 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargetless Intrinsics and Extrinsic Calibration of Multiple LiDARs and Cameras with IMU using Continuous-Time Estimation
Jan 06, 2025



Accurate spatiotemporal calibration is a prerequisite for multisensor fusion. However, sensors are typically asynchronous, and there is no overlap between the fields of view of cameras and LiDARs, posing challenges for intrinsic and extrinsic parameter calibration. To address this, we propose a calibration pipeline based on continuous-time and bundle adjustment (BA) capable of simultaneous intrinsic and extrinsic calibration (6 DOF transformation and time offset). We do not require overlapping fields of view or any calibration board. Firstly, we establish data associations between cameras using Structure from Motion (SFM) and perform self-calibration of camera intrinsics. Then, we establish data associations between LiDARs through adaptive voxel map construction, optimizing for extrinsic calibration within the map. Finally, by matching features between the intensity projection of LiDAR maps and camera images, we conduct joint optimization for intrinsic and extrinsic parameters. This pipeline functions in texture-rich structured environments, allowing simultaneous calibration of any number of cameras and LiDARs without the need for intricate sensor synchronization triggers. Experimental results demonstrate our method's ability to fulfill co-visibility and motion constraints between sensors without accumulating errors.
S3-SLAM: Sparse Tri-plane Encoding for Neural Implicit SLAM
Apr 28, 2024With the emergence of Neural Radiance Fields (NeRF), neural implicit representations have gained widespread applications across various domains, including simultaneous localization and mapping. However, current neural implicit SLAM faces a challenging trade-off problem between performance and the number of parameters. To address this problem, we propose sparse tri-plane encoding, which efficiently achieves scene reconstruction at resolutions up to 512 using only 2~4% of the commonly used tri-plane parameters (reduced from 100MB to 2~4MB). On this basis, we design S3-SLAM to achieve rapid and high-quality tracking and mapping through sparsifying plane parameters and integrating orthogonal features of tri-plane. Furthermore, we develop hierarchical bundle adjustment to achieve globally consistent geometric structures and reconstruct high-resolution appearance. Experimental results demonstrate that our approach achieves competitive tracking and scene reconstruction with minimal parameters on three datasets. Source code will soon be available.
An Object SLAM Framework for Association, Mapping, and High-Level Tasks
May 12, 2023



Object SLAM is considered increasingly significant for robot high-level perception and decision-making. Existing studies fall short in terms of data association, object representation, and semantic mapping and frequently rely on additional assumptions, limiting their performance. In this paper, we present a comprehensive object SLAM framework that focuses on object-based perception and object-oriented robot tasks. First, we propose an ensemble data association approach for associating objects in complicated conditions by incorporating parametric and nonparametric statistic testing. In addition, we suggest an outlier-robust centroid and scale estimation algorithm for modeling objects based on the iForest and line alignment. Then a lightweight and object-oriented map is represented by estimated general object models. Taking into consideration the semantic invariance of objects, we convert the object map to a topological map to provide semantic descriptors to enable multi-map matching. Finally, we suggest an object-driven active exploration strategy to achieve autonomous mapping in the grasping scenario. A range of public datasets and real-world results in mapping, augmented reality, scene matching, relocalization, and robotic manipulation have been used to evaluate the proposed object SLAM framework for its efficient performance.
BSH-Det3D: Improving 3D Object Detection with BEV Shape Heatmap
Mar 03, 2023



The progress of LiDAR-based 3D object detection has significantly enhanced developments in autonomous driving and robotics. However, due to the limitations of LiDAR sensors, object shapes suffer from deterioration in occluded and distant areas, which creates a fundamental challenge to 3D perception. Existing methods estimate specific 3D shapes and achieve remarkable performance. However, these methods rely on extensive computation and memory, causing imbalances between accuracy and real-time performance. To tackle this challenge, we propose a novel LiDAR-based 3D object detection model named BSH-Det3D, which applies an effective way to enhance spatial features by estimating complete shapes from a bird's eye view (BEV). Specifically, we design the Pillar-based Shape Completion (PSC) module to predict the probability of occupancy whether a pillar contains object shapes. The PSC module generates a BEV shape heatmap for each scene. After integrating with heatmaps, BSH-Det3D can provide additional information in shape deterioration areas and generate high-quality 3D proposals. We also design an attention-based densification fusion module (ADF) to adaptively associate the sparse features with heatmaps and raw points. The ADF module integrates the advantages of points and shapes knowledge with negligible overheads. Extensive experiments on the KITTI benchmark achieve state-of-the-art (SOTA) performance in terms of accuracy and speed, demonstrating the efficiency and flexibility of BSH-Det3D. The source code is available on https://github.com/mystorm16/BSH-Det3D.
