 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Audio2Gestures: Generating Diverse Gestures from Audio
Jan 17, 2023



People may perform diverse gestures affected by various mental and physical factors when speaking the same sentences. This inherent one-to-many relationship makes co-speech gesture generation from audio particularly challenging. Conventional CNNs/RNNs assume one-to-one mapping, and thus tend to predict the average of all possible target motions, easily resulting in plain/boring motions during inference. So we propose to explicitly model the one-to-many audio-to-motion mapping by splitting the cross-modal latent code into shared code and motion-specific code. The shared code is expected to be responsible for the motion component that is more correlated to the audio while the motion-specific code is expected to capture diverse motion information that is more independent of the audio. However, splitting the latent code into two parts poses extra training difficulties. Several crucial training losses/strategies, including relaxed motion loss, bicycle constraint, and diversity loss, are designed to better train the VAE. Experiments on both 3D and 2D motion datasets verify that our method generates more realistic and diverse motions than previous state-of-the-art methods, quantitatively and qualitatively. Besides, our formulation is compatible with discrete cosine transformation (DCT) modeling and other popular backbones (\textit{i.e.} RNN, Transformer). As for motion losses and quantitative motion evaluation, we find structured losses/metrics (\textit{e.g.} STFT) that consider temporal and/or spatial context complement the most commonly used point-wise losses (\textit{e.g.} PCK), resulting in better motion dynamics and more nuanced motion details. Finally, we demonstrate that our method can be readily used to generate motion sequences with user-specified motion clips on the timeline.
Hard Sample Aware Network for Contrastive Deep Graph Clustering
Dec 25, 2022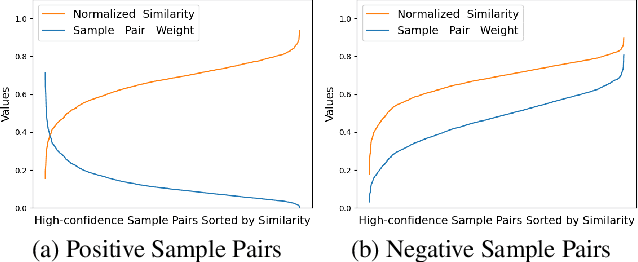
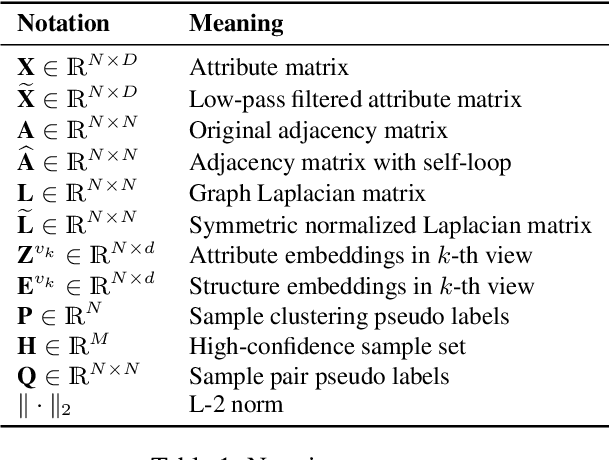
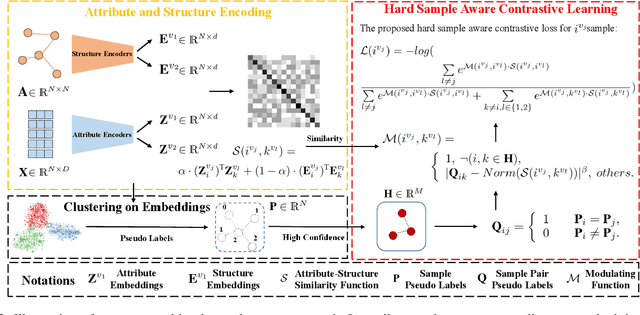
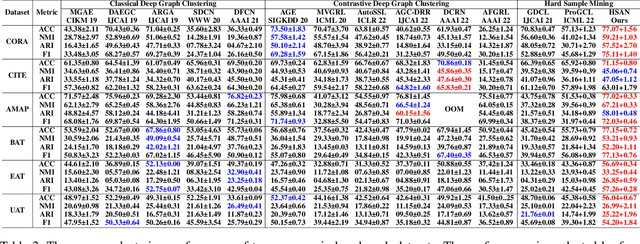
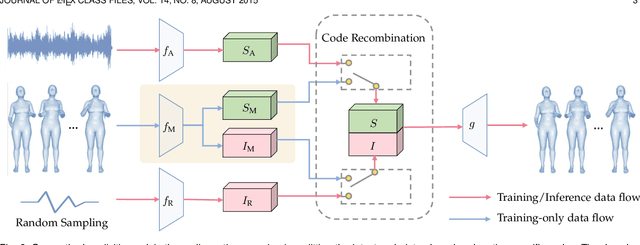
Contrastive deep graph clustering, which aims to divide nodes into disjoint groups via contrastive mechanisms, is a challenging research spot. Among the recent works, hard sample mining-based algorithms have achieved great attention for their promising performance. However, we find that the existing hard sample mining methods have two problems as follows. 1) In the hardness measurement, the important structural information is overlooked for similarity calculation, degrading the representativeness of the selected hard negative samples. 