 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Conversation Style Transfer using Few-Shot Learning
Feb 16, 2023
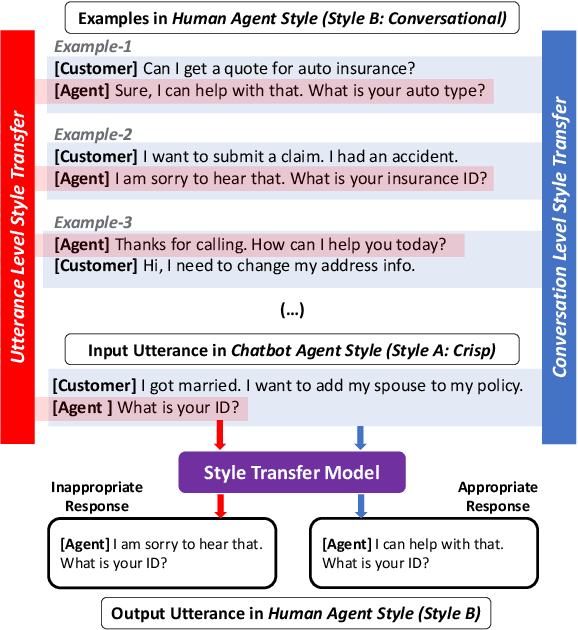

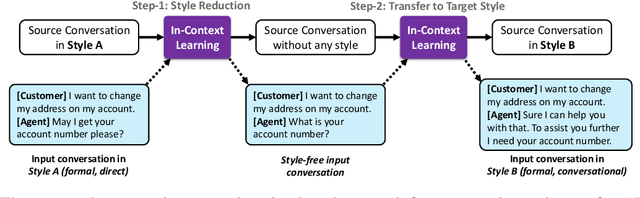
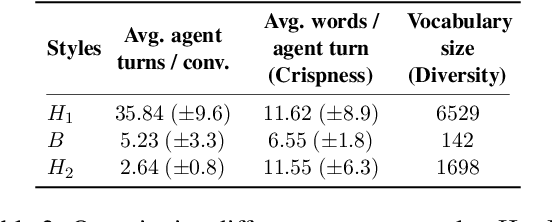
Conventional text style transfer approaches for natural language focus on sentence-level style transfer without considering contextual information, and the style is described with attributes (e.g., formality). When applying style transfer on conversations such as task-oriented dialogues, existing approaches suffer from these limitations as context can play an important role and the style attributes are often difficult to define in conversations. In this paper, we introduce conversation style transfer as a few-shot learning problem, where the model learns to perform style transfer by observing only the target-style dialogue examples. We propose a novel in-context learning approach to solve the task with style-free dialogues as a pivot. Human evaluation shows that by incorporating multi-turn context, the model is able to match the target style while having better appropriateness and semantic correctness compared to utterance-level style transfer. Additionally, we show that conversation style transfer can also benefit downstream tasks. Results on multi-domain intent classification tasks show improvement in F1 scores after transferring the style of training data to match the style of test data.
