 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ANNA: Abstractive Text-to-Image Synthesis with Filtered News Captions
Jan 05, 2023

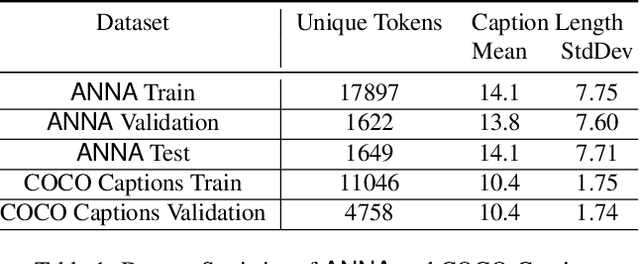
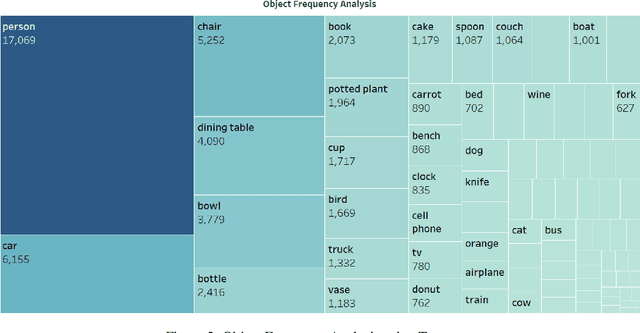
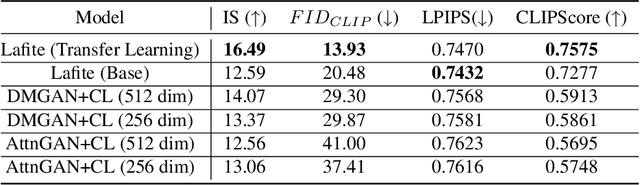
Advancements in Text-to-Image synthesis over recent years have focused more on improving the quality of generated samples on datasets with descriptive captions. However, real-world image-caption pairs present in domains such as news data do not use simple and directly descriptive captions. With captions containing information on both the image content and underlying contextual cues, they become abstractive in nature. In this paper, we launch ANNA, an Abstractive News captioNs dAtaset extracted from online news articles in a variety of different contexts. We explore the capabilities of current Text-to-Image synthesis models to generate news domain-specific images using abstractive captions by benchmarking them on ANNA, in both standard training and transfer learning settings. The generated images are judged on the basis of contextual relevance, visual quality, and perceptual similarity to ground-truth image-caption pairs. Through our experiments, we show that techniques such as transfer learning achieve limited success in understanding abstractive captions but still fail to consistently learn the relationships between content and context features.
MaNi: Maximizing Mutual Information for Nuclei Cross-Domain Unsupervised Segmentation
Jun 29, 2022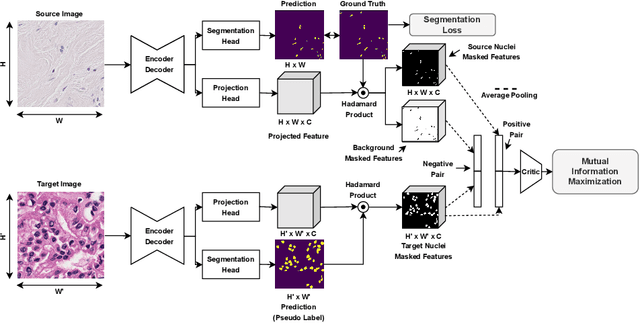
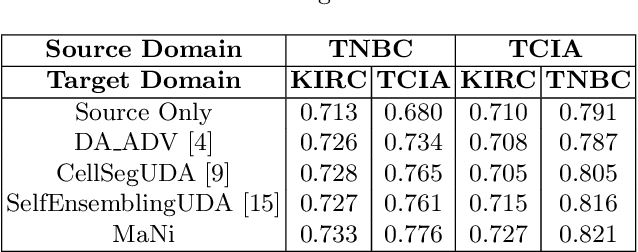
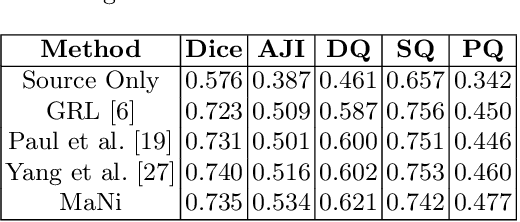
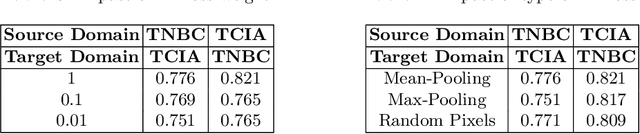
In this work, we propose a mutual information (MI) based unsupervised domain adaptation (UDA) method for the cross-domain nuclei segmentation. Nuclei vary substantially in structure and appearances across different cancer types, leading to a drop in performance of deep learning models when trained on one cancer type and tested on another. This domain shift becomes even more critical as accurate segmentation and quantification of nuclei is an essential histopathology task for the diagnosis/ prognosis of patients and annotating nuclei at the pixel level for new cancer types demands extensive effort by medical experts. To address this problem, we maximize