 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An automated, geometry-based method for the analysis of hippocampal thickness
Feb 01, 2023
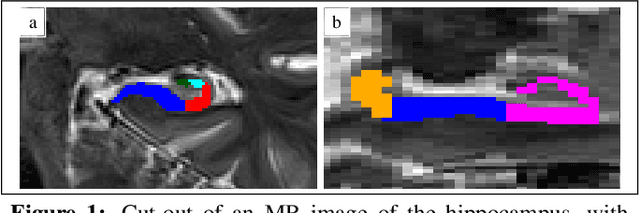
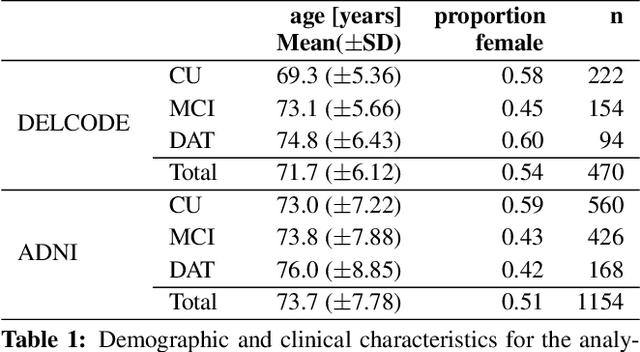
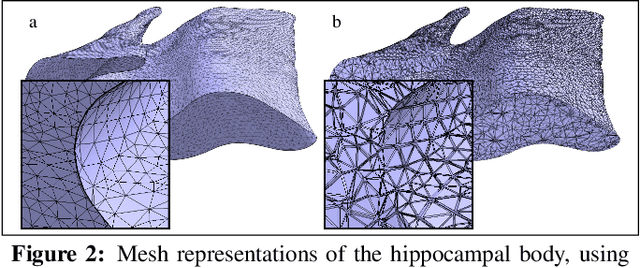
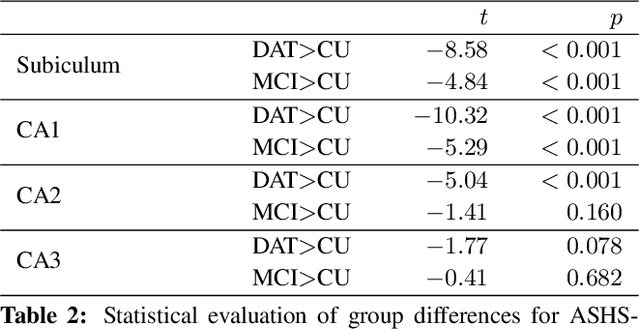
The hippocampus is one of the most studied neuroanatomical structures due to its involvement in attention, learning, and memory as well as its atrophy in ageing, neurological, and psychiatric diseases. Hippocampal shape changes, however, are complex and cannot be fully characterized by a single summary metric such as hippocampal volume as determined from MR images. In this work, we propose an automated, geometry-based approach for the unfolding, point-wise correspondence, and local analysis of hippocampal shape features such as thickness and curvature. Starting from an automated segmentation of hippocampal subfields, we create a 3D tetrahedral mesh model as well as a 3D intrinsic coordinate system of the hippocampal body. From this coordinate system, we derive local curvature and thickness estimates as well as a 2D sheet for hippocampal unfolding. We evaluate the performance of our algorithm with a series of experiments to quantify neurodegenerative changes in Mild Cognitive Impairment and Alzheimer's disease dementia. We find that hippocampal thickness estimates detect known differences between clinical groups and can determine the location of these effects on the hippocampal sheet. Further, thickness estimates improve classification of clinical groups and cognitively unimpaired controls when added as an additional predictor. Comparable results are obtained with different datasets and segmentation algorithms. Taken together, we replicate canonical findings on hippocampal volume/shape changes in dementia, extend them by gaining insight into their spatial localization on the hippocampal sheet, and provide additional, complementary information beyond traditional measures. We provide a new set of sensitive processing and analysis tools for the analysis of hippocampal geometry that allows comparisons across studies without relying on image registration or requiring manual intervention.