Adapting Step-size: A Unified Perspective to Analyze and Improve Gradient-based Methods for Adversarial Attacks
Feb 02, 2023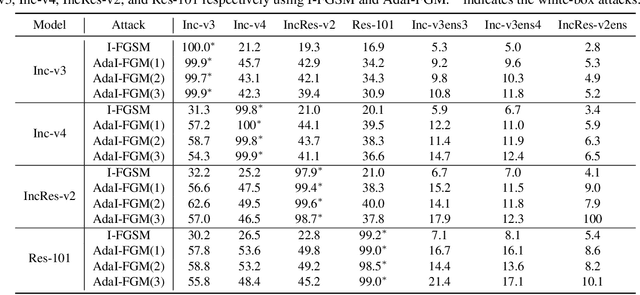
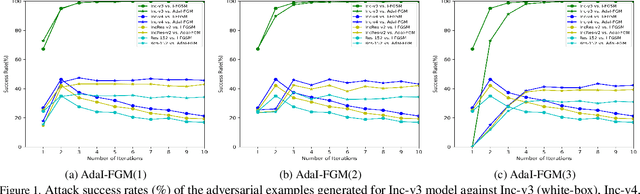
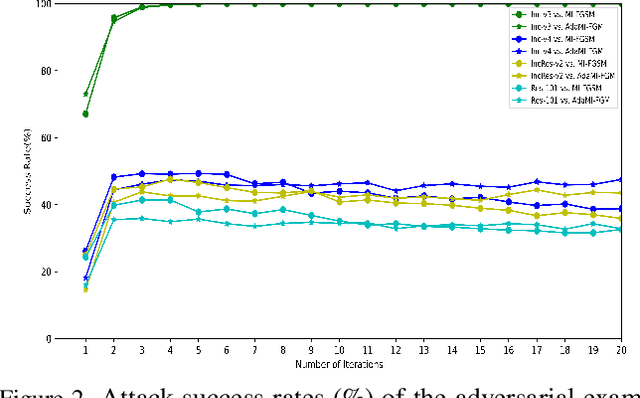

Learning adversarial examples can be formulated as an optimization problem of maximizing the loss function with some box-constraints. However, for solving this induced optimization problem, the state-of-the-art gradient-based methods such as FGSM, I-FGSM and MI-FGSM look different from their original methods especially in updating the direction, which makes it difficult to understand them and then leaves some theoretical issues to be addressed in viewpoint of optimization. In this paper, from the perspective of adapting step-size, we provide a unified theoretical interpretation of these gradient-based adversarial learning methods. We show that each of these algorithms is in fact a specific reformulation of their original gradient methods but using the step-size rules with only current gradient information. Motivated by such analysis, we present a broad class of adaptive gradient-based algorithms based on the regular gradient methods, in which the step-size strategy utilizing information of the accumulated gradients is integrated. Such adaptive step-size strategies directly normalize the scale of the gradients rather than use some empirical operations. The important benefit is that convergence for the iterative algorithms is guaranteed and then the whole optimization process can be stabilized. The experiments demonstrate that our AdaI-FGM consistently outperforms I-FGSM and AdaMI-FGM remains competitive with MI-FGSM for black-box attacks.
Adaptive Siamese Tracking with a Compact Latent Network
Feb 02, 2023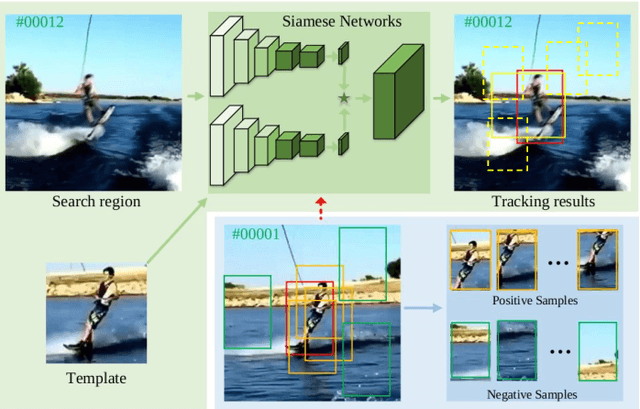
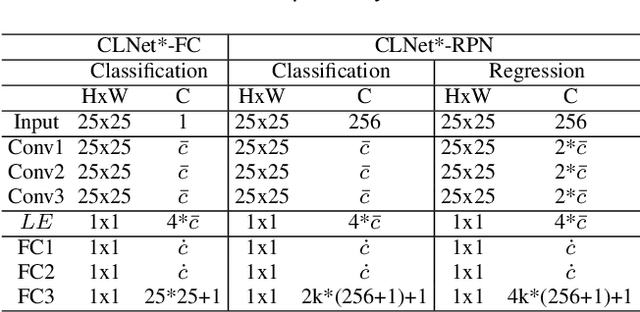
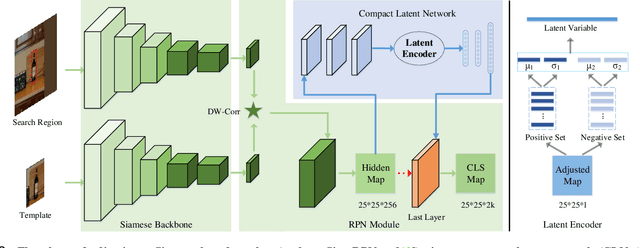

In this paper, we provide an intuitive viewing to simplify the Siamese-based trackers by converting the tracking task to a classification. Under this viewing, we perform an in-depth analysis for them through visual simulations and real tracking examples, and find that the failure cases in some challenging situations can be regarded as the issue of missing decisive samples in offline training. Since the samples in the initial (first) frame contain rich sequence-specific information, we can regard them as the decisive samples to represent the whole sequence. To quickly adapt the base model to new scenes, a compact latent network is presented via fully using these decisive samples. Specifically, we present a statistics-based compact latent feature for fast adjustment by efficiently extracting the sequence-specific information. Furthermore, a new diverse sample mining strategy is designed for training to further improve the discrimination ability of the proposed compact latent network. Finally, a conditional updating strategy is proposed to efficiently update the basic models to handle scene variation during the tracking phase. To evaluate the generalization ability and effectiveness and of our method, we apply it to adjust three classical Siamese-based trackers, namely SiamRPN++, SiamFC, and SiamBAN. Extensive experimental results on six recent datasets demonstrate that all three adjusted trackers obtain the superior performance in terms of the accuracy, while having high running speed.