FR-LIO: Fast and Robust Lidar-Inertial Odometry by Tightly-Coupled Iterated Kalman Smoother and Robocentric Voxels
Feb 08, 2023



This paper presents a fast lidar-inertial odometry (LIO) system that is robust to aggressive motion. To achieve robust tracking in aggressive motion scenes, we exploit the continuous scanning property of lidar to adaptively divide the full scan into multiple partial scans (named sub-frames) according to the motion intensity. And to avoid the degradation of sub-frames resulting from insufficient constraints, we propose a robust state estimation method based on a tightly-coupled iterated error state Kalman smoother (ESKS) framework. Furthermore, we propose a robocentric voxel map (RC-Vox) to improve the system's efficiency. The RC-Vox allows efficient maintenance of map points and k nearest neighbor (k-NN) queries by mapping local map points into a fixed-size, two-layer 3D array structure. Extensive experiments were conducted on 27 sequences from 4 public datasets and our own dataset. The results show that our system can achieve stable tracking in aggressive motion scenes that cannot be handled by other state-of-the-art methods, while our system can achieve competitive performance with these methods in general scenes. In terms of efficiency, the RC-Vox allows our system to achieve the fastest speed compared with the current advanced LIO systems.
DYP-SLAM: A Real-time Visual SLAM Based on YOLO and Probability in Dynamic Environments
Feb 04, 2022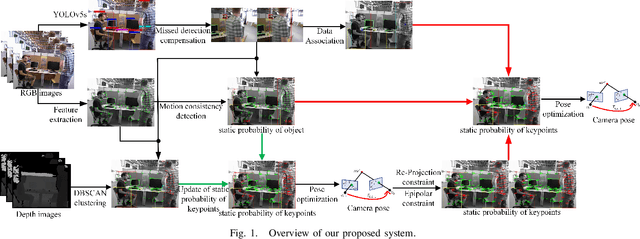

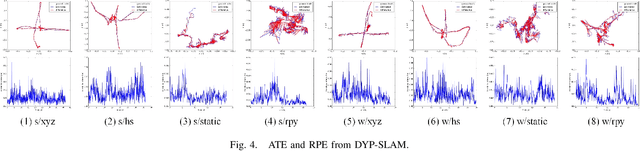
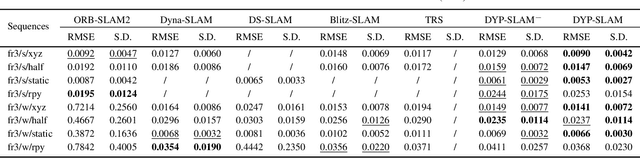
SLAM algorithm is based on the static assumption of environment. Therefore, the dynamic factors in the environment will have a great impact on the matching points due to violating this assumption, and then directly affect the accuracy of subsequent camera pose estimation. Recently, some related works generally use the combination of semantic constraints and geometric constraints to deal with dynamic objects, but there are some problems, such as poor real-time performance, easy to treat people as rigid bodies, and poor performance in low dynamic scenes. In this paper, a dynamic scene oriented visual SLAM algorithm based on target detection and static probability named DYP-SLAM is proposed. The algorithm combines semantic constraints and geometric constraints to calculate the static probability of objects, keypoints and map points, and takes them as weights to participate in camera pose estimation. The proposed algorithm is evaluated on the public dataset and compared with a variety of advanced algorithms. It has achieved the best results in almost all low dynamics and high dynamic scenarios, and showing quite high real-time.
