 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Uncertainty Calibration and its Application to Object Detection
Feb 06, 2023

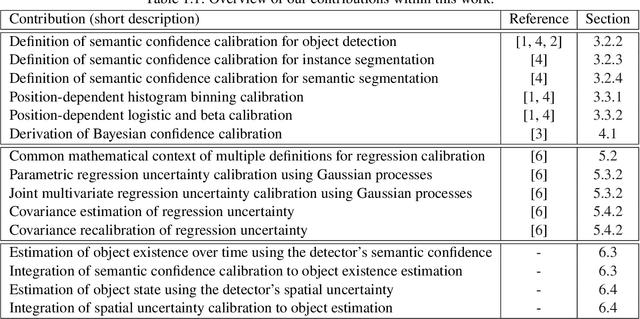
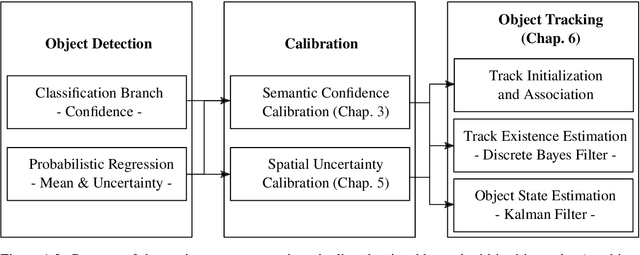
Image-based environment perception is an important component especially for driver assistance systems or autonomous driving. In this scope, modern neuronal networks are used to identify multiple objects as well as the according position and size information within a single frame. The performance of such an object detection model is important for the overall performance of the whole system. However, a detection model might also predict these objects under a certain degree of uncertainty. [...] In this work, we examine the semantic uncertainty (which object type?) as well as the spatial uncertainty (where is the object and how large is it?). We evaluate if the predicted uncertainties of an object detection model match with the observed error that is achieved on real-world data. In the first part of this work, we introduce the definition for confidence calibration of the semantic uncertainty in the context of object detection, instance segmentation, and semantic segmentation. We integrate additional position information in our examinations to evaluate the effect of the object's position on the semantic calibration properties. Besides measuring calibration, it is also possible to perform a post-hoc recalibration of semantic uncertainty that might have turned out to be miscalibrated. [...] The second part of this work deals with the spatial uncertainty obtained by a probabilistic detection model. [...] We review and extend common calibration methods so that it is possible to obtain parametric uncertainty distributions for the position information in a more flexible way. In the last part, we demonstrate a possible use-case for our derived calibration methods in the context of object tracking. [...] We integrate our previously proposed calibration techniques and demonstrate the usefulness of semantic and spatial uncertainty calibration in a subsequent process. [...]
Autodecompose: A generative self-supervised model for semantic decomposition
Feb 06, 2023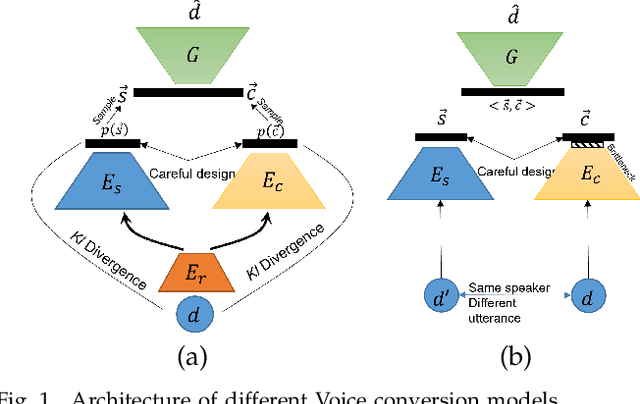

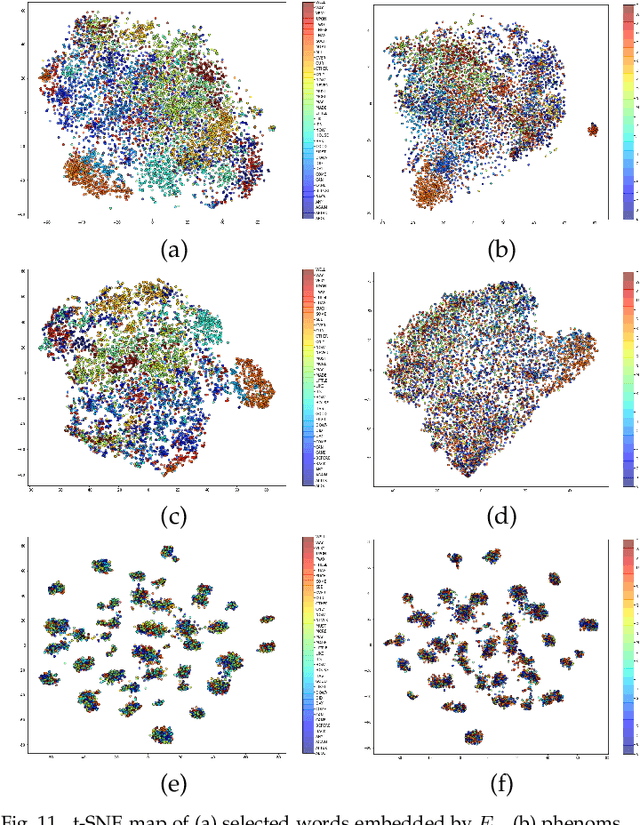
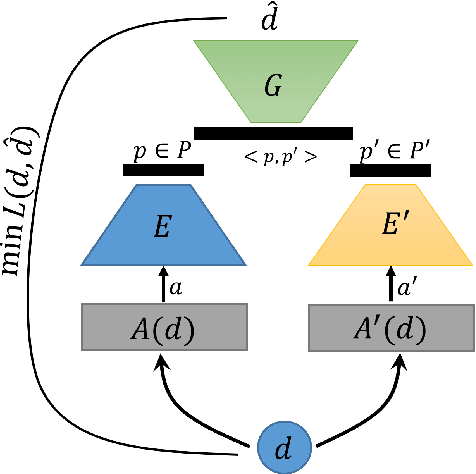