* Extended version of the paper "CLNet: A Compact Latent Network for Fast Adjusting Siamese Trackers" presented at ECCV 2020. Accepted at TPAMI
Physical Layer Security in Near-Field Communications: What Will Be Changed?
Feb 08, 2023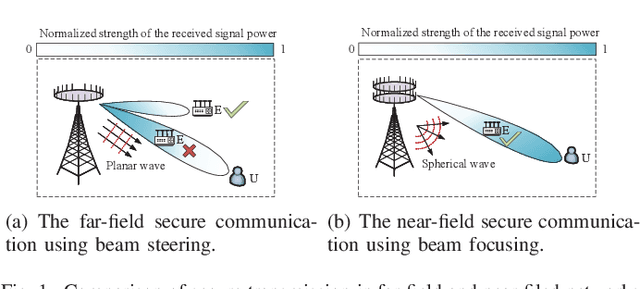
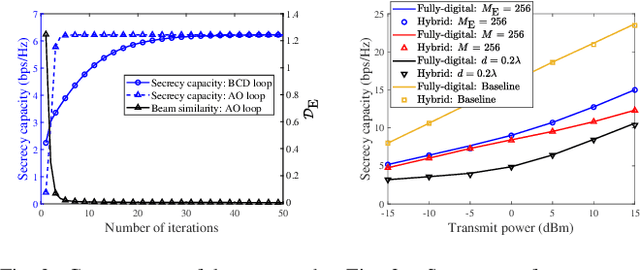
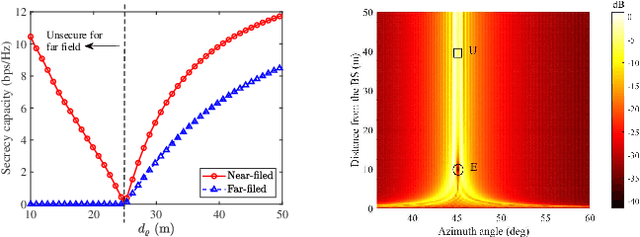
A near-field secure transmission framework is proposed. Employing the hybrid beamforming architecture, a base station (BS) transmits the confidential information to a legitimate user (U) against an eavesdropper (E) in the near field. A two-stage algorithm is proposed to maximize the near-field secrecy capacity. Based on the fully-digital beamformers obtained in the first stage, the optimal analog beamformers and baseband digital beamformers can be alternatingly derived in the closed-form expressions in the second stage. Numerical results demonstrate that in contrast to the far-field secure communication relying on the angular disparity, the near-filed secure communication in the near-field communication mainly relies on the distance disparity between U and E.