the MI between labeled source cancer type data and unlabeled target cancer type data for transferring nuclei segmentation knowledge across domains. We use the Jensen-Shanon divergence bound, requiring only one negative pair per positive pair for MI maximization. We evaluate our set-up for multiple modeling frameworks and on different datasets comprising of over 20 cancer-type domain shifts and demonstrate competitive performance. All the recently proposed approaches consist of multiple components for improving the domain adaptation, whereas our proposed module is light and can be easily incorporated into other methods (Implementation: https://github.com/YashSharma/MaNi ).
High-Resolution Cloud Removal with Multi-Modal and Multi-Resolution Data Fusion: A New Baseline and Benchmark
Jan 09, 2023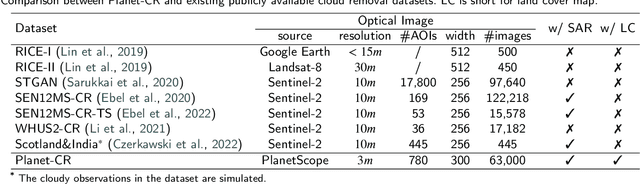
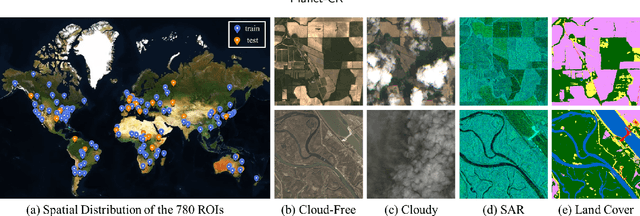
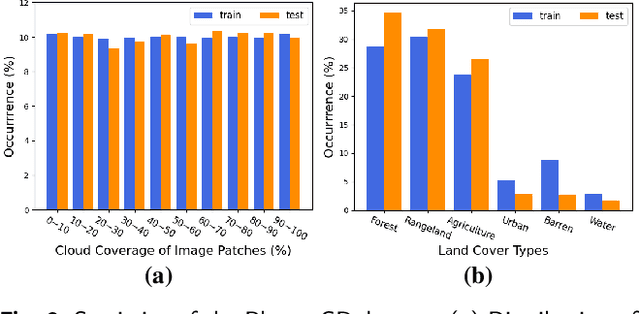
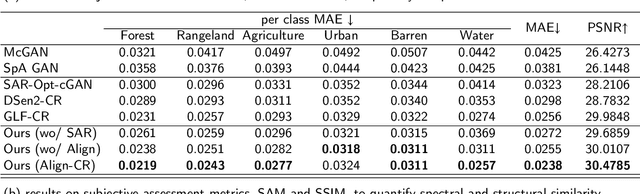
In this paper, we introduce Planet-CR, a benchmark dataset for high-resolution cloud removal with multi-modal and multi-resolution data fusion. Planet-CR is the first public dataset for cloud removal to feature globally sampled high resolution optical observations, in combination with paired radar measurements as well as pixel-level land cover annotations. It provides solid basis for exhaustive evaluation in terms of generating visually pleasing textures and semantically meaningful structures. With this dataset, we consider the problem of cloud removal in high resolution optical remote sensing imagery by integrating multi-modal and multi-resolution information. Existing multi-modal data fusion based methods, which assume the image pairs are aligned pixel-to-pixel, are hence not appropriate for this problem. To this end, we design a new baseline named Align-CR to perform the low-resolution SAR image guided high-resolution optical image cloud removal. It implicitly aligns the multi-modal and multi-resolution data during the reconstruction process to promote the cloud removal performance. The experimental results demonstrate that the proposed Align-CR method gives the best performance in both visual recovery quality and semantic recovery quality. The project is available at https://github.com/zhu-xlab/Planet-CR, and hope this will inspire future research.