We introduce Autodecompose, a novel self-supervised generative model that decomposes data into two semantically independent properties: the desired property, which captures a specific aspect of the data (e.g. the voice in an audio signal), and the context property, which aggregates all other information (e.g. the content of the audio signal), without any labels given. Autodecompose uses two complementary augmentations, one that manipulates the context while preserving the desired property and the other that manipulates the desired property while preserving the context. The augmented variants of the data are encoded by two encoders and reconstructed by a decoder. We prove that one of the encoders embeds the desired property while the other embeds the context property. We apply Autodecompose to audio signals to encode sound source (human voice) and content. We pre-trained the model on YouTube and LibriSpeech datasets and fine-tuned in a self-supervised manner without exposing the labels. Our results showed that, using the sound source encoder of pre-trained Autodecompose, a linear classifier achieves F1 score of 97.6\% in recognizing the voice of 30 speakers using only 10 seconds of labeled samples, compared to 95.7\% for supervised models. Additionally, our experiments showed that Autodecompose is robust against overfitting even when a large model is pre-trained on a small dataset. A large Autodecompose model was pre-trained from scratch on 60 seconds of audio from 3 speakers achieved over 98.5\% F1 score in recognizing those three speakers in other unseen utterances. We finally show that the context encoder embeds information about the content of the speech and ignores the sound source information. Our sample code for training the model, as well as examples for using the pre-trained models are available here: \url{https://github.com/rezabonyadi/autodecompose}
Cluster-aware Contrastive Learning for Unsupervised Out-of-distribution Detection
Feb 06, 2023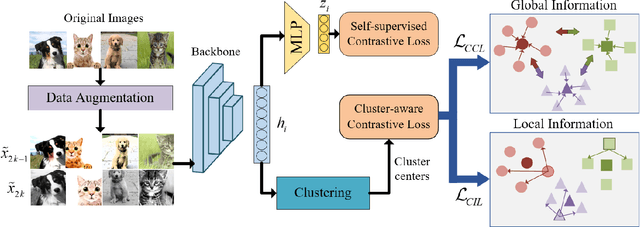
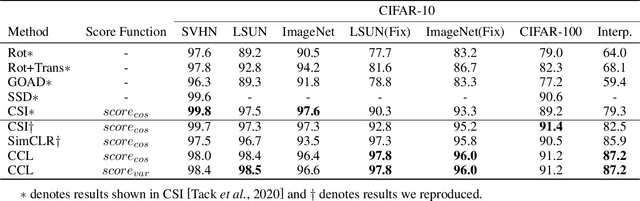
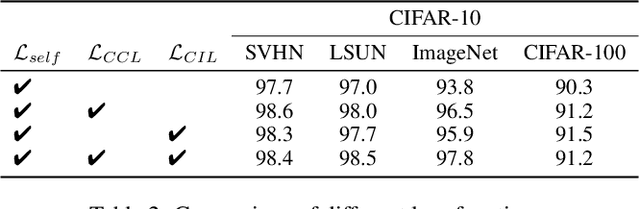
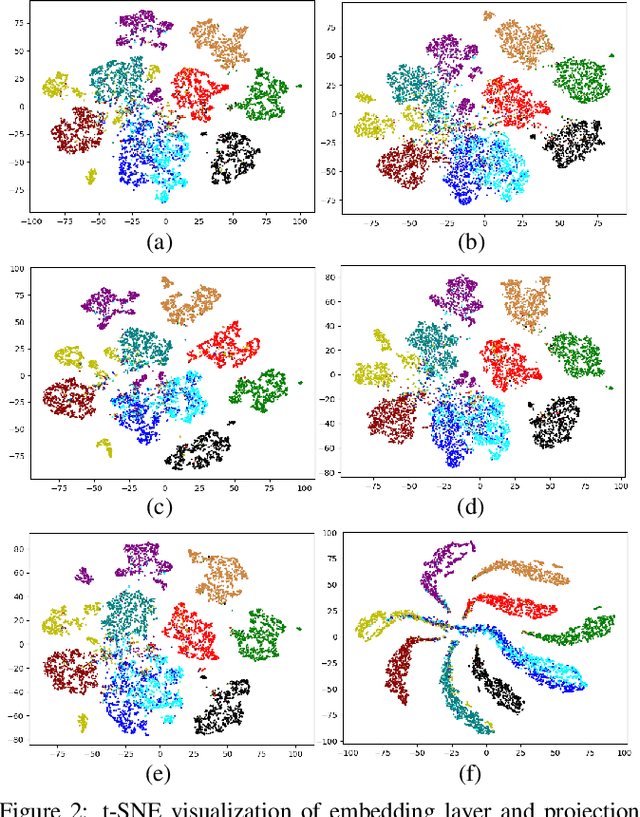
Unsupervised out-of-distribution (OOD) Detection aims to separate the samples falling outside the distribution of training data without label information. Among numerous branches, contrastive learning has shown its excellent capability of learning discriminative representation in OOD detection. However, for its limited vision, merely focusing on instance-level relationship between augmented samples, it lacks attention to the relationship between samples with same semantics. Based on the