner that is comprehensible to humans remains a significant challenge across various domains. In unsupervised healthcare data analysis, interpreting clustered data can offer meaningful insights into patients' health outcomes, which hold direct implications for healthcare providers. This paper addresses the problem of interpreting clustered sensor data collected from older adult patients recovering from lower-limb fractures in the community. A total of 560 days of multimodal sensor data, including acceleration, step count, ambient motion, GPS location, heart rate, and sleep, alongside clinical scores, were remotely collected from patients at home. Clustering was first carried out separately for each data modality to assess the impact of feature sets extracted from each modality on patients' recovery trajectories. Then, using context-aware prompting, a large language model was employed to infer meaningful cluster labels for the clusters derived from each modality. The quality of these clusters and their corresponding labels was validated through rigorous statistical testing and visualization against clinical scores collected alongside the multimodal sensor data. The results demonstrated the statistical significance of most modality-specific cluster labels generated by the large language model with respect to clinical scores, confirming the efficacy of the proposed method for interpreting sensor data in an unsupervised manner. This unsupervised data analysis approach, relying solely on sensor data, enables clinicians to identify at-risk patients and take timely measures to improve health outcomes.
Adaptive Per-Tree Canopy Volume Estimation Using Mobile LiDAR in Structured and Unstructured Orchards
Jun 09, 2025We present a real-time system for per-tree canopy volume estimation using mobile LiDAR data collected during routine robotic navigation. Unlike prior approaches that rely on static scans or assume uniform orchard structures, our method adapts to varying field geometries via an integrated pipeline of LiDAR-inertial odometry, adaptive segmentation, and geometric reconstruction. We evaluate the system across two commercial orchards, one pistachio orchard with regular spacing and one almond orchard with dense, overlapping crowns. A hybrid clustering strategy combining DBSCAN and spectral clustering enables robust per-tree segmentation, achieving 93% success in pistachio and 80% in almond, with strong agreement to drone derived canopy volume estimates. This work advances scalable, non-intrusive tree monitoring for structurally diverse orchard environments.
Supervised Contrastive Learning for Ordinal Engagement Measurement
May 27, 2025Student engagement plays a crucial role in the successful delivery of educational programs. Automated engagement measurement helps instructors monitor student participation, identify disengagement, and adapt their teaching strategies to enhance learning outcomes effectively. This paper identifies two key challenges in this problem: class imbalance and incorporating order into engagement levels rather than treating it as mere categories. Then, a novel approach to video-based student engagement measurement in virtual learning environments is proposed that utilizes supervised contrastive learning for ordinal classification of engagement. Various affective and behavioral features are extracted from video samples and utilized to train ordinal classifiers within a supervised contrastive learning framework (with a sequential classifier as the encoder). A key step involves the application of diverse time-series data augmentation techniques to these feature vectors, enhancing model training. The effectiveness of the proposed method was evaluated using a publicly available dataset for engagement measurement, DAiSEE, containing videos of students who participated in virtual learning programs. The results demonstrate the robust ability of the proposed method for the classification of the engagement level. This approach promises a significant contribution to understanding and enhancing student engagement in virtual learning environments.
Dynamics of Affective States During Takeover Requests in Conditionally Automated Driving Among Older Adults with and without Cognitive Impairment
May 23, 2025



Driving is a key component of independence and quality of life for older adults. However, cognitive decline associated with conditions such as mild cognitive impairment and dementia can compromise driving safety and often lead to premature driving cessation. Conditionally automated vehicles, which require drivers to take over control when automation reaches its operational limits, offer a potential assistive solution. However, their effectiveness depends on the driver's ability to respond to takeover requests (TORs) in a timely and appropriate manner. Understanding emotional responses during TORs can provide insight into drivers' engagement, stress levels, and readiness to resume control, particularly in cognitively vulnerable populations. This study investigated affective responses, measured via facial expression analysis of valence and arousal, during TORs among cognitively healthy older adults and those with cognitive impairment. Facial affect data were analyzed across different road geometries and speeds to evaluate within- and between-group differences in affective states. Within-group comparisons using the Wilcoxon signed-rank test revealed significant changes in valence and arousal during TORs for both groups. Cognitively healthy individuals showed adaptive increases in arousal under higher-demand conditions, while those with cognitive impairment exhibited reduced arousal and more positive valence in several scenarios. Between-group comparisons using the Mann-Whitney U test indicated that cognitively impaired individuals displayed lower arousal and higher valence than controls across different TOR conditions. These findings suggest reduced emotional response and awareness in cognitively impaired drivers, highlighting the need for adaptive vehicle systems that detect affective states and support safe handovers for vulnerable users.
One-Shot Federated Unsupervised Domain Adaptation with Scaled Entropy Attention and Multi-Source Smoothed Pseudo Labeling
Mar 13, 2025



