 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Synthesis-based Imaging-Differentiation Representation Learning for Multi-Sequence 3D/4D MRI
Feb 01, 2023
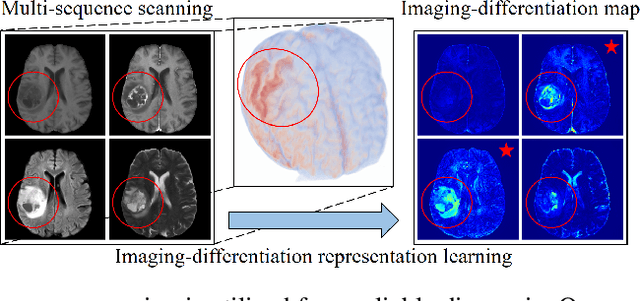
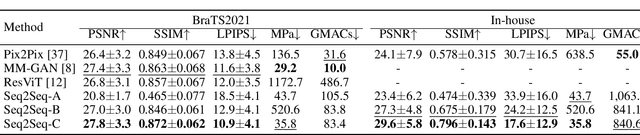
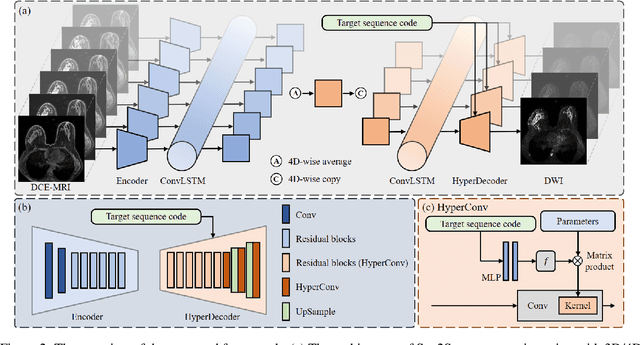
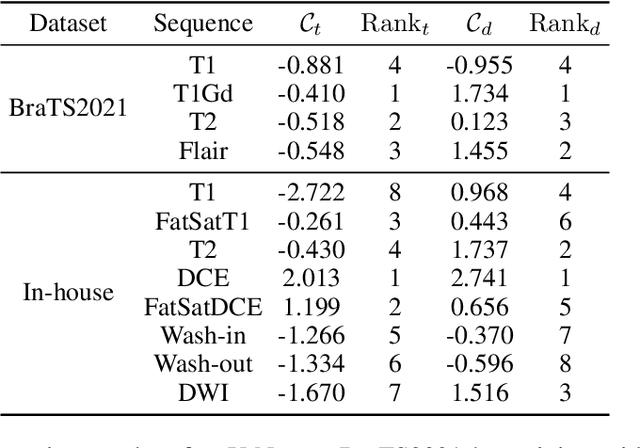
Multi-sequence MRIs can be necessary for reliable diagnosis in clinical practice due to the complimentary information within sequences. However, redundant information exists across sequences, which interferes with mining efficient representations by modern machine learning or deep learning models. To handle various clinical scenarios, we propose a sequence-to-sequence generation framework (Seq2Seq) for imaging-differentiation representation learning. In this study, not only do we propose arbitrary 3D/4D sequence generation within one model to generate any specified target sequence, but also we are able to rank the importance of each sequence based on a new metric estimating the difficulty of a sequence being generated. Furthermore, we also exploit the generation inability of the model to extract regions that contain unique information for each sequence. We conduct extensive experiments using three datasets including a toy dataset of 20,000 simulated subjects, a brain MRI dataset of 1,251 subjects, and a breast MRI dataset of 2,101 subjects, to demonstrate that (1) our proposed Seq2Seq is efficient and lightweight for complex clinical datasets and can achieve excellent image quality; (2) top-ranking sequences can be used to replace complete sequences with non-inferior performance; (3) combining MRI with our imaging-differentiation map leads to better performance in clinical tasks such as glioblastoma MGMT promoter methylation status prediction and breast cancer pathological complete response status prediction. Our code is available at https://github.com/fiy2W/mri_seq2seq.