2) Previous works merely focus on the hard negative sample pairs while neglecting the hard positive sample pairs. Nevertheless, samples within the same cluster but with low similarity should also be carefully learned. To solve the problems, we propose a novel contrastive deep graph clustering method dubbed Hard Sample Aware Network (HSAN) by introducing a comprehensive similarity measure criterion and a general dynamic sample weighing strategy. Concretely, in our algorithm, the similarities between samples are calculated by considering both the attribute embeddings and the structure embeddings, better revealing sample relationships and assisting hardness measurement. Moreover, under the guidance of the carefully collected high-confidence clustering information, our proposed weight modulating function will first recognize the positive and negative samples and then dynamically up-weight the hard sample pairs while down-weighting the easy ones. In this way, our method can mine not only the hard negative samples but also the hard positive sample, thus improving the discriminative capability of the samples further. Extensive experiments and analyses demonstrate the superiority and effectiveness of our proposed method.
Relation-based Motion Prediction using Traffic Scene Graphs
Nov 24, 2022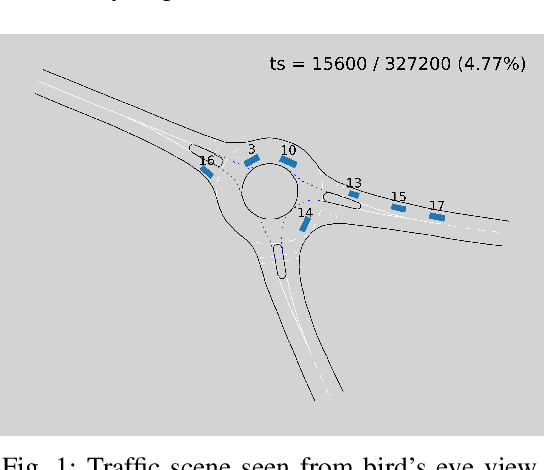
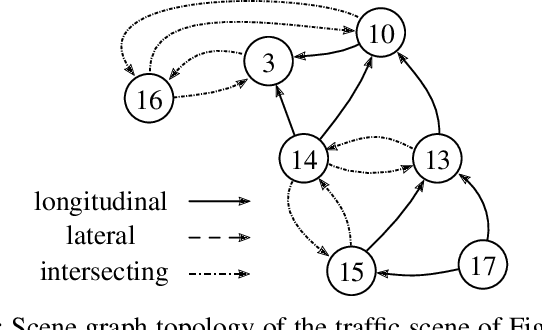
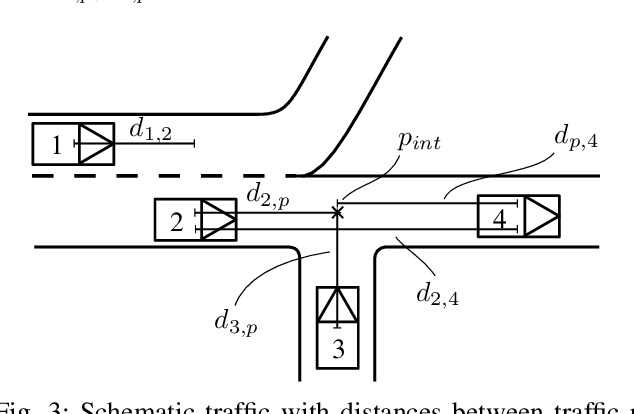
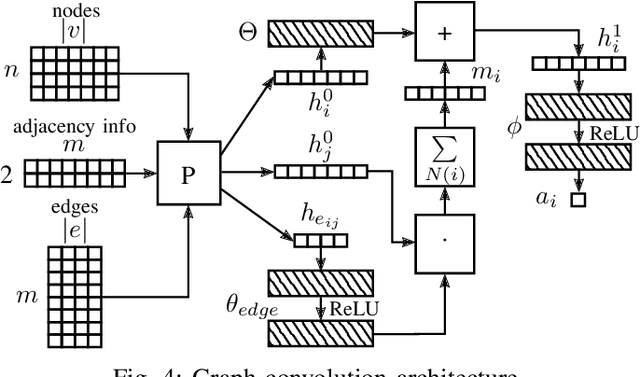
Representing relevant information of a traffic scene and understanding its environment is crucial for the success of autonomous driving. Modeling the surrounding of an autonomous car using semantic relations, i.e., how different traffic participants relate in the context of traffic rule based behaviors, is hardly been considered in previous work. This stems from the fact that these relations are hard to extract from real-world traffic scenes. In this work, we model traffic scenes in a form of spatial semantic scene graphs for various different predictions about the traffic participants, e.g., acceleration and deceleration. Our learning and inference approach uses Graph Neural Networks (GNNs) and shows that incorporating explicit information about the spatial semantic relations between traffic participants improves the predicdtion results. Specifically, the acceleration prediction of traffic participants is improved by up to 12% compared to the baselines, which do not exploit this explicit information. Furthermore, by including additional information about previous scenes, we achieve 73% improvements.