Leveraging Contextual Relatedness to Identify Suicide Documentation in Clinical Notes through Zero Shot Learning
Jan 09, 2023
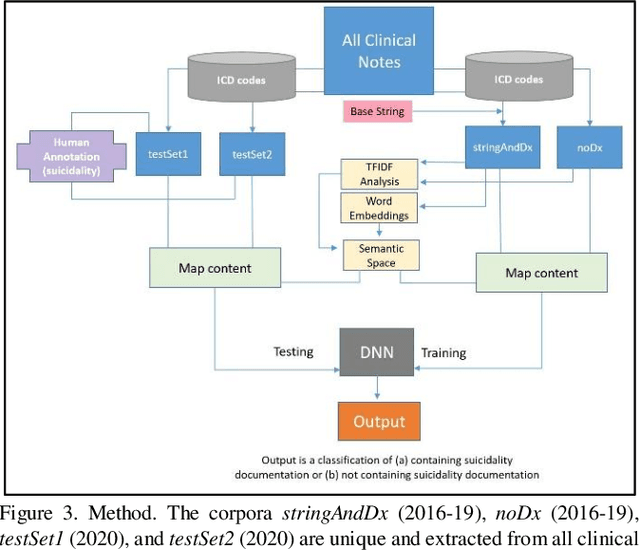
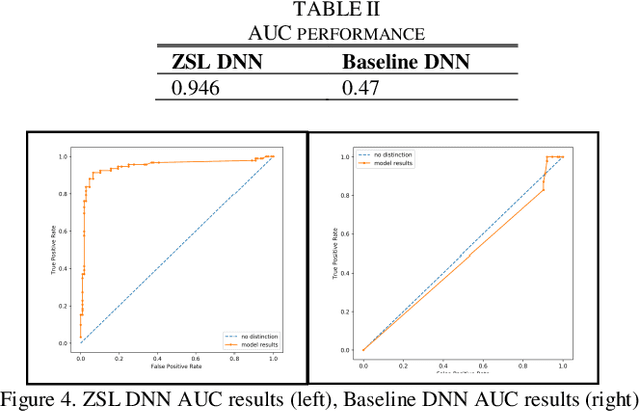
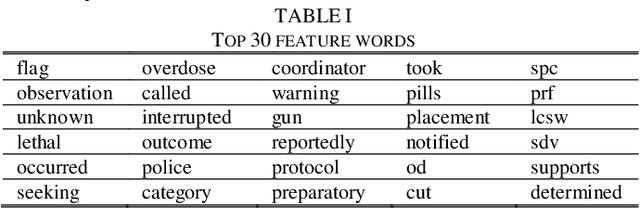
Identifying suicidality including suicidal ideation, attempts, and risk factors in electronic health record data in clinical notes is difficult. A major difficulty is the lack of training samples given the small number of true positive instances among the increasingly large number of patients being screened. This paper describes a novel methodology that identifies suicidality in clinical notes by addressing this data sparsity issue through zero-shot learning. U.S. Veterans Affairs clinical notes served as data. The training dataset label was determined using diagnostic codes of suicide attempt and self-harm. A base string associated with the target label of suicidality was used to provide auxiliary information by narrowing the positive training cases to those containing the base string. A deep neural network was trained by mapping the training documents contents to a semantic space. For comparison, we trained another deep neural network using the identical training dataset labels and bag-of-words features. The zero shot learning model outperformed the baseline model in terms of AUC, sensitivity, specificity, and positive predictive value at multiple probability thresholds. In applying a 0.90 probability threshold, the methodology identified notes not associated with a relevant ICD 10 CM code that documented suicidality, with 94 percent accuracy. This new method can effectively identify suicidality without requiring manual annotation.