Self-Supervised Node Representation Learning via Node-to-Neighbourhood Alignment
Feb 10, 2023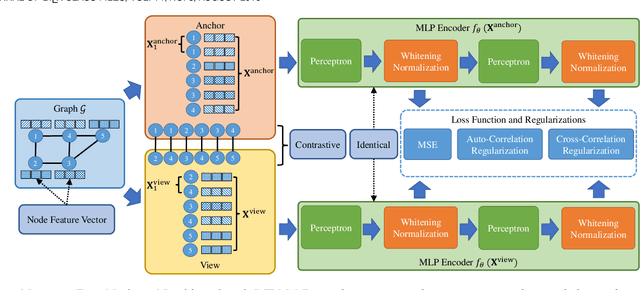
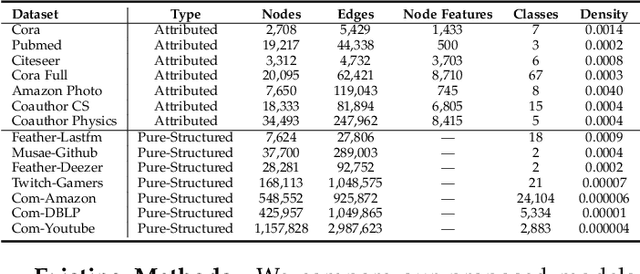
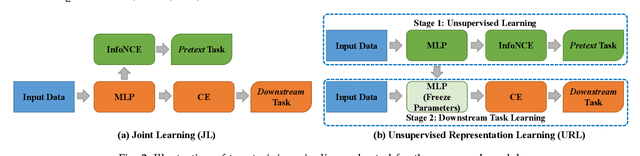
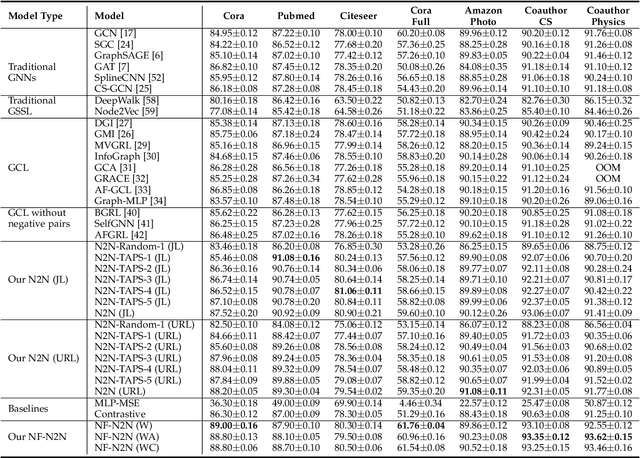
Self-supervised node representation learning aims to learn node representations from unlabelled graphs that rival the supervised counterparts. The key towards learning informative node representations lies in how to effectively gain contextual information from the graph structure. In this work, we present simple-yet-effective self-supervised node representation learning via aligning the hidden representations of nodes and their neighbourhood. Our first idea achieves such node-to-neighbourhood alignment by directly maximizing the mutual information between their representations, which, we prove theoretically, plays the role of graph smoothing. Our framework is optimized via a surrogate contrastive loss and a Topology-Aware Positive Sampling (TAPS) strategy is proposed to sample positives by considering the structural dependencies between nodes, which enables offline positive selection. Considering the excessive memory overheads of contrastive learning, we further propose a negative-free solution, where the main contribution is a Graph Signal Decorrelation (GSD) constraint to avoid representation collapse and over-smoothing. The GSD constraint unifies some of the existing constraints and can be used to derive new implementations to combat representation collapse. By applying our methods on top of simple MLP-based node representation encoders, we learn node representations that achieve promising node classification performance on a set of graph-structured datasets from small- to large-scale.