Digital Blind Box: Random Symmetric Private Information Retrieval
May 16, 2022
We introduce the problem of random symmetric private information retrieval (RSPIR). In canonical PIR, a user downloads a message out of $K$ messages from $N$ non-colluding and replicated databases in such a way that no database can know which message the user has downloaded (user privacy). In SPIR, the privacy is symmetric, in that, not only that the databases cannot know which message the user has downloaded, the user itself cannot learn anything further than the particular message it has downloaded (database privacy). In RSPIR, different from SPIR, the user does not have an input to the databases, i.e., the user does not pick a specific message to download, instead is content with any one of the messages. In RSPIR, the databases need to send symbols to the user in such a way that the user is guaranteed to download a message correctly (random reliability), the databases do not know which message the user has received (user privacy), and the user does not learn anything further than the one message it has received (database privacy). This is the digital version of a blind box, also known as gachapon, which implements the above specified setting with physical objects for entertainment. This is also the blind version of $1$-out-of-$K$ oblivious transfer (OT), an important cryptographic primitive. We study the information-theoretic capacity of RSPIR for the case of $N=2$ databases. We determine its exact capacity for the cases of $K = 2, 3, 4$ messages. While we provide a general achievable scheme that is applicable to any number of messages, the capacity for $K\geq 5$ remains open.
Radio Frequency Fingerprints Extraction for LTE-V2X: A Channel Estimation Based Methodology
Jan 04, 2023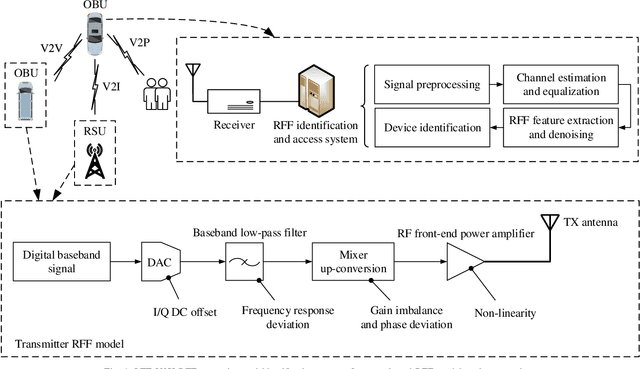
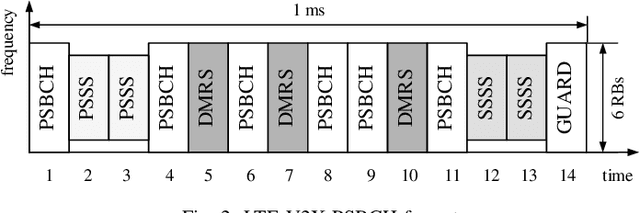
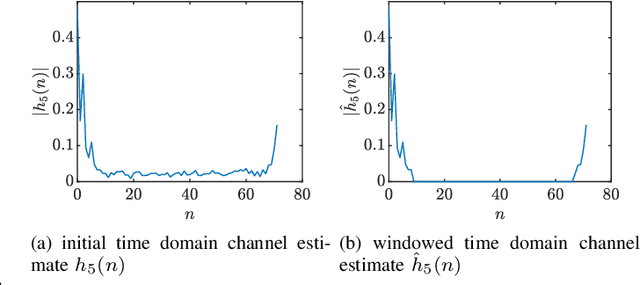
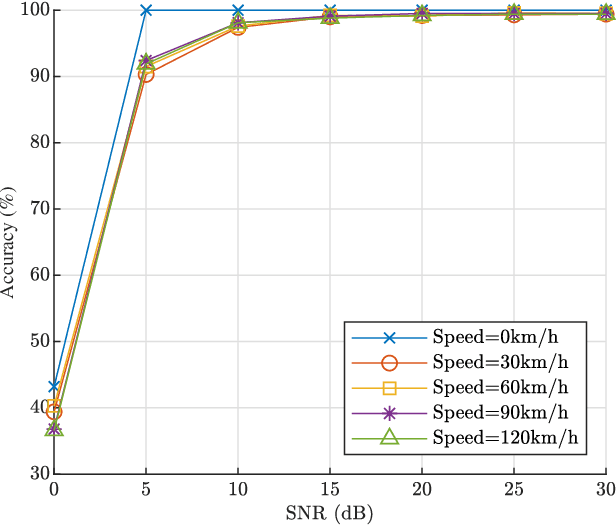
