 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AutoMatch: A Large-scale Audio Beat Matching Benchmark for Boosting Deep Learning Assistant Video Editing
Mar 03, 2023
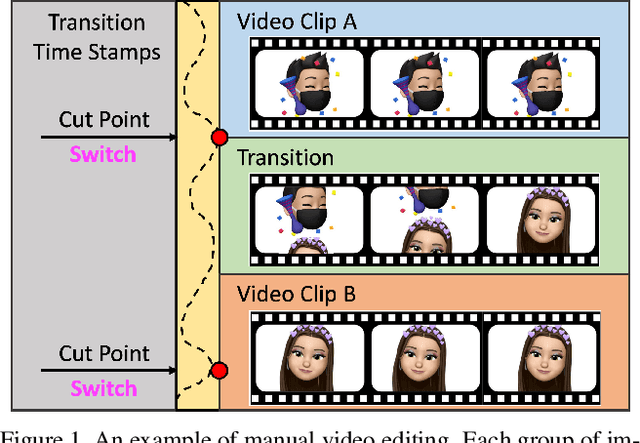
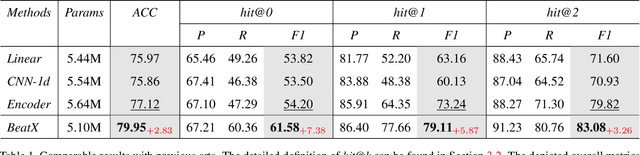
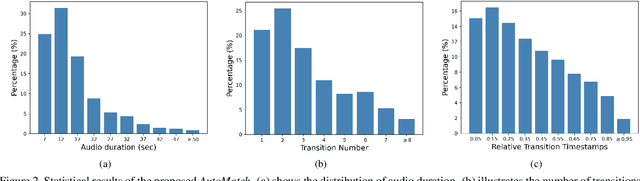
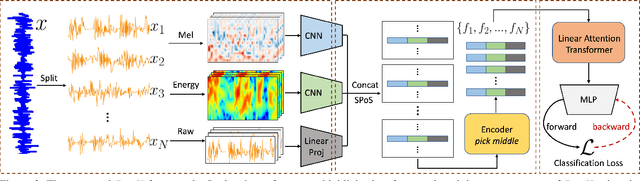
The explosion of short videos has dramatically reshaped the manners people socialize, yielding a new trend for daily sharing and access to the latest information. These rich video resources, on the one hand, benefited from the popularization of portable devices with cameras, but on the other, they can not be independent of the valuable editing work contributed by numerous video creators. In this paper, we investigate a novel and practical problem, namely audio beat matching (ABM), which aims to recommend the proper transition time stamps based on the background music. This technique helps to ease the labor-intensive work during video editing, saving energy for creators so that they can focus more on the creativity of video content. We formally define the ABM problem and its evaluation protocol. Meanwhile, a large-scale audio dataset, i.e., the AutoMatch with over 87k finely annotated background music, is presented to facilitate this newly opened research direction. To further lay solid foundations for the following study, we also propose a novel model termed BeatX to tackle this challenging task. Alongside, we creatively present the concept of label scope, which eliminates the data imbalance issues and assigns adaptive weights for the ground truth during the training procedure in one stop. Though plentiful short video platforms have flourished for a long time, the relevant research concerning this scenario is not sufficient, and to the best of our knowledge, AutoMatch is the first large-scale dataset to tackle the audio beat matching problem. We hope the released dataset and our competitive baseline can encourage more attention to this line of research. The dataset and codes will be made publicly available.