Text recognition on images using pre-trained CNN
Feb 10, 2023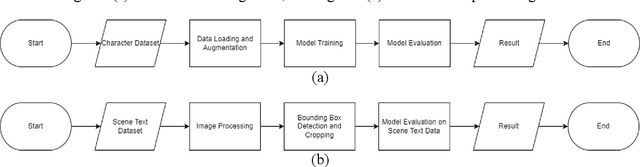
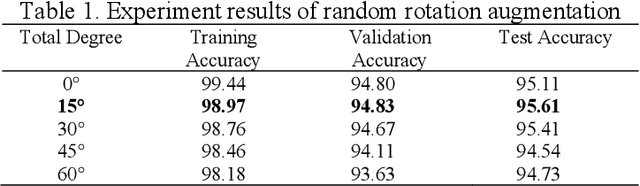

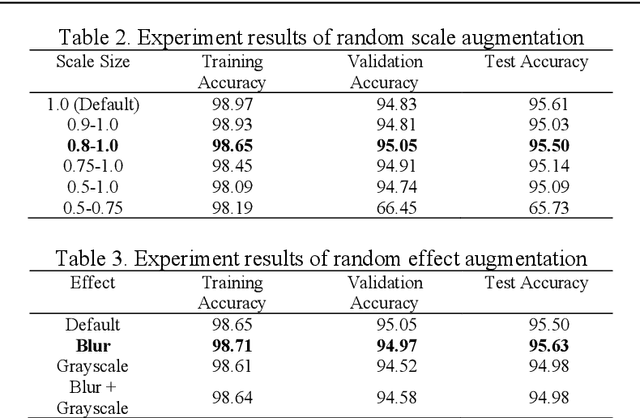
A text on an image often stores important information and directly carries high level semantics, makes it as important source of information and become a very active research topic. Many studies have shown that the use of CNN-based neural networks is quite effective and accurate for image classification which is the basis of text recognition. It can also be more enhanced by using transfer learning from pre-trained model trained on ImageNet dataset as an initial weight. In this research, the recognition is trained by using Chars74K dataset and the best model results then tested on some samples of IIIT-5K-Dataset. The research results showed that the best accuracy is the model that trained using VGG-16 architecture applied with image transformation of rotation 15{\deg}, image scale of 0.9, and the application of gaussian blur effect. The research model has an accuracy of 97.94% for validation data, 98.16% for test data, and 95.62% for the test data from IIIT-5K-Dataset. Based on these results, it can be concluded that pre-trained CNN can produce good accuracy for text recognition, and the model architecture that used in this study can be used as reference material in the development of text detection systems in the future
Adjacent-level Feature Cross-Fusion with 3D CNN for Remote Sensing Image Change Detection
Feb 10, 2023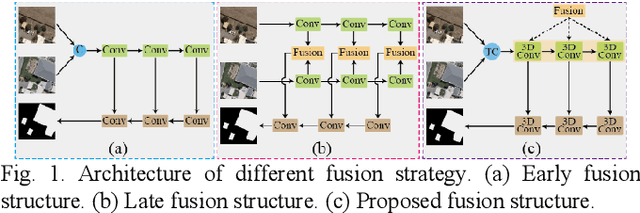

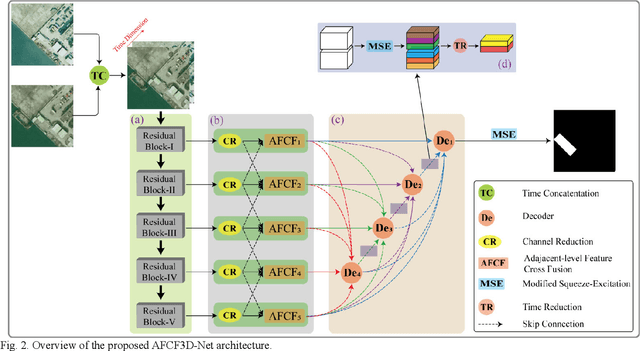
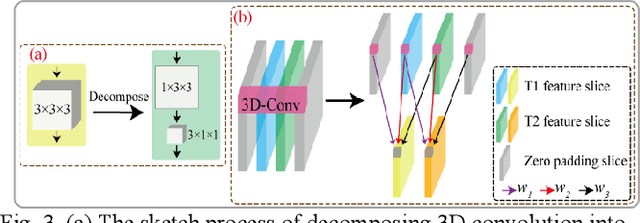
Deep learning-based change detection using remote sensing images has received increasing attention in recent years. However, how to effectively extract and fuse the deep features of bi-temporal images to improve the accuracy of change detection is still a challenge. To address that, a novel adjacent-level feature fusion network with 3D convolution (named AFCF3D-Net) is proposed in this article. First, through the inner fusion property of 3D convolution, we design a new feature fusion way that can simultaneously extract and fuse the feature information from bi-temporal images. Then, in order to bridge the semantic gap between low-level features and high-level features, we propose an adjacent-level feature cross-fusion (AFCF) module to aggregate complementary feature information between the adjacent-levels. Furthermore, the densely skip connection strategy is introduced to improve the capability of pixel-wise prediction and compactness of changed objects in the results. Finally, the