LBCF: A Large-Scale Budget-Constrained Causal Forest Algorithm
Jan 29, 2022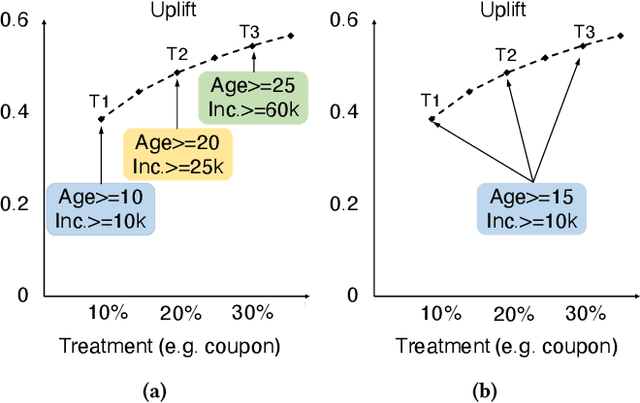
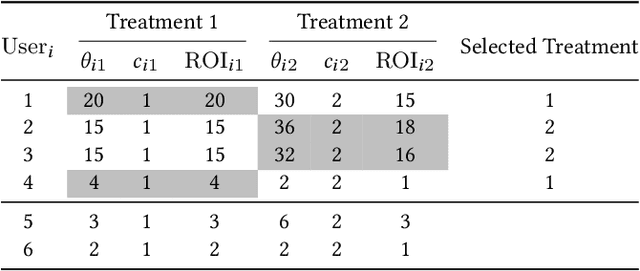
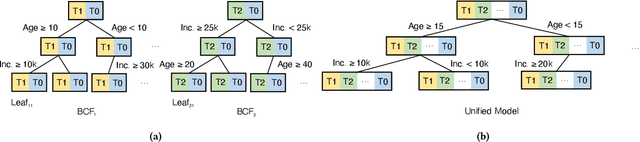

Offering incentives (e.g., coupons at Amazon, discounts at Uber and video bonuses at Tiktok) to user is a common strategy used by online platforms to increase user engagement and platform revenue. Despite its proven effectiveness, these marketing incentives incur an inevitable cost and might result in a low ROI (Return on Investment) if not used properly. On the other hand, different users respond differently to these incentives, for instance, some users never buy certain products without coupons, while others do anyway. Thus, how to select the right amount of incentives (i.e. treatment) to each user under budget constraints is an important research problem with great practical implications. In this paper, we call such problem as a budget-constrained treatment selection (BTS) problem. The challenge is how to efficiently solve BTS problem on a Large-Scale dataset and achieve improved results over the existing techniques. We propose a novel tree-based treatment selection technique under budget constraints, called Large-Scale Budget-Constrained Causal Forest (LBCF) algorithm, which is also an efficient treatment selection algorithm suitable for modern distributed computing systems. A novel offline evaluation method is also proposed to overcome an intrinsic challenge in assessing solutions' performance for BTS problem in randomized control trials (RCT) data. We deploy our approach in a real-world scenario on a large-scale video platform, where the platform gives away bonuses in order to increase users' campaign engagement duration. The simulation analysis, offline and online experiments all show that our method outperforms various tree-based state-of-the-art baselines. The proposed approach is currently serving over hundreds of millions of users on the platform and achieves one of the most tremendous improvements over these months.