Multi-Plane Neural Radiance Fields for Novel View Synthesis
Mar 03, 2023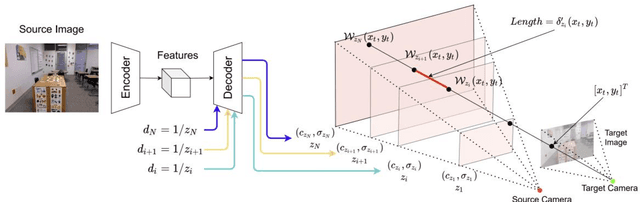
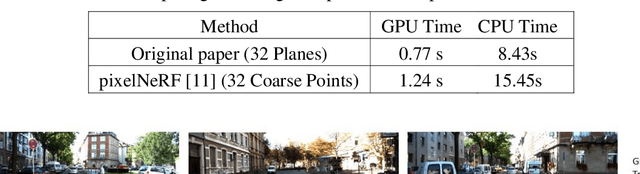
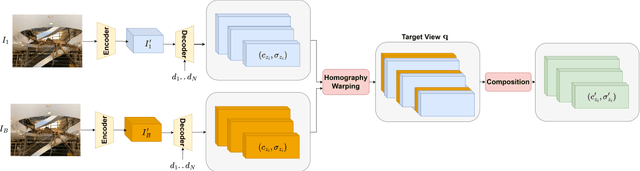
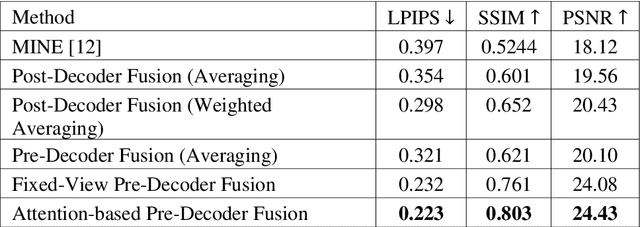
Novel view synthesis is a long-standing problem that revolves around rendering frames of scenes from novel camera viewpoints. Volumetric approaches provide a solution for modeling occlusions through the explicit 3D representation of the camera frustum. Multi-plane Images (MPI) are volumetric methods that represent the scene using front-parallel planes at distinct depths but suffer from depth discretization leading to a 2.D scene representation. Another line of approach relies on implicit 3D scene representations. Neural Radiance Fields (NeRF) utilize neural networks for encapsulating the continuous 3D scene structure within the network weights achieving photorealistic synthesis results, however, methods are constrained to per-scene optimization settings which are inefficient in practice. Multi-plane Neural Radiance Fields (MINE) open the door for combining implicit and explicit scene representations. It enables continuous 3D scene representations, especially in the depth dimension, while utilizing the input image features to avoid per-scene optimization. The main drawback of the current literature work in this domain is being constrained to single-view input, limiting the synthesis ability to narrow viewpoint ranges. In this work, we thoroughly examine the performance, generalization, and efficiency of single-view multi-plane neural radiance fields. In addition, we propose a new multiplane NeRF architecture that accepts multiple views to improve the synthesis results and expand the viewing range. Features from the input source frames are effectively fused through a proposed attention-aware fusion module to highlight important information from different viewpoints. Experiments show the effectiveness of attention-based fusion and the promising outcomes of our proposed method when compared to multi-view NeRF and MPI techniques.
Entity-Agnostic Representation Learning for Parameter-Efficient Knowledge Graph Embedding
Feb 03, 2023
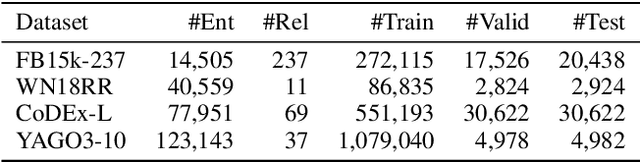
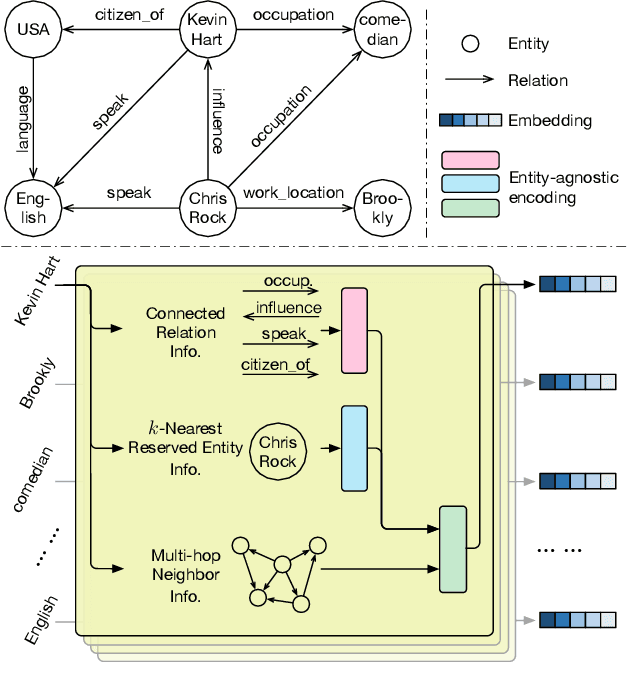
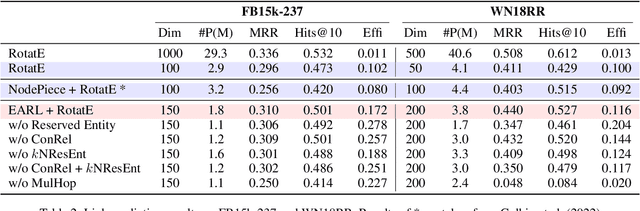