RISs and Sidelink Communications in Smart Cities: The Key to Seamless Localization and Sensing
Jan 09, 2023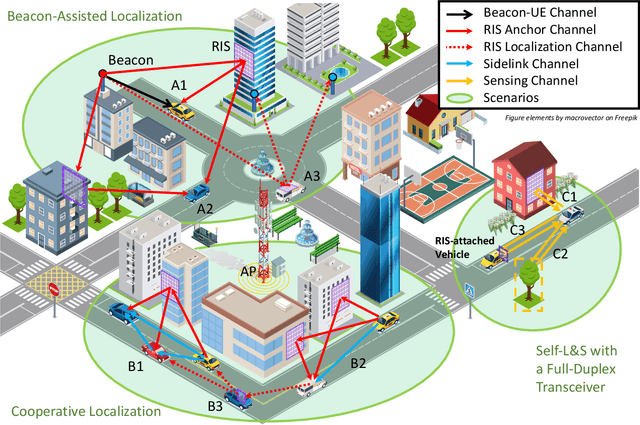
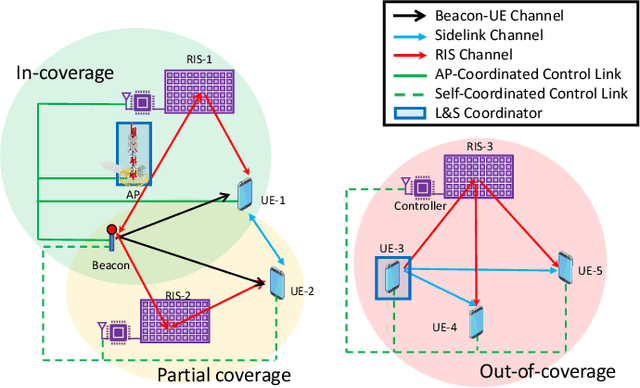
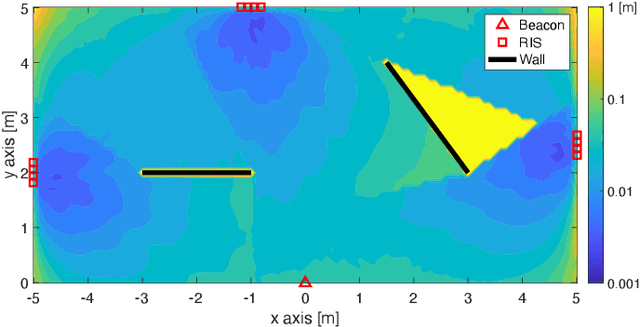
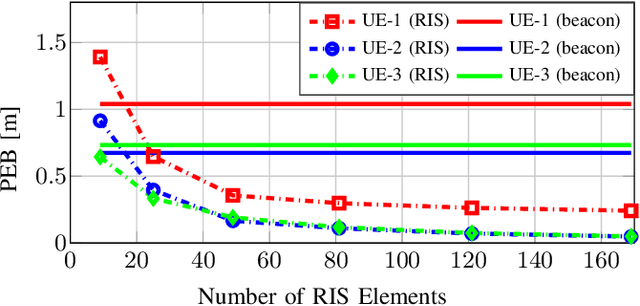
A smart city involves, among other elements, intelligent transportation, crowd monitoring, and digital twins, each of which requires information exchange via wireless communication links and localization of connected devices and passive objects (including people). Although localization and sensing (L&S) are envisioned as core functions of future communication systems, they have inherently different demands in terms of infrastructure compared to communications. Wireless communications generally requires a connection to only a single access point (AP), while L&S demand simultaneous line-of-sight propagation paths to several APs, which serve as location and orientation anchors. Hence, a smart city deployment optimized for communication will be insufficient to meet stringent L&S requirements. In this article, we argue that the emerging technologies of reconfigurable intelligent surfaces (RISs) and sidelink communications constitute the key to providing ubiquitous coverage for L&S in smart cities with low-cost and energy-efficient technical solutions. To this end, we propose and evaluate AP-coordinated and self-coordinated RIS-enabled L&S architectures and detail three groups of application scenarios, relying on low-complexity beacons, cooperative localization, and full-duplex transceivers. A list of practical issues and consequent open research challenges of the proposed L&S systems is also provided.