A General-Purpose Transferable Predictor for Neural Architecture Search
Feb 21, 2023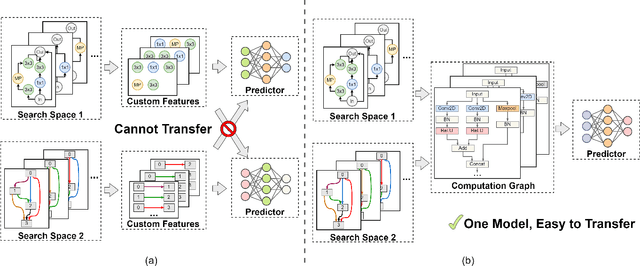
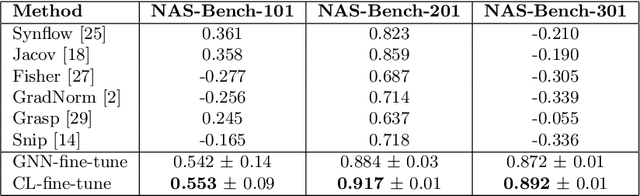
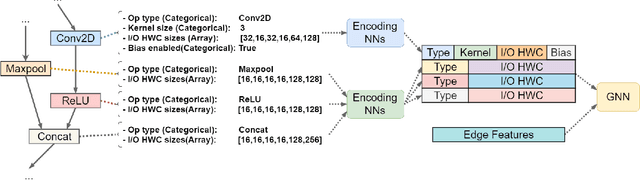

Understanding and modelling the performance of neural architectures is key to Neural Architecture Search (NAS). Performance predictors have seen widespread use in low-cost NAS and achieve high ranking correlations between predicted and ground truth performance in several NAS benchmarks. However, existing predictors are often designed based on network encodings specific to a predefined search space and are therefore not generalizable to other search spaces or new architecture families. In this paper, we propose a general-purpose neural predictor for NAS that can transfer across search spaces, by representing any given candidate Convolutional Neural Network (CNN) with a Computation Graph (CG) that consists of primitive operators. We further combine our CG network representation with Contrastive Learning (CL) and propose a graph representation learning procedure that leverages the structural information of unlabeled architectures from multiple families to train CG embeddings for our performance predictor. Experimental results on NAS-Bench-101, 201 and 301 demonstrate the efficacy of our scheme as we achieve strong positive Spearman Rank Correlation Coefficient (SRCC) on every search space, outperforming several Zero-Cost Proxies, including Synflow and Jacov, which are also generalizable predictors across search spaces. Moreover, when using our proposed general-purpose predictor in an evolutionary neural architecture search algorithm, we can find high-performance architectures on NAS-Bench-101 and find a MobileNetV3 architecture that attains 79.2% top-1 accuracy on ImageNet.
Dealing with Collinearity in Large-Scale Linear System Identification Using Gaussian Regression
Feb 21, 2023
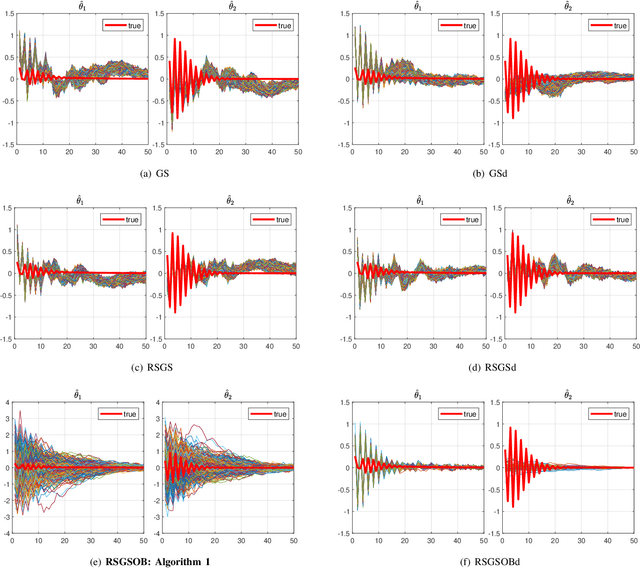
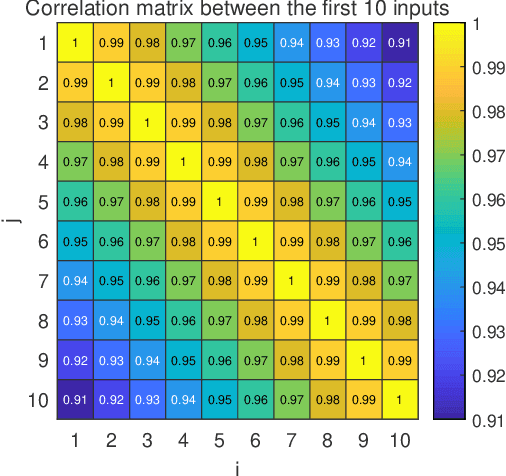
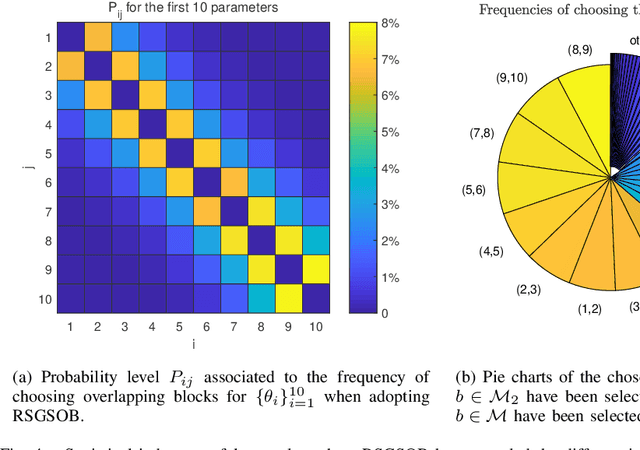
Many problems arising in control and cybernetics require the determination of a mathematical model of the application. This has often to be performed starting from input-output data, leading to a task known as system identification in the engineering literature. One emerging topic in this field is estimation of networks consisting of several interconnected dynamic systems. We consider the linear setting assuming that system outputs are the result of many correlated inputs, hence making system identification severely ill-conditioned. This is a scenario often encountered when modeling complex cybernetics systems composed by many sub-units with feedback and algebraic