We propose an entity-agnostic representation learning method for handling the problem of inefficient parameter storage costs brought by embedding knowledge graphs. Conventional knowledge graph embedding methods map elements in a knowledge graph, including entities and relations, into continuous vector spaces by assigning them one or multiple specific embeddings (i.e., vector representations). Thus the number of embedding parameters increases linearly as the growth of knowledge graphs. In our proposed model, Entity-Agnostic Representation Learning (EARL), we only learn the embeddings for a small set of entities and refer to them as reserved entities. To obtain the embeddings for the full set of entities, we encode their distinguishable information from their connected relations, k-nearest reserved entities, and multi-hop neighbors. We learn universal and entity-agnostic encoders for transforming distinguishable information into entity embeddings. This approach allows our proposed EARL to have a static, efficient, and lower parameter count than conventional knowledge graph embedding methods. Experimental results show that EARL uses fewer parameters and performs better on link prediction tasks than baselines, reflecting its parameter efficiency.
Knowledge Distillation on Graphs: A Survey
Feb 01, 2023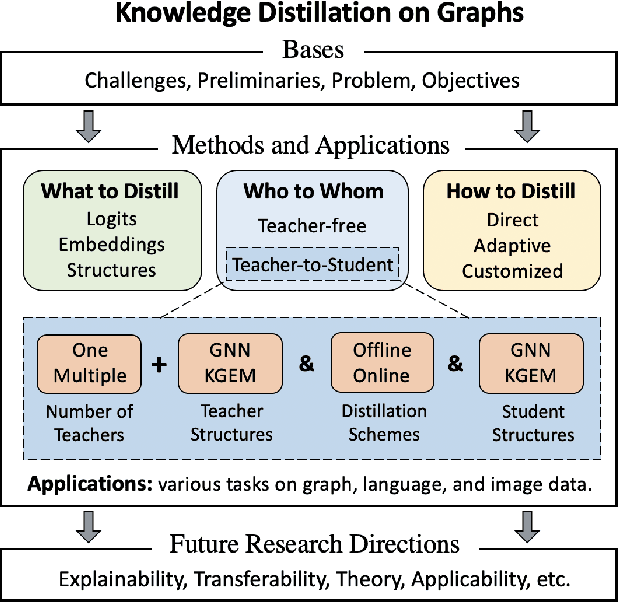
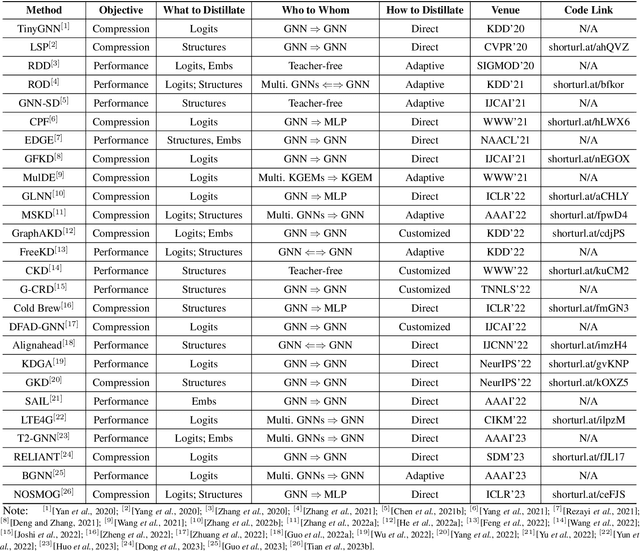
Graph Neural Networks (GNNs) have attracted tremendous attention by demonstrating their capability to handle graph data. However, they are difficult to be deployed in resource-limited devices due to model sizes and scalability constraints imposed by the multi-hop data dependency. In addition, real-world graphs usually possess complex structural information and features. Therefore, to improve the applicability of GNNs and fully encode the complicated topological information, knowledge distillation on graphs (KDG) has been introduced to build a smaller yet effective model and exploit more knowledge from data, leading to model compression and performance improvement. Recently, KDG has achieved considerable progress with many studies proposed. In this survey, we systematically review these works. Specifically, we first introduce KDG challenges and bases, then categorize and summarize existing works of KDG by answering the following three questions: 1) what to distillate, 2) who to whom, and 3) how to distillate. Finally, we share our thoughts on future research directions.