classic contrastive learning, we propose Cluster-aware Contrastive Learning (CCL) framework for unsupervised OOD detection, which considers both instance-level and semantic-level information. Specifically, we study a cooperation strategy of clustering and contrastive learning to effectively extract the latent semantics and design a cluster-aware contrastive loss function to enhance OOD discriminative ability. The loss function can simultaneously pay attention to the global and local relationships by treating both the cluster centers and the samples belonging to the same cluster as positive samples. We conducted sufficient experiments to verify the effectiveness of our framework and the model achieves significant improvement on various image benchmarks.
ContCommRTD: A Distributed Content-based Misinformation-aware Community Detection System for Real-Time Disaster Reporting
Jan 30, 2023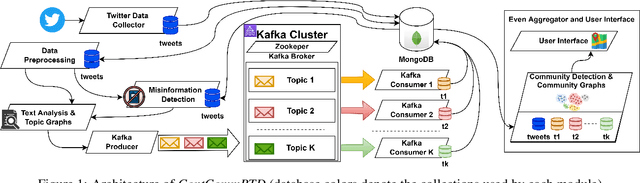
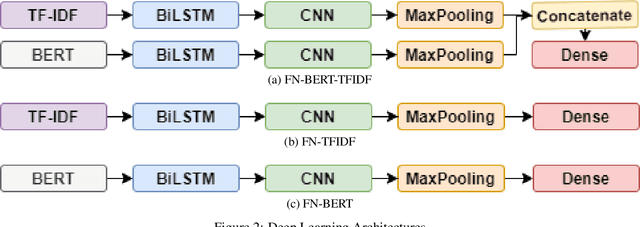
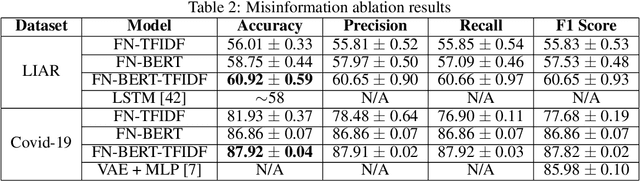
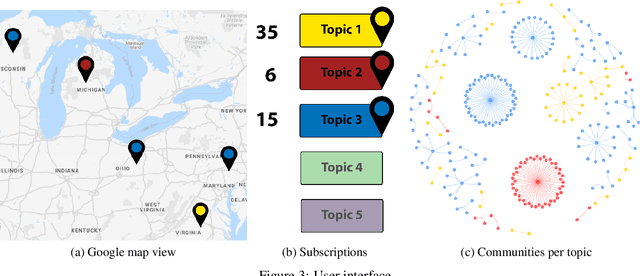
Real-time social media data can provide useful information on evolving hazards. Alongside traditional methods of disaster detection, the integration of social media data can considerably enhance disaster management. In this paper, we investigate the problem of detecting geolocation-content communities on Twitter and propose a novel distributed system that provides in near real-time information on hazard-related events and their evolution. We show that content-based community analysis leads to better and faster dissemination of reports on hazards. Our distributed disaster reporting system analyzes the social relationship among worldwide geolocated tweets, and applies topic modeling to group tweets by topics. Considering for each tweet the following information: user, timestamp, geolocation, retweets, and replies, we create a publisher-subscriber distribution model for topics. We use content similarity and the proximity of nodes to create a new model for geolocation-content based communities. Users can subscribe to different topics in specific geographical areas or worldwide and receive real-time reports regarding these topics. As misinformation can lead to increase damage if propagated in hazards related tweets, we propose a new deep learning model to detect fake news. The misinformed tweets are then removed from display. We also show empirically the scalability capabilities of the proposed system.