Unifying Molecular and Textual Representations via Multi-task Language Modelling
Jan 29, 2023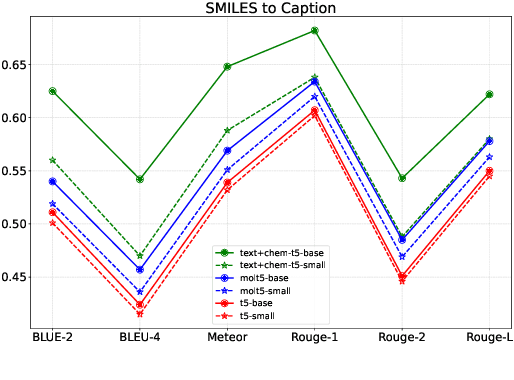
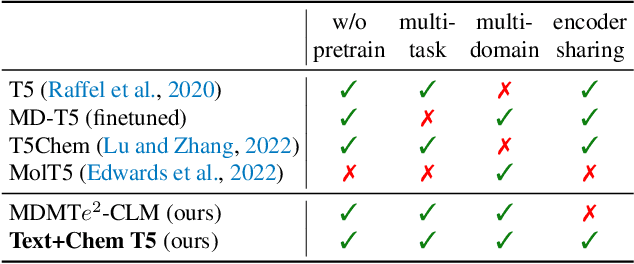
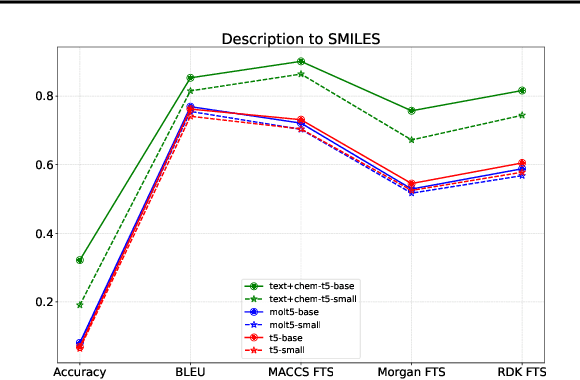
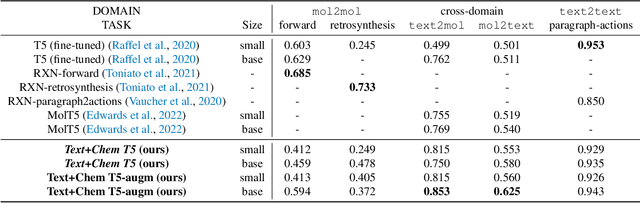
The recent advances in neural language models have also been successfully applied to the field of chemistry, offering generative solutions for classical problems in molecular design and synthesis planning. These new methods have the potential to optimize laboratory operations and fuel a new era of data-driven automation in scientific discovery. However, specialized models are still typically required for each task, leading to the need for problem-specific fine-tuning and neglecting task interrelations. The main obstacle in this field is the lack of a unified representation between natural language and chemical representations, complicating and limiting human-machine interaction. Here, we propose a multi-domain, multi-task language model to solve a wide range of tasks in both the chemical and natural language domains. By leveraging multi-task learning, our model can handle chemical and natural language concurrently, without requiring expensive pre-training on single domains or task-specific models. Interestingly, sharing weights across domains remarkably improves our model when benchmarked against state-of-the-art baselines on single-domain and cross-domain tasks. In particular, sharing information across domains and tasks gives rise to large improvements in cross-domain tasks, the magnitude of which increase with scale, as measured by more than a dozen of relevant metrics. Our work suggests that such models can robustly and efficiently accelerate discovery in physical sciences by superseding problem-specific fine-tuning and enhancing human-model interactions.