DANES: Deep Neural Network Ensemble Architecture for Social and Textual Context-aware Fake News Detection
Feb 01, 2023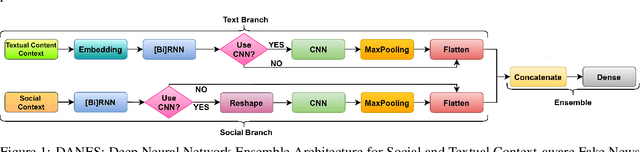
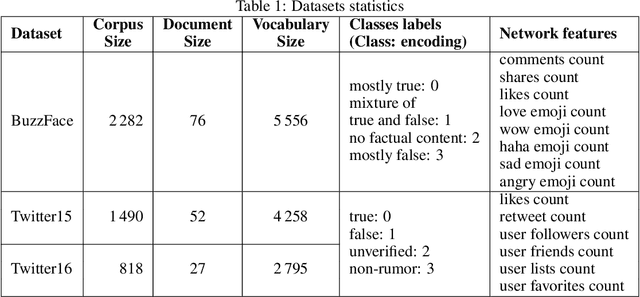
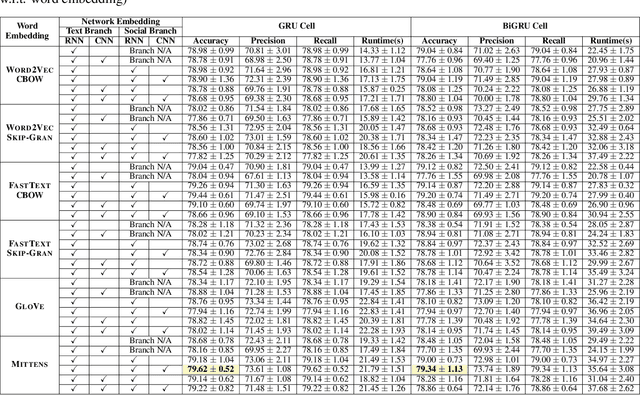
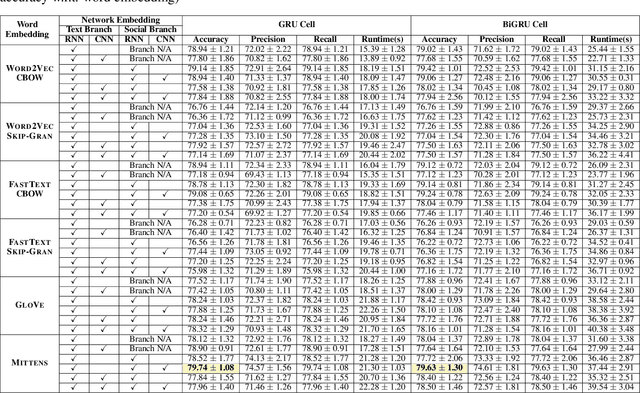
The growing popularity of social media platforms has simplified the creation and distribution of news articles but also creates a conduit for spreading fake news. In consequence, the need arises for effective context-aware fake news detection mechanisms, where the contextual information can be built either from the textual content of posts or from available social data (e.g., information about the users, reactions to posts, or the social network). In this paper, we propose DANES, a Deep Neural Network Ensemble Architecture for Social and Textual Context-aware Fake News Detection. DANES comprises a Text Branch for a textual content-based context and a Social Branch for the social context. These two branches are used to create a novel Network Embedding. Preliminary ablation results on 3 real-world datasets, i.e., BuzzFace, Twitter15, and Twitter16, are promising, with an accuracy that outperforms state-of-the-art solutions when employing both social and textual content features.