The vehicular-to-everything (V2X) technology has recently drawn a number of attentions from both academic and industrial areas. However, the openness of the wireless communication system makes it more vulnerable to identity impersonation and information tampering. How to employ the powerful radio frequency fingerprint (RFF) identification technology in V2X systems turns out to be a vital and also challenging task. In this paper, we propose a novel RFF extraction method for Long Term Evolution-V2X (LTE-V2X) systems. In order to conquer the difficulty of extracting transmitter RFF in the presence of wireless channel and receiver noise, we first estimate the wireless channel which excludes the RFF. Then, we remove the impact of the wireless channel based on the channel estimate and obtain initial RFF features. Finally, we conduct RFF denoising to enhance the quality of the initial RFF. Simulation and experiment results both demonstrate that our proposed RFF extraction scheme achieves a high identification accuracy. Furthermore, the performance is also robust to the vehicle speed.
On Fairness of Medical Image Classification with Multiple Sensitive Attributes via Learning Orthogonal Representations
Jan 04, 2023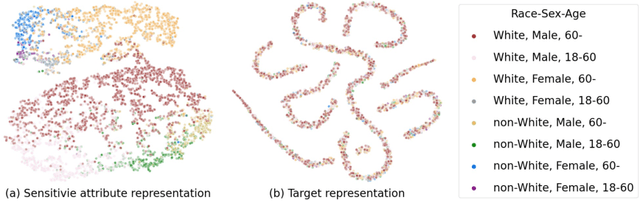

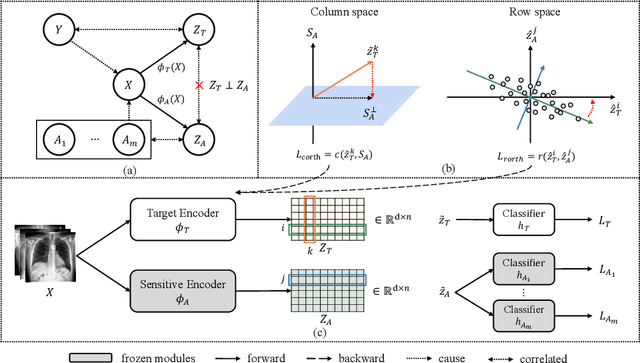
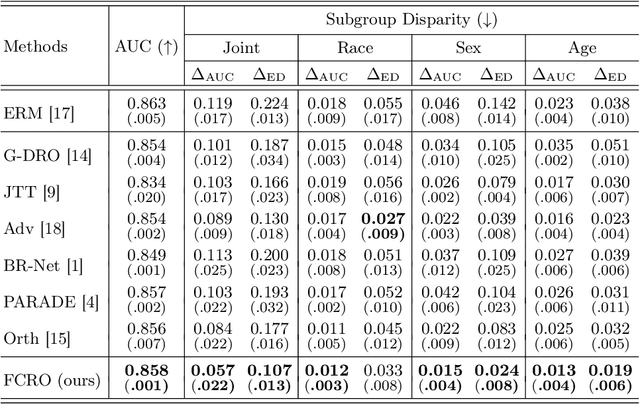
Mitigating the discrimination of machine learning models has gained increasing attention in medical image analysis. However, rare works focus on fair treatments for patients with multiple sensitive demographic ones, which is a crucial yet challenging problem for real-world clinical applications. In this paper, we propose a novel method for fair representation learning with respect to multi-sensitive attributes. We pursue the independence between target and multi-sensitive representations by achieving orthogonality in the representation space. Concretely, we enforce the column space orthogonality by keeping target information on the complement of a low-rank sensitive space. Furthermore, in the row space, we encourage feature dimensions between target and sensitive representations to be orthogonal. The effectiveness of the proposed method is demonstrated with extensive experiments on the CheXpert dataset. To our best knowledge, this is the first work to mitigate unfairness with respect to multiple sensitive attributes in the field of medical imaging.