Self-supervised Semi-implicit Graph Variational Auto-encoders with Masking
Jan 29, 2023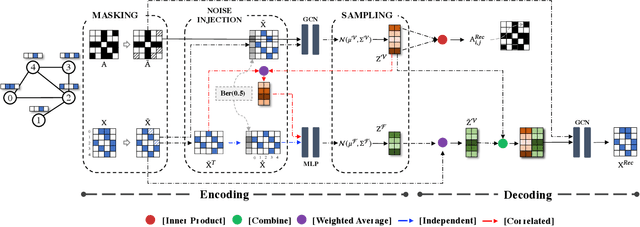
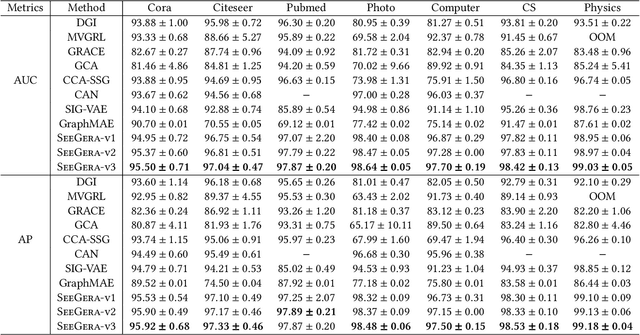

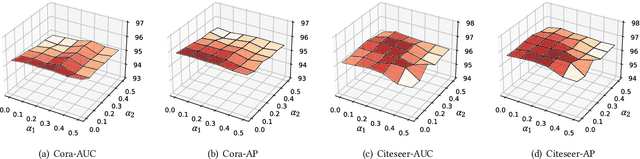
Generative graph self-supervised learning (SSL) aims to learn node representations by reconstructing the input graph data. However, most existing methods focus on unsupervised learning tasks only and very few work has shown its superiority over the state-of-the-art graph contrastive learning (GCL) models, especially on the classification task. While a very recent model has been proposed to bridge the gap, its performance on unsupervised learning tasks is still unknown. In this paper, to comprehensively enhance the performance of generative graph SSL against other GCL models on both unsupervised and supervised learning tasks, we propose the SeeGera model, which is based on the family of self-supervised variational graph auto-encoder (VGAE). Specifically, SeeGera adopts the semi-implicit variational inference framework, a hierarchical variational framework, and mainly focuses on feature reconstruction and structure/feature masking. On the one hand, SeeGera co-embeds both nodes and features in the encoder and reconstructs both links and features in the decoder. Since feature embeddings contain rich semantic information on features, they can be combined with node embeddings to provide fine-grained knowledge for feature reconstruction. On the other hand, SeeGera adds an additional layer for structure/feature masking to the hierarchical variational framework, which boosts the model generalizability. We conduct extensive experiments comparing SeeGera with 9 other state-of-the-art competitors. Our results show that SeeGera can compare favorably against other state-of-the-art GCL methods in a variety of unsupervised and supervised learning tasks.
Confidence-Aware Calibration and Scoring Functions for Curriculum Learning
Jan 29, 2023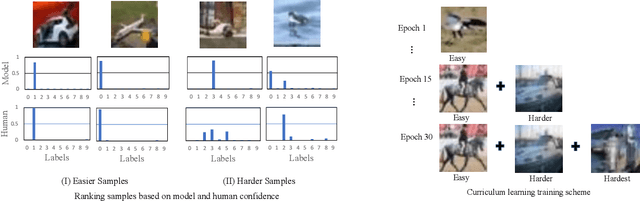
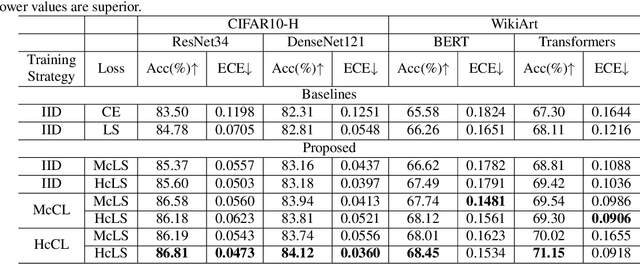
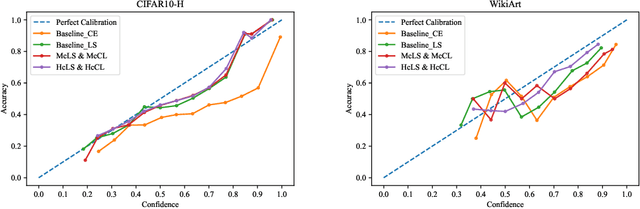
Despite the great success of state-of-the-art deep neural networks, several studies have reported models to be over-confident in predictions, indicating miscalibration. Label Smoothing has been proposed as a solution to the over-confidence problem and works by softening hard targets during training, typically by distributing part of the probability mass from a `one-hot' label uniformly to all other labels. However, neither model nor human confidence in a label are likely to be uniformly distributed in this manner, with some labels more likely to be confused than others. In this paper we integrate notions of model confidence and human confidence with label smoothing, respectively \textit{Model Confidence LS} and \textit{Human Confidence LS}, to achieve better model calibration and generalization. To enhance model generalization, we show how our model and human confidence scores can be successfully applied to curriculum learning, a training strategy inspired by learning of `easier to harder' tasks. A higher model or human confidence score indicates a more recognisable and therefore easier sample, and can therefore be used as a scoring function to rank samples in curriculum learning. We evaluate our proposed methods with four state-of-the-art architectures for image and text classification task, using datasets with multi-rater label annotations by humans. We report that integrating model or human confidence information in label smoothing and curriculum learning improves both model performance and model calibration. The code are available at \url{https://github.com/AoShuang92/Confidence_Calibration_CL}.