Vision, Deduction and Alignment: An Empirical Study on Multi-modal Knowledge Graph Alignment
Feb 17, 2023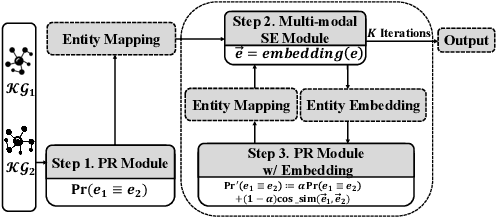
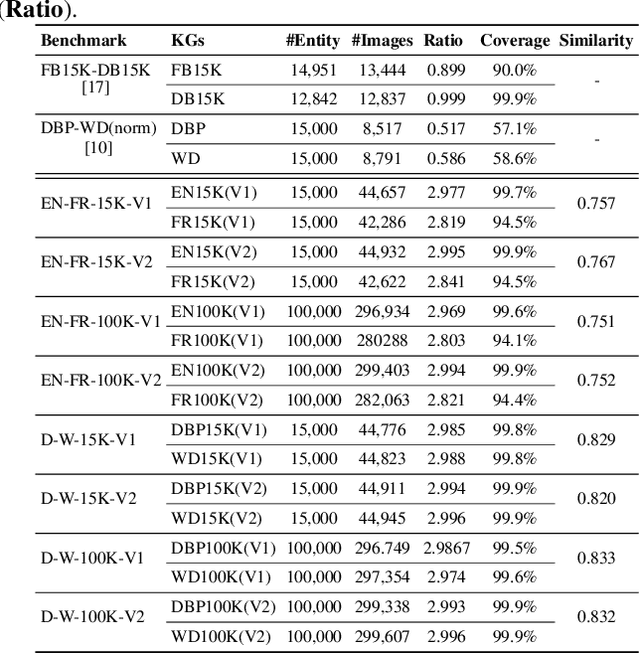
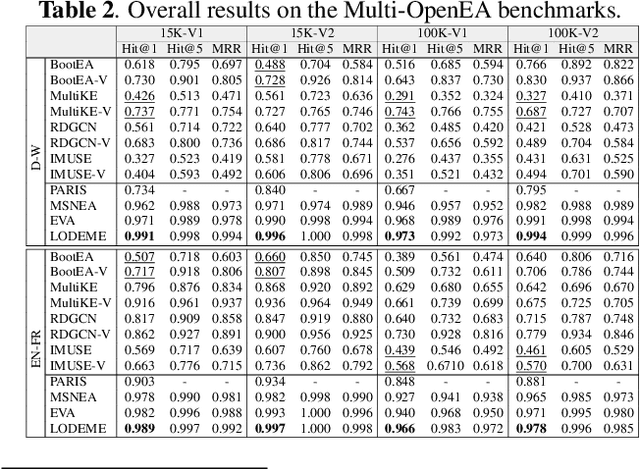
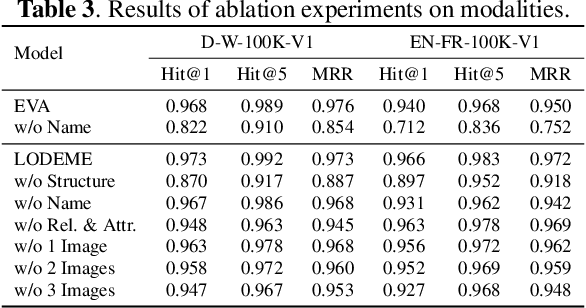
Entity alignment (EA) for knowledge graphs (KGs) plays a critical role in knowledge engineering. Existing EA methods mostly focus on utilizing the graph structures and entity attributes (including literals), but ignore images that are common in modern multi-modal KGs. In this study we first constructed Multi-OpenEA -- eight large-scale, image-equipped EA benchmarks, and then evaluated some existing embedding-based methods for utilizing images. In view of the complementary nature of visual modal information and logical deduction, we further developed a new multi-modal EA method named LODEME using logical deduction and multi-modal KG embedding, with state-of-the-art performance achieved on Multi-OpenEA and other existing multi-modal EA benchmarks.