proposed AFCF3D-Net has been validated on the three challenging remote sensing change detection datasets: Wuhan building dataset (WHU-CD), LEVIR building dataset (LEVIR-CD), and Sun Yat-Sen University (SYSU-CD). The results of quantitative analysis and qualitative comparison demonstrate that the proposed AFCF3D-Net achieves better performance compared to the other state-of-the-art change detection methods.
Semantic Segmentation of Urban Textured Meshes Through Point Sampling
Feb 21, 2023
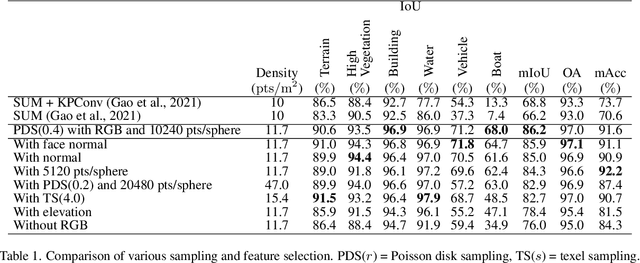


Textured meshes are becoming an increasingly popular representation combining the 3D geometry and radiometry of real scenes. However, semantic segmentation algorithms for urban mesh have been little investigated and do not exploit all radiometric information. To address this problem, we adopt an approach consisting in sampling a point cloud from the textured mesh, then using a point cloud semantic segmentation algorithm on this cloud, and finally using the obtained semantic to segment the initial mesh. In this paper, we study the influence of different parameters such as the sampling method, the density of the extracted cloud, the features selected (color, normal, elevation) as well as the number of points used at each training period. Our result outperforms the state-of-the-art on the SUM dataset, earning about 4 points in OA and 18 points in mIoU.
* 9 pages, 6 figures, conference, presented at XXIV ISPRS Congress
Sedition Hunters: A Quantitative Study of the Crowdsourced Investigation into the 2021 U.S. Capitol Attack
Feb 21, 2023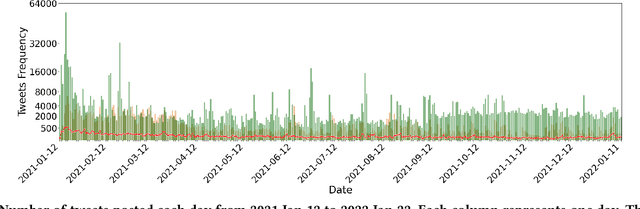
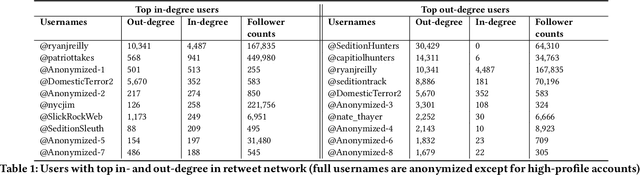

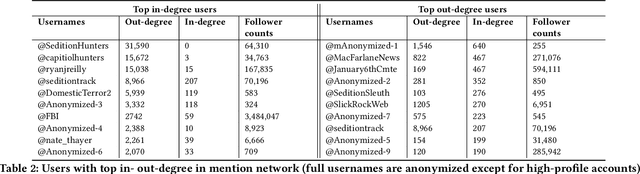
Social media platforms have enabled extremists to organize violent events, such as the 2021 U.S. Capitol Attack. Simultaneously, these platforms enable professional investigators and amateur sleuths to collaboratively collect and identify imagery of suspects with the goal of holding them accountable for their actions. Through a case study of Sedition Hunters, a Twitter community whose goal is to identify individuals who participated in the 2021 U.S. Capitol Attack, we explore what are the main topics or targets of the community, who participates in the community, and how. Using topic modeling, we find that information sharing is the main focus of the community. We also note an increase in awareness of privacy concerns. Furthermore, using social network analysis, we show how some participants played important roles in the community. Finally, we discuss implications for the content and structure of online crowdsourced investigations.