Leveraging Natural Language Processing to Augment Structured Social Determinants of Health Data in the Electronic Health Record
Dec 14, 2022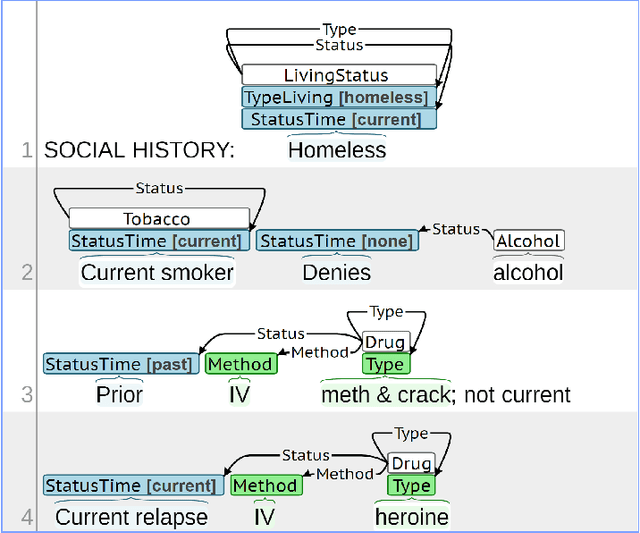
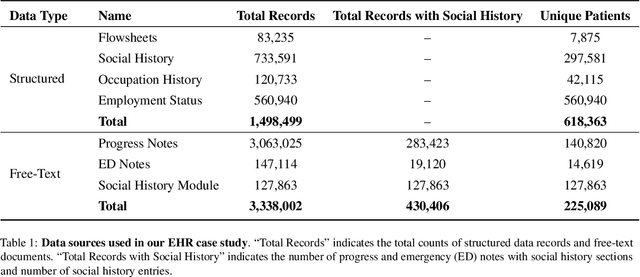
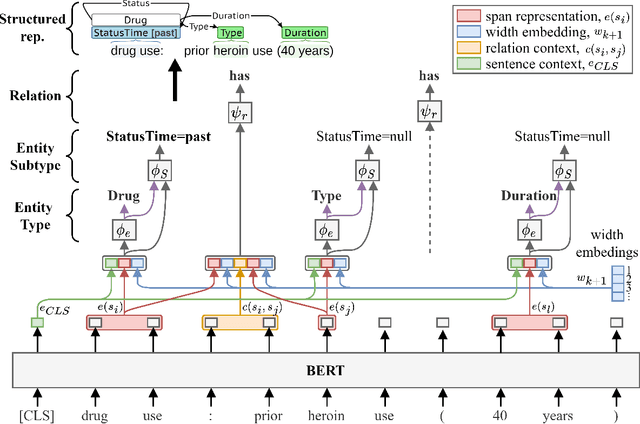
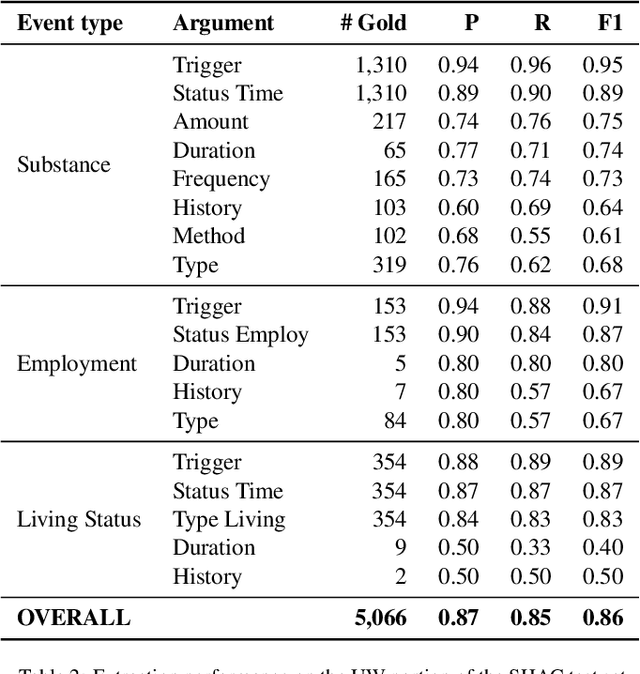
Objective: Social Determinants of Health (SDOH) influence personal health outcomes and health systems interactions. Health systems capture SDOH information through structured data and unstructured clinical notes; however, clinical notes often contain a more comprehensive representation of several key SDOH. The objective of this work is to assess the SDOH information gain achievable by extracting structured semantic representations of SDOH from the clinical narrative and combining these extracted representations with available structured data. Materials and Methods: We developed a natural language processing (NLP) information extraction model for SDOH that utilizes a deep learning entity and relation extraction architecture. In an electronic health record (EHR) case study, we applied the SDOH extractor to a large existing clinical data set with over 200,000 patients and 400,000 notes and compared the extracted information with available structured data. Results: The SDOH extractor achieved 0.86 F1 on a withheld test set. In the EHR case study, we found 19\% of current tobacco users, 10\% of drug users, and 32\% of homeless patients only include documentation of these risk factors in the clinical narrative. Conclusions: Patients who are at-risk for negative health outcomes due to SDOH may be better served if health systems are able to identify SDOH risk factors and associated social needs. Structured semantic representations of text-encoded SDOH information can augment existing structured, and this more comprehensive SDOH representation can assist health systems in identifying and addressing social needs.
Deep learning-based approaches for human motion decoding in smart walkers for rehabilitation