DetIE: Multilingual Open Information Extraction Inspired by Object Detection
Jun 24, 2022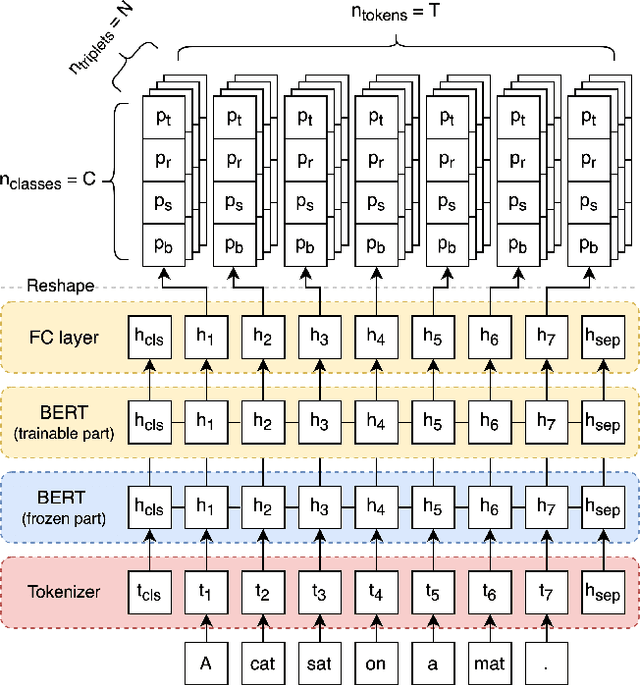
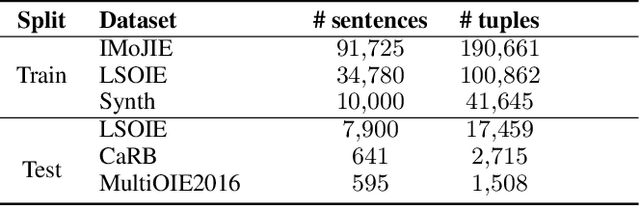
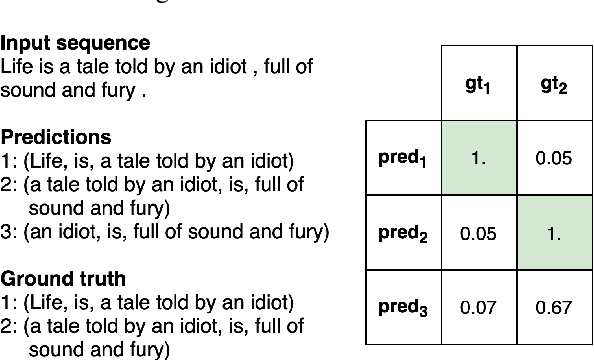

State of the art neural methods for open information extraction (OpenIE) usually extract triplets (or tuples) iteratively in an autoregressive or predicate-based manner in order not to produce duplicates. In this work, we propose a different approach to the problem that can be equally or more successful. Namely, we present a novel single-pass method for OpenIE inspired by object detection algorithms from computer vision. We use an order-agnostic loss based on bipartite matching that forces unique predictions and a Transformer-based encoder-only architecture for sequence labeling. The proposed approach is faster and shows superior or similar performance in comparison with state of the art models on standard benchmarks in terms of both quality metrics and inference time. Our model sets the new state of the art performance of 67.7% F1 on CaRB evaluated as OIE2016 while being 3.35x faster at inference than previous state of the art. We also evaluate the multilingual version of our model in the zero-shot setting for two languages and introduce a strategy for generating synthetic multilingual data to fine-tune the model for each specific language. In this setting, we show performance improvement 15% on multilingual Re-OIE2016, reaching 75% F1 for both Portuguese and Spanish languages. Code and models are available at https://github.com/sberbank-ai/DetIE.