Accurate and Robust Object-oriented SLAM with 3D Quadric Landmark Construction in Outdoor Environment
Oct 18, 2021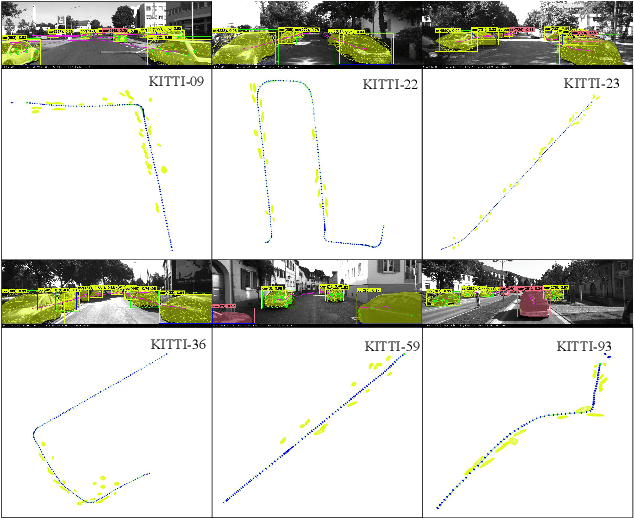
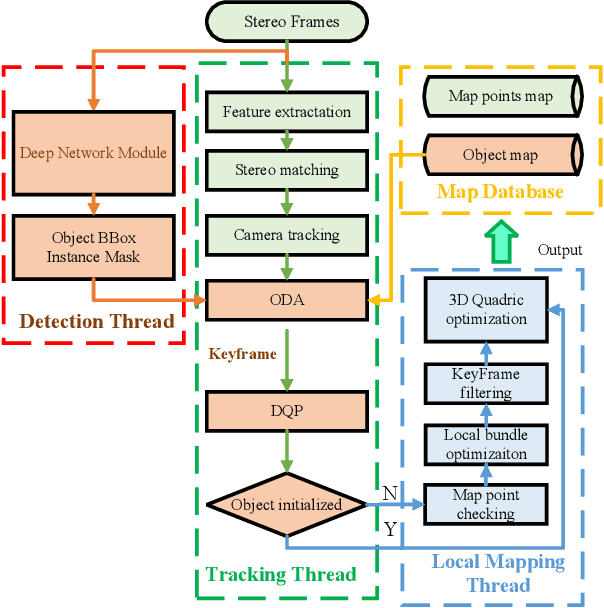
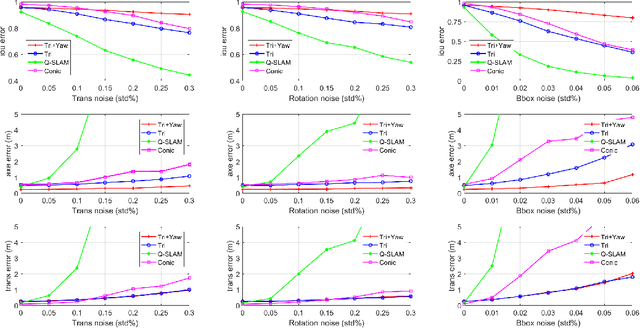
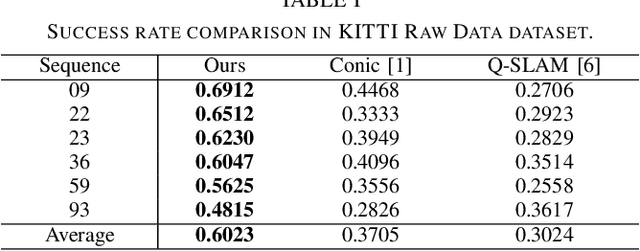
Object-oriented SLAM is a popular technology in autonomous driving and robotics. In this paper, we propose a stereo visual SLAM with a robust quadric landmark representation method. The system consists of four components, including deep learning detection, object-oriented data association, dual quadric landmark initialization and object-based pose optimization. State-of-the-art quadric-based SLAM algorithms always face observation related problems and are sensitive to observation noise, which limits their application in outdoor scenes. To solve this problem, we propose a quadric initialization method based on the decoupling of the quadric parameters method, which improves the robustness to observation noise. The sufficient object data association algorithm and object-oriented optimization with multiple cues enables a highly accurate object pose estimation that is robust to local observations. Experimental results show that the proposed system is more robust to observation noise and significantly outperforms current state-of-the-art methods in outdoor environments. In addition, the proposed system demonstrates real-time performance.