Scene Synthesis from Human Motion
Jan 04, 2023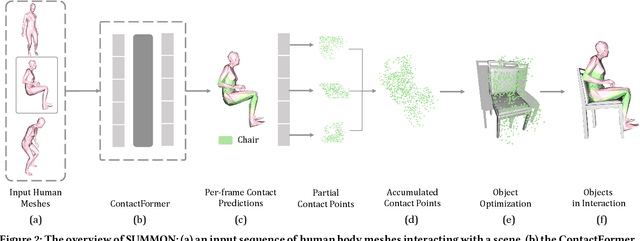
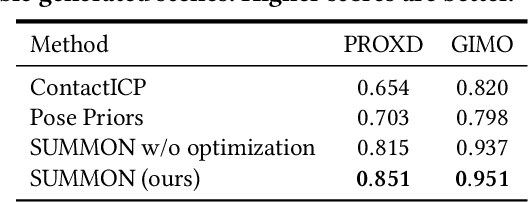
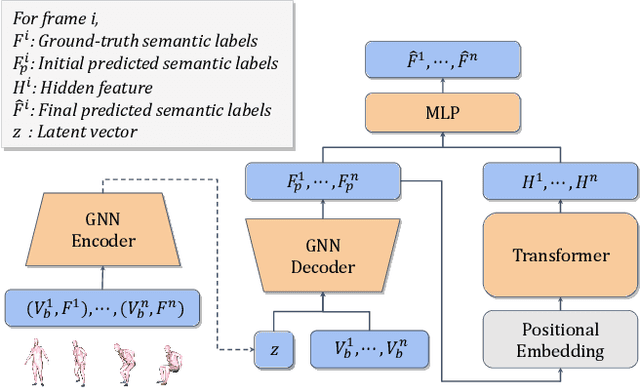
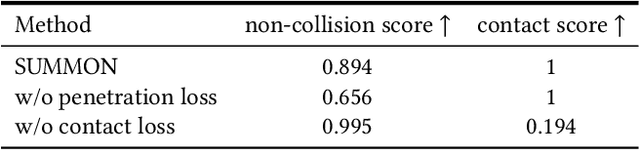
Large-scale capture of human motion with diverse, complex scenes, while immensely useful, is often considered prohibitively costly. Meanwhile, human motion alone contains rich information about the scene they reside in and interact with. For example, a sitting human suggests the existence of a chair, and their leg position further implies the chair's pose. In this paper, we propose to synthesize diverse, semantically reasonable, and physically plausible scenes based on human motion. Our framework, Scene Synthesis from HUMan MotiON (SUMMON), includes two steps. It first uses ContactFormer, our newly introduced contact predictor, to obtain temporally consistent contact labels from human motion. Based on these predictions, SUMMON then chooses interacting objects and optimizes physical plausibility losses; it further populates the scene with objects that do not interact with humans. Experimental results demonstrate that SUMMON synthesizes feasible, plausible, and diverse scenes and has the potential to generate extensive human-scene interaction data for the community.
Source-Aware Spatial-Spectral-Integrated Double U-Net for Image Fusion
Dec 13, 2022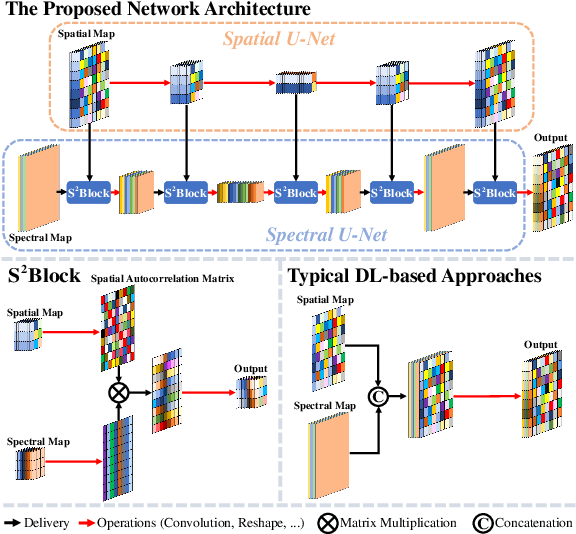
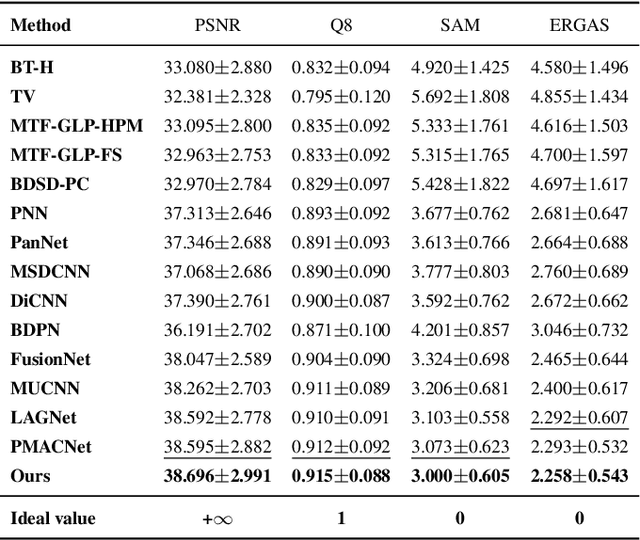
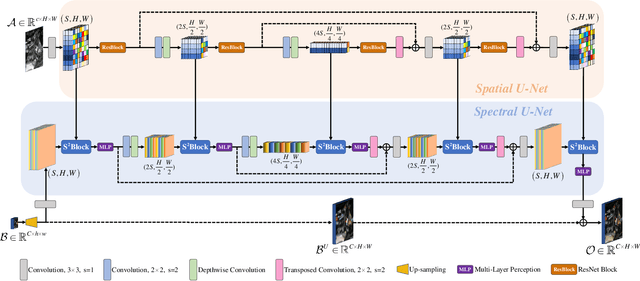