On Interpretable Approaches to Cluster, Classify and Represent Multi-Subspace Data via Minimum Lossy Coding Length based on Rate-Distortion Theory
Feb 21, 2023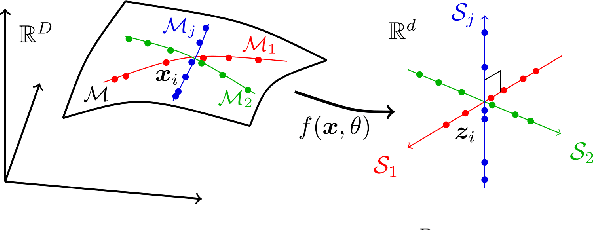
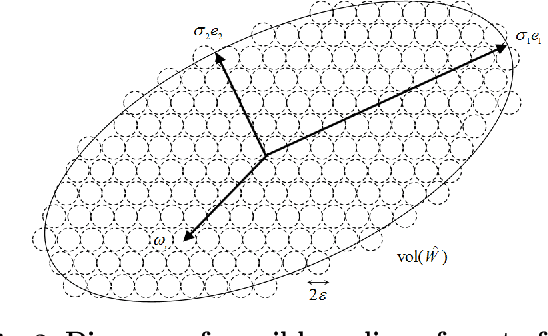
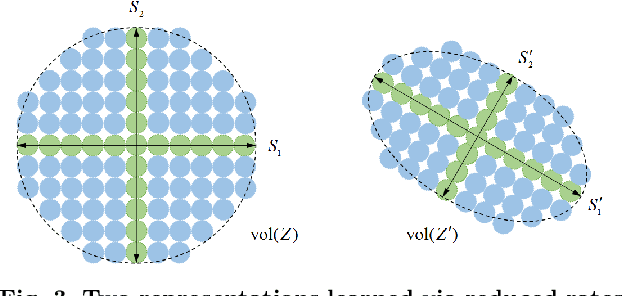
To cluster, classify and represent are three fundamental objectives of learning from high-dimensional data with intrinsic structure. To this end, this paper introduces three interpretable approaches, i.e., segmentation (clustering) via the Minimum Lossy Coding Length criterion, classification via the Minimum Incremental Coding Length criterion and representation via the Maximal Coding Rate Reduction criterion. These are derived based on the lossy data coding and compression framework from the principle of rate distortion in information theory. These algorithms are particularly suitable for dealing with finite-sample data (allowed to be sparse or almost degenerate) of mixed Gaussian distributions or subspaces. The theoretical value and attractive features of these methods are summarized by comparison with other learning methods or evaluation criteria. This summary note aims to provide a theoretical guide to researchers (also engineers) interested in understanding 'white-box' machine (deep) learning methods.