Jan 13, 2023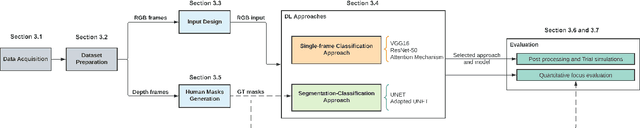

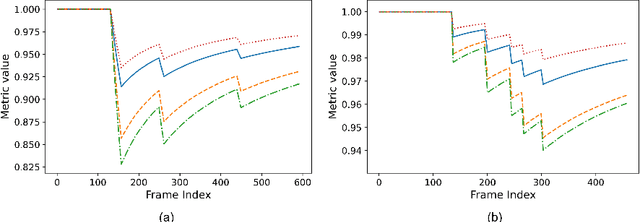
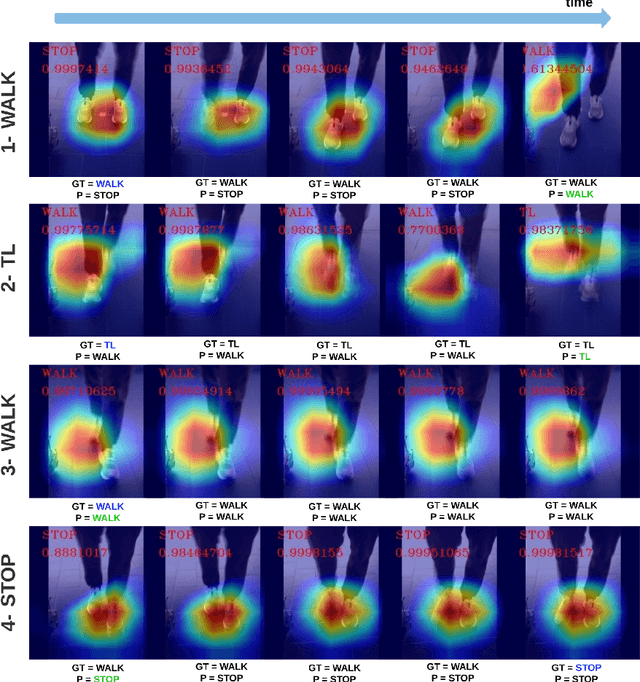
Gait disabilities are among the most frequent worldwide. Their treatment relies on rehabilitation therapies, in which smart walkers are being introduced to empower the user's recovery and autonomy, while reducing the clinicians effort. For that, these should be able to decode human motion and needs, as early as possible. Current walkers decode motion intention using information of wearable or embedded sensors, namely inertial units, force and hall sensors, and lasers, whose main limitations imply an expensive solution or hinder the perception of human movement. Smart walkers commonly lack a seamless human-robot interaction, which intuitively understands human motions. A contactless approach is proposed in this work, addressing human motion decoding as an early action recognition/detection problematic, using RGB-D cameras. We studied different deep learning-based algorithms, organised in three different approaches, to process lower body RGB-D video sequences, recorded from an embedded camera of a smart walker, and classify them into 4 classes (stop, walk, turn right/left). A custom dataset involving 15 healthy participants walking with the device was acquired and prepared, resulting in 28800 balanced RGB-D frames, to train and evaluate the deep networks. The best results were attained by a convolutional neural network with a channel attention mechanism, reaching accuracy values of 99.61% and above 93%, for offline early detection/recognition and trial simulations, respectively. Following the hypothesis that human lower body features encode prominent information, fostering a more robust prediction towards real-time applications, the algorithm focus was also evaluated using Dice metric, leading to values slightly higher than 30%. Promising results were attained for early action detection as a human motion decoding strategy, with enhancements in the focus of the proposed architectures.