In image fusion tasks, pictures from different sources possess distinctive properties, therefore treating them equally will lead to inadequate feature extracting. Besides, multi-scaled networks capture information more sufficiently than single-scaled models in pixel-wised problems. In light of these factors, we propose a source-aware spatial-spectral-integrated double U-shaped network called $\rm{(SU)^2}$Net. The network is mainly composed of a spatial U-net and a spectral U-net, which learn spatial details and spectral characteristics discriminately and hierarchically. In contrast with most previous works that simply apply concatenation to integrate spatial and spectral information, a novel structure named the spatial-spectral block (called $\rm{S^2}$Block) is specially designed to merge feature maps from different sources effectively. Experiment results show that our method outperforms the representative state-of-the-art (SOTA) approaches in both quantitative and qualitative evaluations for a variety of image fusion missions, including remote sensing pansharpening and hyperspectral image super-resolution (HISR).
Structural State Translation: Condition Transfer between Civil Structures Using Domain-Generalization for Structural Health Monitoring
Dec 28, 2022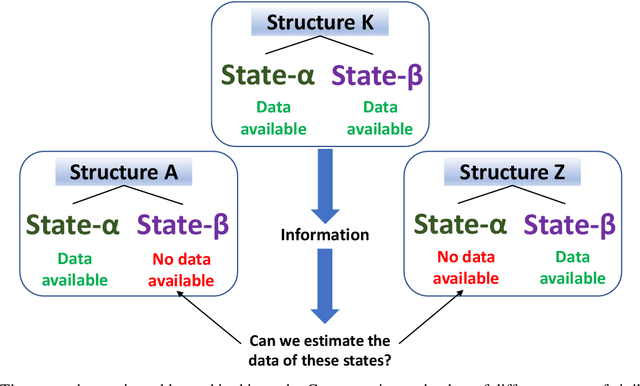
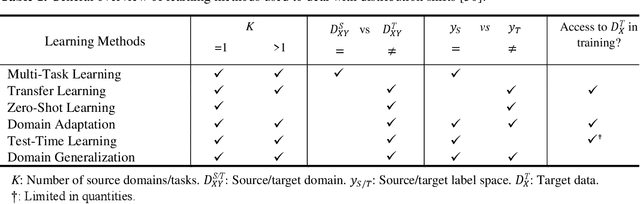
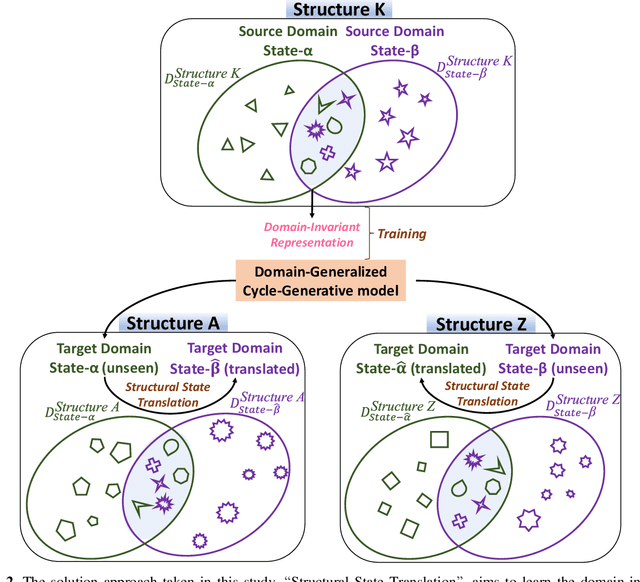
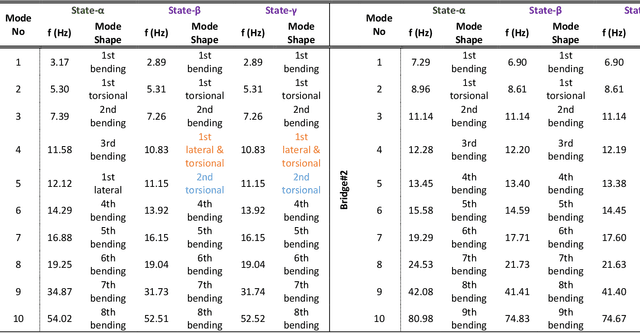
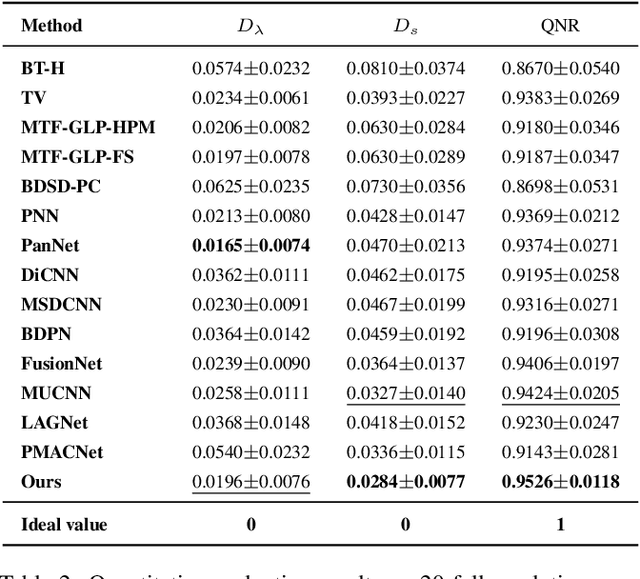
Using Structural Health Monitoring (SHM) systems with extensive sensing arrangements on every civil structure can be costly and impractical. Various concepts have been introduced to alleviate such difficulties, such as Population-based SHM (PBSHM). Nevertheless, the studies presented in the literature do not adequately address the challenge of accessing the information on different structural states (conditions) of dissimilar civil structures. The study herein introduces a novel framework named Structural State Translation (SST), which aims to estimate the response data of different civil structures based on the information obtained from a dissimilar structure. SST can be defined as Translating a state of one civil structure to another state after discovering and learning the domain-invariant representation in the source domains of a dissimilar civil structure. SST employs a Domain-Generalized Cycle-Generative (DGCG) model to learn the domain-invariant representation in the acceleration datasets obtained from a numeric bridge structure that is in two different structural conditions. In other words, the model is tested on three dissimilar numeric bridge models to translate their structural conditions. The evaluation results of SST via Mean Magnitude-Squared Coherence (MMSC) and modal identifiers showed that the translated bridge states (synthetic states) are significantly similar to the real ones. As such, the minimum and maximum average MMSC values of real and translated bridge states are 91.2% and 97.1%, the minimum and the maximum difference in natural frequencies are 5.71% and 0%, and the minimum and maximum Modal Assurance Criterion (MAC) values are 0.998 and 0.870. This study is critical for data scarcity and PBSHM, as it demonstrates that it is possible to obtain data from structures while the structure is actually in a different condition or state.