Coarse-to-fine Hybrid 3D Mapping System with Co-calibrated Omnidirectional Camera and Non-repetitive LiDAR
Feb 08, 2023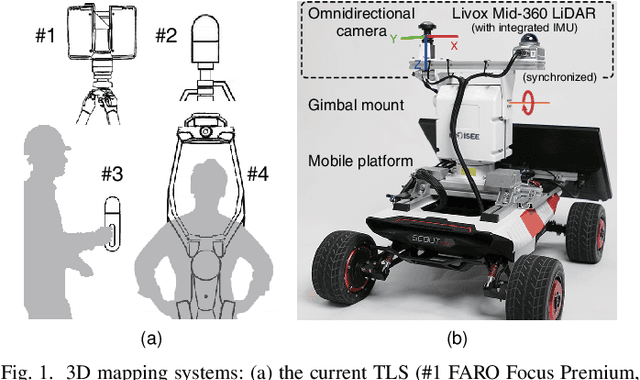

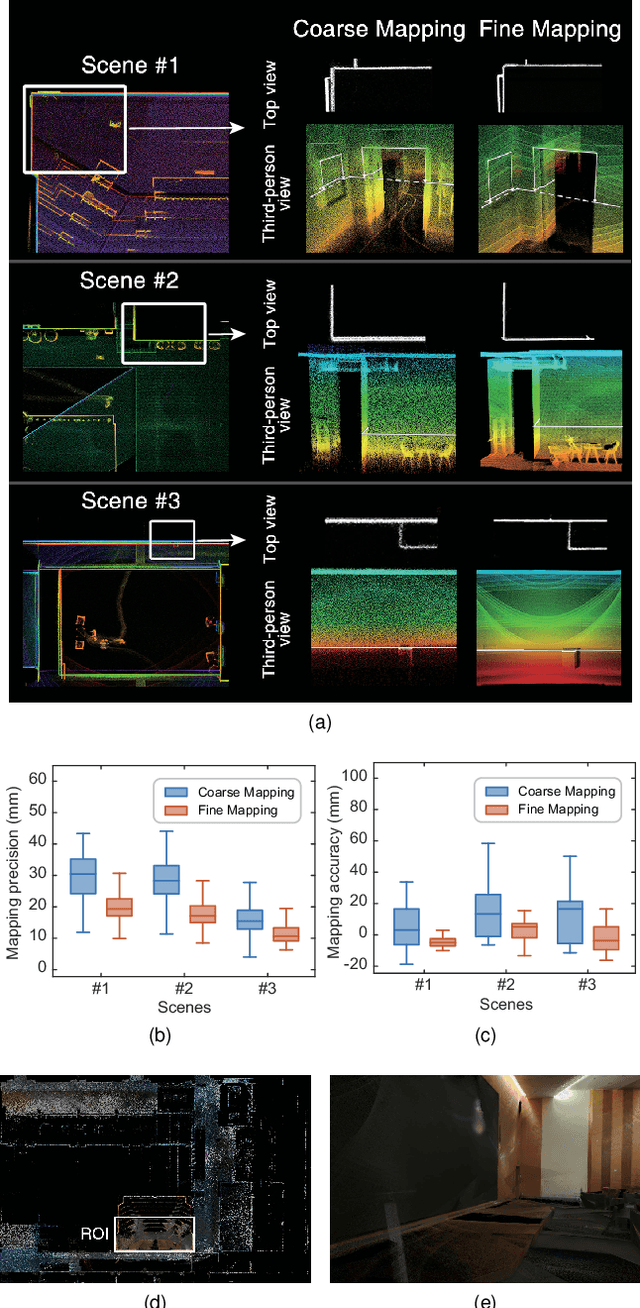
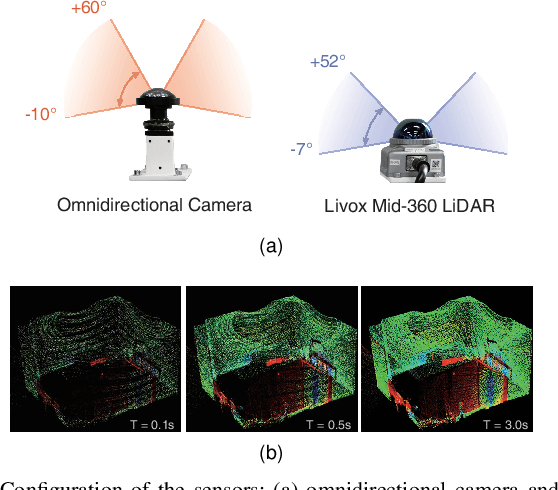
This paper presents a novel 3D mapping robot with an omnidirectional field-of-view (FoV) sensor suite composed of a non-repetitive LiDAR and an omnidirectional camera. Thanks to the non-repetitive scanning nature of the LiDAR, an automatic targetless co-calibration method is proposed to simultaneously calibrate the intrinsic parameters for the omnidirectional camera and the extrinsic parameters for the camera and LiDAR, which is crucial for the required step in bringing color and texture information to the point clouds in surveying and mapping tasks. Comparisons and analyses are made to target-based intrinsic calibration and mutual information (MI)-based extrinsic calibration, respectively. With this co-calibrated sensor suite, the hybrid mapping robot integrates both the odometry-based mapping mode and stationary mapping mode. Meanwhile, we proposed a new workflow to achieve coarse-to-fine mapping, including efficient and coarse mapping in a global environment with odometry-based mapping mode; planning for viewpoints in the region-of-interest (ROI) based on the coarse map (relies on the previous work); navigating to each viewpoint and performing finer and more precise stationary scanning and mapping of the ROI. The fine map is stitched with the global coarse map, which provides a more efficient and precise result than the conventional stationary approaches and the emerging odometry-based approaches, respectively.