Multi-Target Landmark Detection with Incomplete Images via Reinforcement Learning and Shape Prior
Jan 13, 2023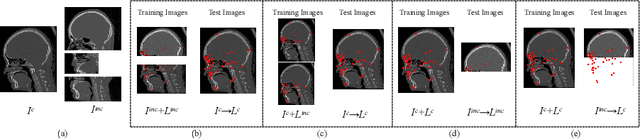
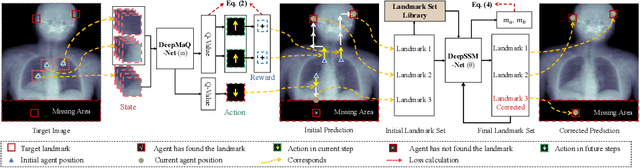

Medical images are generally acquired with limited field-of-view (FOV), which could lead to incomplete regions of interest (ROI), and thus impose a great challenge on medical image analysis. This is particularly evident for the learning-based multi-target landmark detection, where algorithms could be misleading to learn primarily the variation of background due to the varying FOV, failing the detection of targets. Based on learning a navigation policy, instead of predicting targets directly, reinforcement learning (RL)-based methods have the potential totackle this challenge in an efficient manner. Inspired by this, in this work we propose a multi-agent RL framework for simultaneous multi-target landmark detection. This framework is aimed to learn from incomplete or (and) complete images to form an implicit knowledge of global structure, which is consolidated during the training stage for the detection of targets from either complete or incomplete test images. To further explicitly exploit the global structural information from incomplete images, we propose to embed a shape model into the RL process. With this prior knowledge, the proposed RL model can not only localize dozens of targetssimultaneously, but also work effectively and robustly in the presence of incomplete images. We validated the applicability and efficacy of the proposed method on various multi-target detection tasks with incomplete images from practical clinics, using body dual-energy X-ray absorptiometry (DXA), cardiac MRI and head CT datasets. Results showed that our method could predict whole set of landmarks with incomplete training images up to 80% missing proportion (average distance error 2.29 cm on body DXA), and could detect unseen landmarks in regions with missing image information outside FOV of target images (average distance error 6.84 mm on 3D half-head CT).