Vertical Federated Knowledge Transfer via Representation Distillation for Healthcare Collaboration Networks
Feb 11, 2023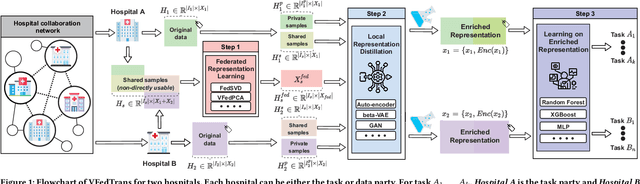
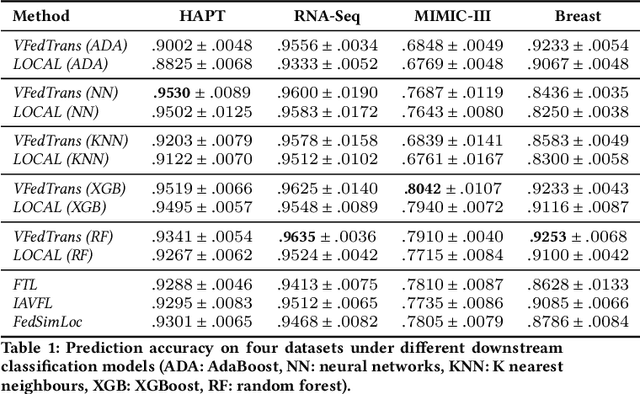
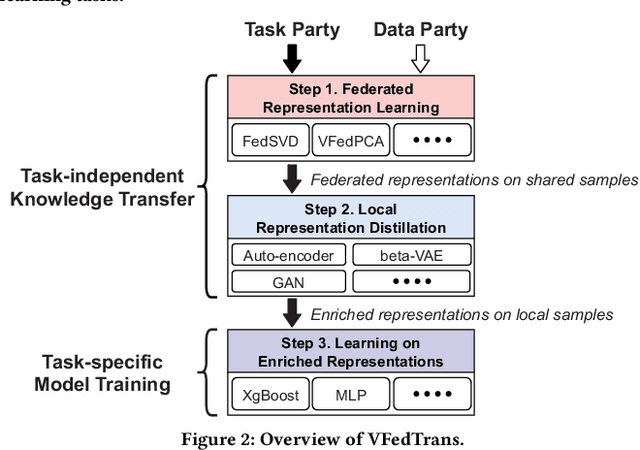
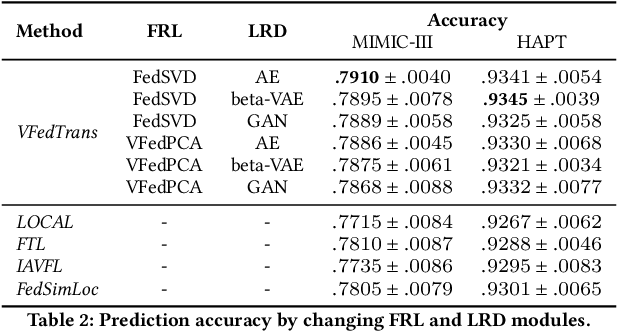
Collaboration between healthcare institutions can significantly lessen the imbalance in medical resources across various geographic areas. However, directly sharing diagnostic information between institutions is typically not permitted due to the protection of patients' highly sensitive privacy. As a novel privacy-preserving machine learning paradigm, federated learning (FL) makes it possible to maximize the data utility among multiple medical institutions. These feature-enrichment FL techniques are referred to as vertical FL (VFL). Traditional VFL can only benefit multi-parties' shared samples, which strongly restricts its application scope. In order to improve the information-sharing capability and innovation of various healthcare-related institutions, and then to establish a next-generation open medical collaboration network, we propose a unified framework for vertical federated knowledge transfer mechanism (VFedTrans) based on a novel cross-hospital representation distillation component. Specifically, our framework includes three steps. First, shared samples' federated representations are extracted by collaboratively modeling multi-parties' joint features with current efficient vertical federated representation learning methods. Second, for each hospital, we learn a local-representation-distilled module, which can transfer the knowledge from shared samples' federated representations to enrich local samples' representations. Finally, each hospital can leverage local samples' representations enriched by the distillation module to boost arbitrary downstream machine learning tasks. The experiments on real-life medical datasets verify the knowledge transfer effectiveness of our framework.
