 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic Transfer to Kyrgyz Using the Treebank Translation Method
Dec 17, 2024



The Kyrgyz language, as a low-resource language, requires significant effort to create high-quality syntactic corpora. This study proposes an approach to simplify the development process of a syntactic corpus for Kyrgyz. We present a tool for transferring syntactic annotations from Turkish to Kyrgyz based on a treebank translation method. The effectiveness of the proposed tool was evaluated using the TueCL treebank. The results demonstrate that this approach achieves higher syntactic annotation accuracy compared to a monolingual model trained on the Kyrgyz KTMU treebank. Additionally, the study introduces a method for assessing the complexity of manual annotation for the resulting syntactic trees, contributing to further optimization of the annotation process.
HJ-Ky-0.1: an Evaluation Dataset for Kyrgyz Word Embeddings
Nov 16, 2024

One of the key tasks in modern applied computational linguistics is constructing word vector representations (word embeddings), which are widely used to address natural language processing tasks such as sentiment analysis, information extraction, and more. To choose an appropriate method for generating these word embeddings, quality assessment techniques are often necessary. A standard approach involves calculating distances between vectors for words with expert-assessed 'similarity'. This work introduces the first 'silver standard' dataset for such tasks in the Kyrgyz language, alongside training corresponding models and validating the dataset's suitability through quality evaluation metrics.
KyrgyzNLP: Challenges, Progress, and Future
Nov 08, 2024



Large language models (LLMs) have excelled in numerous benchmarks, advancing AI applications in both linguistic and non-linguistic tasks. However, this has primarily benefited well-resourced languages, leaving less-resourced ones (LRLs) at a disadvantage. In this paper, we highlight the current state of the NLP field in the specific LRL: kyrgyz tili. Human evaluation, including annotated datasets created by native speakers, remains an irreplaceable component of reliable NLP performance, especially for LRLs where automatic evaluations can fall short. In recent assessments of the resources for Turkic languages, Kyrgyz is labeled with the status 'Scraping By', a severely under-resourced language spoken by millions. This is concerning given the growing importance of the language, not only in Kyrgyzstan but also among diaspora communities where it holds no official status. We review prior efforts in the field, noting that many of the publicly available resources have only recently been developed, with few exceptions beyond dictionaries (the processed data used for the analysis is presented at https://kyrgyznlp.github.io/). While recent papers have made some headway, much more remains to be done. Despite interest and support from both business and government sectors in the Kyrgyz Republic, the situation for Kyrgyz language resources remains challenging. We stress the importance of community-driven efforts to build these resources, ensuring the future advancement sustainability. We then share our view of the most pressing challenges in Kyrgyz NLP. Finally, we propose a roadmap for future development in terms of research topics and language resources.
Neural Click Models for Recommender Systems
Sep 30, 2024We develop and evaluate neural architectures to model the user behavior in recommender systems (RS) inspired by click models for Web search but going beyond standard click models. Proposed architectures include recurrent networks, Transformer-based models that alleviate the quadratic complexity of self-attention, adversarial and hierarchical architectures. Our models outperform baselines on the ContentWise and RL4RS datasets and can be used in RS simulators to model user response for RS evaluation and pretraining.
$ abla^2$DFT: A Universal Quantum Chemistry Dataset of Drug-Like Molecules and a Benchmark for Neural Network Potentials
Jun 20, 2024Methods of computational quantum chemistry provide accurate approximations of molecular properties crucial for computer-aided drug discovery and other areas of chemical science. However, high computational complexity limits the scalability of their applications. Neural network potentials (NNPs) are a promising alternative to quantum chemistry methods, but they require large and diverse datasets for training. This work presents a new dataset and benchmark called $\nabla^2$DFT that is based on the nablaDFT. It contains twice as much molecular structures, three times more conformations, new data types and tasks, and state-of-the-art models. The dataset includes energies, forces, 17 molecular properties, Hamiltonian and overlap matrices, and a wavefunction object. All calculations were performed at the DFT level ($\omega$B97X-D/def2-SVP) for each conformation. Moreover, $\nabla^2$DFT is the first dataset that contains relaxation trajectories for a substantial number of drug-like molecules. We also introduce a novel benchmark for evaluating NNPs in molecular property prediction, Hamiltonian prediction, and conformational optimization tasks. Finally, we propose an extendable framework for training NNPs and implement 10 models within it.