Oversquashing in GNNs through the lens of information contraction and graph expansion
Aug 06, 2022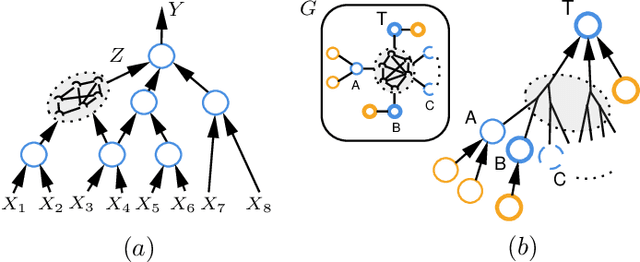
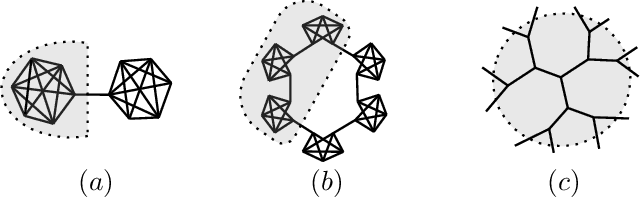
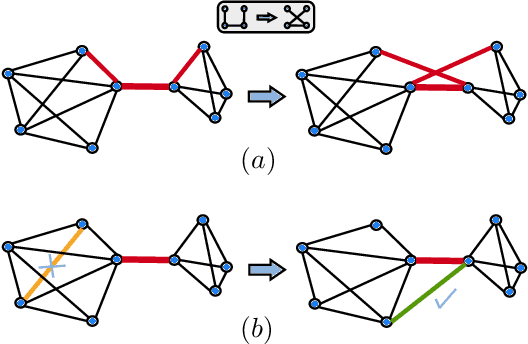
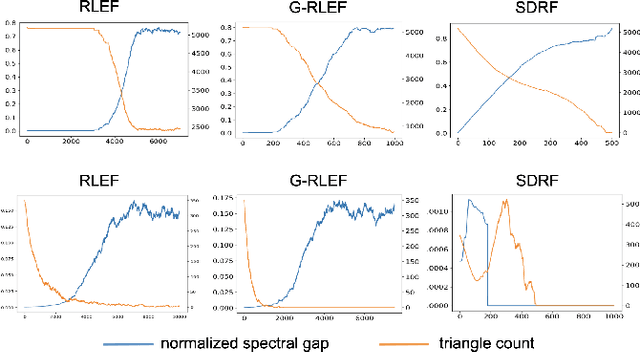
The quality of signal propagation in message-passing graph neural networks (GNNs) strongly influences their expressivity as has been observed in recent works. In particular, for prediction tasks relying on long-range interactions, recursive aggregation of node features can lead to an undesired phenomenon called "oversquashing". We present a framework for analyzing oversquashing based on information contraction. Our analysis is guided by a model of reliable computation due to von Neumann that lends a new insight into oversquashing as signal quenching in noisy computation graphs. Building on this, we propose a graph rewiring algorithm aimed at alleviating oversquashing. Our algorithm employs a random local edge flip primitive motivated by an expander graph construction. We compare the spectral expansion properties of our algorithm with that of an existing curvature-based non-local rewiring strategy. Synthetic experiments show that while our algorithm in general has a slower rate of expansion, it is overall computationally cheaper, preserves the node degrees exactly and never disconnects the graph.
The moral authority of ChatGPT
Jan 13, 2023
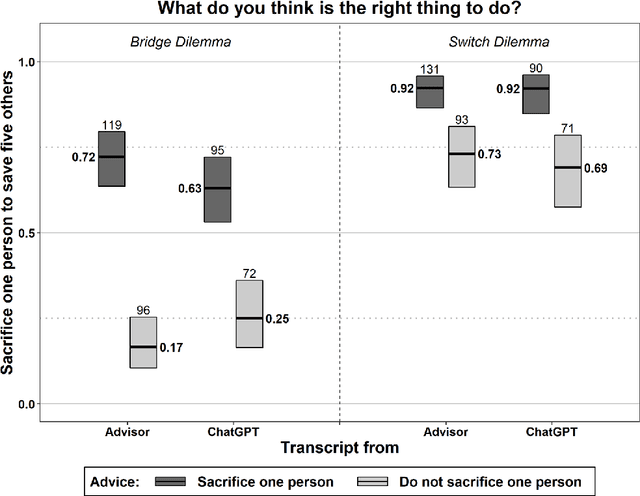
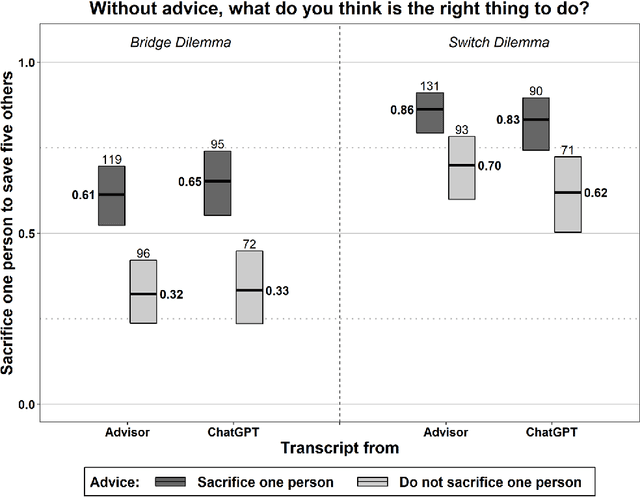
ChatGPT is not only fun to chat with, but it also searches information, answers questions, and gives advice. With consistent moral advice, it might improve the moral judgment and decisions of users, who often hold contradictory moral beliefs. Unfortunately, ChatGPT turns out highly inconsistent as a moral advisor. Nonetheless, it influences users' moral judgment, we find in an experiment, even if they know they are advised by a chatting bot, and they underestimate how much they are influenced. Thus, ChatGPT threatens to corrupt rather than improves users' judgment. These findings raise the question of how to ensure the responsible use of ChatGPT and similar AI. Transparency is often touted but seems ineffective. We propose training to improve digital literacy.