Real-time Local Feature with Global Visual Information Enhancement
Nov 20, 2022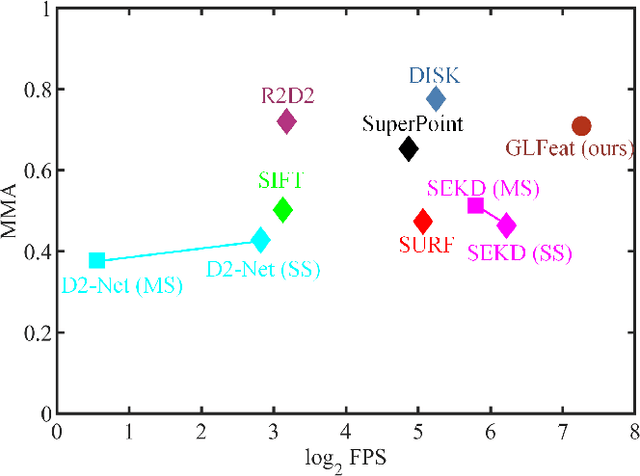
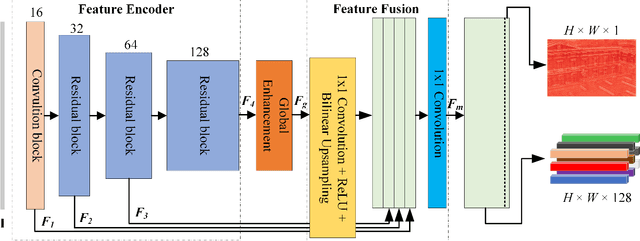

Local feature provides compact and invariant image representation for various visual tasks. Current deep learning-based local feature algorithms always utilize convolution neural network (CNN) architecture with limited receptive field. Besides, even with high-performance GPU devices, the computational efficiency of local features cannot be satisfactory. In this paper, we tackle such problems by proposing a CNN-based local feature algorithm. The proposed method introduces a global enhancement module to fuse global visual clues in a light-weight network, and then optimizes the network by novel deep reinforcement learning scheme from the perspective of local feature matching task. Experiments on the public benchmarks demonstrate that the proposal can achieve considerable robustness against visual interference and meanwhile run in real time.
S3I-PointHop: SO(3)-Invariant PointHop for 3D Point Cloud Classification
Feb 22, 2023
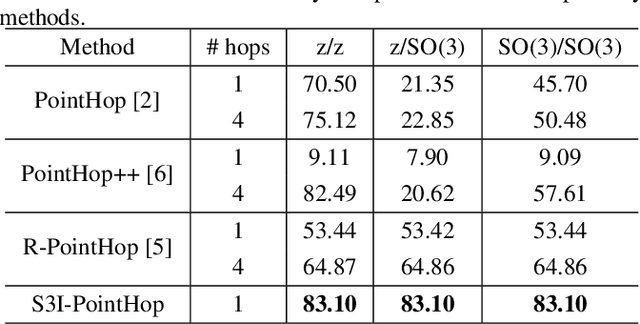
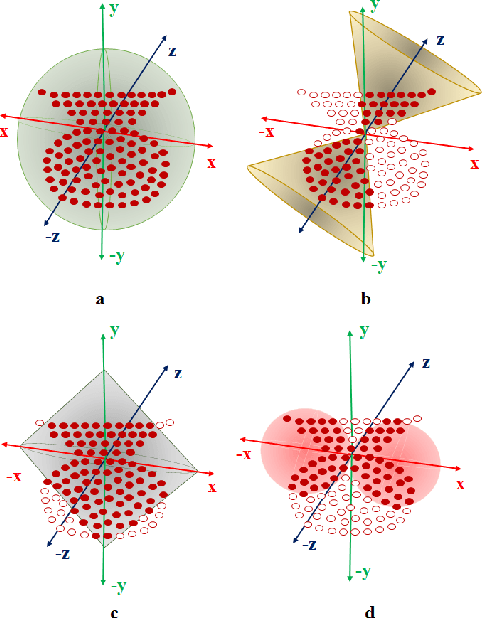
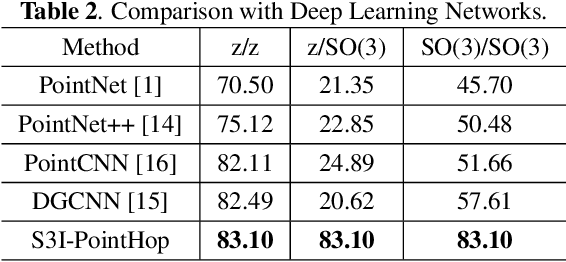
Many point cloud classification methods are developed under the assumption that all point clouds in the dataset are well aligned with the canonical axes so that the 3D Cartesian point coordinates can be employed to learn features. When input point clouds are not aligned, the classification performance drops significantly. In this work, we focus on a mathematically transparent point cloud classification method called PointHop, analyze its reason for failure due to pose variations, and solve the problem by replacing its pose dependent modules with rotation invariant counterparts. The proposed method is named SO(3)-Invariant PointHop (or S3I-PointHop in short). We also significantly simplify the PointHop pipeline using only one single hop along with multiple spatial aggregation techniques. The idea of exploiting more spatial information is novel. Experiments on the ModelNet40 dataset demonstrate the superiority of S3I-PointHop over traditional PointHop-like methods.