Tracking by Associating Clips
Dec 20, 2022The tracking-by-detection paradigm today has become the dominant method for multi-object tracking and works by detecting objects in each frame and then performing data association across frames. However, its sequential frame-wise matching property fundamentally suffers from the intermediate interruptions in a video, such as object occlusions, fast camera movements, and abrupt light changes. Moreover, it typically overlooks temporal information beyond the two frames for matching. In this paper, we investigate an alternative by treating object association as clip-wise matching. Our new perspective views a single long video sequence as multiple short clips, and then the tracking is performed both within and between the clips. The benefits of this new approach are two folds. First, our method is robust to tracking error accumulation or propagation, as the video chunking allows bypassing the interrupted frames, and the short clip tracking avoids the conventional error-prone long-term track memory management. Second, the multiple frame information is aggregated during the clip-wise matching, resulting in a more accurate long-range track association than the current frame-wise matching. Given the state-of-the-art tracking-by-detection tracker, QDTrack, we showcase how the tracking performance improves with our new tracking formulation. We evaluate our proposals on two tracking benchmarks, TAO and MOT17 that have complementary characteristics and challenges each other.
AnnoBERT: Effectively Representing Multiple Annotators' Label Choices to Improve Hate Speech Detection
Dec 20, 2022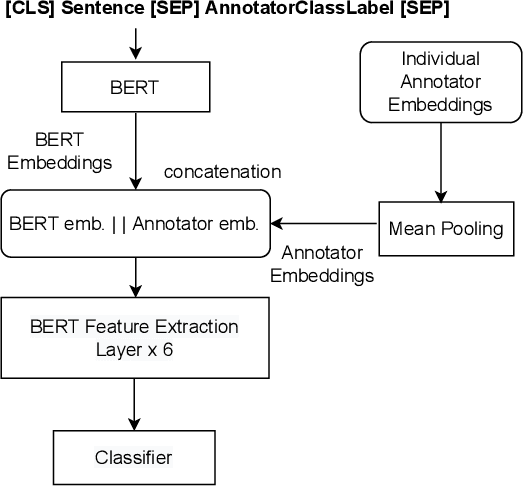

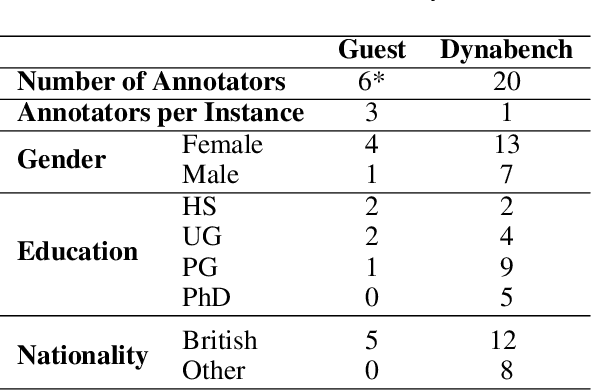
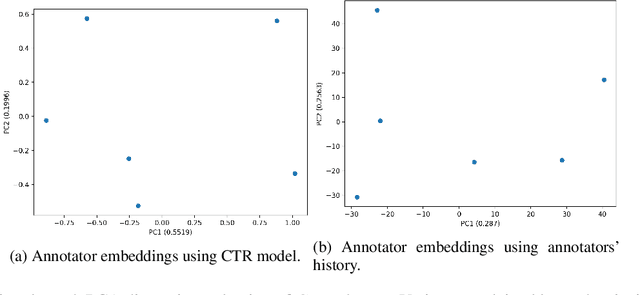
Supervised approaches generally rely on majority-based labels. However, it is hard to achieve high agreement among annotators in subjective tasks such as hate speech detection. Existing neural network models principally regard labels as categorical variables, while ignoring the semantic information in diverse label texts. In this paper, we propose AnnoBERT, a first-of-its-kind architecture integrating annotator characteristics and label text with a transformer-based model to detect hate speech, with unique representations based on each annotator's characteristics via Collaborative Topic Regression (CTR) and integrate label text to enrich textual representations. During training, the model associates annotators with their label choices given a piece of text; during evaluation, when label information is not available, the model predicts the aggregated label given by the participating annotators by utilising the learnt association. The proposed approach displayed an advantage in detecting hate speech, especially in the minority class and edge cases with annotator disagreement. Improvement in the overall performance is the largest when the dataset is more label-imbalanced, suggesting its practical value in identifying real-world hate speech, as the volume of hate speech in-the-wild is extremely small on social media, when compared with normal (non-hate) speech. Through ablation studies, we show the relative contributions of annotator embeddings and label text to the model performance, and tested a range of alternative annotator embeddings and label text combinations.