loops. We develop a strategy cast in a Bayesian regularization framework where any impulse response is seen as realization of a zero-mean Gaussian process. Any covariance is defined by the so called stable spline kernel which includes information on smooth exponential decay. We design a novel Markov chain Monte Carlo scheme able to reconstruct the impulse responses posterior by efficiently dealing with collinearity. Our scheme relies on a variation of the Gibbs sampling technique: beyond considering blocks forming a partition of the parameter space, some other (overlapping) blocks are also updated on the basis of the level of collinearity of the system inputs. Theoretical properties of the algorithm are studied obtaining its convergence rate. Numerical experiments are included using systems containing hundreds of impulse responses and highly correlated inputs.
Data-driven reduced-order modelling for blood flow simulations with geometry-informed snapshots
Feb 21, 2023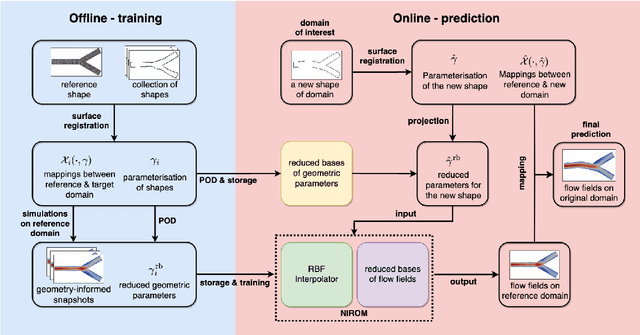
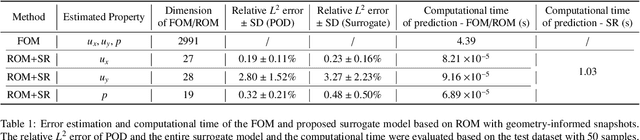
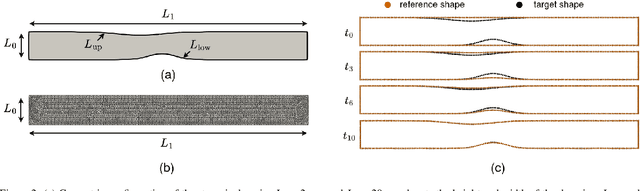

Computational fluid dynamics is a common tool in cardiovascular science and engineering to simulate, predict and study hemodynamics in arteries. However, owing to the complexity and scale of cardiovascular flow problems, the evaluation of the model could be computationally expensive, especially in those cases where a large number of evaluations are required, such as uncertainty quantification and design optimisation. In such scenarios, the model may have to be repeatedly evaluated due to the changes or distinctions of simulation domains. In this work, a data-driven surrogate model is proposed for the efficient prediction of blood flow simulations on similar but distinct domains. The proposed surrogate model leverages surface registration to parameterise those similar but distinct shapes and formulate corresponding hemodynamics information into geometry-informed snapshots by the diffeomorphism constructed between the reference domain and target domain. A non-intrusive reduced-order model for geometrical parameters is subsequently constructed using proper orthogonal decomposition, and a radial basis function interpolator is trained for predicting the reduced coefficients of the reduced-order model based on reduced coefficients of geometrical parameters of the shape. Two examples of blood flowing through a stenosis and a bifurcation are presented and analysed. The proposed surrogate model demonstrates its accuracy and efficiency in hemodynamics prediction and shows its potential application toward real-time simulation or uncertainty quantification for complex patient-specific scenarios.