Benchmarking Multilabel Topic Classification in the Kyrgyz Language
Aug 30, 2023Kyrgyz is a very underrepresented language in terms of modern natural language processing resources. In this work, we present a new public benchmark for topic classification in Kyrgyz, introducing a dataset based on collected and annotated data from the news site 24.KG and presenting several baseline models for news classification in the multilabel setting. We train and evaluate both classical statistical and neural models, reporting the scores, discussing the results, and proposing directions for future work.
Machine Learning for SAT: Restricted Heuristics and New Graph Representations
Jul 18, 2023



Boolean satisfiability (SAT) is a fundamental NP-complete problem with many applications, including automated planning and scheduling. To solve large instances, SAT solvers have to rely on heuristics, e.g., choosing a branching variable in DPLL and CDCL solvers. Such heuristics can be improved with machine learning (ML) models; they can reduce the number of steps but usually hinder the running time because useful models are relatively large and slow. We suggest the strategy of making a few initial steps with a trained ML model and then releasing control to classical heuristics; this simplifies cold start for SAT solving and can decrease both the number of steps and overall runtime, but requires a separate decision of when to release control to the solver. Moreover, we introduce a modification of Graph-Q-SAT tailored to SAT problems converted from other domains, e.g., open shop scheduling problems. We validate the feasibility of our approach with random and industrial SAT problems.
DetIE: Multilingual Open Information Extraction Inspired by Object Detection
Jun 24, 2022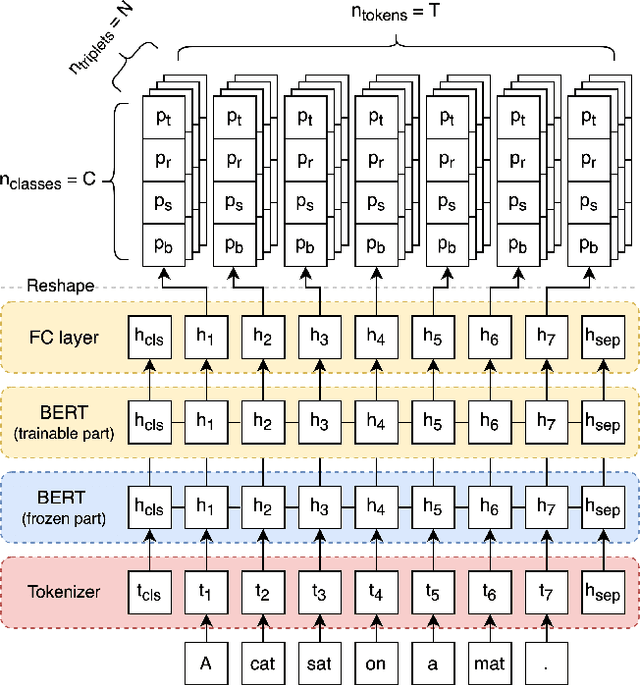
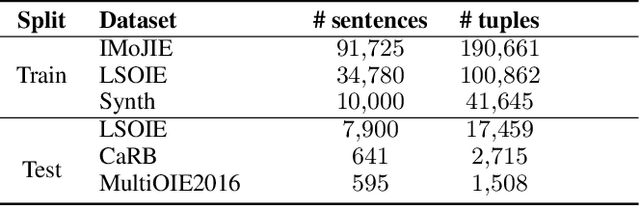
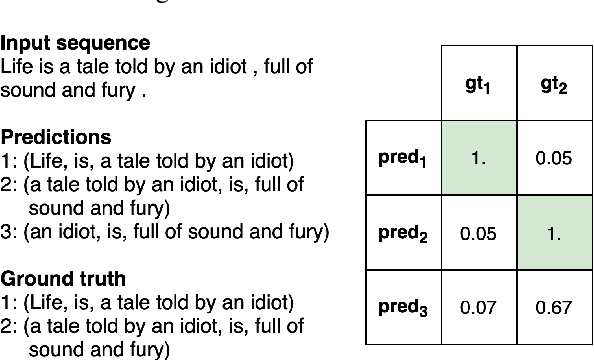

State of the art neural methods for open information extraction (OpenIE) usually extract triplets (or tuples) iteratively in an autoregressive or predicate-based manner in order not to produce duplicates. In this work, we propose a different approach to the problem that can be equally or more successful. Namely, we present a novel single-pass method for OpenIE inspired by object detection algorithms from computer vision. We use an order-agnostic loss based on bipartite matching that forces unique predictions and a Transformer-based encoder-only architecture for sequence labeling. The proposed approach is faster and shows superior or similar performance in comparison with state of the art models on standard benchmarks in terms of both quality metrics and inference time. Our model sets the new state of the art performance of 67.7% F1 on CaRB evaluated as OIE2016 while being 3.35x faster at inference than previous state of the art. We also evaluate the multilingual version of our model in the zero-shot setting for two languages and introduce a strategy for generating synthetic multilingual data to fine-tune the model for each specific language. In this setting, we show performance improvement 15% on multilingual Re-OIE2016, reaching 75% F1 for both Portuguese and Spanish languages. Code and models are available at https://github.com/sberbank-ai/DetIE.