* accepted at ICWSM 2023
CrysGNN : Distilling pre-trained knowledge to enhance property prediction for crystalline materials
Jan 14, 2023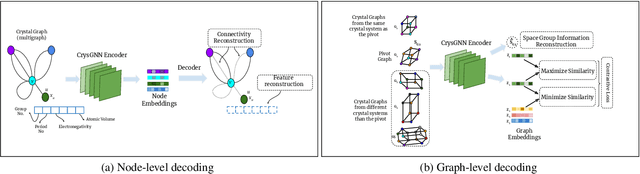
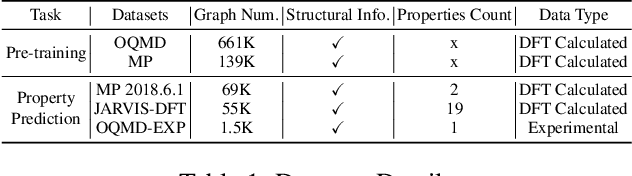
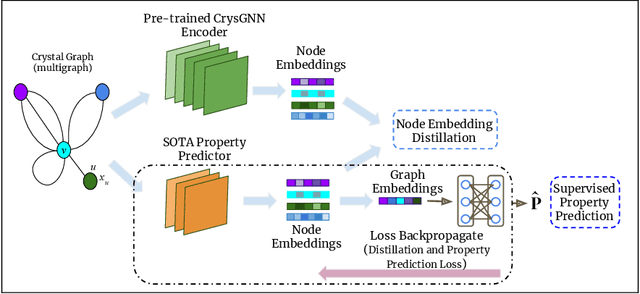
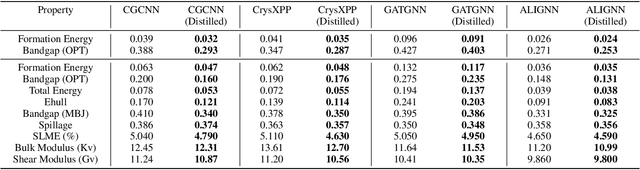
In recent years, graph neural network (GNN) based approaches have emerged as a powerful technique to encode complex topological structure of crystal materials in an enriched representation space. These models are often supervised in nature and using the property-specific training data, learn relationship between crystal structure and different properties like formation energy, bandgap, bulk modulus, etc. Most of these methods require a huge amount of property-tagged data to train the system which may not be available for different properties. However, there is an availability of a huge amount of crystal data with its chemical composition and structural bonds. To leverage these untapped data, this paper presents CrysGNN, a new pre-trained GNN framework for crystalline materials, which captures both node and graph level structural information of crystal graphs using a huge amount of unlabelled material data. Further, we extract distilled knowledge from CrysGNN and inject into different state of the art property predictors to enhance their property prediction accuracy. We conduct extensive experiments to show that with distilled knowledge from the pre-trained model, all the SOTA algorithms are able to outperform their own vanilla version with good margins. We also observe that the distillation process provides a significant improvement over the conventional approach of finetuning the pre-trained model. We have released the pre-trained model along with the large dataset of 800K crystal graph which we carefully curated; so that the pretrained model can be plugged into any existing and upcoming models to enhance their prediction accuracy.