Weather2K: A Multivariate Spatio-Temporal Benchmark Dataset for Meteorological Forecasting Based on Real-Time Observation Data from Ground Weather Stations
Feb 21, 2023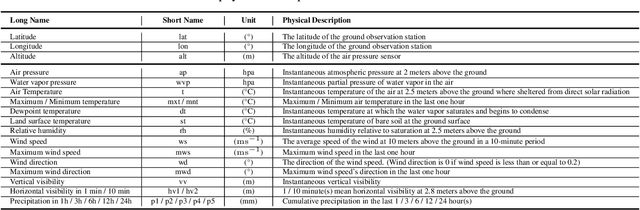
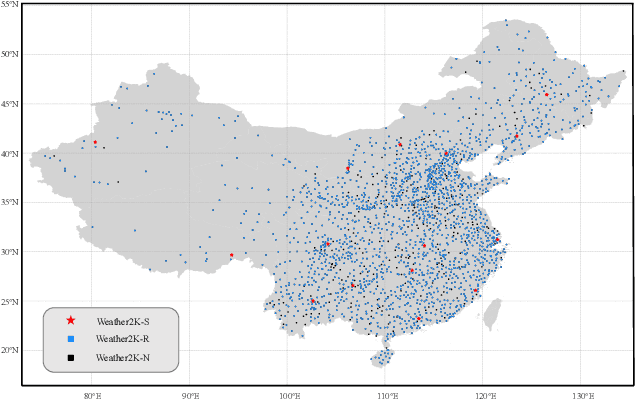
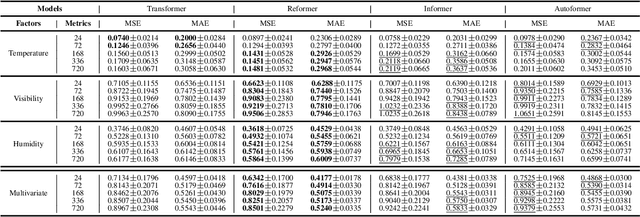
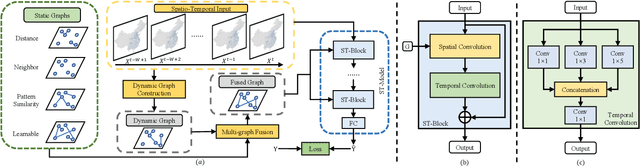
Weather forecasting is one of the cornerstones of meteorological work. In this paper, we present a new benchmark dataset named Weather2K, which aims to make up for the deficiencies of existing weather forecasting datasets in terms of real-time, reliability, and diversity, as well as the key bottleneck of data quality. To be specific, our Weather2K is featured from the following aspects: 1) Reliable and real-time data. The data is hourly collected from 2,130 ground weather stations covering an area of 6 million square kilometers. 2) Multivariate meteorological variables. 20 meteorological factors and 3 constants for position information are provided with a length of 40,896 time steps. 3) Applicable to diverse tasks. We conduct a set of baseline tests on time series forecasting and spatio-temporal forecasting. To the best of our knowledge, our Weather2K is the first attempt to tackle weather forecasting task by taking full advantage of the strengths of observation data from ground weather stations. Based on Weather2K, we further propose Meteorological Factors based Multi-Graph Convolution Network (MFMGCN), which can effectively construct the intrinsic correlation among geographic locations based on meteorological factors. Sufficient experiments show that MFMGCN improves both the forecasting performance and temporal robustness. We hope our Weather2K can significantly motivate researchers to develop efficient and accurate algorithms to advance the task of weather forecasting. The dataset can be available at https://github.com/bycnfz/weather2k/.