DeepfakeMAE: Facial Part Consistency Aware Masked Autoencoder for Deepfake Video Detection
Mar 03, 2023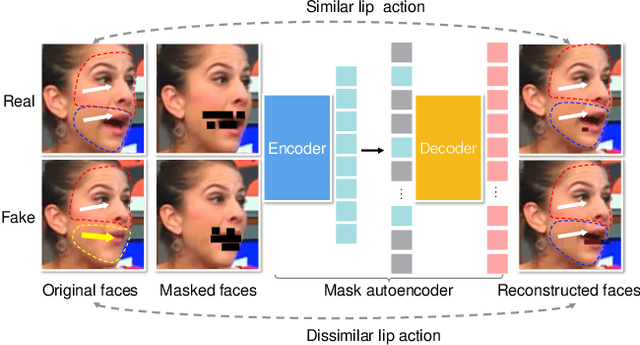
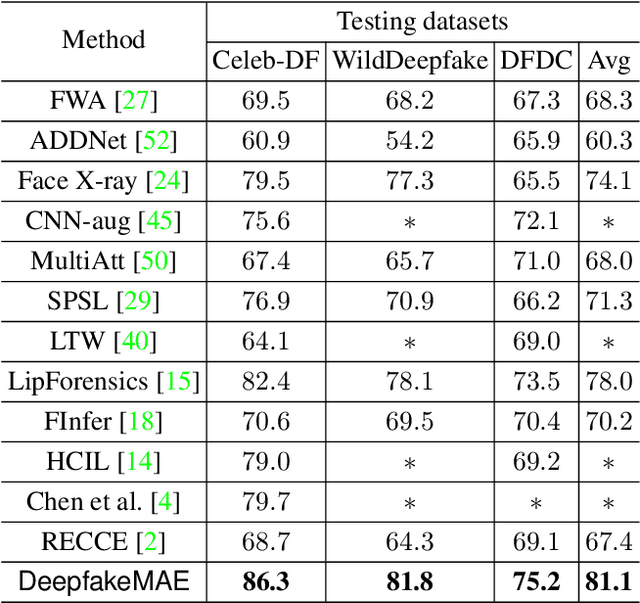
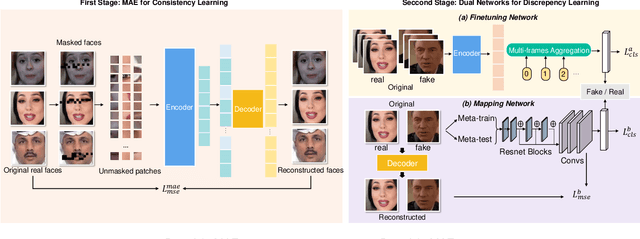
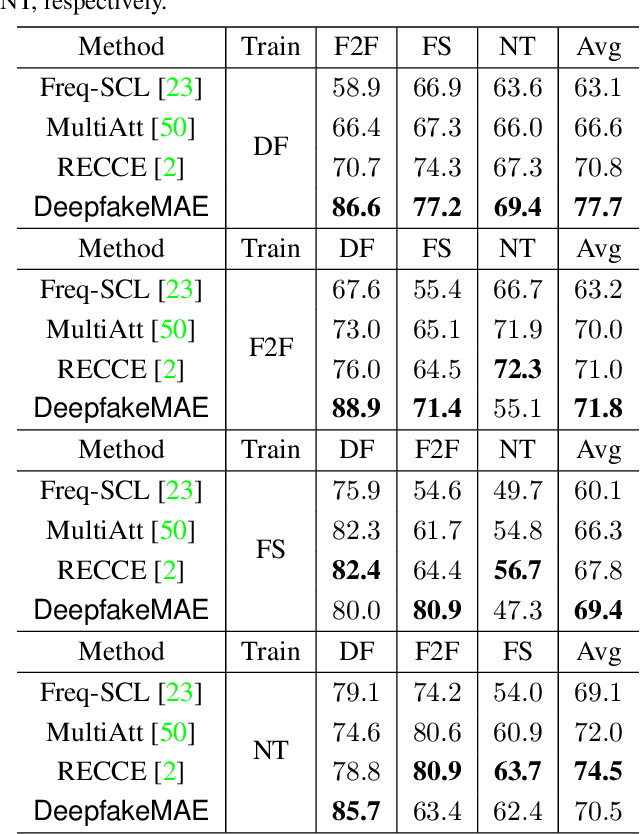
Deepfake techniques have been used maliciously, resulting in strong research interests in developing Deepfake detection methods. Deepfake often manipulates the video content by tampering with some facial parts. However, this manipulation usually breaks the consistency among facial parts, e.g., Deepfake may change smiling lips to upset, but the eyes are still smiling. Existing works propose to spot inconsistency on some specific facial parts (e.g., lips), but they may perform poorly if new Deepfake techniques focus on the specific facial parts used by the detector. Thus, this paper proposes a new Deepfake detection model, DeepfakeMAE, which can utilize the consistencies among all facial parts. Specifically, given a real face image, we first pretrain a masked autoencoder to learn facial part consistency by randomly masking some facial parts and reconstructing missing areas based on the remaining facial parts. Furthermore, to maximize the discrepancy between real and fake videos, we propose a novel model with dual networks that utilize the pretrained encoder and decoder, respectively. 1) The pretrained encoder is finetuned for capturing the overall information of the given video. 2) The pretrained decoder is utilized for distinguishing real and fake videos based on the motivation that DeepfakeMAE's reconstruction should be more similar to a real face image than a fake one. Our extensive experiments on standard benchmarks demonstrate that DeepfakeMAE is highly effective and especially outperforms the previous state-of-the-art method by 3.1% AUC on average in cross-dataset detection.