Drug Synergistic Combinations Predictions via Large-Scale Pre-Training and Graph Structure Learning
Jan 14, 2023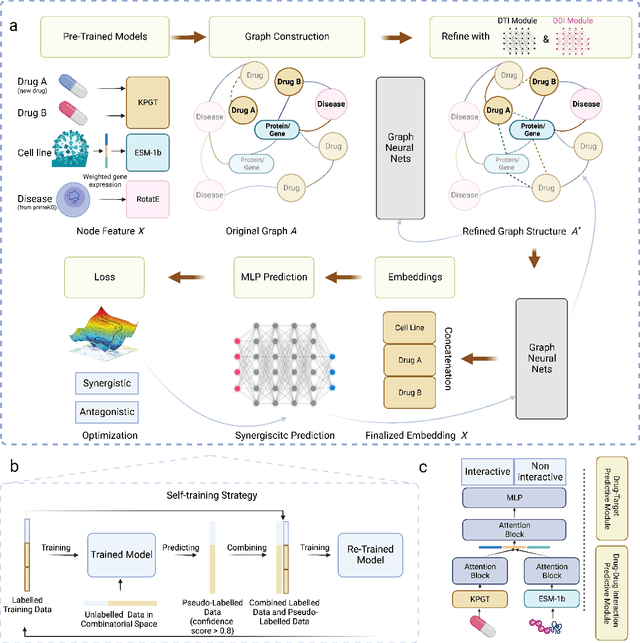

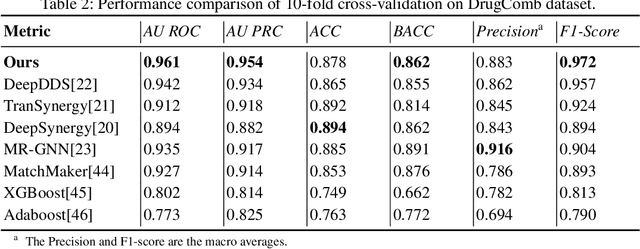
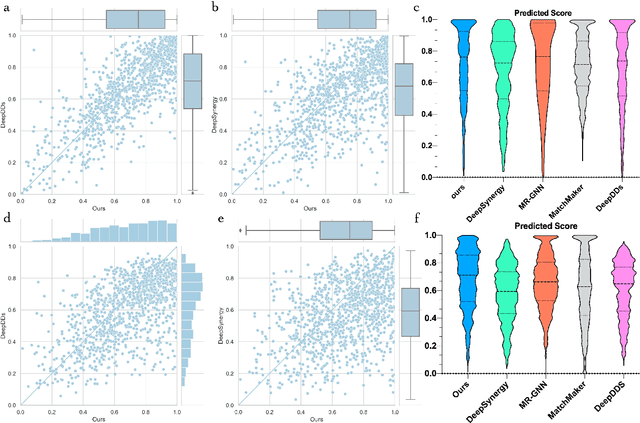
Drug combination therapy is a well-established strategy for disease treatment with better effectiveness and less safety degradation. However, identifying novel drug combinations through wet-lab experiments is resource intensive due to the vast combinatorial search space. Recently, computational approaches, specifically deep learning models have emerged as an efficient way to discover synergistic combinations. While previous methods reported fair performance, their models usually do not take advantage of multi-modal data and they are unable to handle new drugs or cell lines. In this study, we collected data from various datasets covering various drug-related aspects. Then, we take advantage of large-scale pre-training models to generate informative representations and features for drugs, proteins, and diseases. Based on that, a message-passing graph is built on top to propagate information together with graph structure learning flexibility. This is first introduced in the biological networks and enables us to generate pseudo-relations in the graph. Our framework achieves state-of-the-art results in comparison with other deep learning-based methods on synergistic prediction benchmark datasets. We are also capable of inferencing new drug combination data in a test on an independent set released by AstraZeneca, where 10% of improvement over previous methods is observed. In addition, we're robust against unseen drugs and surpass almost 15% AU ROC compared to the second-best model. We believe our framework contributes to both the future wet-lab discovery of novel drugs and the building of promising guidance for precise combination medicine.