Mutual Information and Ensemble Based Feature Recommender for Renal Cancer Stage Classification
Sep 28, 2022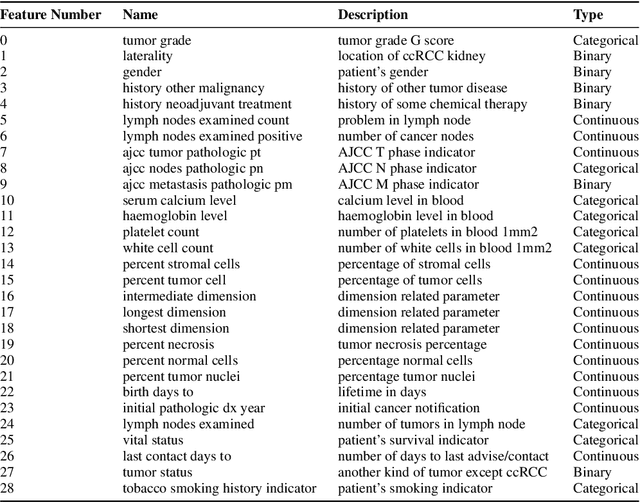
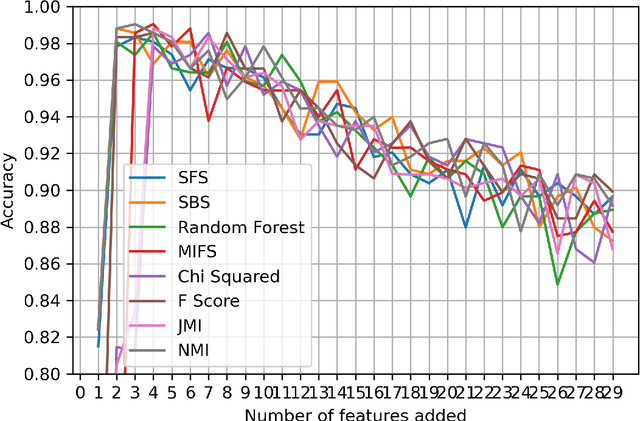
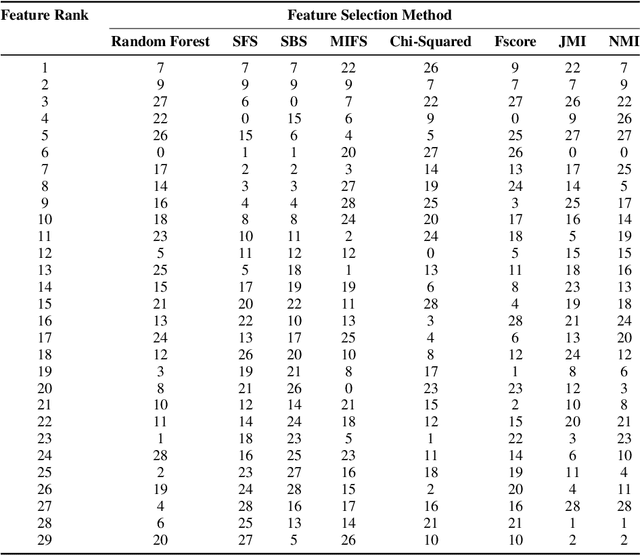
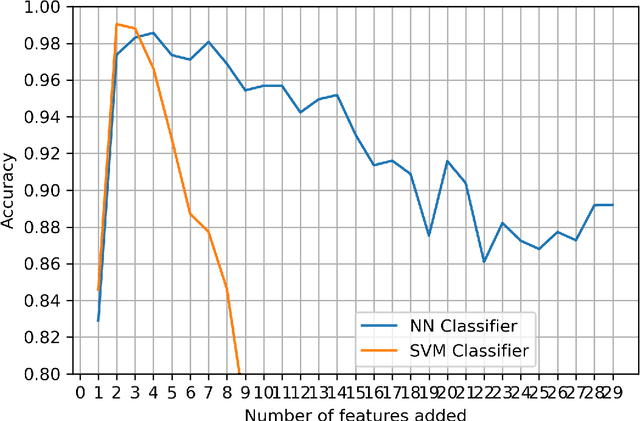
Kidney is an essential organ in human body. It maintains homeostasis and removes harmful substances through urine. Renal cell carcinoma (RCC) is the most common form of kidney cancer. Around 90\% of all kidney cancers are attributed to RCC. Most harmful type of RCC is clear cell renal cell carcinoma (ccRCC) that makes up about 80\% of all RCC cases. Early and accurate detection of ccRCC is necessary to prevent further spreading of the disease in other organs. In this article, a detailed experimentation is done to identify important features which can aid in diagnosing ccRCC at different stages. The ccRCC dataset is obtained from The Cancer Genome Atlas (TCGA). A novel mutual information and ensemble based feature ranking approach considering the order of features obtained from 8 popular feature selection methods is proposed. Performance of the proposed method is evaluated by overall classification accuracy obtained using 2 different classifiers (ANN and SVM). Experimental results show that the proposed feature ranking method is able to attain a higher accuracy (96.6\% and 98.6\% using SVM and NN, respectively) for classifying different stages of ccRCC with a reduced feature set as compared to existing work. It is also to be noted that, out of 3 distinguishing features as mentioned by the existing TNM system (proposed by AJCC and UICC), our proposed method was able to select two of them (size of tumour, metastasis status) as the top-most ones. This establishes the efficacy of our proposed approach.