Adapting Pre-trained Vision Transformers from 2D to 3D through Weight Inflation Improves Medical Image Segmentation
Feb 08, 2023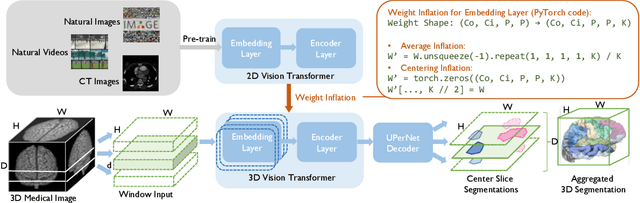
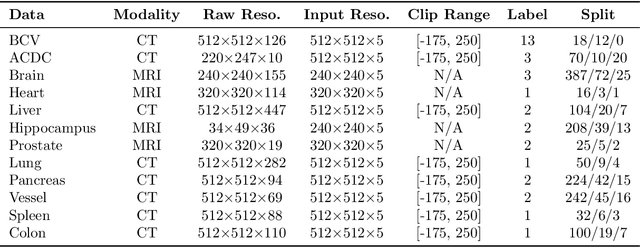
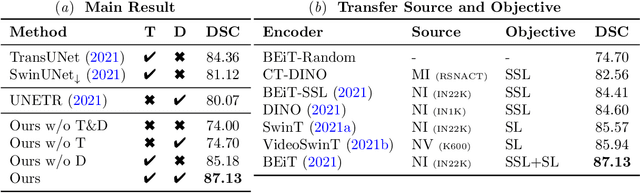
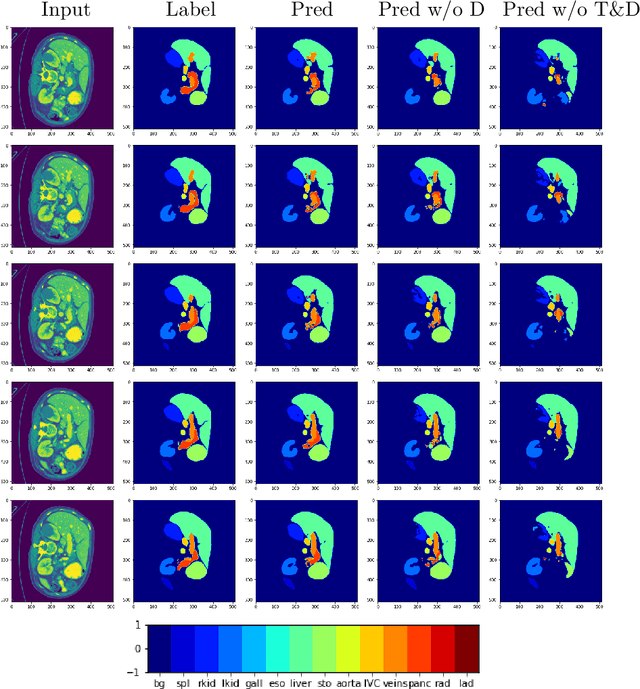
Given the prevalence of 3D medical imaging technologies such as MRI and CT that are widely used in diagnosing and treating diverse diseases, 3D segmentation is one of the fundamental tasks of medical image analysis. Recently, Transformer-based models have started to achieve state-of-the-art performances across many vision tasks, through pre-training on large-scale natural image benchmark datasets. While works on medical image analysis have also begun to explore Transformer-based models, there is currently no optimal strategy to effectively leverage pre-trained Transformers, primarily due to the difference in dimensionality between 2D natural images and 3D medical images. Existing solutions either split 3D images into 2D slices and predict each slice independently, thereby losing crucial depth-wise information, or modify the Transformer architecture to support 3D inputs without leveraging pre-trained weights. In this work, we use a simple yet effective weight inflation strategy to adapt pre-trained Transformers from 2D to 3D, retaining the benefit of both transfer learning and depth information. We further investigate the effectiveness of transfer from different pre-training sources and objectives. Our approach achieves state-of-the-art performances across a broad range of 3D medical image datasets, and can become a standard strategy easily utilized by all work on Transformer-based models for 3D medical images, to maximize performance.