Federated Learning (FL) is a promising approach for privacy-preserving collaborative learning. However, it faces significant challenges when dealing with domain shifts, especially when each client has access only to its source data and cannot share it during target domain adaptation. Moreover, FL methods often require high communication overhead due to multiple rounds of model updates between clients and the server. We propose a one-shot Federated Unsupervised Domain Adaptation (FUDA) method to address these limitations. Specifically, we introduce Scaled Entropy Attention (SEA) for model aggregation and Multi-Source Pseudo Labeling (MSPL) for target domain adaptation. SEA uses scaled prediction entropy on target domain to assign higher attention to reliable models. This improves the global model quality and ensures balanced weighting of contributions. MSPL distills knowledge from multiple source models to generate pseudo labels and manage noisy labels using smoothed soft-label cross-entropy (SSCE). Our approach outperforms state-of-the-art methods across four standard benchmarks while reducing communication and computation costs, making it highly suitable for real-world applications. The implementation code will be made publicly available upon publication.
Multimodal Sensor Dataset for Monitoring Older Adults Post Lower-Limb Fractures in Community Settings
Jan 23, 2025Lower-Limb Fractures (LLF) are a major health concern for older adults, often leading to reduced mobility and prolonged recovery, potentially impairing daily activities and independence. During recovery, older adults frequently face social isolation and functional decline, complicating rehabilitation and adversely affecting physical and mental health. Multi-modal sensor platforms that continuously collect data and analyze it using machine-learning algorithms can remotely monitor this population and infer health outcomes. They can also alert clinicians to individuals at risk of isolation and decline. This paper presents a new publicly available multi-modal sensor dataset, MAISON-LLF, collected from older adults recovering from LLF in community settings. The dataset includes data from smartphone and smartwatch sensors, motion detectors, sleep-tracking mattresses, and clinical questionnaires on isolation and decline. The dataset was collected from ten older adults living alone at home for eight weeks each, totaling 560 days of 24-hour sensor data. For technical validation, supervised machine-learning and deep-learning models were developed using the sensor and clinical questionnaire data, providing a foundational comparison for the research community.
UlcerGPT: A Multimodal Approach Leveraging Large Language and Vision Models for Diabetic Foot Ulcer Image Transcription
Oct 02, 2024



Diabetic foot ulcers (DFUs) are a leading cause of hospitalizations and lower limb amputations, placing a substantial burden on patients and healthcare systems. Early detection and accurate classification of DFUs are critical for preventing serious complications, yet many patients experience delays in receiving care due to limited access to specialized services. Telehealth has emerged as a promising solution, improving access to care and reducing the need for in-person visits. The integration of artificial intelligence and pattern recognition into telemedicine has further enhanced DFU management by enabling automatic detection, classification, and monitoring from images. Despite advancements in artificial intelligence-driven approaches for DFU image analysis, the application of large language models for DFU image transcription has not yet been explored. To address this gap, we introduce UlcerGPT, a novel multimodal approach leveraging large language and vision models for DFU image transcription. This framework combines advanced vision and language models, such as Large Language and Vision Assistant and Chat Generative Pre-trained Transformer, to transcribe DFU images by jointly detecting, classifying, and localizing regions of interest. Through detailed experiments on a public dataset, evaluated by expert clinicians, UlcerGPT demonstrates promising results in the accuracy and efficiency of DFU transcription, offering potential support for clinicians in delivering timely care via telemedicine.
EUDA: An Efficient Unsupervised Domain Adaptation via Self-Supervised Vision Transformer
Jul 31, 2024Unsupervised domain adaptation (UDA) aims to mitigate the domain shift issue, where the distribution of training (source) data differs from that of testing (target) data. Many models have been developed to tackle this problem, and recently vision transformers (ViTs) have shown promising results. However, the complexity and large number of trainable parameters of ViTs restrict their deployment in practical applications. This underscores the need for an efficient model that not only reduces trainable parameters but also allows for adjustable complexity based on specific needs while delivering comparable performance. To achieve this, in this paper we introduce an Efficient Unsupervised Domain Adaptation (EUDA) framework. EUDA employs the DINOv2, which is a self-supervised ViT, as a feature extractor followed by a simplified bottleneck of fully connected layers to refine features for enhanced domain adaptation. Additionally, EUDA employs the synergistic domain alignment loss (SDAL), which integrates cross-entropy (CE) and maximum mean discrepancy (MMD) losses, to balance adaptation by minimizing classification errors in the source domain while aligning the source and target domain distributions. The experimental results indicate the effectiveness of EUDA in producing comparable results as compared with other state-of-the-art methods in domain adaptation with significantly fewer trainable parameters, between 42% to 99.7% fewer. This showcases the ability to train the model in a resource-limited environment. The code of the model is available at: https://github.com/A-Abedi/EUDA.