A Survey on User Behavior Modeling in Recommender Systems
Feb 22, 2023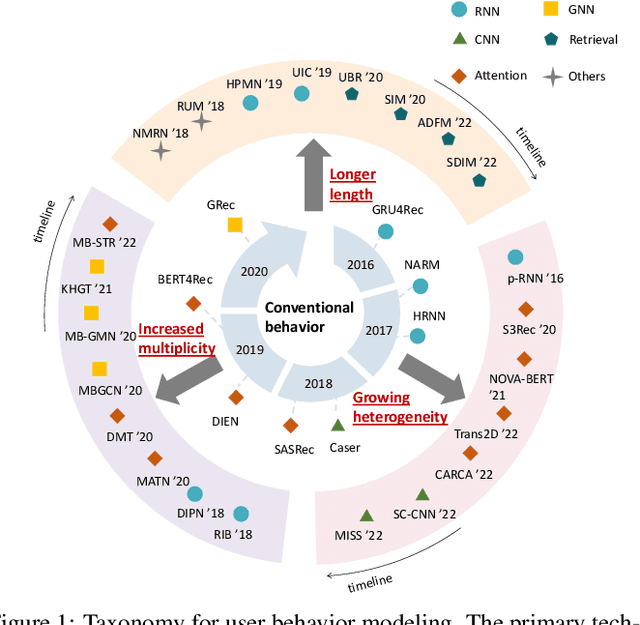

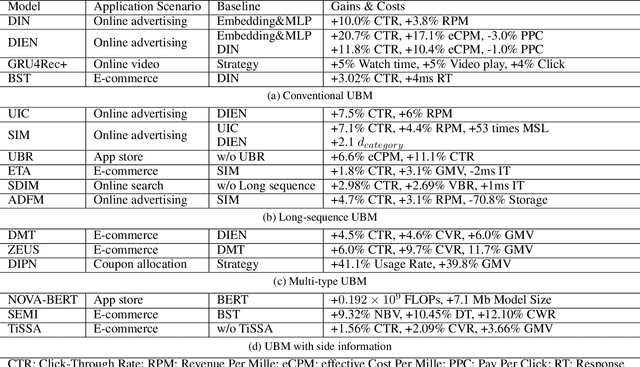
User Behavior Modeling (UBM) plays a critical role in user interest learning, which has been extensively used in recommender systems. Crucial interactive patterns between users and items have been exploited, which brings compelling improvements in many recommendation tasks. In this paper, we attempt to provide a thorough survey of this research topic. We start by reviewing the research background of UBM. Then, we provide a systematic taxonomy of existing UBM research works, which can be categorized into four different directions including Conventional UBM, Long-Sequence UBM, Multi-Type UBM, and UBM with Side Information. Within each direction, representative models and their strengths and weaknesses are comprehensively discussed. Besides, we elaborate on the industrial practices of UBM methods with the hope of providing insights into the application value of existing UBM solutions. Finally, we summarize the survey and discuss the future prospects of this field.