 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuration of a Cardiology Interface Terminology for Highlighting Electronic Health Records using Machine Learning
Jun 06, 2026Electronic health record (EHR) notes are dense medical documents containing large amounts of information, often filled with complex medical jargon. Highlighting all details in EHRs helps reduce the likelihood of missing crucial information by drawing attention to key content. This study proposes the design of a Cardiology Interface Terminology (CIT) to accurately highlight all details in EHR notes of cardiology patients. We introduce an innovative Machine Learning (ML) technique for the design of CIT. The ML technique requires training data. Manual preparation of such training data is time-consuming and expensive. The process of the CIT design includes three phases. In the first two phases, we innovatively derive a training data CIT to be used by the third phase, ML technique. We start by designing an initial CIT, composed of several components: the cardiology-related sub-hierarchies of SNOMED, other SNOMED concepts mined from EHRs of build set, and necessary components of terms e.g., medical abbreviations and medications. Utilizing an iterative process, fine-grained phrases containing initial CIT concepts are extracted from build set as CIT concept candidates. The candidate concepts are semi-automatically reviewed before being added to CIT, yielding the training data CIT, TCIT. In the third phase, a ML model is trained with TCIT to identify candidates fitting to be concepts in the CIT. This model is used to extract further concepts from build set, yielding the final CIT. The final CIT is then used to highlight the test set and evaluate the extent to which it captures details in an unseen EHR dataset. For this purpose, four evaluation metrics, coverage, breadth, completeness, and conciseness are used. The highlighted test set has a coverage of 74.21%, with a breadth of 1.68. For 20 random notes in test set, the average completeness is 98.2% and average conciseness is 84.2%.
Leveraging Contextual Relatedness to Identify Suicide Documentation in Clinical Notes through Zero Shot Learning
Jan 09, 2023



Identifying suicidality including suicidal ideation, attempts, and risk factors in electronic health record data in clinical notes is difficult. A major difficulty is the lack of training samples given the small number of true positive instances among the increasingly large number of patients being screened. This paper describes a novel methodology that identifies suicidality in clinical notes by addressing this data sparsity issue through zero-shot learning. U.S. Veterans Affairs clinical notes served as data. The training dataset label was determined using diagnostic codes of suicide attempt and self-harm. A base string associated with the target label of suicidality was used to provide auxiliary information by narrowing the positive training cases to those containing the base string. A deep neural network was trained by mapping the training documents contents to a semantic space. For comparison, we trained another deep neural network using the identical training dataset labels and bag-of-words features. The zero shot learning model outperformed the baseline model in terms of AUC, sensitivity, specificity, and positive predictive value at multiple probability thresholds. In applying a 0.90 probability threshold, the methodology identified notes not associated with a relevant ICD 10 CM code that documented suicidality, with 94 percent accuracy. This new method can effectively identify suicidality without requiring manual annotation.
Character Entropy in Modern and Historical Texts: Comparison Metrics for an Undeciphered Manuscript
Oct 28, 2020
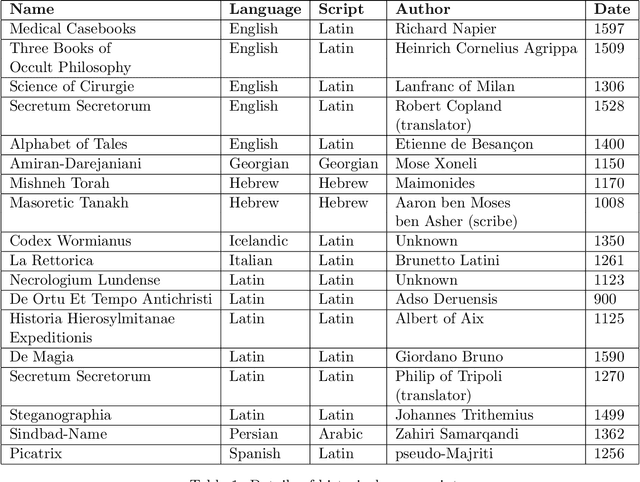

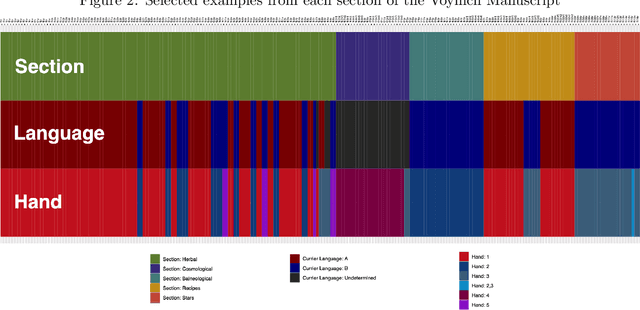
This paper outlines the creation of three corpora for multilingual comparison and analysis of the Voynich manuscript: a corpus of Voynich texts partitioned by Currier language, scribal hand, and transcription system, a corpus of 294 language samples compiled from Wikipedia, and a corpus of eighteen transcribed historical texts in eight languages. These corpora will be utilized in subsequent work by the Voynich Working Group at Yale University. We demonstrate the utility of these corpora for studying characteristics of the Voynich script and language, with an analysis of conditional character entropy in Voynichese. We discuss the interaction between character entropy and language, script size and type, glyph compositionality, scribal conventions and abbreviations, positional character variants, and bigram frequency. This analysis characterizes the interaction between script compositionality, character size, and predictability. We show that substantial manipulations of glyph composition are not sufficient to align conditional entropy levels with natural languages. The unusually predictable nature of the Voynichese script is not attributable to a particular script or transcription system, underlying language, or substitution cipher. Voynichese is distinct from every comparison text in our corpora because character placement is highly constrained within the word, and this may indicate the loss of phonemic distinctions from the underlying language.