BSH-Det3D: Improving 3D Object Detection with BEV Shape Heatmap
Mar 03, 2023
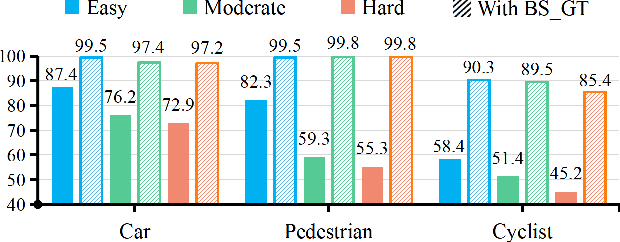
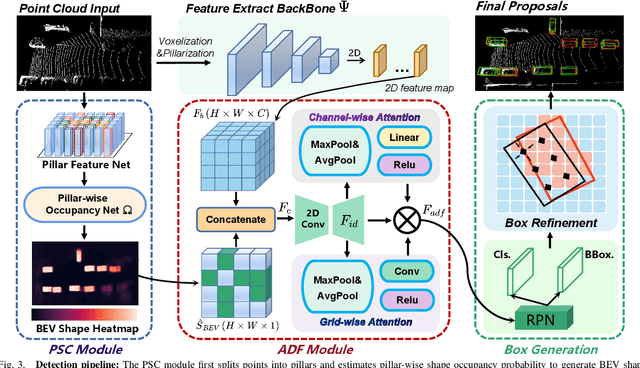
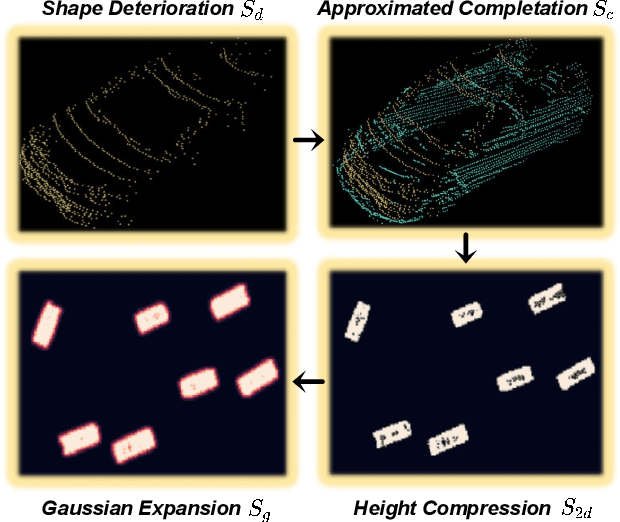
The progress of LiDAR-based 3D object detection has significantly enhanced developments in autonomous driving and robotics. However, due to the limitations of LiDAR sensors, object shapes suffer from deterioration in occluded and distant areas, which creates a fundamental challenge to 3D perception. Existing methods estimate specific 3D shapes and achieve remarkable performance. However, these methods rely on extensive computation and memory, causing imbalances between accuracy and real-time performance. To tackle this challenge, we propose a novel LiDAR-based 3D object detection model named BSH-Det3D, which applies an effective way to enhance spatial features by estimating complete shapes from a bird's eye view (BEV). Specifically, we design the Pillar-based Shape Completion (PSC) module to predict the probability of occupancy whether a pillar contains object shapes. The PSC module generates a BEV shape heatmap for each scene. After integrating with heatmaps, BSH-Det3D can provide additional information in shape deterioration areas and generate high-quality 3D proposals. We also design an attention-based densification fusion module (ADF) to adaptively associate the sparse features with heatmaps and raw points. The ADF module integrates the advantages of points and shapes knowledge with negligible overheads. Extensive experiments on the KITTI benchmark achieve state-of-the-art (SOTA) performance in terms of accuracy and speed, demonstrating the efficiency and flexibility of BSH-Det3D. The source code is available on https://github.com/mystorm16/BSH-Det3D.
A Unified BEV Model for Joint Learning of 3D Local Features and Overlap Estimation
Feb 28, 2023
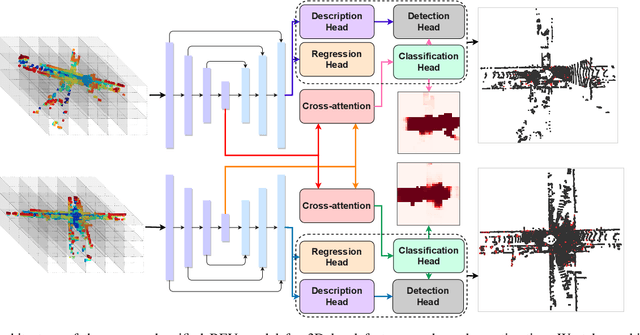
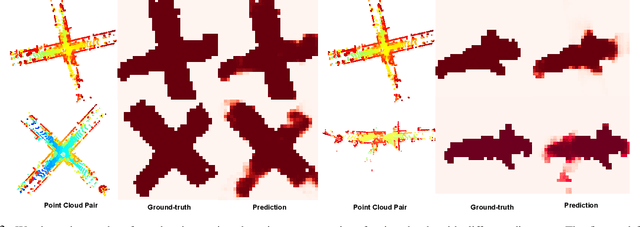
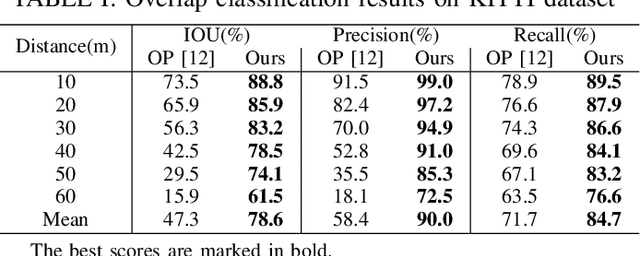
Pairwise point cloud registration is a critical task for many applications, which heavily depends on finding the right correspondences from the two point clouds. However, the low overlap between the input point clouds makes the registration prone to fail, leading to mistaken overlapping and mismatched correspondences, especially in scenes where non-overlapping regions contain similar structures. In this paper, we present a unified bird's-eye view (BEV) model for jointly learning of 3D local features and overlap estimation to fulfill the pairwise registration and loop closure. Feature description based on BEV representation is performed by a sparse UNet-like network, and the 3D keypoints are extracted by a detection head for 2D locations and a regression head for heights, respectively. For overlap detection, a cross-attention module is applied for interacting contextual information of the input point clouds, followed by a classification head to estimate the overlapping region. We evaluate our unified model extensively on the KITTI dataset and Apollo-SouthBay dataset. The experiments demonstrate that our method significantly outperforms existing methods on overlap prediction, especially in scenes with small overlaps. The registration precision also achieves top performance on both datasets in terms of translation and rotation errors. Source codes will be available soon.