Accurate and Robust Scale Recovery for Monocular Visual Odometry Based on Plane Geometry
Jan 15, 2021
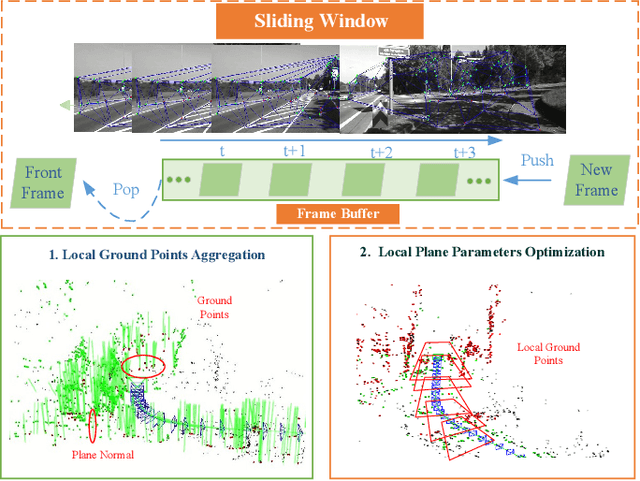
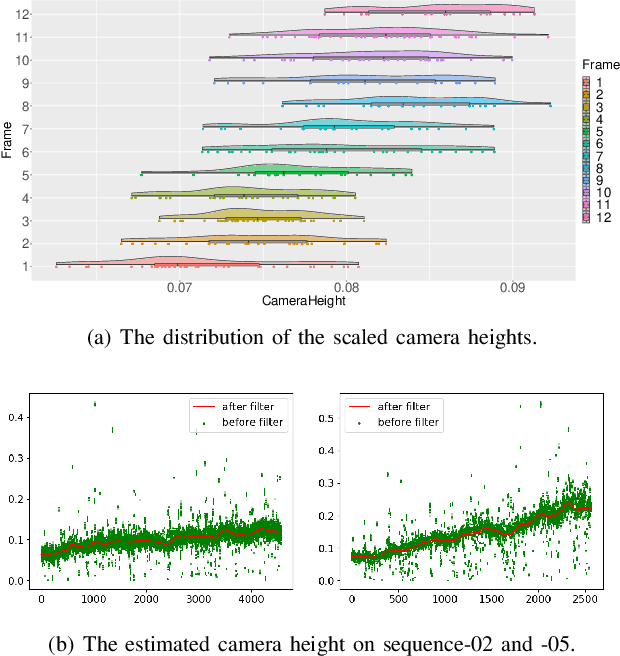
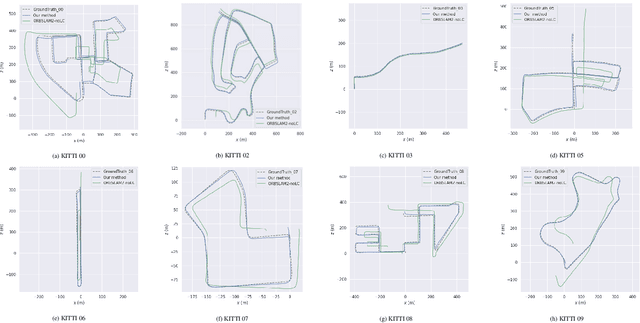
Scale ambiguity is a fundamental problem in monocular visual odometry. Typical solutions include loop closure detection and environment information mining. For applications like self-driving cars, loop closure is not always available, hence mining prior knowledge from the environment becomes a more promising approach. In this paper, with the assumption of a constant height of the camera above the ground, we develop a light-weight scale recovery framework leveraging an accurate and robust estimation of the ground plane. The framework includes a ground point extraction algorithm for selecting high-quality points on the ground plane, and a ground point aggregation algorithm for joining the extracted ground points in a local sliding window. Based on the aggregated data, the scale is finally recovered by solving a least-squares problem using a RANSAC-based optimizer. Sufficient data and robust optimizer enable a highly accurate scale recovery. Experiments on the KITTI dataset show that the proposed framework can achieve state-of-the-art accuracy in terms of translation errors, while maintaining competitive performance on the rotation error. Due to the light-weight design, our framework also demonstrates a high frequency of 20Hz on the dataset.