GLIGEN: Open-Set Grounded Text-to-Image Generation
Jan 17, 2023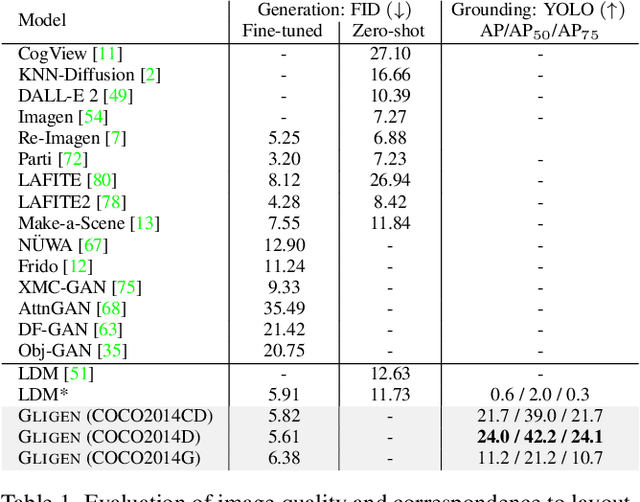
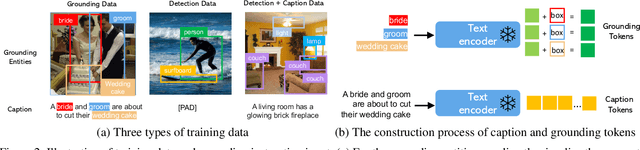
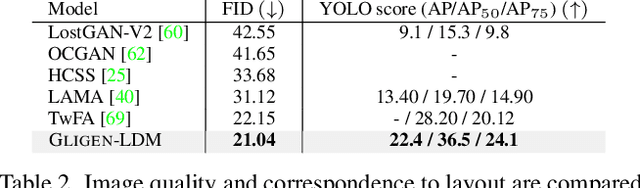
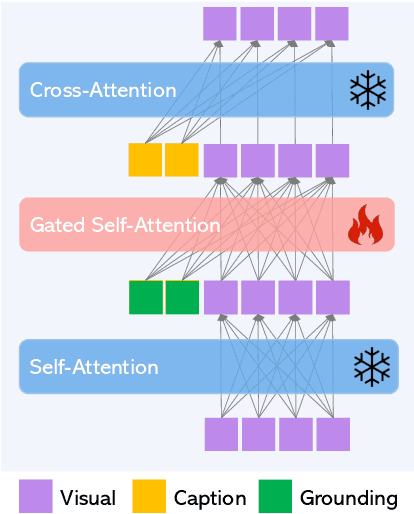
Large-scale text-to-image diffusion models have made amazing advances. However, the status quo is to use text input alone, which can impede controllability. In this work, we propose GLIGEN, Grounded-Language-to-Image Generation, a novel approach that builds upon and extends the functionality of existing pre-trained text-to-image diffusion models by enabling them to also be conditioned on grounding inputs. To preserve the vast concept knowledge of the pre-trained model, we freeze all of its weights and inject the grounding information into new trainable layers via a gated mechanism. Our model achieves open-world grounded text2img generation with caption and bounding box condition inputs, and the grounding ability generalizes well to novel spatial configuration and concepts. GLIGEN's zero-shot performance on COCO and LVIS outperforms that of existing supervised layout-to-image baselines by a large margin.