A Parametric Similarity Method: Comparative Experiments based on Semantically Annotated Large Datasets
Feb 08, 2023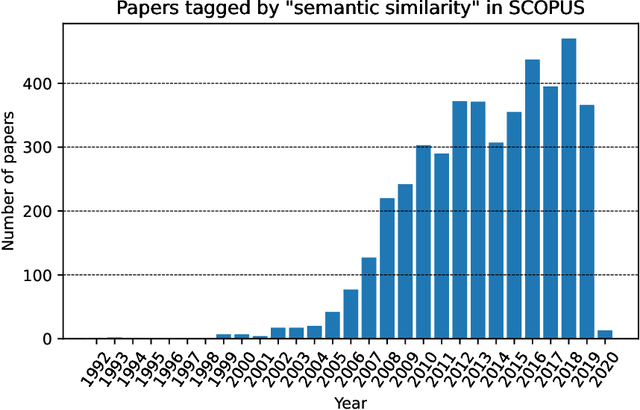

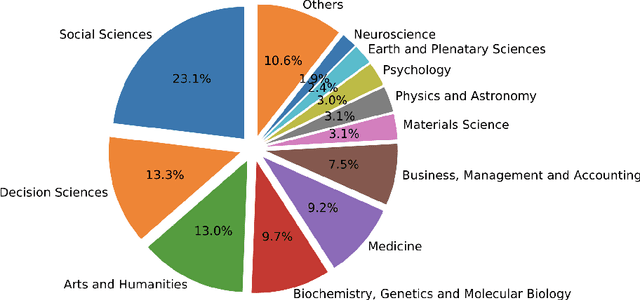

We present the parametric method SemSimp aimed at measuring semantic similarity of digital resources. SemSimp is based on the notion of information content, and it leverages a reference ontology and taxonomic reasoning, encompassing different approaches for weighting the concepts of the ontology. In particular, weights can be computed by considering either the available digital resources or the structure of the reference ontology of a given domain. SemSimp is assessed against six representative semantic similarity methods for comparing sets of concepts proposed in the literature, by carrying out an experimentation that includes both a statistical analysis and an expert judgement evaluation. To the purpose of achieving a reliable assessment, we used a real-world large dataset based on the Digital Library of the Association for Computing Machinery (ACM), and a reference ontology derived from the ACM Computing Classification System (ACM-CCS). For each method, we considered two indicators. The first concerns the degree of confidence to identify the similarity among the papers belonging to some special issues selected from the ACM Transactions on Information Systems journal, the second the Pearson correlation with human judgement. The results reveal that one of the configurations of SemSimp outperforms the other assessed methods. An additional experiment performed in the domain of physics shows that, in general, SemSimp provides better results than the other similarity methods.