Counterfactual Explanations for Concepts in $\mathcal{ELH}$
Jan 12, 2023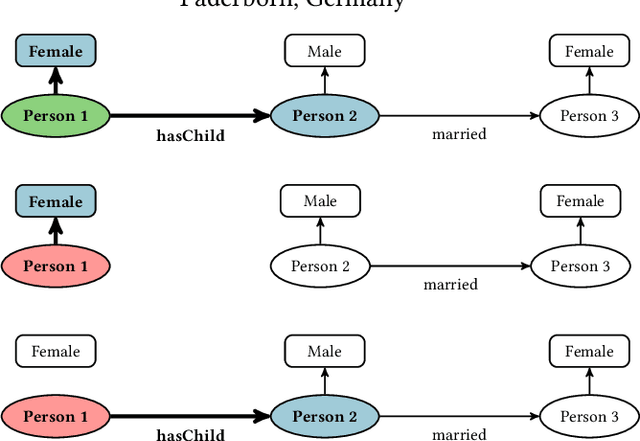
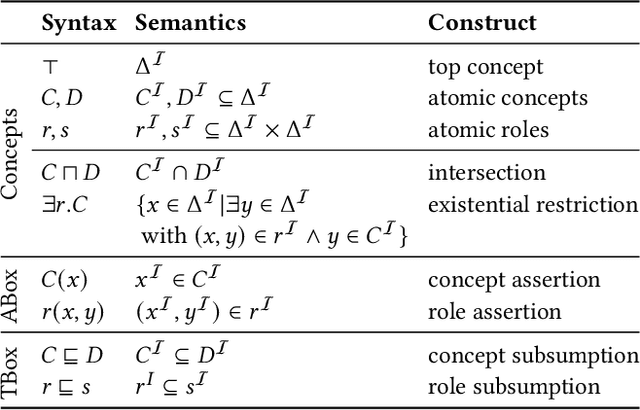
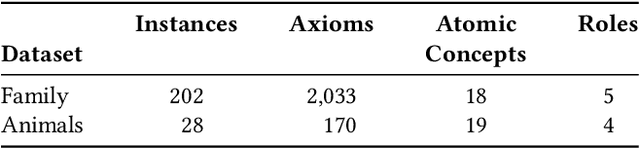
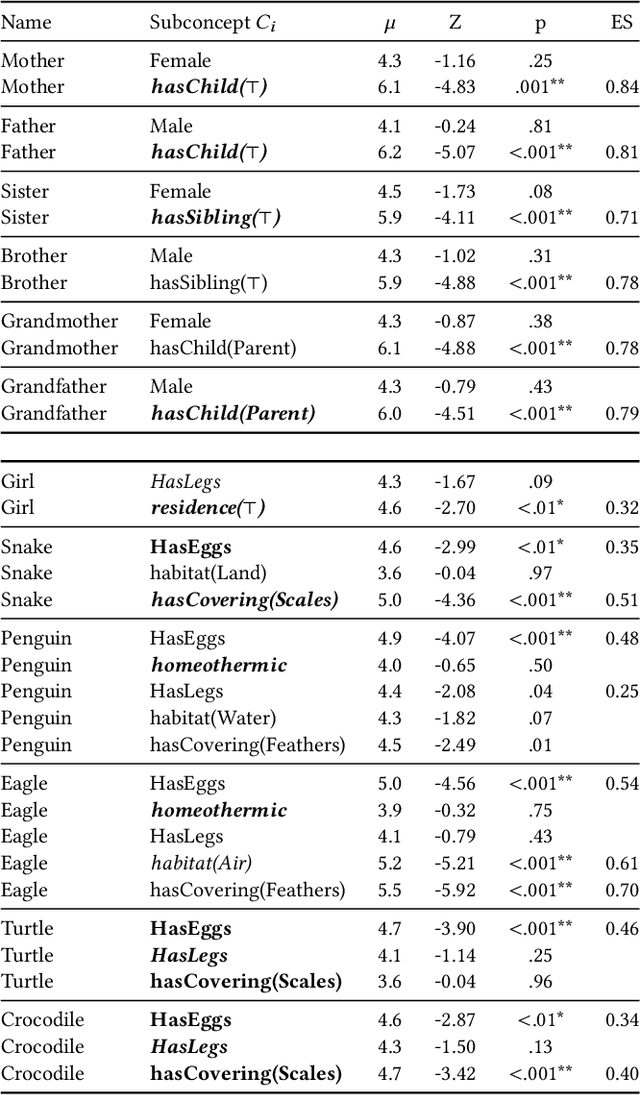
Knowledge bases are widely used for information management on the web, enabling high-impact applications such as web search, question answering, and natural language processing. They also serve as the backbone for automatic decision systems, e.g. for medical diagnostics and credit scoring. As stakeholders affected by these decisions would like to understand their situation and verify fair decisions, a number of explanation approaches have been proposed using concepts in description logics. However, the learned concepts can become long and difficult to fathom for non-experts, even when verbalized. Moreover, long concepts do not immediately provide a clear path of action to change one's situation. Counterfactuals answering the question "How must feature values be changed to obtain a different classification?" have been proposed as short, human-friendly explanations for tabular data. In this paper, we transfer the notion of counterfactuals to description logics and propose the first algorithm for generating counterfactual explanations in the description logic $\mathcal{ELH}$. Counterfactual candidates are generated from concepts and the candidates with fewest feature changes are selected as counterfactuals. In case of multiple counterfactuals, we rank them according to the likeliness of their feature combinations. For evaluation, we conduct a user survey to investigate which of the generated counterfactual candidates are preferred for explanation by participants. In a second study, we explore possible use cases for counterfactual explanations.