Object-Driven Active Mapping for More Accurate Object Pose Estimation and Robotic Grasping
Dec 03, 2020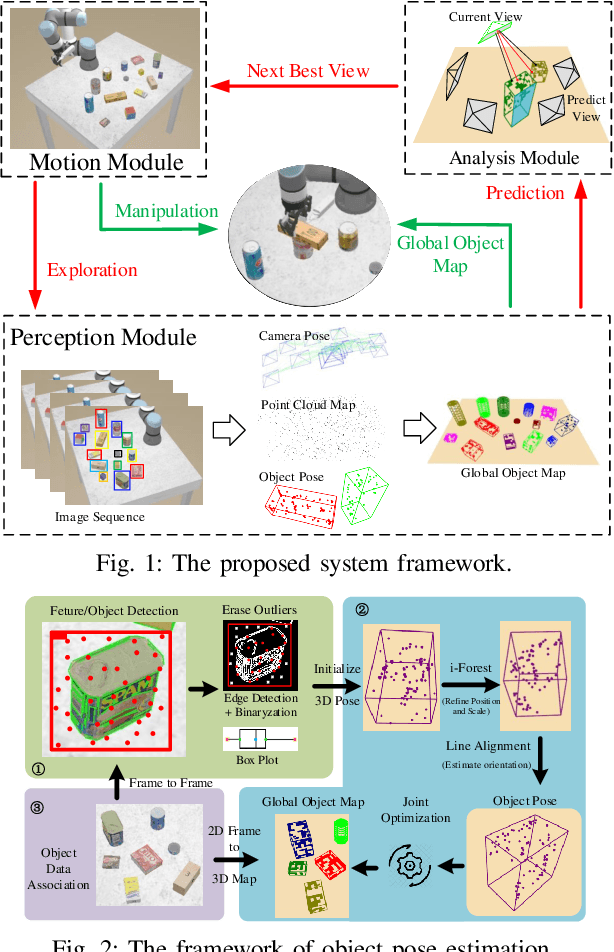
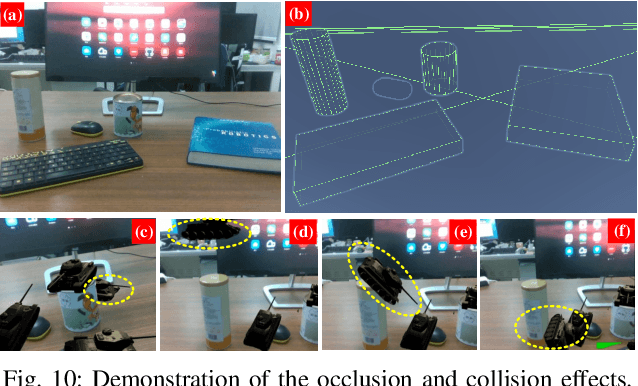

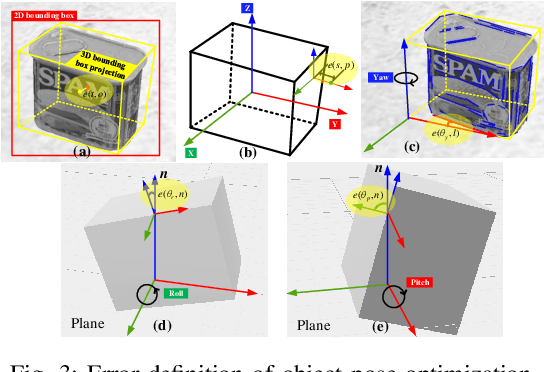
This paper presents the first active object mapping framework for complex robotic grasping tasks. The framework is built on an object SLAM system integrated with a simultaneous multi-object pose estimation process. Aiming to reduce the observation uncertainty on target objects and increase their pose estimation accuracy, we also design an object-driven exploration strategy to guide the object mapping process. By combining the mapping module and the exploration strategy, an accurate object map that is compatible with robotic grasping can be generated. Quantitative evaluations also show that the proposed framework has a very high mapping accuracy. Manipulation experiments, including object grasping, object placement, and the augmented reality, significantly demonstrate the effectiveness and advantages of our proposed framework.