* 32 pages, 9 figures, 11 tables
BERT-ERC: Fine-tuning BERT is Enough for Emotion Recognition in Conversation
Jan 17, 2023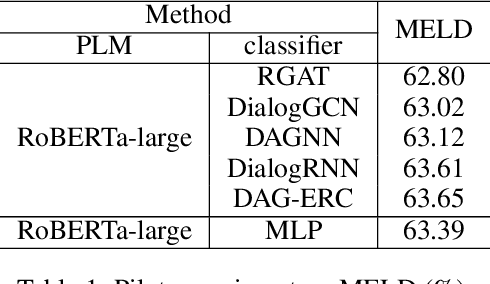
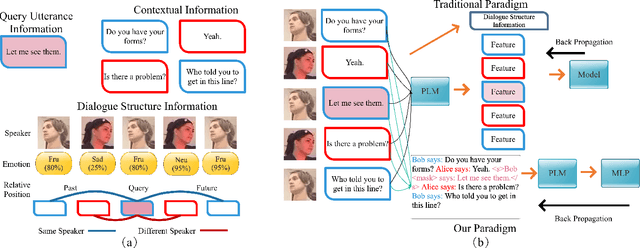
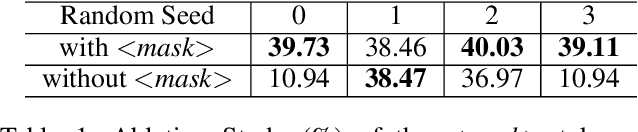
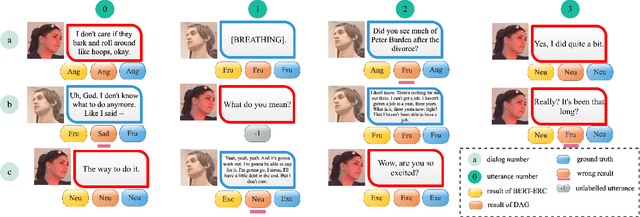
Previous works on emotion recognition in conversation (ERC) follow a two-step paradigm, which can be summarized as first producing context-independent features via fine-tuning pretrained language models (PLMs) and then analyzing contextual information and dialogue structure information among the extracted features. However, we discover that this paradigm has several limitations. Accordingly, we propose a novel paradigm, i.e., exploring contextual information and dialogue structure information in the fine-tuning step, and adapting the PLM to the ERC task in terms of input text, classification structure, and training strategy. Furthermore, we develop our model BERT-ERC according to the proposed paradigm, which improves ERC performance in three aspects, namely suggestive text, fine-grained classification module, and two-stage training. Compared to existing methods, BERT-ERC achieves substantial improvement on four datasets, indicating its effectiveness and generalization capability. Besides, we also set up the limited resources scenario and the online prediction scenario to approximate real-world scenarios. Extensive experiments demonstrate that the proposed paradigm significantly outperforms the previous one and can be adapted to various scenes.
ASDF: A Differential Testing Framework for Automatic Speech Recognition Systems
Feb 11, 2023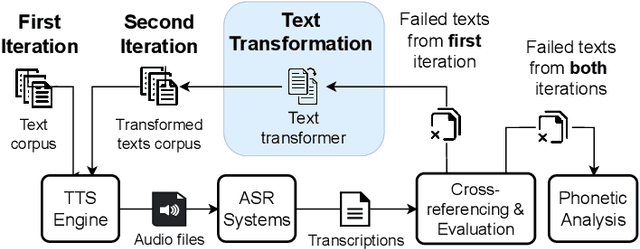
Recent years have witnessed wider adoption of Automated Speech Recognition (ASR) techniques in various domains. Consequently, evaluating and enhancing the quality of ASR systems is of great importance. This paper proposes ASDF, an Automated Speech Recognition Differential Testing Framework for testing ASR systems. ASDF extends an existing ASR testing tool, the CrossASR++, which synthesizes test cases from a text corpus. However, CrossASR++ fails to make use of the text corpus efficiently and provides limited information on how the failed test cases can improve ASR systems. To address these limitations, our tool incorporates two novel features: (1) a text transformation module to boost the number of generated test cases and uncover more errors in ASR systems and (2) a phonetic analysis module to identify on which phonemes the ASR system tend to produce errors. ASDF generates more high-quality test cases by applying various text transformation methods (e.g., change tense) to the texts in failed test cases. By doing so, ASDF can utilize a small text corpus to generate a large number of audio test cases, something which CrossASR++ is not capable of. In addition, ASDF implements more metrics to evaluate the performance of ASR systems from multiple perspectives. ASDF performs phonetic analysis on the identified failed test cases to identify the phonemes that ASR systems tend to transcribe incorrectly, providing useful information for developers to improve ASR systems. The demonstration video of our tool is made online at https://www.youtube.com/watch?v=DzVwfc3h9As. The implementation is available at https://github.com/danielyuenhx/asdf-differential-testing.