Near-Zero-Shot Suggestion Mining with a Little Help from WordNet
Nov 25, 2021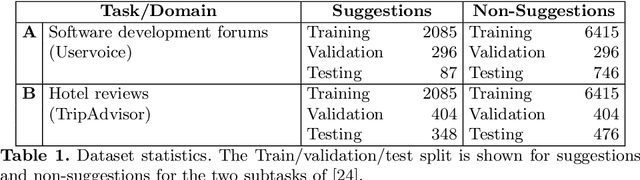
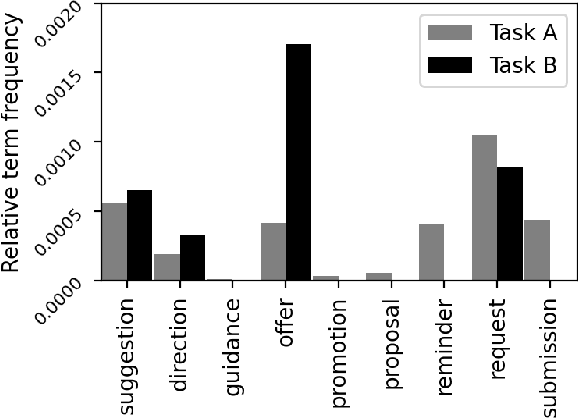

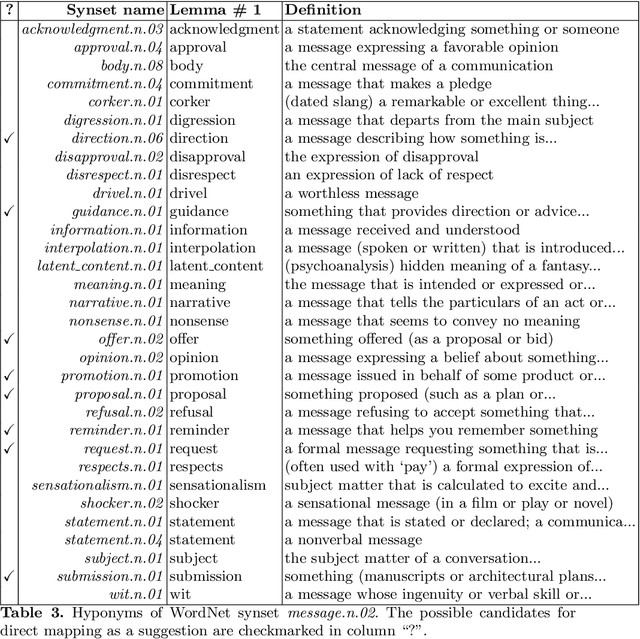
In this work, we explore the constructive side of online reviews: advice, tips, requests, and suggestions that users provide about goods, venues, services, and other items of interest. To reduce training costs and annotation efforts needed to build a classifier for a specific label set, we present and evaluate several entailment-based zero-shot approaches to suggestion classification in a label-fully-unseen fashion. In particular, we introduce the strategy of assigning target class labels to sentences in English language with user intentions, which significantly improves prediction quality. The proposed strategies are evaluated with a comprehensive experimental study that validated our results both quantitatively and qualitatively.