Disentangled Speaker Representation Learning via Mutual Information Minimization
Aug 17, 2022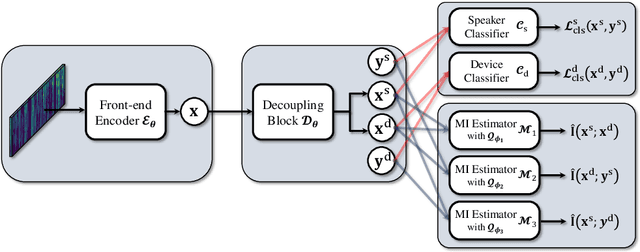
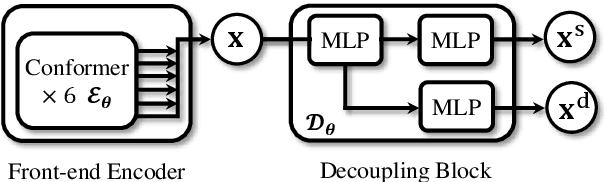
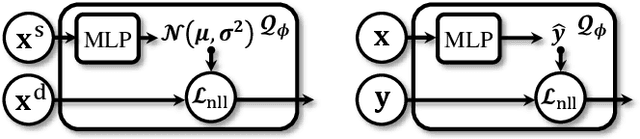
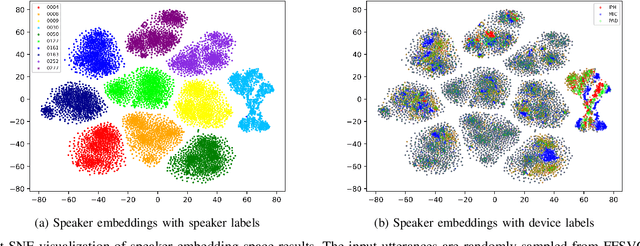
Domain mismatch problem caused by speaker-unrelated feature has been a major topic in speaker recognition. In this paper, we propose an explicit disentanglement framework to unravel speaker-relevant features from speaker-unrelated features via mutual information (MI) minimization. To achieve our goal of minimizing MI between speaker-related and speaker-unrelated features, we adopt a contrastive log-ratio upper bound (CLUB), which exploits the upper bound of MI. Our framework is constructed in a 3-stage structure. First, in the front-end encoder, input speech is encoded into shared initial embedding. Next, in the decoupling block, shared initial embedding is split into separate speaker-related and speaker-unrelated embeddings. Finally, disentanglement is conducted by MI minimization in the last stage. Experiments on Far-Field Speaker Verification Challenge 2022 (FFSVC2022) demonstrate that our proposed framework is effective for disentanglement. Also, to utilize domain-unknown datasets containing numerous speakers, we pre-trained the front-end encoder with VoxCeleb datasets. We then fine-tuned the speaker embedding model in the disentanglement framework with FFSVC 2022 dataset. The experimental results show that fine-tuning with a disentanglement framework on a existing pre-trained model is valid and can further improve performance.