DC-Former: Diverse and Compact Transformer for Person Re-Identification
Feb 28, 2023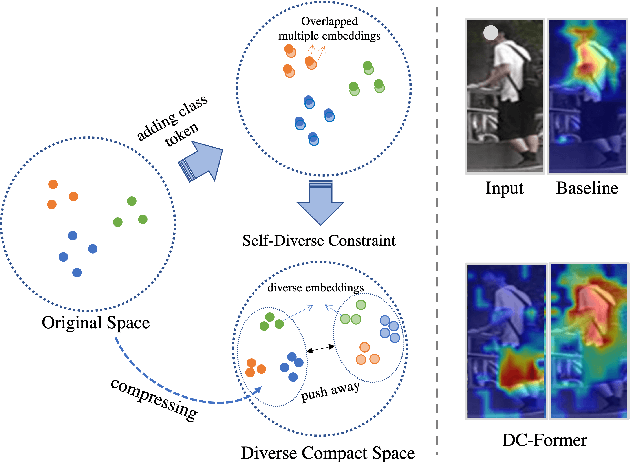
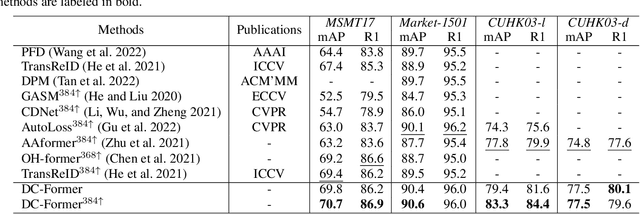
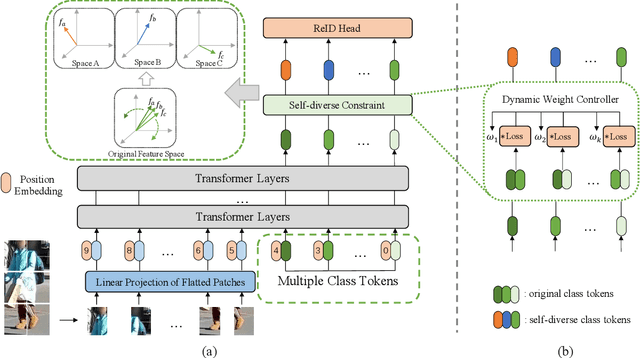
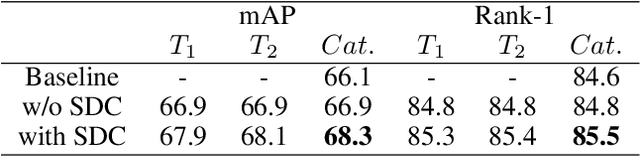
In person re-identification (re-ID) task, it is still challenging to learn discriminative representation by deep learning, due to limited data. Generally speaking, the model will get better performance when increasing the amount of data. The addition of similar classes strengthens the ability of the classifier to identify similar identities, thereby improving the discrimination of representation. In this paper, we propose a Diverse and Compact Transformer (DC-Former) that can achieve a similar effect by splitting embedding space into multiple diverse and compact subspaces. Compact embedding subspace helps model learn more robust and discriminative embedding to identify similar classes. And the fusion of these diverse embeddings containing more fine-grained information can further improve the effect of re-ID. Specifically, multiple class tokens are used in vision transformer to represent multiple embedding spaces. Then, a self-diverse constraint (SDC) is applied to these spaces to push them away from each other, which makes each embedding space diverse and compact. Further, a dynamic weight controller(DWC) is further designed for balancing the relative importance among them during training. The experimental results of our method are promising, which surpass previous state-of-the-art methods on several commonly used person re-ID benchmarks.