Improving unsupervised neural aspect extraction for online discussions using out-of-domain classification
Jun 17, 2020
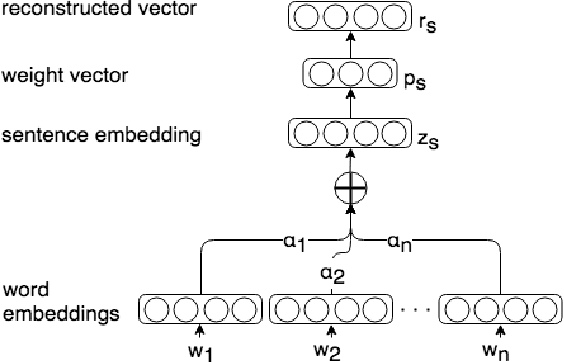
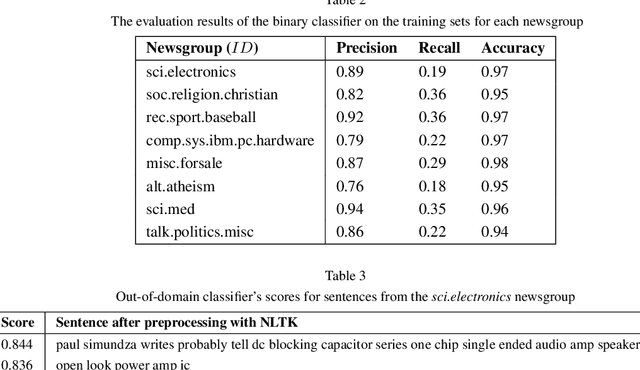
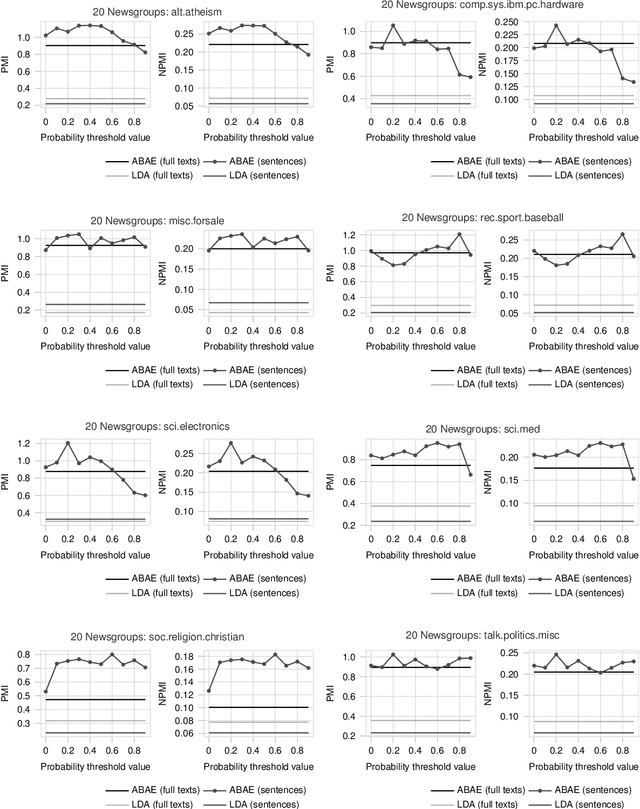
Deep learning architectures based on self-attention have recently achieved and surpassed state of the art results in the task of unsupervised aspect extraction and topic modeling. While models such as neural attention-based aspect extraction (ABAE) have been successfully applied to user-generated texts, they are less coherent when applied to traditional data sources such as news articles and newsgroup documents. In this work, we introduce a simple approach based on sentence filtering in order to improve topical aspects learned from newsgroups-based content without modifying the basic mechanism of ABAE. We train a probabilistic classifier to distinguish between out-of-domain texts (outer dataset) and in-domain texts (target dataset). Then, during data preparation we filter out sentences that have a low probability of being in-domain and train the neural model on the remaining sentences. The positive effect of sentence filtering on topic coherence is demonstrated in comparison to aspect extraction models trained on unfiltered texts.